
Flink狀態(tài)管理與狀態(tài)一致性(長文)
")
目錄
一、前言
二、狀態(tài)類型
2.1、Keyed State
2.2、Operator State
三、狀態(tài)橫向擴展
四、檢查點機制
4.1、開啟檢查點 (checkpoint)
4.2、保存點機制 (Savepoints)
五、狀態(tài)后端
5.1、狀態(tài)管理器分類
5.2、配置方式
六、狀態(tài)一致性
6.1、端到端(end-to-end)
6.2、Flink+Kafka的exactly-once
6.3、Kafka冪等性和事務(wù)
冪等性
事務(wù)
6.4 兩階段提交協(xié)議
一、前言
有狀態(tài)的計算是流處理框架要實現(xiàn)的重要功能,因為稍復(fù)雜的流處理場景都需要記錄狀態(tài),然后在新流入數(shù)據(jù)的基礎(chǔ)上不斷更新狀態(tài)。下面的幾個場景都需要使用流處理的狀態(tài)功能:
數(shù)據(jù)流中的數(shù)據(jù)有重復(fù),想對重復(fù)數(shù)據(jù)去重,需要記錄哪些數(shù)據(jù)已經(jīng)流入過應(yīng)用,當新數(shù)據(jù)流入時,根據(jù)已流入過的數(shù)據(jù)來判斷去重。
檢查輸入流是否符合某個特定的模式,需要將之前流入的元素以狀態(tài)的形式緩存下來。比如,判斷一個溫度傳感器數(shù)據(jù)流中的溫度是否在持續(xù)上升。
對一個時間窗口內(nèi)的數(shù)據(jù)進行聚合分析,分析一個小時內(nèi)某項指標的75分位或99分位的數(shù)值。
一個狀態(tài)更新和獲取的流程如下圖所示,一個算子子任務(wù)接收輸入流,獲取對應(yīng)的狀態(tài),根據(jù)新的計算結(jié)果更新狀態(tài)。一個簡單的例子是對一個時間窗口內(nèi)輸入流的某個整數(shù)字段求和,那么當算子子任務(wù)接收到新元素時,會獲取已經(jīng)存儲在狀態(tài)中的數(shù)值,然后將當前輸入加到狀態(tài)上,并將狀態(tài)數(shù)據(jù)更新。

二、狀態(tài)類型
Flink有兩種基本類型的狀態(tài):托管狀態(tài)(Managed State)和原生狀態(tài)(Raw State)。
兩者的區(qū)別:Managed State是由Flink管理的,F(xiàn)link幫忙存儲、恢復(fù)和優(yōu)化,Raw State是開發(fā)者自己管理的,需要自己序列化。
具體區(qū)別有:
從狀態(tài)管理的方式上來說,Managed State由Flink Runtime托管,狀態(tài)是自動存儲、自動恢復(fù)的,F(xiàn)link在存儲管理和持久化上做了一些優(yōu)化。當橫向伸縮,或者說修改Flink應(yīng)用的并行度時,狀態(tài)也能自動重新分布到多個并行實例上。Raw State是用戶自定義的狀態(tài)。
從狀態(tài)的數(shù)據(jù)結(jié)構(gòu)上來說,Managed State支持了一系列常見的數(shù)據(jù)結(jié)構(gòu),如ValueState、ListState、MapState等。Raw State只支持字節(jié),任何上層數(shù)據(jù)結(jié)構(gòu)需要序列化為字節(jié)數(shù)組。使用時,需要用戶自己序列化,以非常底層的字節(jié)數(shù)組形式存儲,F(xiàn)link并不知道存儲的是什么樣的數(shù)據(jù)結(jié)構(gòu)。
從具體使用場景來說,絕大多數(shù)的算子都可以通過繼承Rich函數(shù)類或其他提供好的接口類,在里面使用Managed State。Raw State是在已有算子和Managed State不夠用時,用戶自定義算子時使用。
對Managed State繼續(xù)細分,它又有兩種類型:Keyed State和Operator State。
為了自定義Flink的算子,可以重寫Rich Function接口類,比如RichFlatMapFunction。使用Keyed State時,通過重寫Rich Function接口類,在里面創(chuàng)建和訪問狀態(tài)。對于Operator State,還需進一步實現(xiàn)CheckpointedFunction接口。
2.1、Keyed State
Flink 為每個鍵值維護一個狀態(tài)實例,并將具有相同鍵的所有數(shù)據(jù),都分區(qū)到同一個算子任務(wù)中,這個任務(wù)會維護和處理這個key對應(yīng)的狀態(tài)。當任務(wù)處理一條數(shù)據(jù)時,它會自動將狀態(tài)的訪問范圍限定為當前數(shù)據(jù)的key。因此,具有相同key的所有數(shù)據(jù)都會訪問相同的狀態(tài)。
需要注意的是鍵控狀態(tài)只能在 KeyedStream 上進行使用,可以通過 stream.keyBy(…) 來得到 KeyedStream 。
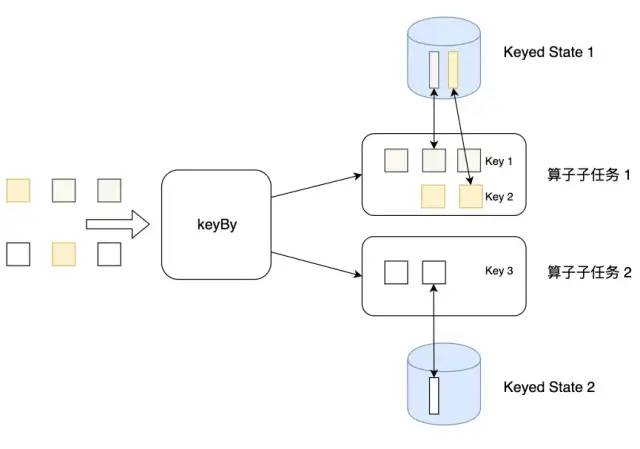
Flink 提供了以下數(shù)據(jù)格式來管理和存儲鍵控狀態(tài) (Keyed State):
ValueState:存儲單值類型的狀態(tài)。可以使用 update(T) 進行更新,并通過 T value() 進行檢索。
ListState:存儲列表類型的狀態(tài)。可以使用 add(T) 或 addAll(List) 添加元素,update(T)進行更新;并通過 get() 獲得整個列表。
ReducingState:用于存儲經(jīng)過 ReduceFunction 計算后的結(jié)果,使用 add(T) 增加元素。
AggregatingState:用于存儲經(jīng)過 AggregatingState 計算后的結(jié)果,使用 add(IN) 添加元素。
FoldingState:已被標識為廢棄,會在未來版本中移除,官方推薦使用 AggregatingState 代替。
MapState:維護 Map 類型的狀態(tài),get獲取,put更新,contains判斷包含,remove移除元素。
public class ListStateDemo extends RichFlatMapFunction<Tuple2<String, Long>,List<Tuple2<String, Long>>>{
private transient ListState<Tuple2<String, Long>> listState;
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
