
一文講透 “進程、線程、協(xié)程”
轉自:程序員小灰

本文從操作系統(tǒng)原理出發(fā)結合代碼實踐講解了以下內(nèi)容:
什么是進程,線程和協(xié)程?
它們之間的關系是什么?
為什么說Python中的多線程是偽多線程?
不同的應用場景該如何選擇技術方案?
...
什么是進程
進程-操作系統(tǒng)提供的抽象概念,是系統(tǒng)進行資源分配和調(diào)度的基本單位,是操作系統(tǒng)結構的基礎。程序是指令、數(shù)據(jù)及其組織形式的描述,進程是程序的實體。程序本身是沒有生命周期的,它只是存在磁盤上的一些指令,程序一旦運行就是進程。
當程序需要運行時,操作系統(tǒng)將代碼和所有靜態(tài)數(shù)據(jù)記載到內(nèi)存和進程的地址空間(每個進程都擁有唯一的地址空間,見下圖所示)中,通過創(chuàng)建和初始化棧(局部變量,函數(shù)參數(shù)和返回地址)、分配堆內(nèi)存以及與 IO 相關的任務,當前期準備工作完成,啟動程序,OS將CPU的控制權轉移到新創(chuàng)建的進程,進程開始運行。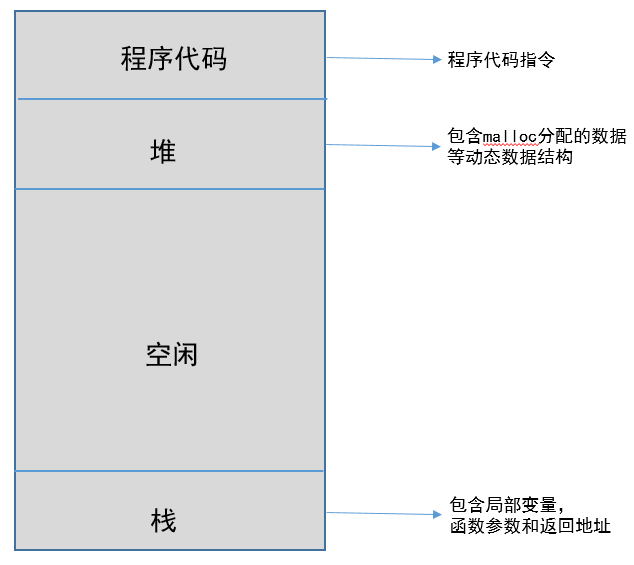
操作系統(tǒng)對進程的控制和管理通過 PCB(Processing Control Block),PCB 通常是系統(tǒng)內(nèi)存占用區(qū)中的一個連續(xù)存區(qū),它存放著操作系統(tǒng)用于描述進程情況及控制進程運行所需的全部信息(進程標識號,進程狀態(tài),進程優(yōu)先級,文件系統(tǒng)指針以及各個寄存器的內(nèi)容等),進程的 PCB 是系統(tǒng)感知進程的唯一實體。
一個進程至少具有 5 種基本狀態(tài):初始態(tài)、執(zhí)行狀態(tài)、等待(阻塞)狀態(tài)、就緒狀態(tài)、終止狀態(tài)
初始狀態(tài):進程剛被創(chuàng)建,由于其他進程正占有 CPU 所以得不到執(zhí)行,只能處于初始狀態(tài)。
執(zhí)行狀態(tài):任意時刻處于執(zhí)行狀態(tài)的進程只能有一個。
就緒狀態(tài):只有處于就緒狀態(tài)的經(jīng)過調(diào)度才能到執(zhí)行狀態(tài)
等待狀態(tài):進程等待某件事件完成
停止狀態(tài):進程結束
進程間的切換
無論是在多核還是單核系統(tǒng)中,一個 CPU 看上去都像是在并發(fā)的執(zhí)行多個進程,這是通過處理器在進程間切換來實現(xiàn)的。
操作系統(tǒng)對把 CPU 控制權在不同進程之間交換執(zhí)行的機制成為上下文切換(context switch),即保存當前進程的上下文,恢復新進程的上下文,然后將 CPU 控制權轉移到新進程,新進程就會從上次停止的地方開始。因此,進程是輪流使用 CPU 的,CPU 被若干進程共享,使用某種調(diào)度算法來決定何時停止一個進程,并轉而為另一個進程提供服務。
單核 CPU 雙進程的情況?
