
小團(tuán)隊(duì)真的適合引入SpringCloud微服務(wù)嗎?

單體應(yīng)用時(shí)代 接口定義 持續(xù)集成(CI) 微服務(wù)時(shí)代 服務(wù)拆分原則 框架選擇 架構(gòu)改造 自動(dòng)化部署 鏈路跟蹤 運(yùn)維監(jiān)控 容器化時(shí)代 架構(gòu)改造 Spring Cloud與k8s的融合 CI的改造 小結(jié)
微服務(wù)是否適合小團(tuán)隊(duì)是個(gè)見(jiàn)仁見(jiàn)智的問(wèn)題。
回歸現(xiàn)象看本質(zhì),隨著業(yè)務(wù)復(fù)雜度的提高,單體應(yīng)用越來(lái)越龐大,就好像一個(gè)類的代碼行越來(lái)越多,分而治之,切成多個(gè)類應(yīng)該是更好的解決方法,所以一個(gè)龐大的單體應(yīng)用分出多個(gè)小應(yīng)用也更符合這種分治的思想。
當(dāng)然微服務(wù)架構(gòu)不應(yīng)該是一個(gè)小團(tuán)隊(duì)一開(kāi)始就該考慮的問(wèn)題,而是慢慢演化的結(jié)果,謹(jǐn)慎過(guò)度設(shè)計(jì)尤為重要。
公司的背景是提供SaaS服務(wù),對(duì)于大客戶也會(huì)有定制開(kāi)發(fā)以及私有化部署。經(jīng)過(guò)2年不到的時(shí)間,技術(shù)架構(gòu)經(jīng)歷了從單體到微服務(wù)再到容器化的過(guò)程。
單體應(yīng)用時(shí)代
早期開(kāi)發(fā)只有兩個(gè)人,考慮微服務(wù)之類的都是多余。不過(guò)由于受前公司影響,最初就決定了前后端分離的路線,因?yàn)椴恍枰紤]SEO的問(wèn)題,索性就做成了SPA單頁(yè)應(yīng)用。
多說(shuō)一句,前后端分離也不一定就不能服務(wù)端渲染,例如電商系統(tǒng)或者一些匿名即可訪問(wèn)的系統(tǒng),加一層薄薄的View層,無(wú)論是php還是用Thymeleaf都是不錯(cuò)的選擇。
部署架構(gòu)上,我們使用Nginx代理前端HTML資源,在接收請(qǐng)求時(shí)根據(jù)路徑反向代理到server的8080端口實(shí)現(xiàn)業(yè)務(wù)。
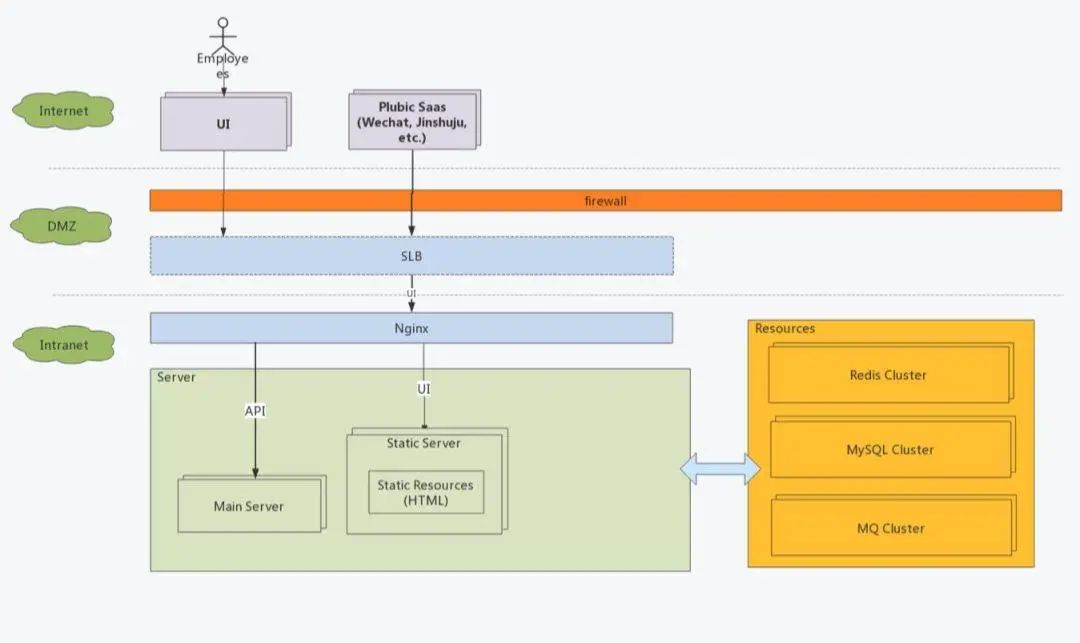
接口定義
接口按照標(biāo)準(zhǔn)的Restful來(lái)定義,