ListStateDescriptor<Tuple2<String, Long>> listStateDescriptor = new ListStateDescriptor(
"listState",
TypeInformation.of(new TypeHint<Tuple2<String, Long>>() {})
);
listState = getRuntimeContext().getListState(listStateDescriptor);
}
@Override
public void flatMap(Tuple2<String, Long> value, Collector<List<Tuple2<String, Long>>> out) throws Exception {
List<Tuple2<String, Long>> currentListState = Lists.newArrayList(listState.get().iterator());
currentListState.add(value);
listState.update(currentListState);
out.collect(currentListState);
}
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment senv = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<Tuple2<String, Long>> dataStream = senv.fromElements(
Tuple2.of("a", 50L),Tuple2.of("a", 60L),Tuple2.of("a", 70L),
Tuple2.of("b", 50L),Tuple2.of("b", 60L),Tuple2.of("b", 70L),
Tuple2.of("c", 50L),Tuple2.of("c", 60L),Tuple2.of("c", 70L)
);
dataStream
.keyBy(0)
.flatMap(new ListStateDemo())
.print();
senv.execute(ListStateDemo.class.getSimpleName());
}
}
2.2、Operator State
Operator State可以用在所有算子上,每個算子子任務(wù)或者說每個算子實例共享一個狀態(tài),流入這個算子子任務(wù)的數(shù)據(jù)可以訪問和更新這個狀態(tài)。
算子狀態(tài)不能由相同或不同算子的另一個實例訪問。
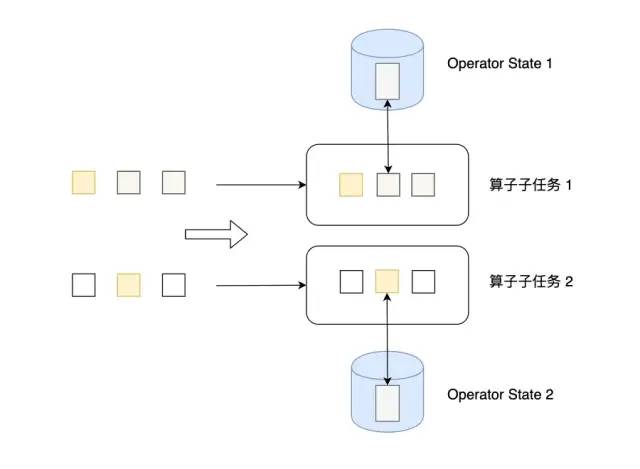
Flink為算子狀態(tài)提供三種基本數(shù)據(jù)結(jié)構(gòu):
ListState:存儲列表類型的狀態(tài)。
UnionListState:存儲列表類型的狀態(tài),與 ListState 的區(qū)別在于:如果并行度發(fā)生變化,ListState 會將該算子的所有并發(fā)的狀態(tài)實例進行匯總,然后均分給新的 Task;而 UnionListState 只是將所有并發(fā)的狀態(tài)實例匯總起來,具體的劃分行為則由用戶進行定義。
BroadcastState:用于廣播的算子狀態(tài)。如果一個算子有多項任務(wù),而它的每項任務(wù)狀態(tài)又都相同,那么這種特殊情況最適合應(yīng)用廣播狀態(tài)。
假設(shè)此時不需要區(qū)分監(jiān)控數(shù)據(jù)的類型,只要有監(jiān)控數(shù)據(jù)超過閾值并達到指定的次數(shù)后,就進行報警:
public class OperateStateDemo extends RichFlatMapFunction<Tuple2<String, Long>, List<Tuple2<String, Long>>>
implements CheckpointedFunction{
private final int threshold;
private transient ListState<Tuple2<String, Long>> checkpointedState;
private List<Tuple2<String, Long>> bufferedElements;
public OperateStateDemo(int threshold) {
this.threshold = threshold;
this.bufferedElements = new ArrayList<>();
}
@Override
public void flatMap(Tuple2<String, Long> value, Collector<List<Tuple2<String, Long>>> out) throws Exception {
bufferedElements.add(value);
if(bufferedElements.size() == threshold) {
out.collect(bufferedElements);
bufferedElements.clear();
}
}
/**
* 進行checkpoint快照
* @param context
* @throws Exception
*/
@Override
public void snapshotState(FunctionSnapshotContext context) throws Exception {
checkpointedState.clear();
for(Tuple2<String, Long> element : bufferedElements) {
checkpointedState.add(element);
}
}
@Override
public void initializeState(FunctionInitializationContext context) throws Exception {
ListStateDescriptor<Tuple2<String, Long>> listStateDescriptor = new ListStateDescriptor(
"listState",
TypeInformation.of(new TypeHint<Tuple2<String, Long>>() {})
);
checkpointedState = context.getOperatorStateStore().getListState(listStateDescriptor);
// 如果是故障恢復(fù)
if(context.isRestored()) {
for(Tuple2<String, Long> element : checkpointedState.get()) {
