
Lakehouse 概覽 | 一文了解 Data Lakehouse 的演變
本文是 Forest Rim Technology 數(shù)據(jù)團(tuán)隊(duì)撰寫(xiě)的,作者 Bill Inmon 和 Mary Levins,其中 Bill Inmon 被稱為是數(shù)據(jù)倉(cāng)庫(kù)之父,最早的數(shù)據(jù)倉(cāng)庫(kù)概念提出者,被《計(jì)算機(jī)世界》評(píng)為計(jì)算機(jī)行業(yè)歷史上最具影響力的十大人物之一。
原始數(shù)據(jù)的挑戰(zhàn)
隨著大量應(yīng)用程序的出現(xiàn),產(chǎn)生了相同的數(shù)據(jù)在不同地方出現(xiàn)不同值的情況。為了做出決定,用戶必須找到在眾多應(yīng)用程序中使用哪個(gè)版本的數(shù)據(jù)才是正確的。如果用戶沒(méi)有找到并使用正確的數(shù)據(jù),則可能做出錯(cuò)誤的決定。
人們發(fā)現(xiàn)他們需要一種不同的架構(gòu)方法來(lái)找到用于決策的正確數(shù)據(jù)。因此,數(shù)據(jù)倉(cāng)庫(kù)誕生了。
數(shù)據(jù)倉(cāng)庫(kù)
數(shù)據(jù)倉(cāng)庫(kù)導(dǎo)致不同的應(yīng)用程序數(shù)據(jù)被放置在單獨(dú)的地方。設(shè)計(jì)者必須圍繞數(shù)據(jù)倉(cāng)庫(kù)建立一個(gè)全新的基礎(chǔ)設(shè)施。
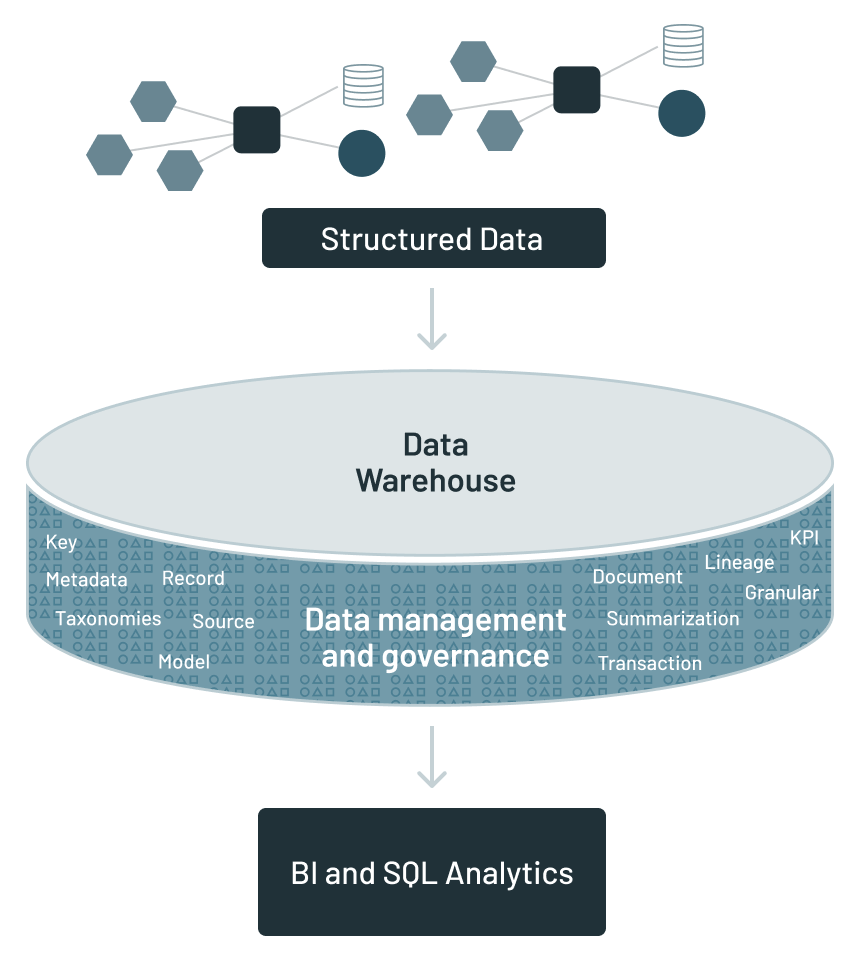
圍繞數(shù)據(jù)倉(cāng)庫(kù)的分析基礎(chǔ)設(shè)施包含以下內(nèi)容:
?元數(shù)據(jù)(Metadata)– 一個(gè)關(guān)于數(shù)據(jù)位于何處的指南;?數(shù)據(jù)模型(A data model)– 數(shù)據(jù)倉(cāng)庫(kù)中數(shù)據(jù)的抽象;?數(shù)據(jù)血緣(Data lineage)– 數(shù)據(jù)倉(cāng)庫(kù)中數(shù)據(jù)的起源和轉(zhuǎn)換;?摘要(Summarization)– 用于創(chuàng)建數(shù)據(jù)的算法工作的描述;?KPIs?– 關(guān)鍵績(jī)效指標(biāo)在哪里;?ETL?– 允許將應(yīng)用程序數(shù)據(jù)轉(zhuǎn)換為公司數(shù)據(jù)。