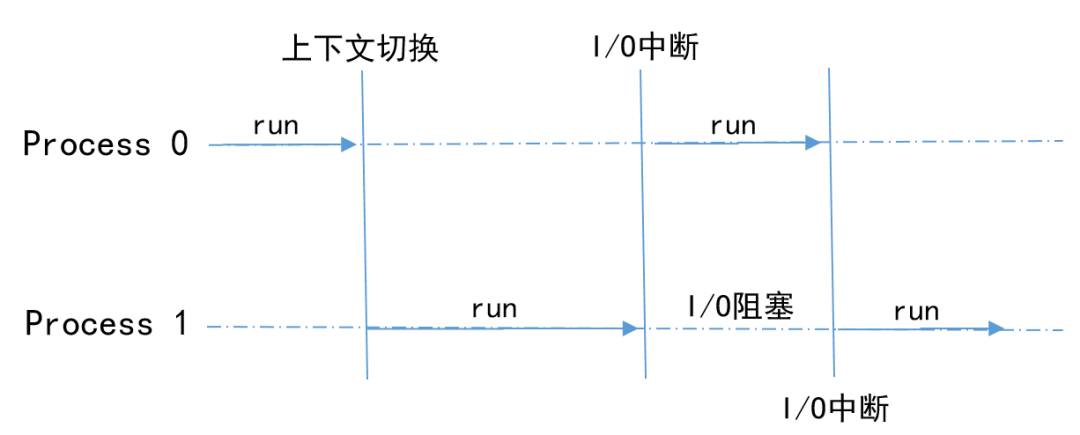
進程直接特定的機制和遇到 I/O 中斷的情況下,進行上下文切換,輪流使用 CPU 資源
雙核 CPU 雙進程的情況?
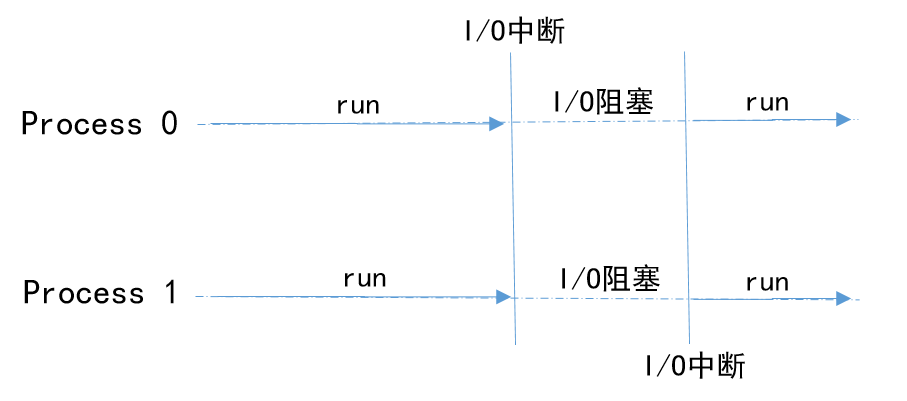
每一個進程獨占一個 CPU 核心資源,在處理 I/O 請求的時候,CPU 處于阻塞狀態(tài)
進程間數(shù)據(jù)共享
系統(tǒng)中的進程與其他進程共享 CPU 和主存資源,為了更好的管理主存,現(xiàn)在系統(tǒng)提供了一種對主存的抽象概念,即為虛擬存儲器(VM)。它是一個抽象的概念,它為每一個進程提供了一個假象,即每個進程都在獨占地使用主存。
虛擬存儲器主要提供了三個能力:
將主存看成是一個存儲在磁盤上的高速緩存,在主存中只保存活動區(qū)域,并根據(jù)需要在磁盤和主存之間來回傳送數(shù)據(jù),通過這種方式,更高效地使用主存
為每個進程提供了一致的地址空間,從而簡化了存儲器管理
保護了每個進程的地址空間不被其他進程破壞
由于進程擁有自己獨占的虛擬地址空間,CPU 通過地址翻譯將虛擬地址轉換成真實的物理地址,每個進程只能訪問自己的地址空間。因此,在沒有其他機制(進程間通信)的輔助下,進程之間是無法共享數(shù)據(jù)的
以 python 中 multiprocessing 為例
import multiprocessingimport threadingimport timen = 0def count(num):global nfor i in range(100000):n += iprint("Process {0}:n={1},id(n)={2}".format(num, n, id(n)))if __name__ == '__main__':start_time = time.time()process = list()for i in range(5):p = multiprocessing.Process(target=count, args=(i,)) # 測試多進程使用# p = threading.Thread(target=count, args=(i,)) # 測試多線程使用process.append(p)for p in process:p.start()for p in process:p.join()print("Main:n={0},id(n)={1}".format(n, id(n)))end_time = time.time()print("Total time:{0}".format(end_time - start_time))
