
Zookeeper 思維導(dǎo)圖
常見相關(guān)問題
ZooKeeper 是什么?
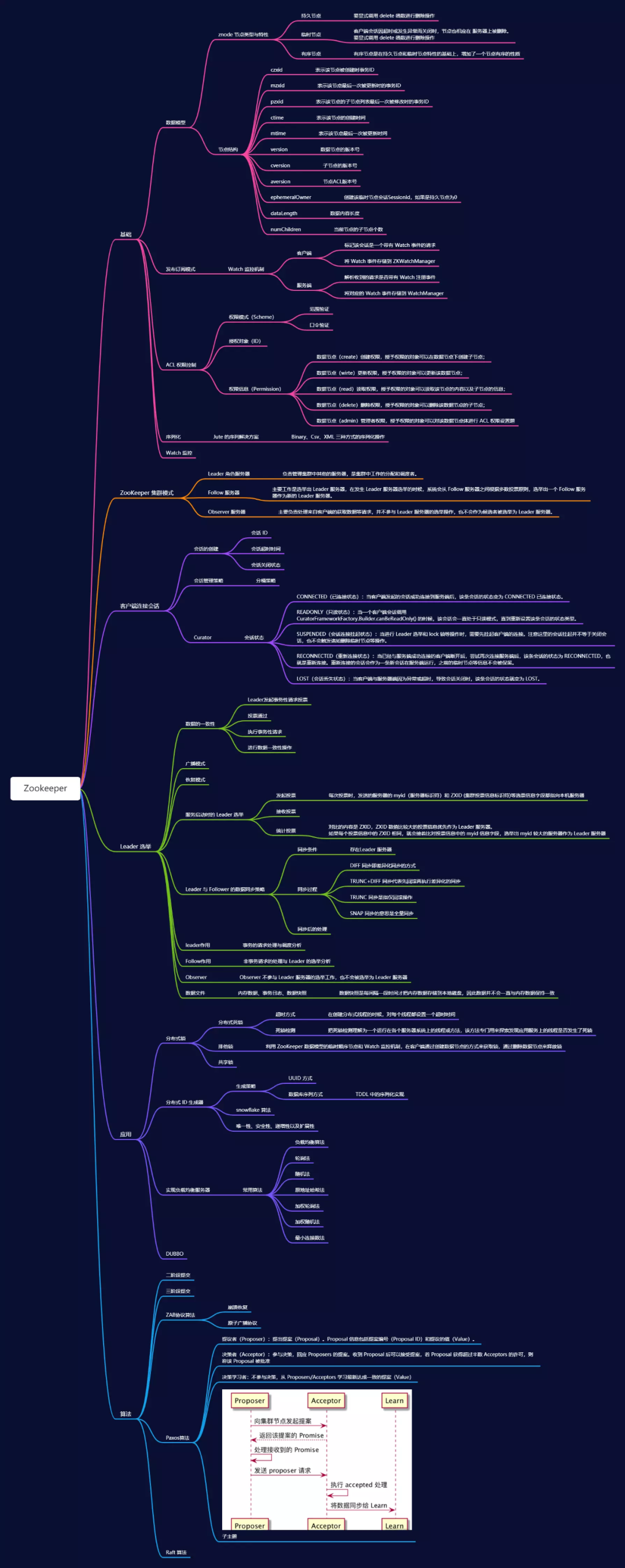
ZooKeeper 是一個分布式的,開放源碼的分布式應(yīng)用程序協(xié)調(diào)服務(wù),是Google 的 Chubby 一個開源的實現(xiàn),它是集群的管理者,監(jiān)視著集群中各個節(jié)點的狀態(tài)根據(jù)節(jié)點提交的反饋進(jìn)行下一步合理操作。最終,將簡單易用的接口和性能高效、功能穩(wěn)定的系統(tǒng)提供給用戶。客戶端的讀請求可以被集群中的任意一臺機(jī)器處理,如果讀請求在節(jié)點上注冊了監(jiān)聽器,這個監(jiān)聽器也是由所連接的zookeeper機(jī)器來處理。對于寫請求,這些請求會同時發(fā)給其他zookeeper機(jī)器并且達(dá)成一致后,請求才會返回成功。因此,隨著zookeeper的集群機(jī)器增多,讀請求的吞吐會提高但是寫請求的吞吐會下降。有序性是zookeeper中非常重要的一個特性,所有的更新都是全局有序的,每個更新都有一個唯一的時間戳,這個時間戳稱為zxid(Zookeeper Transaction Id)。而讀請求只會相對于更新有序,也就是讀請求的返回結(jié)果中會帶有這個zookeeper最新的zxid。
節(jié)點類型
PERSISTENT-持久化目錄節(jié)點 客戶端與zookeeper斷開連接后,該節(jié)點依舊存在 PERSISTENT_SEQUENTIAL-持久化順序編號目錄節(jié)點 客戶端與zookeeper斷開連接后,該節(jié)點依舊存在,只是Zookeeper給該節(jié)點名稱進(jìn)行順序編號 EPHEMERAL-臨時目錄節(jié)點 客戶端與zookeeper斷開連接后,該節(jié)點被刪除 EPHEMERAL_SEQUENTIAL-臨時順序編號目錄節(jié)點。客戶端與zookeeper斷開連接后,該節(jié)點被刪除,只是Zookeeper給該節(jié)點名稱進(jìn)行順序編號
集群模式
Leader 角色服務(wù)器負(fù)責(zé)管理集群中其他的服務(wù)器,是集群中工作的分配和調(diào)度者。 Follow 服務(wù)器的主要工作是選舉出 Leader 服務(wù)器,在發(fā)生 Leader 服務(wù)器選舉的時候,系統(tǒng)會從 Follow 服務(wù)器之間根據(jù)多數(shù)投票原則,選舉出一個 Follow 服務(wù)器作為新的 Leader 服務(wù)器。 Observer 服務(wù)器則主要負(fù)責(zé)處理來自客戶端的獲取數(shù)據(jù)等請求,并不參與 Leader 服務(wù)器的選舉操作,也不會作為候選者被選舉為 Leader 服務(wù)器。
Zookeeper工作原理
Zookeeper 下 Server工作狀態(tài)
LOOKING:當(dāng)前Server不知道leader是誰,正在搜尋
LEADING:當(dāng)前Server即為選舉出來的leader
FOLLOWING:leader已經(jīng)選舉出來,當(dāng)前Server與之同步
Zookeeper分布式鎖(文件系統(tǒng)、通知機(jī)制)
zookeeper是如何選取主leader的?
Zookeeper同步流程

評論
圖片
表情