版本,統(tǒng)一跟在 /api/后面,例如? /api/v2以資源為中心,使用復(fù)數(shù)表述,例如 /api/contacts,也可以嵌套,如/api/groups/1/contacts/100url中盡量不使用動(dòng)詞,實(shí)踐中發(fā)現(xiàn)做到這一點(diǎn)真的比較難,每個(gè)研發(fā)人員的思路不一致,起的名字也千奇百怪,都需要在代碼Review中覆蓋。 動(dòng)作支持, POST / PUT / DELELE / GET?,這里有一個(gè)坑,PUT和PATCH都是更新,但是PUT是全量更新而PATCH是部分更新,前者如果傳入的字段是空(未傳也視為空)那么也會(huì)被更新到數(shù)據(jù)庫(kù)中。目前我們雖然是使用PUT但是忽略空字段和未傳字段,本質(zhì)上是一種部分更新,這也帶來(lái)了一些問(wèn)題,比如確有置空的業(yè)務(wù)需要特殊處理。接口通過(guò)swagger生成文檔供前端同事使用。
持續(xù)集成(CI)
團(tuán)隊(duì)初始成員之前都有在大團(tuán)隊(duì)共事的經(jīng)歷,所以對(duì)于質(zhì)量管控和流程管理都有一些共同的要求。因此在開(kāi)發(fā)之初就引入了集成測(cè)試的體系,可以直接開(kāi)發(fā)針對(duì)接口的測(cè)試用例,統(tǒng)一執(zhí)行并計(jì)算覆蓋率。
一般來(lái)說(shuō)代碼自動(dòng)執(zhí)行的都是單元測(cè)試(Unit Test),我們之所以叫集成測(cè)試是因?yàn)闇y(cè)試用例是針對(duì)API的,并且包含了數(shù)據(jù)庫(kù)的讀寫,MQ的操作等等,除了外部服務(wù)的依賴基本都是符合真實(shí)生產(chǎn)場(chǎng)景,相當(dāng)于把Jmeter的事情直接在Java層面做掉了。
這在開(kāi)發(fā)初期為我們提供了非常大的便利性。但值得注意的是,由于數(shù)據(jù)庫(kù)以及其他資源的引入,數(shù)據(jù)準(zhǔn)備以及數(shù)據(jù)清理時(shí)要考慮的問(wèn)題就會(huì)更多,例如如何控制并行任務(wù)之間的測(cè)試數(shù)據(jù)互不影響等等。
為了讓這一套流程可以自動(dòng)化的運(yùn)作起來(lái), 引入Jenkins也是理所當(dāng)然的事情了。
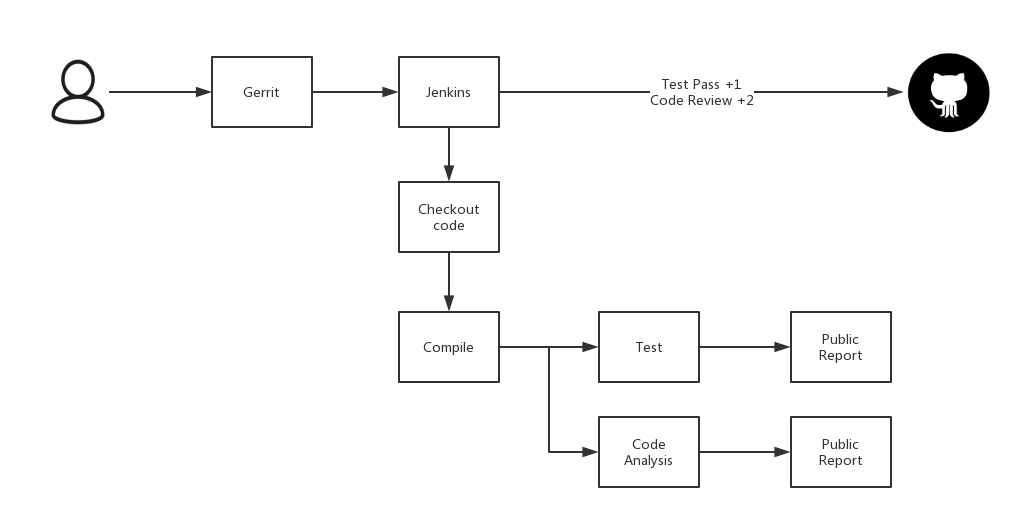