結果
Process 1:n=4999950000,id(n)=139854202072440Process 0:n=4999950000,id(n)=139854329146064Process 2:n=4999950000,id(n)=139854202072400Process 4:n=4999950000,id(n)=139854201618960Process 3:n=4999950000,id(n)=139854202069320Main:n=0,id(n)=9462720Total time:0.03138256072998047
變量 n 在進程 p{0,1,2,3,4} 和主進程(main)中均擁有唯一的地址空間
什么是線程
線程-也是操作系統(tǒng)提供的抽象概念,是程序執(zhí)行中一個單一的順序控制流程,是程序執(zhí)行流的最小單元,是處理器調(diào)度和分派的基本單位。一個進程可以有一個或多個線程,同一進程中的多個線程將共享該進程中的全部系統(tǒng)資源,如虛擬地址空間,文件描述符和信號處理等等。但同一進程中的多個線程有各自的調(diào)用棧和線程本地存儲(如下圖所示)。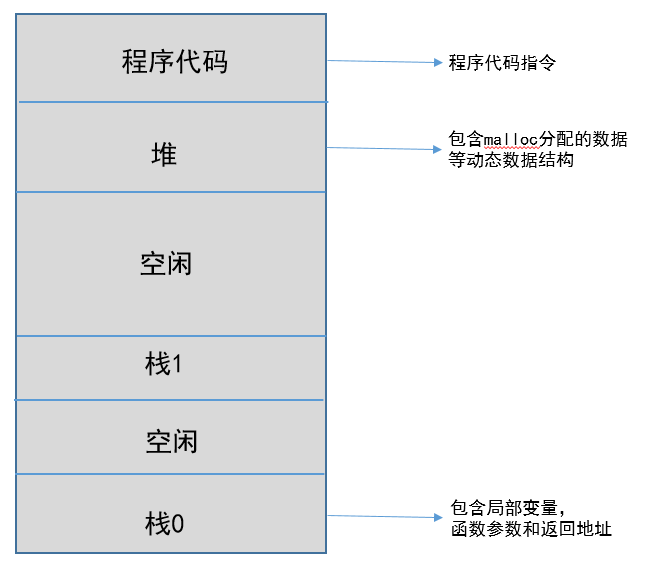
系統(tǒng)利用 PCB 來完成對進程的控制和管理。同樣,系統(tǒng)為線程分配一個線程控制塊TCB(Thread Control Block),將所有用于控制和管理線程的信息記錄在線程的控制塊中, TCB 中通常包括:
線程標志符
一組寄存器
線程運行狀態(tài)
優(yōu)先級
線程專有存儲區(qū)
信號屏蔽
和進程一樣,線程同樣有五種狀態(tài):初始態(tài)、執(zhí)行狀態(tài)、等待(阻塞)狀態(tài)、就緒狀態(tài)和終止狀態(tài),線程之間的切換和進程一樣也需要上下文切換,這里不再贅述。
進程和線程之間有許多相似的地方,那它們之間到底有什么區(qū)別呢?