bufferedElements.add(element);
}
checkpointedState.clear();
}
}
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment senv = StreamExecutionEnvironment.getExecutionEnvironment();
senv.getCheckpointConfig().setCheckpointInterval(500);
DataStream<Tuple2<String, Long>> dataStream = senv.fromElements(
Tuple2.of("a", 50L),Tuple2.of("a", 60L),Tuple2.of("a", 70L),
Tuple2.of("b", 50L),Tuple2.of("b", 60L),Tuple2.of("b", 70L),
Tuple2.of("c", 50L),Tuple2.of("c", 60L),Tuple2.of("c", 70L)
);
dataStream
.flatMap(new OperateStateDemo(2))
.print();
senv.execute(OperateStateDemo.class.getSimpleName());
}
}
三、狀態(tài)橫向擴展
狀態(tài)的橫向擴展問題主要是指修改Flink應(yīng)用的并行度,確切的說,每個算子的并行實例數(shù)或算子子任務(wù)數(shù)發(fā)生了變化,應(yīng)用需要關(guān)停或啟動一些算子子任務(wù),某份在原來某個算子子任務(wù)上的狀態(tài)數(shù)據(jù)需要平滑更新到新的算子子任務(wù)上。
Flink的Checkpoint就是一個非常好的在各算子間遷移狀態(tài)數(shù)據(jù)的機制。算子的本地狀態(tài)將數(shù)據(jù)生成快照(snapshot),保存到分布式存儲(如HDFS)上。橫向伸縮后,算子子任務(wù)個數(shù)變化,子任務(wù)重啟,相應(yīng)的狀態(tài)從分布式存儲上重建(restore)。

對于Keyed State和Operator State這兩種狀態(tài),他們的橫向伸縮機制不太相同。由于每個Keyed State總是與某個Key相對應(yīng),當橫向伸縮時,Key總會被自動分配到某個算子子任務(wù)上,因此Keyed State會自動在多個并行子任務(wù)之間遷移。對于一個非KeyedStream,流入算子子任務(wù)的數(shù)據(jù)可能會隨著并行度的改變而改變。如上圖所示,假如一個應(yīng)用的并行度原來為2,那么數(shù)據(jù)會被分成兩份并行地流入兩個算子子任務(wù),每個算子子任務(wù)有一份自己的狀態(tài),當并行度改為3時,數(shù)據(jù)流被拆成3支,或者并行度改為1,數(shù)據(jù)流合并為1支,此時狀態(tài)的存儲也相應(yīng)發(fā)生了變化。對于橫向伸縮問題,Operator State有兩種狀態(tài)分配方式:一種是均勻分配,另一種是將所有狀態(tài)合并,再分發(fā)給每個實例上。
四、檢查點機制
為了使 Flink 的狀態(tài)具有良好的容錯性,F(xiàn)link 提供了檢查點機制 (CheckPoints) 。通過檢查點機制,F(xiàn)link 定期在數(shù)據(jù)流上生成 checkpoint barrier ,當某個算子收到 barrier 時,即會基于當前狀態(tài)生成一份快照,然后再將該 barrier 傳遞到下游算子,下游算子接收到該 barrier 后,也基于當前狀態(tài)生成一份快照,依次傳遞直至到最后的 Sink 算子上。當出現(xiàn)異常后,F(xiàn)link 就可以根據(jù)最近的一次的快照數(shù)據(jù)將所有算子恢復(fù)到先前的狀態(tài)。
4.1、開啟檢查點 (checkpoint)
默認情況下 checkpoint 是禁用的。通過調(diào)用 StreamExecutionEnvironment 的 enableCheckpointing(n) 來啟用 checkpoint,里面的 n 是進行 checkpoint 的間隔,單位毫秒。
Checkpoint是Flink實現(xiàn)容錯機制最核心的功能,它能夠根據(jù)配置周期性地基于Stream中各個Operator的狀態(tài)來生成Snapshot,從而將這些狀態(tài)數(shù)據(jù)定期持久化存儲下來,當Flink程序一旦意外崩潰時,重新運行程序時可以有選擇地從這些Snapshot進行恢復(fù),從而修正因為故障帶來的程序數(shù)據(jù)狀態(tài)中斷。這里,我們簡單理解一下Flink Checkpoint機制,如官網(wǎng)下圖所示:

Checkpoint指定觸發(fā)生成時間間隔后,每當需要觸發(fā)Checkpoint時,會向Flink程序運行時的多個分布式的Stream Source中插入一個Barrier標記,這些Barrier會根據(jù)Stream中的數(shù)據(jù)記錄一起流向下游的各個Operator。當一個Operator接收到一個Barrier時,它會暫停處理Steam中新接收到的數(shù)據(jù)記錄。因為一個Operator可能存在多個輸入的Stream,而每個Stream中都會存在對應(yīng)的Barrier,該Operator要等到所有的輸入Stream中的Barrier都到達。當所有Stream中的Barrier都已經(jīng)到達該Operator,這時所有的Barrier在時間上看來是同一個時刻點(表示已經(jīng)對齊),在等待所有Barrier到達的過程中,Operator的Buffer中可能已經(jīng)緩存了一些比Barrier早到達Operator的數(shù)據(jù)記錄(Outgoing Records),這時該Operator會將數(shù)據(jù)記錄(Outgoing Records)發(fā)射(Emit)出去,作為下游Operator的輸入,最后將Barrier對應(yīng)Snapshot發(fā)射(Emit)出去作為此次Checkpoint的結(jié)果數(shù)據(jù)。
Checkpoint 其他的屬性包括:
精確一次(exactly-once)對比至少一次(at-least-once):你可以選擇向 enableCheckpointing(long interval, CheckpointingMode mode) 方法中傳入一個模式來選擇使用兩種保證等級中的哪一種。對于大多數(shù)應(yīng)用來說,精確一次是較好的選擇。至少一次可能與某些延遲超低(始終只有幾毫秒)的應(yīng)用的關(guān)聯(lián)較大。