隨著企業(yè)中數(shù)據(jù)(文本、物聯(lián)網(wǎng)、圖像、音頻、視頻等)的多樣性增加,數(shù)據(jù)倉(cāng)庫(kù)的局限性變得明顯。此外,機(jī)器學(xué)習(xí)(ML)和人工智能的興起引入了迭代算法,這些算法需要直接訪問(wèn)數(shù)據(jù),而不是基于 SQL。
公司的所有數(shù)據(jù)
一般情況下,數(shù)據(jù)倉(cāng)庫(kù)里面的數(shù)據(jù)是結(jié)構(gòu)化的數(shù)據(jù)。但是現(xiàn)在公司中有許多其他的數(shù)據(jù)類型,包括結(jié)構(gòu)化(Structured data)、文本數(shù)據(jù)(Textual data)以及非結(jié)構(gòu)化(unstructured data)的數(shù)據(jù)。
結(jié)構(gòu)化數(shù)據(jù)通常是組織為執(zhí)行日常業(yè)務(wù)活動(dòng)而生成的基于事務(wù)(transaction-based)的數(shù)據(jù)。文本數(shù)據(jù)是由公司內(nèi)部發(fā)生的信件、電子郵件和對(duì)話生成的數(shù)據(jù)。非結(jié)構(gòu)化數(shù)據(jù)是其他來(lái)源的數(shù)據(jù),如物聯(lián)網(wǎng)數(shù)據(jù)、圖像、視頻和基于模擬的數(shù)據(jù)。
數(shù)據(jù)湖
數(shù)據(jù)湖是企業(yè)中所有不同類型數(shù)據(jù)的集合。它已經(jīng)成為企業(yè)存放所有數(shù)據(jù)的地方,因?yàn)樗牡统杀敬鎯?chǔ)系統(tǒng)擁有一個(gè)文件 API,以通用和開(kāi)放的文件格式保存數(shù)據(jù),如 Apache Parquet 和 ORC。開(kāi)放格式的使用也使得數(shù)據(jù)湖中的數(shù)據(jù)可以被其他分析引擎訪問(wèn)到,如機(jī)器學(xué)習(xí)系統(tǒng)。