進程 VS 線程
進程是資源的分配和調(diào)度的獨立單元。進程擁有完整的虛擬地址空間,當發(fā)生進程切換時,不同的進程擁有不同的虛擬地址空間。而同一進程的多個線程是可以共享同一地址空間
線程是 CPU 調(diào)度的基本單元,一個進程包含若干線程。
線程比進程小,基本上不擁有系統(tǒng)資源。線程的創(chuàng)建和銷毀所需要的時間比進程小很多
由于線程之間能夠共享地址空間,因此,需要考慮同步和互斥操作
一個線程的意外終止會影響整個進程的正常運行,但是一個進程的意外終止不會影響其他的進程的運行。因此,多進程程序安全性更高。
總之,多進程程序安全性高,進程切換開銷大,效率低;多線程程序維護成本高,線程切換開銷小,效率高。(python 的多線程是偽多線程,下文中將詳細介紹)
什么是協(xié)程
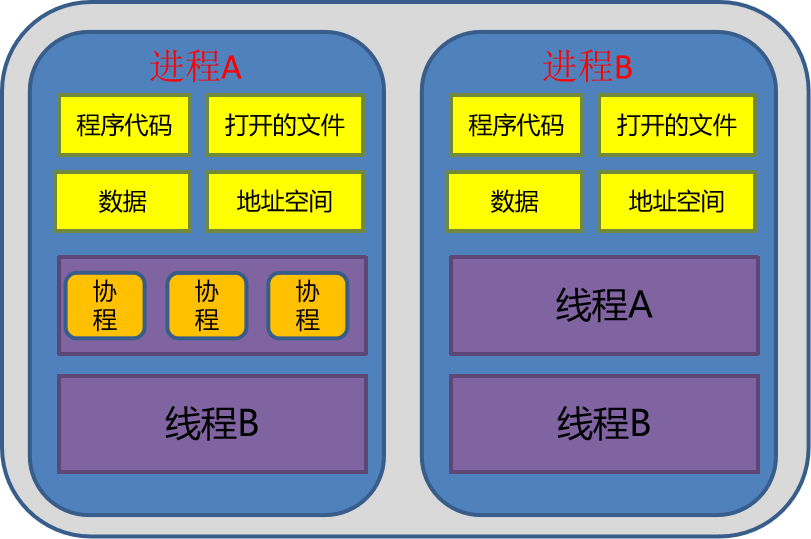
協(xié)程(Coroutine,又稱微線程)是一種比線程更加輕量級的存在,協(xié)程不是被操作系統(tǒng)內(nèi)核所管理,而完全是由程序所控制。協(xié)程與線程以及進程的關系見下圖所示。
協(xié)程可以比作子程序,但執(zhí)行過程中,子程序內(nèi)部可中斷,然后轉而執(zhí)行別的子程序,在適當?shù)臅r候再返回來接著執(zhí)行。協(xié)程之間的切換不需要涉及任何系統(tǒng)調(diào)用或任何阻塞調(diào)用
協(xié)程只在一個線程中執(zhí)行,是子程序之間的切換,發(fā)生在用戶態(tài)上。而且,線程的阻塞狀態(tài)是由操作系統(tǒng)內(nèi)核來完成,發(fā)生在內(nèi)核態(tài)上,因此協(xié)程相比線程節(jié)省線程創(chuàng)建和切換的開銷
協(xié)程中不存在同時寫變量沖突,因此,也就不需要用來守衛(wèi)關鍵區(qū)塊的同步性原語,比如互斥鎖、信號量等,并且不需要來自操作系統(tǒng)的支持。
協(xié)程適用于 IO 阻塞且需要大量并發(fā)的場景,當發(fā)生 IO 阻塞,由協(xié)程的調(diào)度器進行調(diào)度,通過將數(shù)據(jù)流 yield 掉,并且記錄當前棧上的數(shù)據(jù),阻塞完后立刻再通過線程恢復棧,并把阻塞的結果放到這個線程上去運行。
下面,將針對在不同的應用場景中如何選擇使用 Python 中的進程,線程,協(xié)程進行分析。
如何選擇?
在針對不同的場景對比三者的區(qū)別之前,首先需要介紹一下 python 的多線程(一直被程序員所詬病,認為是"假的"多線程)。
那為什么認為 Python 中的多線程是“偽”多線程呢?
