
只需3行Python代碼就能獲取海量數(shù)據(jù)
一談起數(shù)據(jù)分析,首先想到的就是數(shù)據(jù),沒有數(shù)據(jù),談何分析。
畢竟好的菜肴,沒有好的原材料,是很難做的~
所以本期就給大家分享一個(gè)獲取數(shù)據(jù)的方法,只需三行代碼就能搞定。
「GoPUP」,大佬造的輪子,大概有100+的免費(fèi)數(shù)據(jù)接口。

GitHub:https://github.com/justinzm/gopup
使用文檔:http://doc.gopup.cn/#/README
主要有指數(shù)數(shù)據(jù)、宏觀經(jīng)濟(jì)數(shù)據(jù)、新經(jīng)濟(jì)數(shù)據(jù)、微博KOL數(shù)據(jù)、信息數(shù)據(jù)、生活數(shù)據(jù)、疫情數(shù)據(jù)等。
# 安裝gopup
pip install gopup --upgrade
安裝成功后,就能使用了。
01 微博指數(shù)
獲取指定關(guān)鍵詞的微博指數(shù)。
# 微博指數(shù)
import gopup as gp
df_index = gp.weibo_index(word="馬保國", time_type="1month")
print(df_index)
time_type="1month"; 1hour, 1day, 1month, 3month 選其一。
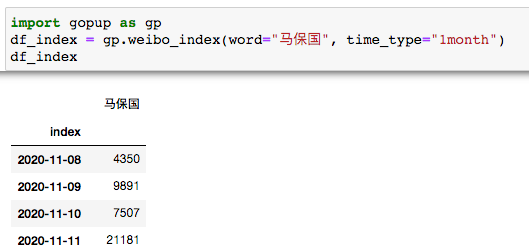
三行Python代碼實(shí)現(xiàn)數(shù)據(jù)獲取。
02 百度指數(shù)
獲取指定關(guān)鍵詞的百度搜索指數(shù)。
# 百度指數(shù)
import gopup as gp
cookie = "此處輸入您在網(wǎng)頁端登錄百度指數(shù)后的 cookie 數(shù)據(jù)"
index_df = gp.baidu_search_index(word="馬保國", start_date='2020-11-15', end_date='2020-11-25', cookie=cookie)
print(index_df)
需要登陸百度指數(shù),獲取你的Cookie。
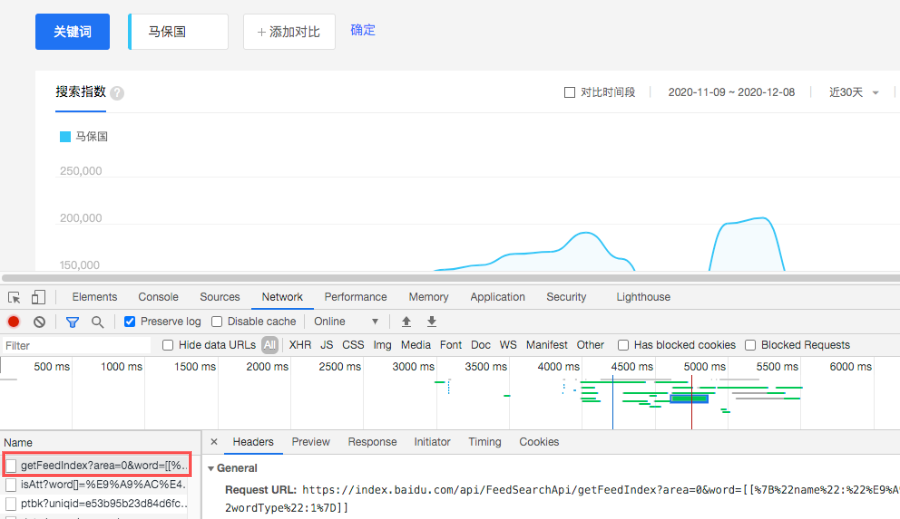
設(shè)置關(guān)鍵詞,時(shí)間起始,就能獲取到馬保國老師的熱度數(shù)據(jù)了。