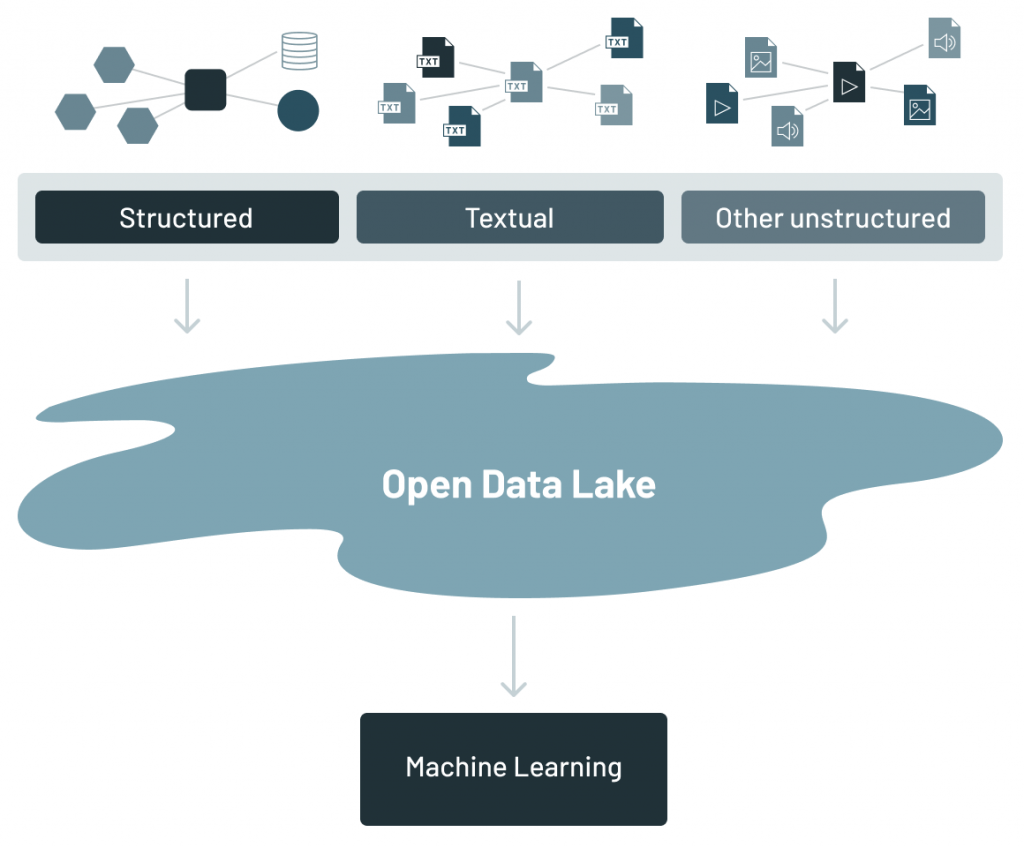
最初構(gòu)思數(shù)據(jù)湖時(shí),人們認(rèn)為只需要提取數(shù)據(jù)并將其放入數(shù)據(jù)湖即可。一旦進(jìn)入數(shù)據(jù)湖,終端用戶就可以一頭扎進(jìn)去,找到數(shù)據(jù)并進(jìn)行分析。然而,企業(yè)很快發(fā)現(xiàn),使用數(shù)據(jù)湖中的數(shù)據(jù)與僅僅將數(shù)據(jù)放入湖中完全是兩碼事。
由于缺乏一些關(guān)鍵特性,數(shù)據(jù)湖的許多承諾都沒(méi)有實(shí)現(xiàn):不支持事務(wù),不保證數(shù)據(jù)質(zhì)量,以及性能優(yōu)化不佳。因此,企業(yè)中的大部分?jǐn)?shù)據(jù)湖變成了數(shù)據(jù)沼澤(data swamps)。
當(dāng)前數(shù)據(jù)架構(gòu)面臨的挑戰(zhàn)
由于數(shù)據(jù)湖和數(shù)據(jù)倉(cāng)庫(kù)的局限性,常見(jiàn)的方法是使用多個(gè)系統(tǒng)——一個(gè)數(shù)據(jù)湖、幾個(gè)數(shù)據(jù)倉(cāng)庫(kù)和其他專門(mén)的系統(tǒng),這導(dǎo)致三個(gè)常見(jiàn)問(wèn)題:
?缺乏開(kāi)放性:數(shù)據(jù)倉(cāng)庫(kù)將數(shù)據(jù)轉(zhuǎn)換為專有格式,這增加了將數(shù)據(jù)或工作負(fù)載遷移到其他系統(tǒng)的成本。由于數(shù)據(jù)倉(cāng)庫(kù)主要提供僅 SQL 的訪問(wèn)模式,因此很難運(yùn)行其他分析引擎,如機(jī)器學(xué)習(xí)系統(tǒng)。此外,使用 SQL 直接訪問(wèn)數(shù)據(jù)倉(cāng)庫(kù)中的數(shù)據(jù)非常昂貴和緩慢,這使得與其他技術(shù)的集成變得非常困難。?對(duì)機(jī)器學(xué)習(xí)的支持有限:盡管有很多關(guān)于 ML 和數(shù)據(jù)管理融合的研究,但沒(méi)有一個(gè)領(lǐng)先的機(jī)器學(xué)習(xí)系統(tǒng),如 TensorFlow、PyTorch 和 XGBoost,能夠很好地在倉(cāng)庫(kù)之上工作。