開(kāi)發(fā)人員提交代碼進(jìn)入gerrit中,Jenkins被觸發(fā)開(kāi)始編譯代碼并執(zhí)行集成測(cè)試,完成后生成測(cè)試報(bào)告,測(cè)試通過(guò)再由reviewer進(jìn)行代碼review。在單體應(yīng)用時(shí)代這樣的CI架構(gòu)已經(jīng)足夠好用,由于有集成測(cè)試的覆蓋,在保持API兼容性的前提下進(jìn)行代碼重構(gòu)都會(huì)變得更有信心。
微服務(wù)時(shí)代
服務(wù)拆分原則
從數(shù)據(jù)層面看,最簡(jiǎn)單的方式就是看數(shù)據(jù)庫(kù)的表之間是否有比較少的關(guān)聯(lián)。例如最容易分離的一般來(lái)說(shuō)都是用戶管理模塊。如果從領(lǐng)域驅(qū)動(dòng)設(shè)計(jì)(DDD)看,其實(shí)一個(gè)服務(wù)就是一個(gè)或幾個(gè)相關(guān)聯(lián)的領(lǐng)域模型,通過(guò)少量數(shù)據(jù)冗余劃清服務(wù)邊界。
單個(gè)服務(wù)內(nèi)通過(guò)領(lǐng)域服務(wù)完成多個(gè)領(lǐng)域?qū)ο髤f(xié)作。當(dāng)然DDD比較復(fù)雜,要求領(lǐng)域?qū)ο笤O(shè)計(jì)上是充血模型而非貧血模型。
從實(shí)踐角度講,充血模型對(duì)于大部分開(kāi)發(fā)人員來(lái)說(shuō)難度非常高,什么代碼應(yīng)該屬于行為,什么屬于領(lǐng)域服務(wù),很多時(shí)候非常考驗(yàn)人員水平。
服務(wù)拆分是一個(gè)大工程,往往需要幾個(gè)對(duì)業(yè)務(wù)以及數(shù)據(jù)最熟悉的人一起討論,甚至要考慮到團(tuán)隊(duì)結(jié)構(gòu),最終的效果是服務(wù)邊界清晰, 沒(méi)有環(huán)形依賴和避免雙向依賴。
框架選擇
由于之前的單體服務(wù)使用的是spring boot,所以框架自然而的選擇了spring cloud。其實(shí)個(gè)人認(rèn)為微服務(wù)框架不應(yīng)該限制技術(shù)與語(yǔ)言,但生產(chǎn)實(shí)踐中發(fā)現(xiàn)無(wú)論dubbo還是spring cloud都具有侵入性,我們?cè)趯odejs應(yīng)用融入spring cloud體系時(shí)就發(fā)現(xiàn)了許多問(wèn)題。也許未來(lái)的service mesh才是更合理的發(fā)展道路。
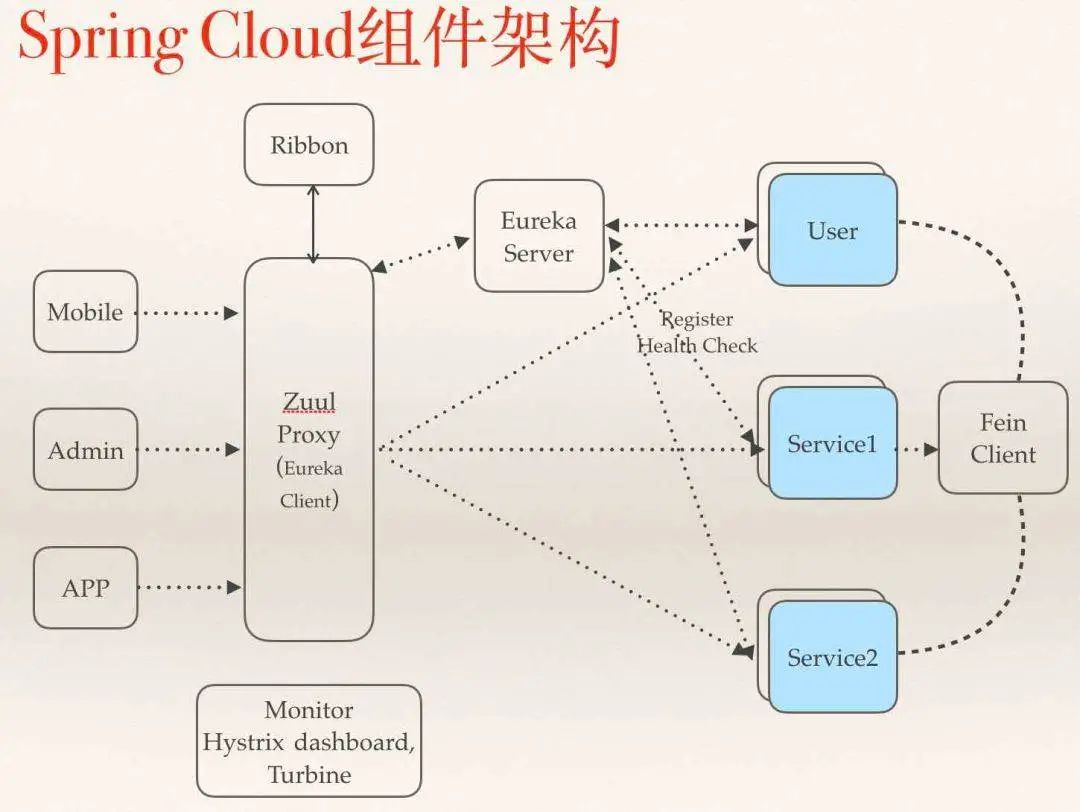