checkpoint 超時:如果 checkpoint 執(zhí)行的時間超過了該配置的閾值,還在進行中的 checkpoint 操作就會被拋棄。
checkpoints 之間的最小時間:該屬性定義在 checkpoint 之間需要多久的時間,以確保流應(yīng)用在 checkpoint 之間有足夠的進展。如果值設(shè)置為了 5000,無論 checkpoint 持續(xù)時間與間隔是多久,在前一個 checkpoint 完成時的至少五秒后會才開始下一個 checkpoint。
并發(fā) checkpoint 的數(shù)目: 默認情況下,在上一個 checkpoint 未完成(失敗或者成功)的情況下,系統(tǒng)不會觸發(fā)另一個 checkpoint。這確保了拓撲不會在 checkpoint 上花費太多時間,從而影響正常的處理流程。不過允許多個 checkpoint 并行進行是可行的,對于有確定的處理延遲(例如某方法所調(diào)用比較耗時的外部服務(wù)),但是仍然想進行頻繁的 checkpoint 去最小化故障后重跑的 pipelines 來說,是有意義的。
externalized checkpoints: 你可以配置周期存儲 checkpoint 到外部系統(tǒng)中。Externalized checkpoints 將他們的元數(shù)據(jù)寫到持久化存儲上并且在 job 失敗的時候不會被自動刪除。這種方式下,如果你的 job 失敗,你將會有一個現(xiàn)有的 checkpoint 去恢復(fù)。更多的細節(jié)請看 Externalized checkpoints 的部署文檔。
在 checkpoint 出錯時使 task 失敗或者繼續(xù)進行 task:他決定了在 task checkpoint 的過程中發(fā)生錯誤時,是否使 task 也失敗,使失敗是默認的行為。或者禁用它時,這個任務(wù)將會簡單的把 checkpoint 錯誤信息報告給 checkpoint coordinator 并繼續(xù)運行。
優(yōu)先從 checkpoint 恢復(fù)(prefer checkpoint for recovery):該屬性確定 job 是否在最新的 checkpoint 回退,即使有更近的 savepoint 可用,這可以潛在地減少恢復(fù)時間(checkpoint 恢復(fù)比 savepoint 恢復(fù)更快)。
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 每 1000ms 開始一次 checkpoint
env.enableCheckpointing(1000);
// 高級選項:
// 設(shè)置模式為精確一次 (這是默認值)
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
// 確認 checkpoints 之間的時間會進行 500 ms
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(500);
// Checkpoint 必須在一分鐘內(nèi)完成,否則就會被拋棄
env.getCheckpointConfig().setCheckpointTimeout(60000);
// 同一時間只允許一個 checkpoint 進行
env.getCheckpointConfig().setMaxConcurrentCheckpoints(1);
// 開啟在 job 中止后仍然保留的 externalized checkpoints
env.getCheckpointConfig().enableExternalizedCheckpoints(ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
// 允許在有更近 savepoint 時回退到 checkpoint
env.getCheckpointConfig().setPreferCheckpointForRecovery(true);
保存多個Checkpoint
默認情況下,如果設(shè)置了Checkpoint選項,則Flink只保留最近成功生成的1個Checkpoint,而當Flink程序失敗時,可以從最近的這個Checkpoint來進行恢復(fù)。但是,如果我們希望保留多個Checkpoint,并能夠根據(jù)實際需要選擇其中一個進行恢復(fù),這樣會更加靈活,比如,我們發(fā)現(xiàn)最近4個小時數(shù)據(jù)記錄處理有問題,希望將整個狀態(tài)還原到4小時之前。
Flink可以支持保留多個Checkpoint,需要在Flink的配置文件conf/flink-conf.yaml中,添加如下配置,指定最多需要保存Checkpoint的個數(shù):
state.checkpoints.num-retained: 20
保留了最近的20個Checkpoint。如果希望會退到某個Checkpoint點,只需要指定對應(yīng)的某個Checkpoint路徑即可實現(xiàn)。

從Checkpoint進行恢復(fù)
從指定的checkpoint處啟動,最近的一個/flink/checkpoints/workFlowCheckpoint/339439e2a3d89ead4d71ae3816615281/chk-1740584啟動,通常需要先停掉當前運行的flink-session,然后通過命令啟動:
../bin/flink run -p 10 -s /flink/checkpoints/workFlowCheckpoint/339439e2a3d89ead4d71ae3816615281/chk-1740584/_metadata -c com.code2144.helper_wink-1.0-SNAPSHOT.jar
可以把命令放到腳本里面,每次直接執(zhí)行checkpoint恢復(fù)腳本即可:

4.2、保存點機制 (Savepoints)
保存點機制 (Savepoints)是檢查點機制的一種特殊的實現(xiàn),它允許通過手工的方式來觸發(fā) Checkpoint,并將結(jié)果持久化存儲到指定路徑中,主要用于避免 Flink 集群在重啟或升級時導(dǎo)致狀態(tài)丟失。示例如下:
# 觸發(fā)指定id的作業(yè)的Savepoint,并將結(jié)果存儲到指定目錄下
bin/flink savepoint :jobId [:targetDirectory]
手動savepoint