與提取少量數(shù)據(jù)的 BI 系統(tǒng)不同,ML 系統(tǒng)使用復(fù)雜的非 SQL 代碼處理大型數(shù)據(jù)集。對(duì)于這些用例,倉(cāng)庫(kù)供應(yīng)商建議將數(shù)據(jù)導(dǎo)出到文件中,這進(jìn)一步增加了系統(tǒng)的復(fù)雜性。?數(shù)據(jù)湖和數(shù)據(jù)倉(cāng)庫(kù)之間的強(qiáng)制權(quán)衡:超過(guò)90%的企業(yè)數(shù)據(jù)存儲(chǔ)在數(shù)據(jù)湖中,這是因?yàn)閿?shù)據(jù)湖使用廉價(jià)存儲(chǔ),從開(kāi)放直接訪問(wèn)文件到低成本的靈活性。為了克服數(shù)據(jù)湖缺乏性能和質(zhì)量的問(wèn)題,企業(yè)將數(shù)據(jù)湖中的一小部分?jǐn)?shù)據(jù) ETL 到下游數(shù)據(jù)倉(cāng)庫(kù),用于最重要的決策支持和 BI 應(yīng)用。這種雙系統(tǒng)架構(gòu)需要對(duì)數(shù)據(jù)湖和數(shù)據(jù)倉(cāng)庫(kù)之間的 ETL 數(shù)據(jù)進(jìn)行持續(xù)的工程處理。每個(gè) ETL 步驟都有可能導(dǎo)致失敗或引入 bug,從而降低數(shù)據(jù)質(zhì)量,同時(shí)保持?jǐn)?shù)據(jù)湖和數(shù)據(jù)倉(cāng)庫(kù)的一致性是非常困難和昂貴的。除了需要為持續(xù)的 ETL 支付費(fèi)用外,用戶還要為復(fù)制到倉(cāng)庫(kù)的數(shù)據(jù)支付兩倍的存儲(chǔ)成本。
data lakehouse 的誕生
當(dāng)前,業(yè)界出現(xiàn)了一種稱為 data lakehouse 的新型數(shù)據(jù)架構(gòu),它通過(guò)一種新的開(kāi)放和標(biāo)準(zhǔn)化的系統(tǒng)設(shè)計(jì)來(lái)實(shí)現(xiàn):其實(shí)現(xiàn)與數(shù)據(jù)倉(cāng)庫(kù)中類似的數(shù)據(jù)結(jié)構(gòu)和數(shù)據(jù)管理功能,并將數(shù)據(jù)存放在數(shù)據(jù)湖使用的低成本存儲(chǔ)系統(tǒng)中