這是典型的Spring Cloud的使用方法
zuul作為gateway,分發(fā)不同客戶端的請(qǐng)求到具體service erueka作為注冊(cè)中心,完成了服務(wù)發(fā)現(xiàn)和服務(wù)注冊(cè) 每個(gè)service包括gateway都自帶了Hystrix提供的限流和熔斷功能 service之間通過(guò)feign和ribbon互相調(diào)用,feign實(shí)際上是屏蔽了service對(duì)erueka的操作
上文說(shuō)的一旦要融入異構(gòu)語(yǔ)言的service,那么服務(wù)注冊(cè),服務(wù)發(fā)現(xiàn),服務(wù)調(diào)用,熔斷和限流都需要自己處理。
再有關(guān)于zuul要多說(shuō)幾句,Sprin Cloud提供的zuul對(duì)Netflix版本的做了裁剪,去掉了動(dòng)態(tài)路由功能(Groovy實(shí)現(xiàn)),另外一點(diǎn)就是zuul的性能一般,由于采用同步編程模型,對(duì)于IO密集型等后臺(tái)處理時(shí)間長(zhǎng)的鏈路非常容易將servlet的線程池占滿,所以如果將zuul與主要service放置在同一臺(tái)物理機(jī)上,在流量大的情況下,zuul的資源消耗非常大。
實(shí)際測(cè)試也發(fā)現(xiàn)經(jīng)過(guò)zuul與直接調(diào)用service的性能損失在30%左右,并發(fā)壓力大時(shí)更為明顯。現(xiàn)在spring cloud gateway是pivotal的主推了,支持異步編程模型,后續(xù)架構(gòu)優(yōu)化也許會(huì)采用,或是直接使用Kong這種基于nginx的網(wǎng)關(guān)來(lái)提供性能。當(dāng)然同步模型也有優(yōu)點(diǎn),編碼更簡(jiǎn)單,后文將會(huì)提到使用ThreadLocal如何建立鏈路跟蹤。
架構(gòu)改造
經(jīng)過(guò)大半年的改造以及新需求的加入,單體服務(wù)被不斷拆分,最終形成了10余個(gè)微服務(wù),并且搭建了Spark用于BI。初步形成兩大體系,微服務(wù)架構(gòu)的在線業(yè)務(wù)系統(tǒng)(OLTP) + Spark大數(shù)據(jù)分析系統(tǒng)(OLAP)。數(shù)據(jù)源從只有Mysql增加到了ES和Hive。多數(shù)據(jù)源之間的數(shù)據(jù)同步也是值得一說(shuō)的話題,但內(nèi)容太多不在此文贅述。