/app/local/flink-1.6.2/bin/flink savepoint 0409251eaff826ef2dd775b6a2d5e219 [hdfs://bigdata/path]
成功觸發(fā)savepoint通常會提示:Savepoint completed. Path: hdfs://path...:

手動取消任務(wù)
與checkpoint異常停止或者手動Kill掉不一樣,對于savepoint通常是我們想要手動停止任務(wù),然后更新代碼,可以使用flink cancel ...命令:
/app/local/flink-1.6.2/bin/flink cancel 0409251eaff826ef2dd775b6a2d5e219
從指定savepoint啟動job
bin/flink run -p 8 -s hdfs:///flink/savepoints/savepoint-567452-9e3587e55980 -c com.code2144.helper_workflow.HelperWorkFlowStreaming jars/BSS-ONSS-Flink-1.0-SNAPSHOT.jar
五、狀態(tài)后端
Flink 提供了多種 state backends,它用于指定狀態(tài)的存儲方式和位置。
狀態(tài)可以位于 Java 的堆或堆外內(nèi)存。取決于 state backend,F(xiàn)link 也可以自己管理應(yīng)用程序的狀態(tài)。為了讓應(yīng)用程序可以維護非常大的狀態(tài),F(xiàn)link 可以自己管理內(nèi)存(如果有必要可以溢寫到磁盤)。默認情況下,所有 Flink Job 會使用配置文件 flink-conf.yaml 中指定的 state backend。
但是,配置文件中指定的默認 state backend 會被 Job 中指定的 state backend 覆蓋。
5.1、狀態(tài)管理器分類
MemoryStateBackend
默認的方式,即基于 JVM 的堆內(nèi)存進行存儲,主要適用于本地開發(fā)和調(diào)試。
FsStateBackend
基于文件系統(tǒng)進行存儲,可以是本地文件系統(tǒng),也可以是 HDFS 等分布式文件系統(tǒng)。需要注意而是雖然選擇使用了 FsStateBackend ,但正在進行的數(shù)據(jù)仍然是存儲在 TaskManager 的內(nèi)存中的,只有在 checkpoint 時,才會將狀態(tài)快照寫入到指定文件系統(tǒng)上。
RocksDBStateBackend
RocksDBStateBackend 是 Flink 內(nèi)置的第三方狀態(tài)管理器,采用嵌入式的 key-value 型數(shù)據(jù)庫 RocksDB 來存儲正在進行的數(shù)據(jù)。等到 checkpoint 時,再將其中的數(shù)據(jù)持久化到指定的文件系統(tǒng)中,所以采用 RocksDBStateBackend 時也需要配置持久化存儲的文件系統(tǒng)。之所以這樣做是因為 RocksDB 作為嵌入式數(shù)據(jù)庫安全性比較低,但比起全文件系統(tǒng)的方式,其讀取速率更快;比起全內(nèi)存的方式,其存儲空間更大,因此它是一種比較均衡的方案。
5.2、配置方式
Flink 支持使用兩種方式來配置后端管理器:
第一種方式:基于代碼方式進行配置,只對當前作業(yè)生效:
// 配置 FsStateBackend
env.setStateBackend(new FsStateBackend("hdfs://namenode:40010/flink/checkpoints"));
// 配置 RocksDBStateBackend
env.setStateBackend(new RocksDBStateBackend("hdfs://namenode:40010/flink/checkpoints"));
配置 RocksDBStateBackend 時,需要額外導(dǎo)入下面的依賴:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-statebackend-rocksdb_2.11</artifactId>
<version>1.9.0</version>
</dependency>
第二種方式:基于 flink-conf.yaml 配置文件的方式進行配置,對所有部署在該集群上的作業(yè)都生效:
state.backend: filesystem
state.checkpoints.dir: hdfs://namenode:40010/flink/checkpoints
六、狀態(tài)一致性
6.1、端到端(end-to-end)
在真實應(yīng)用中,流處理應(yīng)用除了流處理器以外還包含了數(shù)據(jù)源(例如 Kafka)和輸出到持久化系統(tǒng)。
端到端的一致性保證,意味著結(jié)果的正確性貫穿了整個流處理應(yīng)用的始終;每一個組件都保證了它自己的一致性,整個端到端的一致性級別取決于所有組件中一致性最弱的組件。具體可以劃分如下:
內(nèi)部保證:依賴checkpoint
source 端:需要外部源可重設(shè)數(shù)據(jù)的讀取位置
sink 端:需要保證從故障恢復(fù)時,數(shù)據(jù)不會重復(fù)寫入外部系統(tǒng)。
而對于sink端,又有兩種具體的實現(xiàn)方式:冪等(Idempotent)寫入:所謂冪等操作,是說一個操作,可以重復(fù)執(zhí)行很多次,但只導(dǎo)致一次結(jié)果更改,也就是說,后面再重復(fù)執(zhí)行就不起作用了。
事務(wù)性(Transactional)寫入:需要構(gòu)建事務(wù)來寫入外部系統(tǒng),構(gòu)建的事務(wù)對應(yīng)著 checkpoint,等到 checkpoint 真正完成的時候,才把所有對應(yīng)的結(jié)果寫入 sink 系統(tǒng)中。
對于事務(wù)性寫入,具體又有兩種實現(xiàn)方式:預(yù)寫日志(WAL)和兩階段提交(2PC)。Flink DataStream API 提供了GenericWriteAheadSink 模板類和 TwoPhaseCommitSinkFunction 接口,可以方便地實現(xiàn)這兩種方式的事務(wù)性寫入。
6.2、Flink+Kafka 實現(xiàn)端到端的 exactly-once語義
端到端的狀態(tài)一致性的實現(xiàn),需要每一個組件都實現(xiàn),對于Flink + Kafka的數(shù)據(jù)管道系統(tǒng)(Kafka進、Kafka出)而言,各組件怎樣保證exactly-once語義呢?