后面還有百度資訊、媒體、需求圖譜、人群年齡、性別、興趣分布數(shù)據(jù)接口,就不一一介紹了。
感興趣的同學(xué)可以自行去查看文檔。
03 頭條指數(shù)
獲取指定關(guān)鍵詞的頭條指數(shù)。
# 頭條指數(shù)
import gopup as gp
index_df = gp.toutiao_index(keyword="馬保國", start_date='20201115', end_date='20201125')
print(index_df)
接口掛了,不知為何~
還有相關(guān)性、情感、地域、城市、年齡、性別、用戶閱讀興趣分析數(shù)據(jù)等接口。
04 谷歌數(shù)據(jù)
需要通過代理才能使用,不過上面這三類已經(jīng)完全夠用了。
# 谷歌數(shù)據(jù)
import gopup as gp
index_df = gp.google_index(keyword="馬保國", start_date='2020-11-15T10', end_date='2020-11-25T23')
print(index_df)
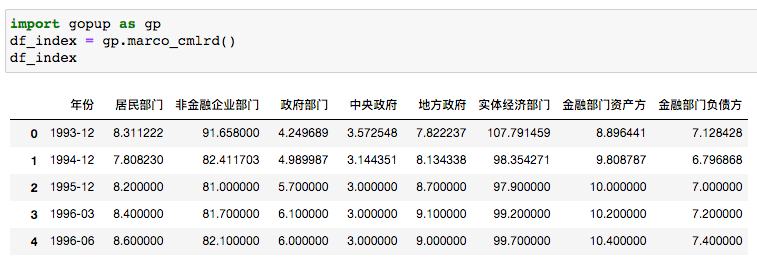
05 宏觀經(jīng)濟(jì)數(shù)據(jù)
有一個(gè)杠桿率的數(shù)據(jù)可以使用。
# 杠桿數(shù)據(jù)
import gopup as gp
df_index = gp.marco_cmlrd()
print(df_index)
不懂經(jīng)濟(jì)學(xué),所以不明覺厲。
06 新經(jīng)濟(jì)數(shù)據(jù)
這個(gè)數(shù)據(jù)倒是蠻有趣的,主要是公司數(shù)據(jù)。
比如獨(dú)角獸和倒閉公司的數(shù)據(jù)。
# 獨(dú)角獸公司數(shù)據(jù)
import gopup as gp
df_index = gp.nicorn_company()
print(df_index)
一共是240家獨(dú)角獸公司。
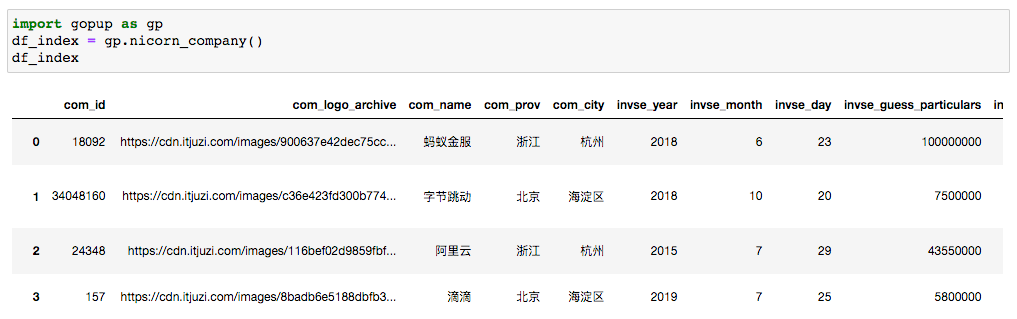
螞蟻、字節(jié)、阿里云、滴滴,都是行業(yè)中的大佬。
# 倒閉公司數(shù)據(jù)
import gopup as gp
df_index = gp.death_company()
print(df_index)
倒閉的公司一共有6921家。