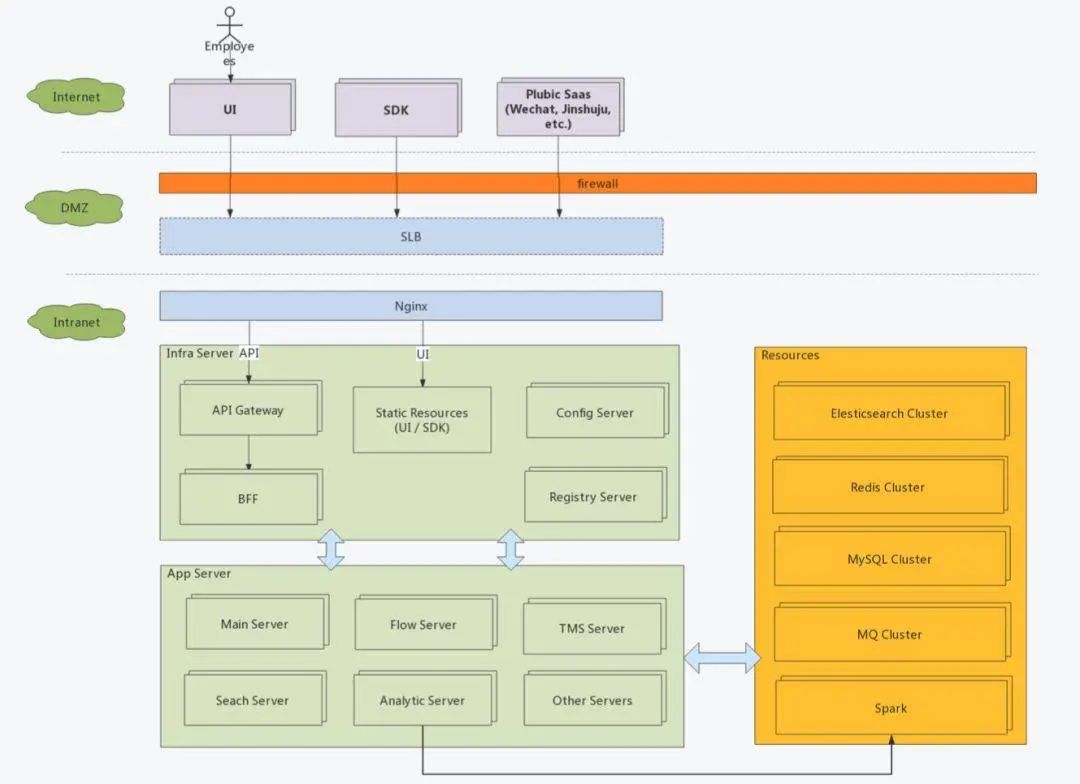
自動(dòng)化部署
與CI比起來(lái),持續(xù)交付(CD)實(shí)現(xiàn)更為復(fù)雜,在資源不足的情況我們尚未實(shí)現(xiàn)CD,只是實(shí)現(xiàn)執(zhí)行了自動(dòng)化部署。
由于生產(chǎn)環(huán)境需要通過(guò)跳板機(jī)操作,所以我們通過(guò)Jenkins生成jar包傳輸?shù)教鍣C(jī),之后再通過(guò)Ansible部署到集群。
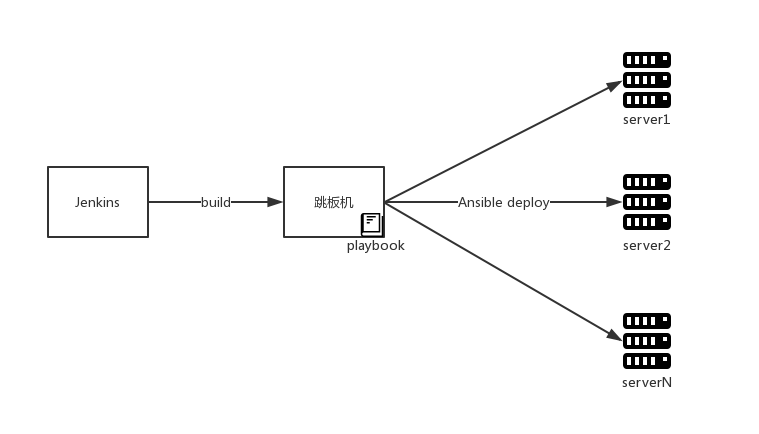
簡(jiǎn)單粗暴的部署方式在小規(guī)模團(tuán)隊(duì)開(kāi)發(fā)時(shí)還是夠用的,只是需要在部署前保證測(cè)試(人工測(cè)試 + 自動(dòng)化測(cè)試)到位。
鏈路跟蹤
開(kāi)源的全鏈路跟蹤很多,比如spring cloud sleuth + zipkin,國(guó)內(nèi)有美團(tuán)的CAT等等。其目的就是當(dāng)一個(gè)請(qǐng)求經(jīng)過(guò)多個(gè)服務(wù)時(shí),可以通過(guò)一個(gè)固定值獲取整條請(qǐng)求鏈路的行為日志,基于此可以再進(jìn)行耗時(shí)分析等,衍生出一些性能診斷的功能。不過(guò)對(duì)于我們而言,首要目的就是trouble shooting,出了問(wèn)題需要快速定位異常出現(xiàn)在什么服務(wù),整個(gè)請(qǐng)求的鏈路是怎樣的。
為了讓解決方案輕量,我們?cè)谌罩局写蛴equestId以及TraceId來(lái)標(biāo)記鏈路。RequestId在gateway生成表示唯一一次請(qǐng)求,TraceId相當(dāng)于二級(jí)路徑,一開(kāi)始與RequestId一樣,但進(jìn)入線程池或者消息隊(duì)列后,TraceId會(huì)增加標(biāo)記來(lái)標(biāo)識(shí)唯一條路徑。
舉個(gè)例子,當(dāng)一次請(qǐng)求會(huì)向MQ發(fā)送一個(gè)消息,那么這個(gè)消息可能會(huì)被多個(gè)消費(fèi)者消費(fèi),此時(shí)每個(gè)消費(fèi)線程都會(huì)自己生成一個(gè)TraceId來(lái)標(biāo)記消費(fèi)鏈路。加入TraceId的目的就是為了避免只用RequestId過(guò)濾出太多日志。實(shí)現(xiàn)如圖所示,