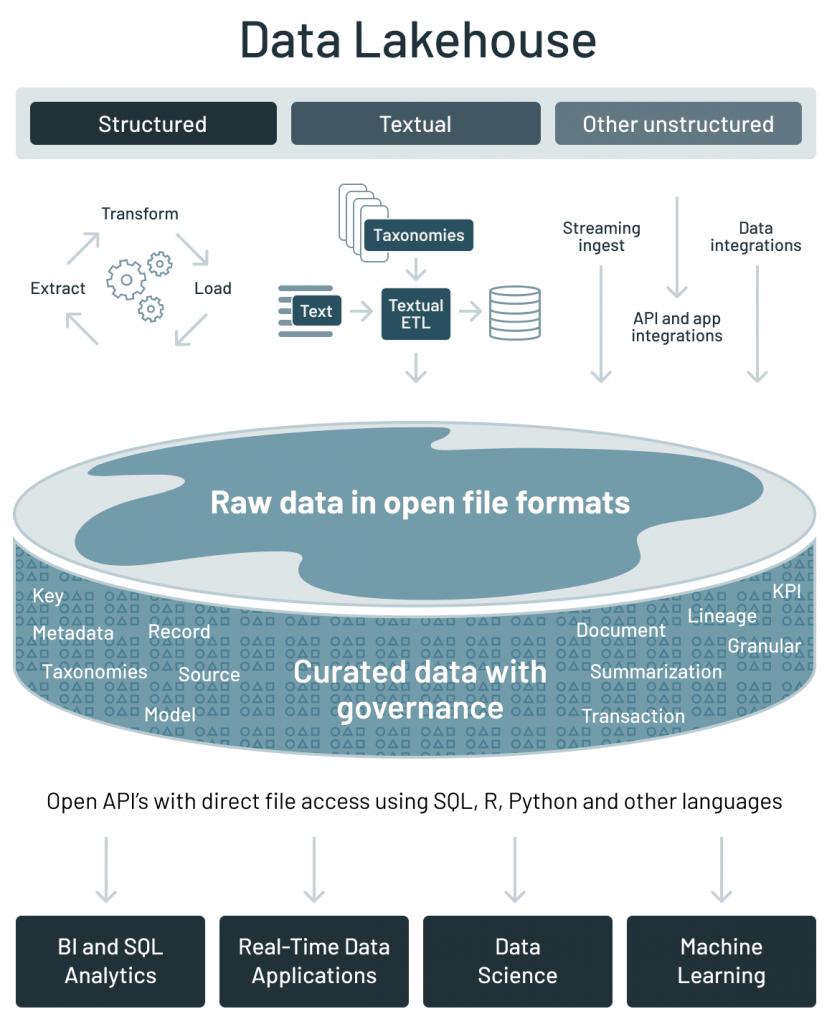
data lakehouse 架構(gòu)解決了上一節(jié)討論的當(dāng)前數(shù)據(jù)架構(gòu)的主要挑戰(zhàn):
?通過(guò)使用開(kāi)放的數(shù)據(jù)存儲(chǔ)格式(如 Apache Parquet)實(shí)現(xiàn)數(shù)據(jù)開(kāi)放訪問(wèn);?原生就支持?jǐn)?shù)據(jù)科學(xué)和機(jī)器學(xué)習(xí)工作負(fù)載;?在低成本存儲(chǔ)上提供一流的性能和可靠性。
以下是 data lakehouse 架構(gòu)的主要優(yōu)點(diǎn):
開(kāi)放性
?使用開(kāi)放文件格式:基于開(kāi)放和標(biāo)準(zhǔn)化的文件格式,如 Apache Parquet 和 ORC;?開(kāi)放的 API:提供可以直接有效訪問(wèn)數(shù)據(jù)的開(kāi)放 API,而不需要專有引擎和被廠商鎖定;?語(yǔ)言支持:不僅支持 SQL 訪問(wèn),還支持各種其他工具和引擎,包括機(jī)器學(xué)習(xí)和 Python/R 庫(kù)
支持機(jī)器學(xué)習(xí)
?支持多種數(shù)據(jù)類型:為許多新的應(yīng)用程序存儲(chǔ)、精煉、分析和訪問(wèn)數(shù)據(jù),包括圖像、視頻、音頻、半結(jié)構(gòu)化數(shù)據(jù)和文本;?高效的非 SQL 直接讀取:使用 R 和 Python 庫(kù)直接高效的訪問(wèn)大量數(shù)據(jù),以運(yùn)行機(jī)器學(xué)習(xí)實(shí)驗(yàn);?對(duì) DataFrame API 的支持:內(nèi)置的聲明式 DataFrame API 具有查詢優(yōu)化功能,可用于 ML 工作負(fù)載中的數(shù)據(jù)訪問(wèn),因?yàn)橹T如 TensorFlow,PyTorch 和XGBoost 的 ML 系統(tǒng)已采用 DataFrames 作為操作數(shù)據(jù)的主要抽象。?數(shù)據(jù)版本控制:提供數(shù)據(jù)快照,使數(shù)據(jù)科學(xué)和機(jī)器學(xué)習(xí)團(tuán)隊(duì)可以訪問(wèn)和還原到較早版本的數(shù)據(jù),以進(jìn)行審核和回滾或重現(xiàn) ML 實(shí)驗(yàn)。