更換上面 multiprocessing 示例中, p=multiprocessing.Process(target=count,args=(i,))為 p=threading.Thread(target=count,args=(i,)),其他照舊,運行結果如下:
為了減少代碼冗余和文章篇幅,命名和打印不規(guī)則問題請忽略
Process 0:n=5756690257,id(n)=140103573185600Process 2:n=10819616173,id(n)=140103573185600Process 1:n=11829507727,id(n)=140103573185600Process 4:n=17812587459,id(n)=140103573072912Process 3:n=14424763612,id(n)=140103573185600Main:n=17812587459,id(n)=140103573072912Total time:0.1056210994720459
n 是全局變量,Main 的打印結果與線程相等,證明了線程之間是數(shù)據(jù)共享
但是,為什么多線程運行時間比多進程還要長?這與我們上面所說(線程的開銷<<進程的開銷)的嚴重不相符啊。這就是輪到 Cpython(python 默認的解釋器)中 GIL(Global Interpreter Lock,全局解釋鎖)登場了。
什么是GIL
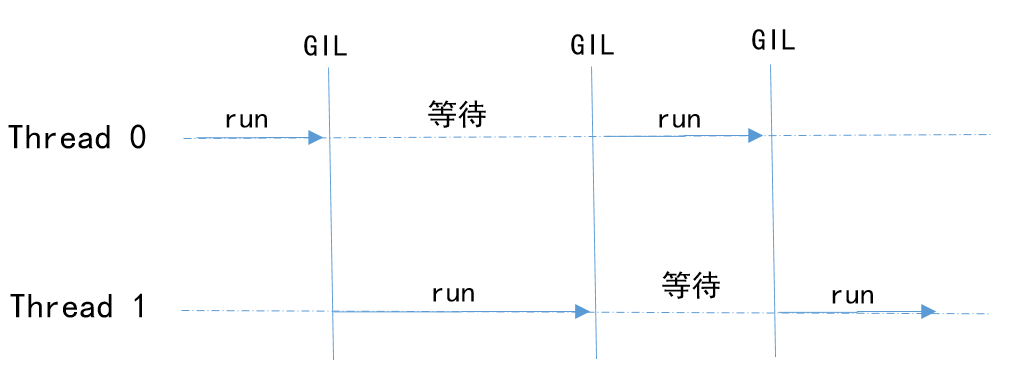
GIL來源于Python設計之初的考慮,為了數(shù)據(jù)安全(由于內(nèi)存管理機制中采用引用計數(shù))所做的決定。某個線程想要執(zhí)行,必須先拿到 GIL。因此,可以把 GIL 看作是“通行證”,并且在一個 Python進程中,GIL 只有一個,拿不到通行證的線程,就不允許進入 CPU 執(zhí)行。
Cpython 解釋器在內(nèi)存管理中采用引用計數(shù),當對象的引用次數(shù)為 0 時,會將對象當作垃圾進行回收。設想這樣一種場景:
一個進程中含有兩個線程,分別為線程 0 和線程 1,兩個線程全都引用對象 a。當兩個線程同時對 a 發(fā)生引用(并未修改,不需要使用同步性原語),就會發(fā)生同時修改對象 a 的引用計數(shù)器,造成計數(shù)器引用少于實質性的引用,當進行垃圾回收時,造成錯誤異常。因此,需要一把全局鎖(即為GIL)來保證對象引用計數(shù)的正確性和安全性。
無論是單核還是多核,一個進程永遠只能同時執(zhí)行一個線程(拿到 GIL 的線程才能執(zhí)行,如下圖所示),這就是為什么在多核 CPU 上,Python 的多線程效率并不高的根本原因。
那是不是在 Python 中遇到并發(fā)的需求就使用多進程就萬事大吉了呢?其實不然,軟件工程中有一句名言:沒有銀彈!
何時用?
常見的應用場景不外乎三種:
CPU 密集型:程序需要占用 CPU 進行大量的運算和數(shù)據(jù)處理;
I/O 密集型:程序中需要頻繁的進行 I/O 操作;例如網(wǎng)絡中 socket 數(shù)據(jù)傳輸和讀取等;
CPU 密集+I/O 密集:以上兩種的結合
CPU 密集型的情況可以對比以上 multiprocessing 和 threading 的例子,多進程的性能 > 多線程的性能。
下面主要解釋一下 I/O 密集型的情況。與 I/O 設備交互,目前最常用的解決方案就是?DMA。
什么是 DMA
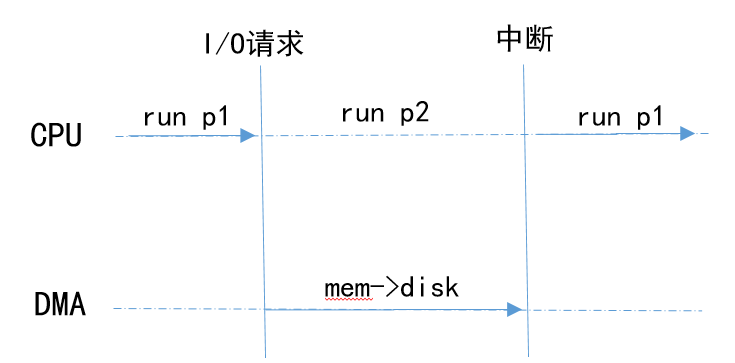
DMA(Direct Memory Access) 是系統(tǒng)中的一個特殊設備,它可以協(xié)調(diào)完成內(nèi)存到設備間的數(shù)據(jù)傳輸,中間過程不需要 CPU 介入。
以文件寫入為例:
進程 p1 發(fā)出數(shù)據(jù)寫入磁盤文件的請求?