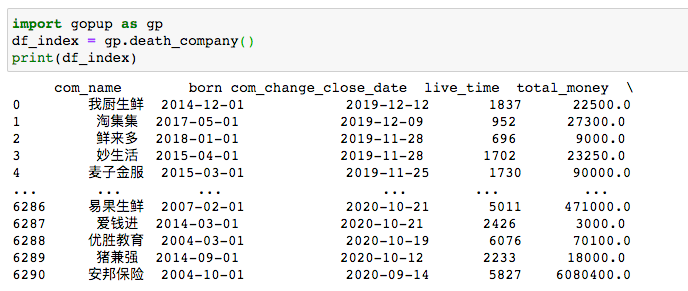
看到不少P2P的公司。
剩下還有有一個(gè)特許經(jīng)營許可數(shù)據(jù),好像是吊牌銷售的意思。
前段時(shí)間看到一篇文章,講的就是南極人吊牌銷售的事情,南極人都不自己搞生產(chǎn),而是代工。
07 KOL數(shù)據(jù)&信息數(shù)據(jù)
主要是微博的KOL,所以沒啥用。
# KOL數(shù)據(jù)
import gopup as gp
g = gp.pro_api(token = "……")
df_index = g.weibo_user(keyword="雷軍")
print(df_index)
信息數(shù)據(jù)是新聞聯(lián)播文字稿。
08 中國油價(jià)數(shù)據(jù)
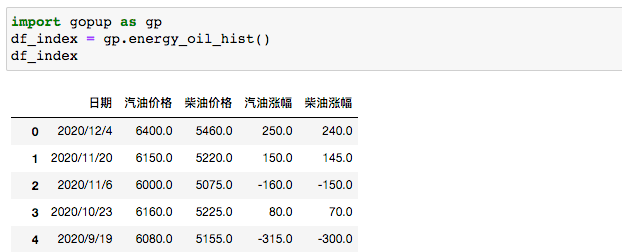
包含汽油和柴油的調(diào)價(jià)信息數(shù)據(jù)。
# 油價(jià)數(shù)據(jù)
import gopup as gp
df_index = gp.energy_oil_hist()
print(df_index)
時(shí)間從2000年直到2020年,細(xì)數(shù)20年油價(jià)變化。
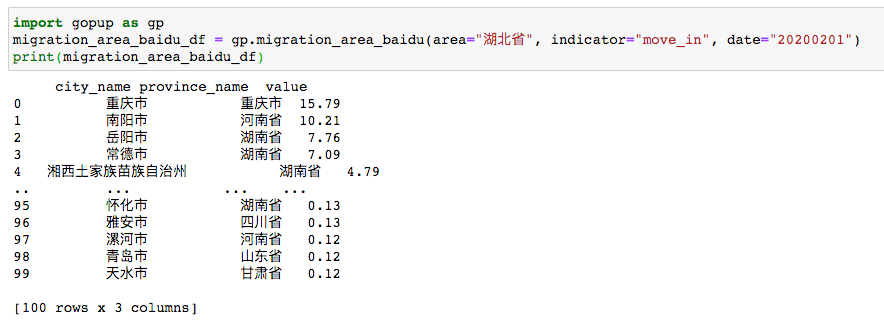
09 百度遷徙數(shù)據(jù)
可以用來做飛線圖或者OD圖。
# 遷徙數(shù)據(jù)
import gopup as gp
migration_area_baidu_df = gp.migration_area_baidu(area="湖北省", indicator="move_in", date="20200201")
print(migration_area_baidu_df)
單次返回100個(gè)城市的數(shù)據(jù)。
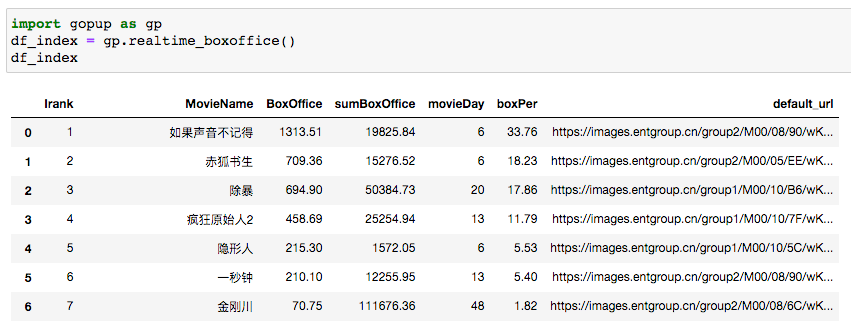
10 影視數(shù)據(jù)
實(shí)時(shí)電影票房數(shù)據(jù),最近又有病例出現(xiàn),數(shù)據(jù)應(yīng)該也比較慘淡。
這里需要一個(gè)WebDES.js文件,才能請求成功。
# 實(shí)時(shí)電影票房數(shù)據(jù)
import gopup as gp
df_index = gp.realtime_boxoffice()