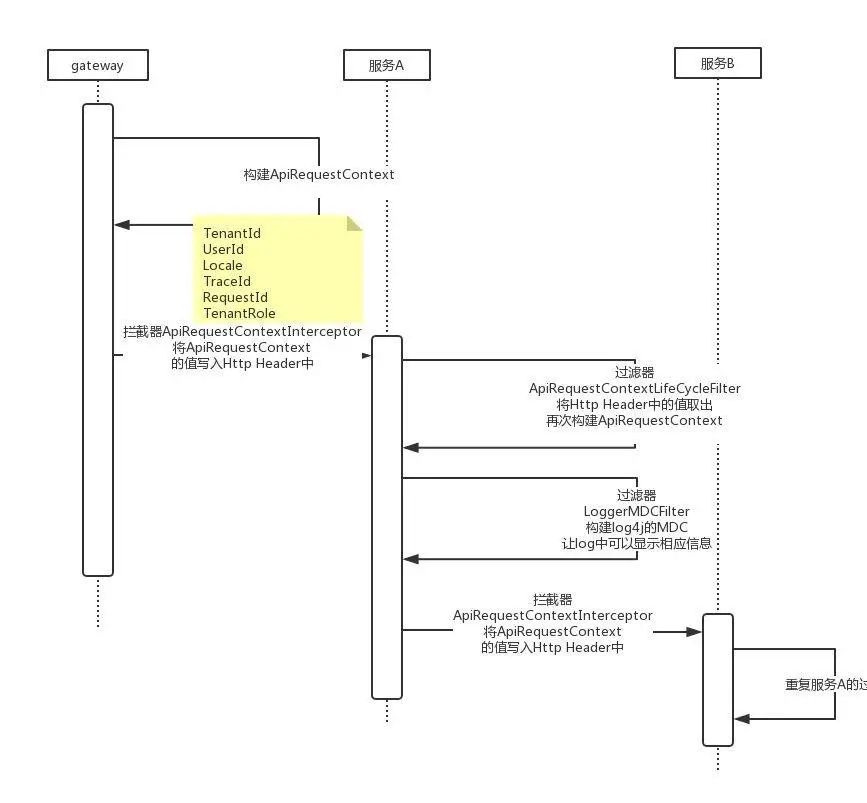
簡(jiǎn)單的說(shuō),通過(guò)ThreadLocal存放APIRequestContext串聯(lián)單服務(wù)內(nèi)的所有調(diào)用,當(dāng)跨服務(wù)調(diào)用時(shí),將APIRequestContext信息轉(zhuǎn)化為Http Header,被調(diào)用方獲取到Http Header后再次構(gòu)建APIRequestContext放入ThreadLocal,重復(fù)循環(huán)保證RequestId和TraceId不丟失即可。如果進(jìn)入MQ,那么APIRequestContext信息轉(zhuǎn)化為Message Header即可(基于Rabbitmq實(shí)現(xiàn))。
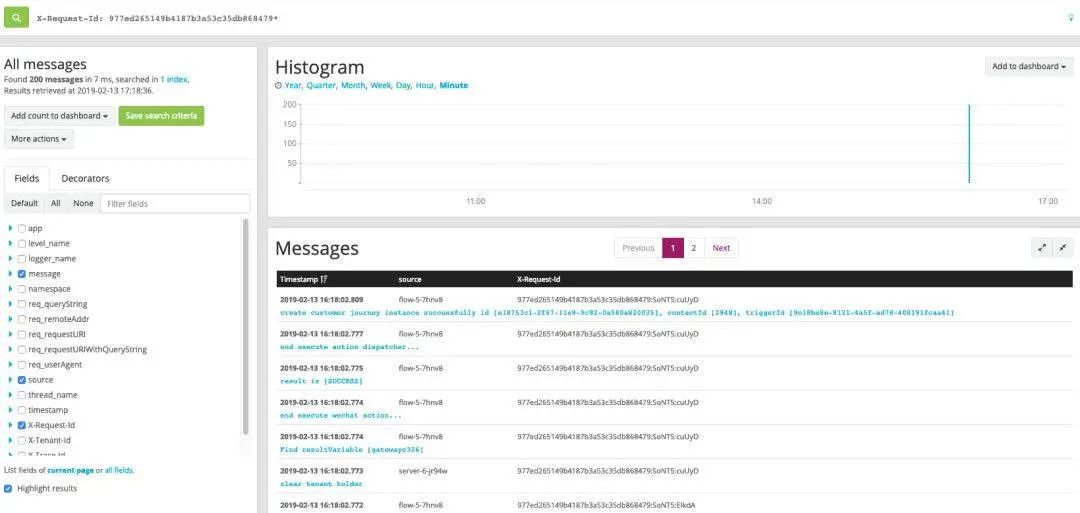
當(dāng)日志匯總到日志系統(tǒng)后,如果出現(xiàn)問(wèn)題,只需要捕獲發(fā)生異常的RequestId或是TraceId即可進(jìn)行問(wèn)題定位
運(yùn)維監(jiān)控
在容器化之前,采用telegraf + influxdb + grafana的方案。telegraf作為探針收集jvm,system,mysql等資源的信息,寫入influxdb,最終通過(guò)grafana做數(shù)據(jù)可視化。spring boot actuator可以配合jolokia暴露jvm的endpoint。整個(gè)方案零編碼,只需要花時(shí)間配置。
容器化時(shí)代
架構(gòu)改造
因?yàn)樵谧鑫⒎?wù)之初就計(jì)劃了容器化,所以架構(gòu)并未大動(dòng),只是每個(gè)服務(wù)都會(huì)建立一個(gè)Dockerfile用于創(chuàng)建docker image
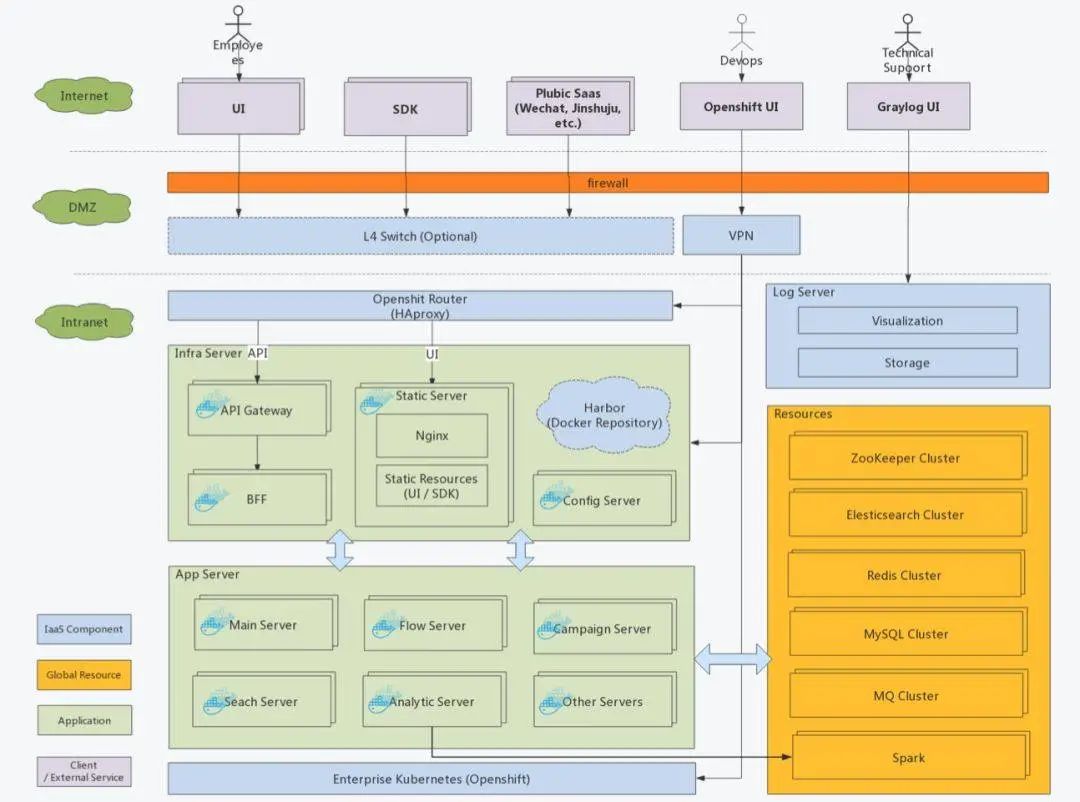
涉及變化的部分包括:
CI中多了構(gòu)建docker image的步驟 自動(dòng)化測(cè)試過(guò)程中將數(shù)據(jù)庫(kù)升級(jí)從應(yīng)用中剝離單獨(dú)做成docker image 生產(chǎn)中用k8s自帶的service替代了eruka
理由下文一一道來(lái)。
Spring Cloud與k8s的融合