內(nèi)部:利用checkpoint機制,把狀態(tài)存盤,發(fā)生故障的時候可以恢復(fù),保證內(nèi)部的狀態(tài)一致性
source:kafka consumer作為source,可以將偏移量保存下來,如果后續(xù)任務(wù)出現(xiàn)了故障,恢復(fù)的時候可以由連接器重置偏移量,重新消費數(shù)據(jù),保證一致性
sink:kafka producer作為sink,采用兩階段提交 sink,需要實現(xiàn)一個TwoPhaseCommitSinkFunction內(nèi)部的checkpoint機制。
EXACTLY_ONCE語義簡稱EOS,指的是每條輸入消息只會影響最終結(jié)果一次,注意這里是影響一次,而非處理一次,F(xiàn)link一直宣稱自己支持EOS,實際上主要是對于Flink應(yīng)用內(nèi)部來說的,對于外部系統(tǒng)(端到端)則有比較強的限制
外部系統(tǒng)寫入支持冪等性
外部系統(tǒng)支持以事務(wù)的方式寫入
Kafka在0.11版本之前只能保證At-Least-Once或At-Most-Once語義,從0.11版本開始,引入了冪等發(fā)送和事務(wù),從而開始保證EXACTLY_ONCE語義。
| Maven依賴 | 開始支持的版本 | 生產(chǎn)/消費 類名 | kafka版本 | 注意 |
|---|---|---|---|---|
| flink-connector-kafka-0.8_2.11 | 1.0.0 | FlinkKafkaConsumer08 FlinkKafkaProducer08 | 0.8.x | 使用Kafka內(nèi)部SimpleConsumer API. Flink把Offsets提交到ZK |
| flink-connector-kafka-0.9_2.11 | 1.0.0 | FlinkKafkaConsumer09 FlinkKafkaProducer09 | 0.9.x | 使用新版Kafka Consumer API. |
| flink-connector-kafka-0.10_2.11 | 1.2.0 | FlinkKafkaConsumer010 FlinkKafkaProducer010 | 0.10.x | 支持Kafka生產(chǎn)/消費消息帶時間戳 |
| flink-connector-kafka-0.11_2.11 | 1.4.0 | FlinkKafkaConsumer011 FlinkKafkaProducer011 | 0.11.x | 由于0.11.x Kafka不支持scala 2.10。此連接器支持Kafka事務(wù)消息傳遞,以便為生產(chǎn)者提供exactly once語義。 |
flink-connector-kafka_2.11 | 1.7.0 | FlinkKafkaConsumer FlinkKafkaProducer | >=1.0.0 | 高版本向后兼容。但是,對于Kafka 0.11.x和0.10.x版本,我們建議分別使用專用的flink-connector-Kafka-0.11_2.11和link-connector-Kafka-0.10_2.11 |
Flink在1.4.0版本引入了TwoPhaseCommitSinkFunction接口,封裝了兩階段提交邏輯,并在Kafka Sink connector中實現(xiàn)了TwoPhaseCommitSinkFunction,依賴Kafka版本為0.11+
public class FlinkKafkaDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment senv = StreamExecutionEnvironment.getExecutionEnvironment();
senv.enableCheckpointing(1000);
senv.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
// kafka 數(shù)據(jù)源
Map<String, String> config = Configuration.initConfig("commons.xml");
Properties kafkaProps = new Properties();
kafkaProps.setProperty("bootstrap.servers", config.get("kafka-ipport"));
kafkaProps.setProperty("group.id", config.get("kafka-groupid"));
SingleOutputStreamOperator<String> dataStream = senv.addSource(
new FlinkKafkaConsumer011(
config.get("kafka-topic"),
new SimpleStringSchema(),
kafkaProps
));
// sink 到 kafka
FlinkKafkaProducer011<String> producer011 = new FlinkKafkaProducer011<>(