CPU 處理寫入請求,通過編程告訴 DMA 引擎數(shù)據(jù)在內(nèi)存的位置,要寫入數(shù)據(jù)的大小以及目標設備等信息
CPU 處理其他進程 p2 的請求,DMA 負責將內(nèi)存數(shù)據(jù)寫入到設備中
DMA 完成數(shù)據(jù)傳輸,中斷 CPU
CPU?從 p2 上下文切換到 p1,繼續(xù)執(zhí)行 p1
Python多線程的表現(xiàn)(I/O密集型)
線程Thread0首先執(zhí)行,線程Thread1等待(GIL的存在)
Thread0收到I/O請求,將請求轉發(fā)給DMA,DMA執(zhí)行請求
Thread1占用CPU資源,繼續(xù)執(zhí)行
CPU收到DMA的中斷請求,切換到Thread0繼續(xù)執(zhí)行
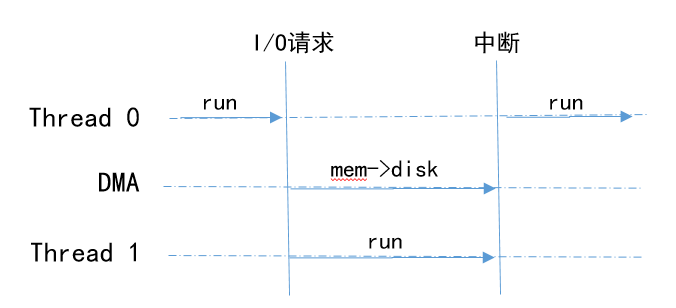
與進程的執(zhí)行模式相似,彌補了 GIL 帶來的不足,又由于線程的開銷遠遠小于進程的開銷,因此,在 IO 密集型場景中,多線程的性能更高
實踐是檢驗真理的唯一標準,下面將針對 I/O 密集型場景進行測試。
測試
執(zhí)行代碼
import multiprocessingimport threadingimport timedef count(num):time.sleep(1) ## 模擬IO操作print("Process {0} End".format(num))if __name__ == '__main__':start_time = time.time()process = list()for i in range(5):p = multiprocessing.Process(target=count, args=(i,))# p = threading.Thread(target=count, args=(i,))process.append(p)for p in process:p.start()for p in process:p.join()end_time = time.time()print("Total time:{0}".format(end_time - start_time))
結果
## 多進程Process 0 EndProcess 3 EndProcess 4 EndProcess 2 EndProcess 1 EndTotal time:1.383193016052246## 多線程Process 0 EndProcess 4 EndProcess 3 EndProcess 1 EndProcess 2 EndTotal time:1.003425121307373
多線程的執(zhí)行效性能高于多進程
是不是認為這就結束了?遠還沒有呢。針對 I/O 密集型的程序,協(xié)程的執(zhí)行效率更高,因為它是程序自身所控制的,這樣將節(jié)省線程創(chuàng)建和切換所帶來的開銷。
以 Python 中 asyncio 應用為依賴,使用 async/await 語法進行協(xié)程的創(chuàng)建和使用。
程序代碼
import timeimport asyncioasync def coroutine():await asyncio.sleep(1) ## 模擬IO操作if __name__ == "__main__":start_time = time.time()loop = asyncio.get_event_loop()tasks = []for i in range(5):task = loop.create_task(coroutine())tasks.append(task)loop.run_until_complete(asyncio.wait(tasks))loop.close()end_time = time.time()print("total time:", end_time - start_time)
結果
total time: 1.001854419708252協(xié)程的執(zhí)行效性能高于多線程
總結
本文從操作系統(tǒng)原理出發(fā)結合代碼實踐講解了進程,線程和協(xié)程以及他們之間的關系。并且,總結和整理了 Python 實踐中針對不同的場景如何選擇對應的方案,如下:
CPU 密集型:多進程
IO 密集型:多線程(協(xié)程維護成本較高,而且在讀寫文件方面效率沒有顯著提升)
CPU 密集和 IO 密集:多進程+協(xié)程
推薦閱讀
1
2
3
4
崔慶才
靜覓博客博主,《Python3網(wǎng)絡爬蟲開發(fā)實戰(zhàn)》作者
隱形字
個人公眾號:進擊的Coder


長按識別二維碼關注