一流的性能和低成本的可靠性
?性能優(yōu)化:通過(guò)利用文件統(tǒng)計(jì)信息,來(lái)啟用各種優(yōu)化技術(shù),例如緩存,多維 clustering 和跳過(guò)無(wú)用數(shù)據(jù);?模式增強(qiáng)和管理:支持星型/雪花模型等數(shù)據(jù)倉(cāng)庫(kù)模式架構(gòu),并提供健壯的數(shù)據(jù)治理和審計(jì)機(jī)制;?事務(wù)支持:當(dāng)多方并發(fā)地讀寫(xiě)數(shù)據(jù)(通常使用SQL)時(shí),利用 ACID 事務(wù)來(lái)確保數(shù)據(jù)一致性;?低成本存儲(chǔ):Lakehouse 架構(gòu)使用了低成本的對(duì)象存儲(chǔ),如 Amazon S3、Azure Blob 存儲(chǔ)或 Google Cloud Storage。。
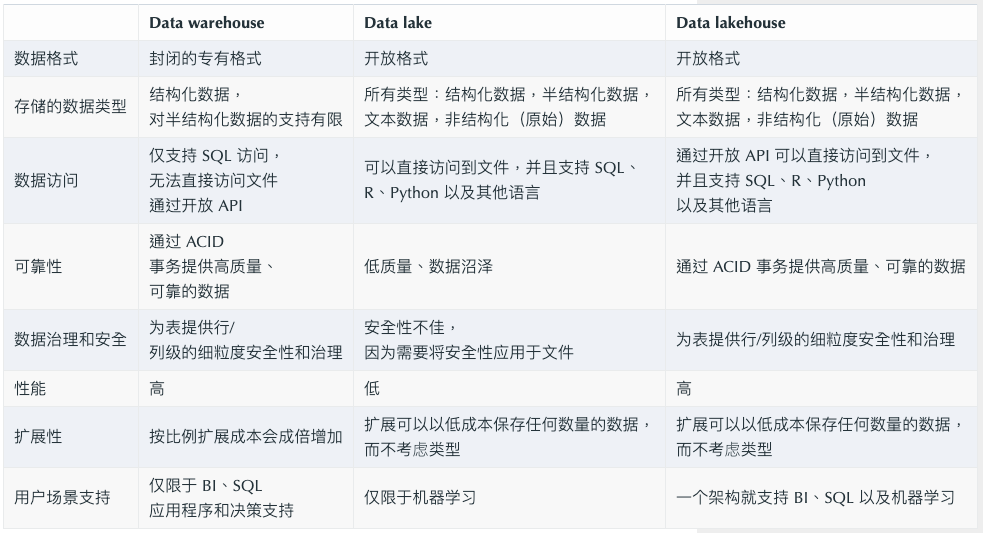
數(shù)據(jù)倉(cāng)庫(kù)、數(shù)據(jù)湖以及 data lakehouse 比較
data lakehouse 的影響
我們相信,data lakehouse 架構(gòu)提供的機(jī)會(huì),可以與我們?cè)跀?shù)據(jù)倉(cāng)庫(kù)市場(chǎng)的早期相媲美。data lakehouse 在開(kāi)放環(huán)境中管理數(shù)據(jù)的獨(dú)特能力,融合了企業(yè)各個(gè)部門(mén)的各種數(shù)據(jù),并將數(shù)據(jù)湖中數(shù)據(jù)科學(xué)焦點(diǎn)與數(shù)據(jù)倉(cāng)庫(kù)中終端用戶分析相結(jié)合,將為組織釋放難以置信的價(jià)值。
本文翻譯自《Evolution to the Data Lakehouse》:
https://databricks.com/blog/2021/05/19/evolution-to-the-data-lakehouse.html