config.get("kafka-ipport"),
"test-kafka-producer",
new SimpleStringSchema());
producer011.setWriteTimestampToKafka(true);
dataStream.map(x -> {
// 拋出異常
if("name4".equals(JSON.parseObject(x).get("name"))){
System.out.println("name4 exception test...");
// throw new RuntimeException("name4 exception test...");
}
return x;
}).addSink(producer011);
senv.execute(FlinkKafkaDemo.class.getSimpleName());
}
}
Flink由JobManager協(xié)調(diào)各個TaskManager進行checkpoint存儲,checkpoint保存在 StateBackend中,默認StateBackend是內(nèi)存級的,也可以改為文件級的進行持久化保存。

當 checkpoint 啟動時,JobManager 會將檢查點分界線(barrier)注入數(shù)據(jù)流;barrier會在算子間傳遞下去。

每個算子會對當前的狀態(tài)做個快照,保存到狀態(tài)后端。對于source任務(wù)而言,就會把當前的offset作為狀態(tài)保存起來。下次從checkpoint恢復(fù)時,source任務(wù)可以重新提交偏移量,從上次保存的位置開始重新消費數(shù)據(jù)。

每個內(nèi)部的 transform 任務(wù)遇到 barrier 時,都會把狀態(tài)存到 checkpoint 里。
sink 任務(wù)首先把數(shù)據(jù)寫入外部 kafka,這些數(shù)據(jù)都屬于預(yù)提交的事務(wù)(還不能被消費);當遇到 barrier時,把狀態(tài)保存到狀態(tài)后端,并開啟新的預(yù)提交事務(wù)。

當所有算子任務(wù)的快照完成,也就是這次的 checkpoint 完成時,JobManager 會向所有任務(wù)發(fā)通知,確認這次 checkpoint 完成。當sink 任務(wù)收到確認通知,就會正式提交之前的事務(wù),kafka 中未確認的數(shù)據(jù)就改為“已確認”,數(shù)據(jù)就真正可以被消費了。

所以看到,執(zhí)行過程實際上是一個兩段式提交,每個算子執(zhí)行完成,會進行“預(yù)提交”,直到執(zhí)行完sink操作,會發(fā)起“確認提交”,如果執(zhí)行失敗,預(yù)提交會放棄掉。
具體的兩階段提交步驟總結(jié)如下:
第一條數(shù)據(jù)來了之后,開啟一個 kafka 的事務(wù)(transaction),正常寫入 kafka 分區(qū)日志但標記為未提交,這就是“預(yù)提交”, jobmanager 觸發(fā) checkpoint 操作,barrier 從 source 開始向下傳遞,遇到 barrier 的算子將狀態(tài)存入狀態(tài)后端,并通知 jobmanager
sink 連接器收到 barrier,保存當前狀態(tài),存入 checkpoint,通知 jobmanager,并開啟下一階段的事務(wù),用于提交下個檢查點的數(shù)據(jù)
jobmanager 收到所有任務(wù)的通知,發(fā)出確認信息,表示 checkpoint 完成
sink 任務(wù)收到 jobmanager 的確認信息,正式提交這段時間的數(shù)據(jù)
外部kafka關(guān)閉事務(wù),提交的數(shù)據(jù)可以正常消費了。
所以也可以看到,如果宕機需要通過StateBackend進行恢復(fù),只能恢復(fù)所有確認提交的操作。
6.3、Kafka冪等性和事務(wù)
前面表格總結(jié)的可以看出,Kafka在0.11版本之前只能保證At-Least-Once或At-Most-Once語義,從0.11版本開始,引入了冪等發(fā)送和事務(wù),從而開始保證EXACTLY_ONCE語義。
冪等性
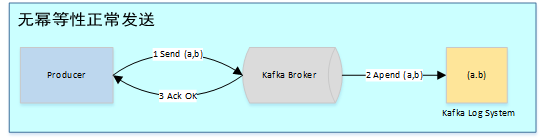
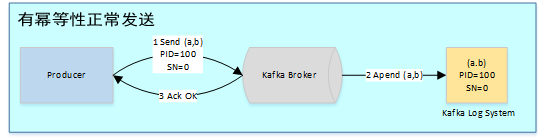
在未引入冪等性時,Kafka正常發(fā)送和重試發(fā)送消息流程圖如下:
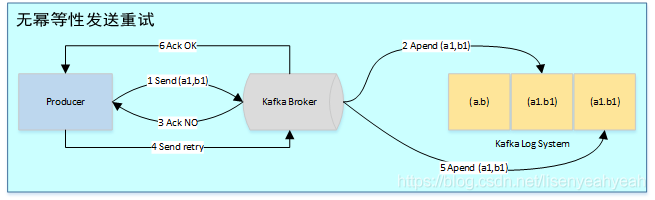
為了實現(xiàn)Producer的冪等語義,Kafka引入了Producer ID(即PID)和Sequence Number。每個新的Producer在初始化的時候會被分配一個唯一的PID,該PID對用戶完全透明而不會暴露給用戶。
Producer發(fā)送每條消息
序號比Broker維護的序號大1以上,說明存在亂序。
序號比Broker維護的序號小,說明此消息以及被保存,為重復(fù)數(shù)據(jù)。
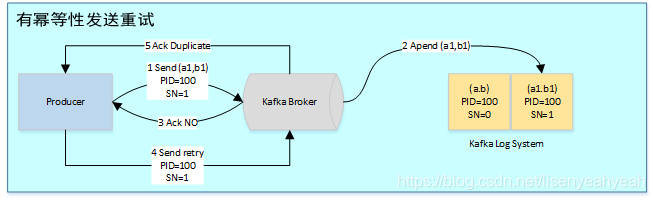