我們使用的是Redhat的Openshift,可以認(rèn)為是k8s企業(yè)版,其本身就有service的概念。一個(gè)service下有多個(gè)pod,pod內(nèi)即是一個(gè)可服務(wù)單元。service之間互相調(diào)用時(shí)k8s會(huì)提供默認(rèn)的負(fù)載均衡控制,發(fā)起調(diào)用方只需要寫被調(diào)用方的serviceId即可。這一點(diǎn)和spring cloud fegin使用ribbon提供的功能如出一轍。
也就是說(shuō)服務(wù)治理可以通過(guò)k8s來(lái)解決,那么為什么要替換呢?其實(shí)上文提到了,Spring Cloud技術(shù)棧對(duì)于異構(gòu)語(yǔ)言的支持問(wèn)題,我們有許多BFF(Backend for Frontend)是使用nodejs實(shí)現(xiàn)的,這些服務(wù)要想融合到Spring Cloud中,服務(wù)注冊(cè),負(fù)載均衡,心跳檢查等等都要自己實(shí)現(xiàn)。
如果以后還有其他語(yǔ)言架構(gòu)的服務(wù)加入進(jìn)來(lái),這些輪子又要重造。基于此類原因綜合考量后,決定采用Openshift所提供的網(wǎng)絡(luò)能力替換eruka。
由于本地開(kāi)發(fā)和聯(lián)調(diào)過(guò)程中依然依賴eruka,所以只在生產(chǎn)上通過(guò)配置參數(shù)來(lái)控制,
eureka.client.enabled`?設(shè)置為?false,停止各服務(wù)的eureka注冊(cè)
`ribbon.eureka.enabled`?設(shè)置為?false,讓ribbon不從eureka獲取服務(wù)列表
以服務(wù)foo為例,`foo.ribbon.listofservers`?設(shè)置為?`http://foo:8080`,那么當(dāng)一個(gè)服務(wù)需要使用服務(wù)foo的時(shí)候,就會(huì)直接調(diào)用到`http://foo:8080
CI的改造
CI的改造主要是多了一部編譯docker image并打包到Harbor的過(guò)程,部署時(shí)會(huì)直接從Harbor拉取鏡像。另一個(gè)就是數(shù)據(jù)庫(kù)的升級(jí)工具。之前我們使用flyway作為數(shù)據(jù)庫(kù)升級(jí)工具,當(dāng)應(yīng)用啟動(dòng)時(shí)自動(dòng)執(zhí)行SQL腳本。
