
快過(guò)年了,來(lái)寫(xiě)首詩(shī)不?(一)
從短篇小說(shuō)到寫(xiě)5萬(wàn)字的小說(shuō),機(jī)器不斷涌現(xiàn)出前所未有的詞匯。在網(wǎng)頁(yè)上有大量的例子可供開(kāi)發(fā)人員使用機(jī)器學(xué)習(xí)來(lái)編寫(xiě)文本,呈現(xiàn)的效果有荒謬的也有令人嘆為觀(guān)止的。?由于自然語(yǔ)言處理(NLP)領(lǐng)域的重大進(jìn)步,機(jī)器能夠自己理解上下文和編造故事。文本生成的例子包括,機(jī)器編寫(xiě)了流行小說(shuō)的整個(gè)章節(jié),比如《權(quán)力的游戲》和《哈利波特》,取得了不同程度的成功。
現(xiàn)在,有大量的數(shù)據(jù)可以按順序分類(lèi)。它們以音頻、視頻、文本、時(shí)間序列、傳感器數(shù)據(jù)等形式存在。針對(duì)這樣特殊類(lèi)別的數(shù)據(jù),如果兩個(gè)事件都發(fā)生在特定的時(shí)間內(nèi),A先于B和B先于A是完全不同的兩個(gè)場(chǎng)景。然而,在傳統(tǒng)的機(jī)器學(xué)習(xí)問(wèn)題中,一個(gè)特定的數(shù)據(jù)點(diǎn)是否被記錄在另一個(gè)數(shù)據(jù)點(diǎn)之前是不重要的。這種考慮使我們的序列預(yù)測(cè)問(wèn)題有了新的解決方法。
文本是由一個(gè)挨著一個(gè)的字符組成的,實(shí)際中是很難處理的。這是因?yàn)樵谔幚砦谋緯r(shí),可以訓(xùn)練一個(gè)模型來(lái)使用之前發(fā)生的序列來(lái)做出非常準(zhǔn)確的預(yù)測(cè),但是之前的一個(gè)錯(cuò)誤的預(yù)測(cè)有可能使整個(gè)句子變得毫無(wú)意義。這就是讓文本生成器變得棘手的原因!?
詩(shī)詞生成思路

自然語(yǔ)言生成是自然語(yǔ)言處理里面最有意思的任務(wù)之一,本文中主要指古詩(shī)自動(dòng)寫(xiě)詩(shī)。文本生成通常包含以下步驟:1.導(dǎo)入依賴(lài) 2.加載數(shù)據(jù) 3.創(chuàng)建映射 4.數(shù)據(jù)預(yù)處理 5.模型構(gòu)建及訓(xùn)練 6.文本生成。
而在模型構(gòu)建中,我們使用了循環(huán)神經(jīng)網(wǎng)絡(luò)對(duì)輸入進(jìn)來(lái)的詩(shī)詞序列進(jìn)行特征提取,并做出預(yù)測(cè)結(jié)果。具體思路如下:
?
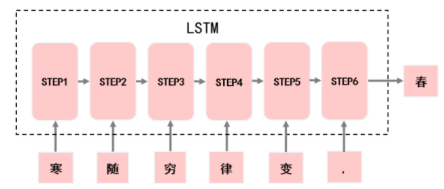
由前六個(gè)字預(yù)測(cè)出下一個(gè)字。
利用“寒隨窮律變,”預(yù)測(cè)出“春”。
?
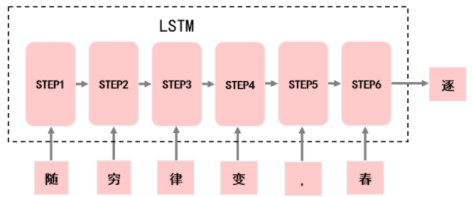
利用“隨窮律變,春”預(yù)測(cè)出“逐”。
?
然后利用這樣的方式去構(gòu)建循環(huán)神經(jīng)網(wǎng)絡(luò)即可一步一步地往下預(yù)測(cè),實(shí)現(xiàn)古詩(shī)創(chuàng)作,即:
?
寒隨窮律變, -> 春
隨窮律變,春 -> 逐
窮律變,春逐 -> 鳥(niǎo)
律變,春逐鳥(niǎo) -> 聲
變,春逐鳥(niǎo)聲 -> 開(kāi)
,春逐鳥(niǎo)聲開(kāi) -> 。
……
?
最終得到古詩(shī):寒隨窮律變,春逐鳥(niǎo)聲開(kāi)。初風(fēng)飄帶柳,晚雪間花梅。碧林青舊竹,綠沼翠新苔。芝田初雁去,綺樹(shù)巧鶯來(lái)。
數(shù)據(jù)集處理
數(shù)據(jù)集如下(回復(fù)‘詩(shī)詞生成’即可獲取數(shù)據(jù)),是一個(gè)大概4.3w首古詩(shī)的文本文件,我們需要對(duì)數(shù)據(jù)進(jìn)行處理,使之可以喂給模型進(jìn)行訓(xùn)練:

?
首先,我們定義一個(gè)LoadData.py函數(shù),然后導(dǎo)入依賴(lài),寫(xiě)入第一個(gè)函數(shù)load_file(),這個(gè)函數(shù)主要用來(lái)讀取數(shù)據(jù),并且對(duì)數(shù)據(jù)進(jìn)行切割和提取。
import numpy as npfrom collections import Counterimport os# from tensorflow.keras import utils# 讀取數(shù)據(jù)def load_file(path):res=''with open(path,'r',encoding='utf8') as f:for value in f:ones=value.strip().split(':')[1:][0]if len(ones.split(',')[0])==5:res+=ones+'0'return res
我們將調(diào)用一下這個(gè)函數(shù),并將結(jié)果保存到txt文件中,可以得到如下的文件,我們提取了五言絕句的詩(shī)詞,然后去掉了詩(shī)的名字,并在詩(shī)的末尾添加一個(gè)終止符’0’。
cont=load_file(path='poetry.txt')with open('cont.txt','w',encoding='utf8') as f:f.write(cont)

接著,我們需要制作詞典。詞典的意思就是說(shuō),在詩(shī)中的每一個(gè)中文都有對(duì)應(yīng)的索引。而后面我們喂給模型進(jìn)行訓(xùn)練的數(shù)據(jù)就是由這些索引組成的詩(shī)句。這里我們提取出現(xiàn)次數(shù)較多的前5000個(gè)詞作為詞典。
# 獲得詞典def get_wordDict(res,word_len=5000):words=sorted(list(res))word_dict=Counter(words)wordPairs = sorted(word_dict.items(), key=lambda x: -x[1])wordPairs=wordPairs[:word_len]wordlist=[]for w in wordPairs:wordlist.append(w[0]+'\n')with open('word_list.txt','w',encoding='utf8') as f:f.writelines(wordlist)
將load_file中的返回值輸入到get_wordDict()中,運(yùn)行結(jié)果如下,這就是我們制作好的字典。

接著,我們編寫(xiě)一個(gè)函數(shù)get_data(),用來(lái)獲得完整的詩(shī)句以及我們剛剛提取的詞典:
# 獲得完整的詩(shī)句,以及詞典def get_data():res=load_file('poetry.txt')if not os.path.isfile('word_list.txt'):wordlist=get_wordDict(res)with open('word_list.txt','r',encoding='utf8')as f:wordlist=[i.strip() for i in f.readlines()]res_list=res.split('0')return res_list,wordlist
然后,編寫(xiě)函數(shù)get_index(),用來(lái)循環(huán)每一首詩(shī)句,并提取出我們想要的 6個(gè)字符預(yù)測(cè)一個(gè)字符的格式。
# 獲得數(shù)據(jù)def get_index(cont,wordlist,num_classes):# 將中文轉(zhuǎn)換成索引cont_index=[wordlist.index(i) if i in wordlist elsewordlist.index('z') for i in cont]data=[]label=[]#for i in range(len(cont_index)):if i < len(cont_index)-6:data.append(cont_index[i:i+6])label.append([cont_index[i+6]])print(cont_index[i:i+6],'==>'[cont_index[i+6]])return data,label
?
我們調(diào)用一下這個(gè)函數(shù),cont是一首完整的詩(shī),而wordlist是字典。輸出的結(jié)果如下,這是我們想要的格式:

接著,我們還要進(jìn)行獨(dú)熱編碼,將數(shù)據(jù)與標(biāo)簽都變成獨(dú)熱編碼的形式:
def one_host(data,num_classes,batch_size):array=np.zeros((batch_size,len(data[0]),num_classes))m=len(data)for i in range(m):for index,value in enumerate(data[i]):array[i,index,int(value)]=1.return array
最后,我們把數(shù)據(jù)組裝成生成器的形式,這可以讓我們一邊訓(xùn)練一邊加載數(shù)據(jù)。避免內(nèi)存溢出的情況,具體代碼如下:
# 將數(shù)據(jù)組裝成生成器def gen_data(cont,wordlist,batch_size=1,num_classes=5000):# 使用循環(huán)一直讀取數(shù)據(jù)while True:x_data=[]y_data=[]# 讀取每一首詩(shī)for i in cont:# 獲取詩(shī)的索引并將每首詩(shī)組裝成 6-》1的形式。返回值都是數(shù)組=get_index(i,wordlist,num_classes=num_classes)=(data)=(label)# 當(dāng)長(zhǎng)度大于批次大小時(shí)if len(x_data)>batch_size:x=x_data[:batch_size]y=y_data[:batch_size]# 對(duì)數(shù)據(jù)進(jìn)行獨(dú)熱編碼x=one_host(x,num_classes,batch_size)y=one_host(y,num_classes,batch_size)x=np.array(x).reshape(-1,6,num_classes)y=np.array(y).reshape(-1,num_classes)# 懶加載yield x,y# 保證詩(shī)的完整性x_data=x_data[batch_size:]y_data=y_data[batch_size:]
這樣,一個(gè)數(shù)據(jù)生成器就制作好了,我們可以使用如下的方式來(lái)確認(rèn)生成數(shù)據(jù)的準(zhǔn)確性:
cont,wordlist=get_data()# 每個(gè)批次16條數(shù)據(jù)gan=gen_data(cont,wordlist,16)for i in range(1):x,y=next(gan)print(np.argmax(x,axis=-1),np.argmax(y,axis=-1))
程序運(yùn)行的結(jié)果如下:
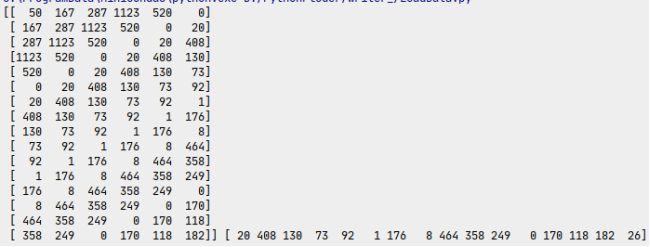
和我們想要的數(shù)據(jù)格式是一致的。
寒隨窮律變, -> 春
隨窮律變,春 -> 逐
窮律變,春逐 -> 鳥(niǎo)
律變,春逐鳥(niǎo) -> 聲
變,春逐鳥(niǎo)聲 -> 開(kāi)
,春逐鳥(niǎo)聲開(kāi) -> 。
……
由于篇幅關(guān)系,訓(xùn)練步驟放在下篇
生成結(jié)果預(yù)覽