print(df_index)
「如果聲音不記得」當(dāng)日1千萬的票房,太少了。
單日影院數(shù)據(jù),今年影院能倒閉一大堆。
# 單日影院數(shù)據(jù)
import gopup as gp
df_index = gp.day_cinema(date="2020-12-08")
print(df_index)
得到票房前100的數(shù)據(jù)。
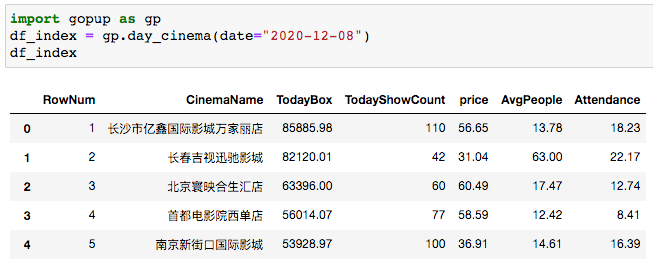
最高應(yīng)該是8萬多的收入。
實(shí)時(shí)電視劇播映指數(shù),天氣冷了選個(gè)好劇或者綜藝,窩在被窩刷起來。
# 電視劇數(shù)據(jù)
import gopup as gp
df_index = gp.realtime_tv()
print(df_index)
大秦賦,小F也在看,感覺還不錯(cuò)。
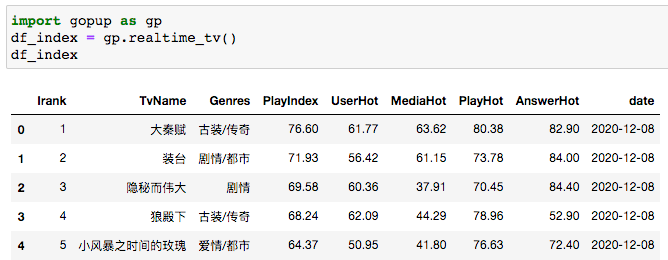
還有實(shí)時(shí)綜藝播映指數(shù)、藝人商業(yè)價(jià)值、流量價(jià)值等數(shù)據(jù)。
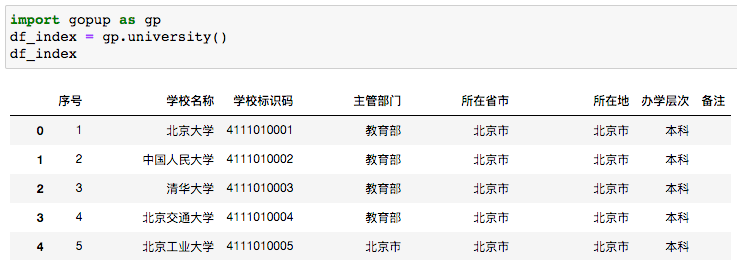
11 全國高等學(xué)校數(shù)據(jù)
普通高等學(xué)校名單,包含名稱、主管部門,所在省市、所在地、辦學(xué)層次等信息。
# 普通高等學(xué)校數(shù)據(jù)
import gopup as gp
df_index = gp.university()
print(df_index)
一共是2631所高校。
還有成人高等學(xué)校以及高等學(xué)校詳情數(shù)據(jù)。
12 疫情數(shù)據(jù)
有網(wǎng)易、丁香園、百度三家的疫情數(shù)據(jù)。
# 世界歷史累計(jì)確診數(shù)據(jù)
import gopup as gp
covid_163_df = gp.covid_163(indicator="世界歷史累計(jì)數(shù)據(jù)")
print(covid_163_df)
目前累計(jì)207個(gè)國家有疫情出現(xiàn)。
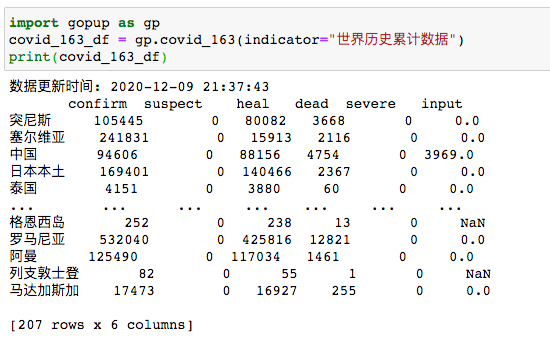
全世界總共就233個(gè)國家和地區(qū),快接近90%了。
由于數(shù)據(jù)接口太多了,這里就不一一介紹了,可以點(diǎn)擊左下角的閱讀原文,查看文檔。