隨著服務(wù)實(shí)例越來(lái)越多,一個(gè)服務(wù)的多個(gè)實(shí)例同時(shí)升級(jí)的情況也時(shí)有發(fā)生,雖然flyway是通過(guò)數(shù)據(jù)庫(kù)鎖實(shí)現(xiàn)了升級(jí)過(guò)程不會(huì)有并發(fā),但會(huì)導(dǎo)致被鎖服務(wù)啟動(dòng)時(shí)間變長(zhǎng)的問(wèn)題。
從實(shí)際升級(jí)過(guò)程來(lái)看,將可能發(fā)生的并發(fā)升級(jí)變?yōu)閱我贿M(jìn)程可能更靠譜。此外后期分庫(kù)分表的架構(gòu)也會(huì)使隨應(yīng)用啟動(dòng)自動(dòng)升級(jí)數(shù)據(jù)庫(kù)變的困難。綜合考量,我們將升級(jí)任務(wù)做了拆分,每個(gè)服務(wù)都有自己的升級(jí)項(xiàng)目并會(huì)做容器化。
在使用時(shí),作為run once的工具來(lái)使用,即docker run -rm的方式。并且后續(xù)也支持了設(shè)定目標(biāo)版本的功能,在私有化項(xiàng)目的跨版本升級(jí)中起到了非常好的效果。
至于自動(dòng)部署,由于服務(wù)之間存在上下游關(guān)系,例如config,eureka等屬于基本服務(wù)被其他服務(wù)依賴,部署也產(chǎn)生了先后順序。基于Jenkins做pipeline可以很好的解決這個(gè)問(wèn)題。
小結(jié)
其實(shí)以上的每一點(diǎn)都可以深入的寫成一篇文章,微服務(wù)的架構(gòu)演進(jìn)涉及到開(kāi)發(fā),測(cè)試和運(yùn)維,要求團(tuán)隊(duì)內(nèi)多工種緊密合作。
分治是軟件行業(yè)解決大系統(tǒng)的不二法門,作為小團(tuán)隊(duì)我們并沒(méi)有盲目追新,而是在發(fā)展的過(guò)程通過(guò)服務(wù)化的方式解決問(wèn)題。
從另一方面我們也體會(huì)到了微服務(wù)對(duì)于人的要求,以及對(duì)于團(tuán)隊(duì)的挑戰(zhàn)都比過(guò)去要高要大。未來(lái)仍需探索,演進(jìn)仍在路上。
作者:Dean
來(lái)源:deanwangpro.com/2019/02/18/road-of-microservice
歡迎關(guān)注“Java引導(dǎo)者”,我們分享最有價(jià)值的Java的干貨文章,助力您成為有思想的Java開(kāi)發(fā)工程師!