有了冪等性,Kafka正常發(fā)送和重試發(fā)送消息流程圖如下:
事務(wù)
事務(wù)是指所有的操作作為一個原子,要么都成功,要么都失敗,而不會出現(xiàn)部分成功或部分失敗的可能。舉個例子,比如小明給小王轉(zhuǎn)賬1000元,那首先小明的賬戶會減去1000,然后小王的賬戶會增加1000,這兩個操作就必須作為一個事務(wù),否則就會出現(xiàn)只減不增或只增不減的問題,因此要么都失敗,表示此次轉(zhuǎn)賬失敗。要么都成功,表示此次轉(zhuǎn)賬成功。分布式下為了保證事務(wù),一般采用兩階段提交協(xié)議。
為了解決跨session和所有分區(qū)不能EXACTLY-ONCE問題,Kafka從0.11開始引入了事務(wù)。
為了支持事務(wù),Kafka引入了Transacation Coordinator來協(xié)調(diào)整個事務(wù)的進行,并可將事務(wù)持久化到內(nèi)部topic里,類似于offset和group的保存。
用戶為應(yīng)用提供一個全局的Transacation ID,應(yīng)用重啟后Transacation ID不會改變。為了保證新的Producer啟動后,舊的具有相同Transaction ID的Producer即失效,每次Producer通過Transaction ID拿到PID的同時,還會獲取一個單調(diào)遞增的epoch。由于舊的Producer的epoch比新Producer的epoch小,Kafka可以很容易識別出該Producer是老的Producer并拒絕其請求。有了Transaction ID后,Kafka可保證:
跨Session的數(shù)據(jù)冪等發(fā)送。當具有相同Transaction ID的新的Producer實例被創(chuàng)建且工作時,舊的Producer停止工作。
跨Session的事務(wù)恢復(fù)。如果某個應(yīng)用實例宕機,新的實例可以保證任何未完成的舊的事務(wù)要么Commit要么Abort,使得新實例從一個正常狀態(tài)開始工作。
KIP-98 對Kafka事務(wù)原理進行了詳細介紹,完整的流程圖如下:
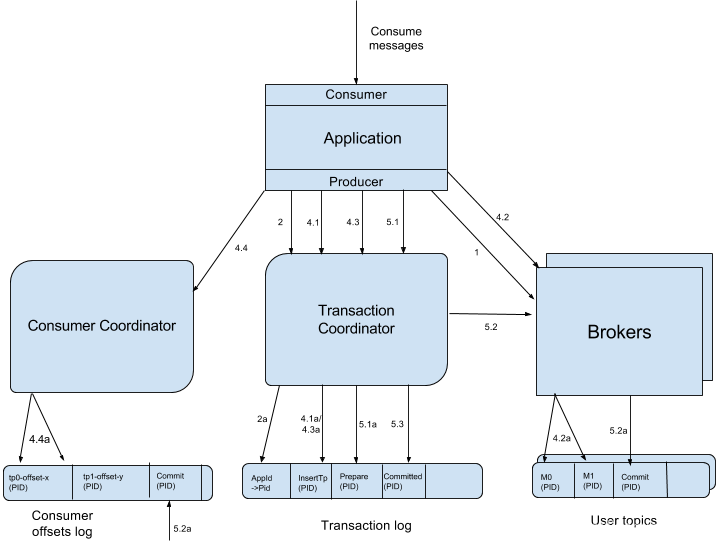
Producer向任意一個brokers發(fā)送 FindCoordinatorRequest請求來獲取Transaction Coordinator的地址;
找到Transaction Coordinator后,具有冪等特性的Producer必須發(fā)起InitPidRequest請求以獲取PID。
調(diào)用beginTransaction()方法開啟一個事務(wù),Producer本地會記錄已經(jīng)開啟了事務(wù),但Transaction Coordinator只有在Producer發(fā)送第一條消息后才認為事務(wù)已經(jīng)開啟。
Consume-Transform-Produce這一階段,包含了整個事務(wù)的數(shù)據(jù)處理過程,并且包含了多種請求。
提交或回滾事務(wù) 一旦上述數(shù)據(jù)寫入操作完成,應(yīng)用程序必須調(diào)用KafkaProducer的commitTransaction方法或者abortTransaction方法以結(jié)束當前事務(wù)。
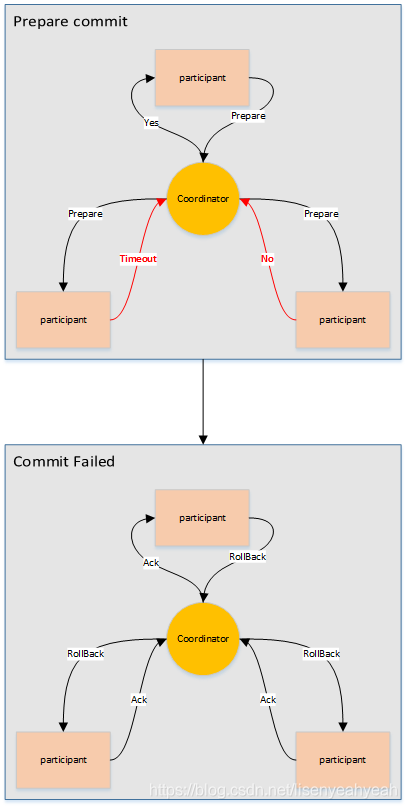
6.4 兩階段提交協(xié)議
兩階段提交指的是一種協(xié)議,經(jīng)常用來實現(xiàn)分布式事務(wù),可以簡單理解為預(yù)提交+實際提交,一般分為協(xié)調(diào)器Coordinator(以下簡稱C)和若干事務(wù)參與者Participant(以下簡稱P)兩種角色。
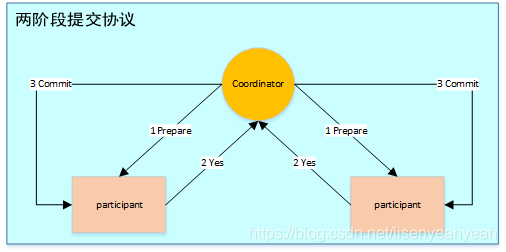
C先將prepare請求寫入本地日志,然后發(fā)送一個prepare的請求給P
P收到prepare請求后,開始執(zhí)行事務(wù),如果執(zhí)行成功返回一個Yes或OK狀態(tài)給C,否則返回No,并將狀態(tài)存到本地日志。
C收到P返回的狀態(tài),如果每個P的狀態(tài)都是Yes,則開始執(zhí)行事務(wù)Commit操作,發(fā)Commit請求給每個P,P收到Commit請求后各自執(zhí)行Commit事務(wù)操作。如果至少一個P的狀態(tài)為No,則會執(zhí)行Abort操作,發(fā)Abort請求給每個P,P收到Abort請求后各自執(zhí)行Abort事務(wù)操作。
注:C或P把發(fā)送或接收到的消息先寫到日志里,主要是為了故障后恢復(fù)用,類似WAL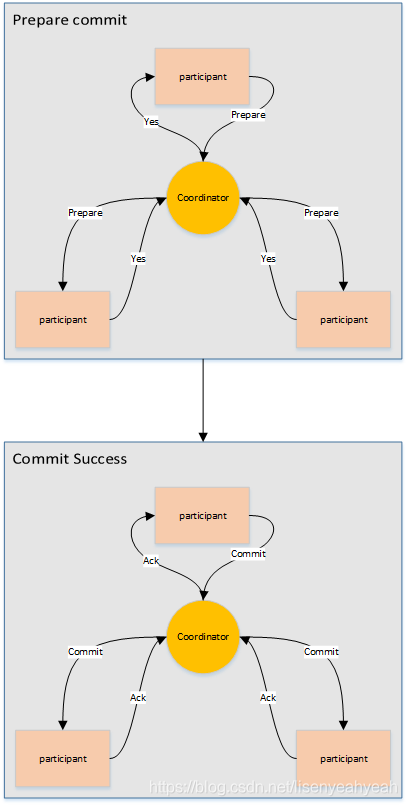
七、鏈接文檔
橫向擴展相關(guān)來于:Flink狀態(tài)管理詳解:Keyed State和Operator List State深度解析
checkpoint 相關(guān)來于:Apache Flink v1.10 官方中文文檔
狀態(tài)一致性相關(guān)來于:再忙也需要看的Flink狀態(tài)管理