
【CV】通俗易懂的目標(biāo)檢測 | RCNN, SPPNet, Fast, Faster
全文5500個字,22幅圖,學(xué)習(xí)時長預(yù)計20分鐘
目錄
0?概述
1?RCNN
1.1 候選區(qū)Region Proposal
1.2 特征提取
1.3 SVM分類
1.4 線性回歸
2 SPP Net
3 Fast RCNN
4 Faster RCNN
5 總結(jié)
0 概述
本文主要講一下深度網(wǎng)絡(luò)時代,目標(biāo)檢測系列的RCNN這個分支,這個分支就是常說的two-step,候選框 + 深度學(xué)習(xí)分類的模式:RCNN->SPP->Fast RCNN->Faster RCNN
另外一個分支是yolo v1-v4,這個分支是one-step的端到端的方式。不過這里主要是介紹RCNN那個體系的。
把下圖中的yolo忽略,剩下的四個就是RCNN體系的一個非常好的總結(jié)。
1 RCNN
RCNN既然是two-step,那么就從這里切入理解:
第一步,生成候選區(qū) 第二步,判斷每個候選區(qū)的類別 2.1 用CNN提取特征 2.2 用SVM分類 2.3 用線性回歸矯正候選框的位置
1.1 候選區(qū)Region Proposal
一個圖片中有多個待檢測的目標(biāo),我們怎么找到這個目標(biāo)的位置呢?Region Proposal就是給出目標(biāo)可能在的候選框中。如下圖,Region Proposal給出了大大小小的可能候選框: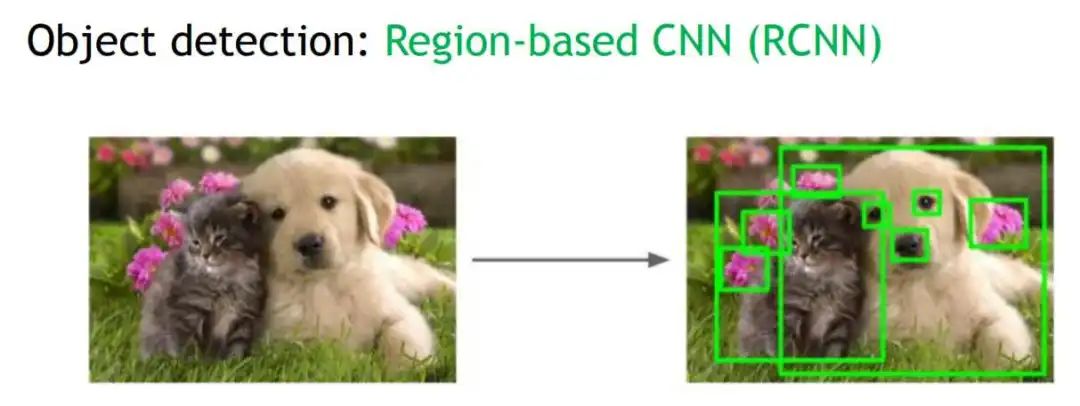
怎么給出可能的候選框呢?比較籠統(tǒng)的說法是:利用圖像中的紋理、邊緣、顏色等信息,先產(chǎn)生較小的相同紋理、相同顏色的候選框,然后小的候選框慢慢合并成大的紋理相似的候選框。
【selective search 選擇性搜索】這個選擇性搜索就是給出候選框的算法的名字。用Selective Search方法可以對一張圖片生成大約1000~3000個候選框,具體的算法邏輯如下:
使用一種過分割手段,將圖像分割成過小的區(qū)域; 查看現(xiàn)有小區(qū)域,合并可能性最高的兩個區(qū)域,重復(fù)直到整張圖像合并成一個區(qū)域位置;; 輸出所有曾經(jīng)存在過的區(qū)域,也就是從小合并到大的所有出現(xiàn)過的大大小小的候選框,即所謂候選區(qū)域。
【合并遵守的原則】
顏色(顏色直方圖)相近的; 紋理(梯度直方圖)相近的; 合并后總面積小的;
1.2 特征提取
之前選出來的大大小小的候選框,其實(shí)就是大大小小的圖片。這里把圖片都縮放成統(tǒng)一的227*227的大小,然后把統(tǒng)一大小的圖片輸入到CNN中,進(jìn)行特征提取。這里的特征網(wǎng)絡(luò)是一個比較簡單的網(wǎng)絡(luò)(當(dāng)年resnet啊googlenet啊都沒提出來,BN層也沒提出來,所以結(jié)構(gòu)如下)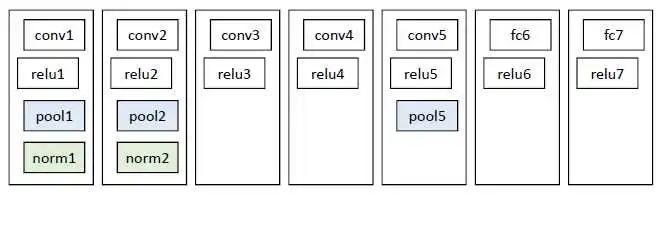
從上圖中的pool5之后的輸出的特征圖取出來,所以SVM的輸入特征。(這里需要提到的是,pool5在某些博客中被說成了第五個池化層,感覺不是很恰當(dāng),應(yīng)該是第三個池化層,只是接在了第5個卷積層后面。)
1.3 SVM分類
眾所周知,SVM只能分類二分類任務(wù)(這個不清楚的給我回去看之前的SVM推導(dǎo)去)。
想要SVM處理多分類任務(wù),那么就有多種集成方式。我記得上課老師說的有兩種(我只記得兩種了):
one vs one:就是假設(shè)5個類別,那么兩兩類別之間訓(xùn)練一個SVM,總共訓(xùn)練10個SVM,然后把一個圖片放入這個10個SVN,然后對于結(jié)果進(jìn)行投票; one vs all:這個5分類任務(wù),就訓(xùn)練5個SVM,然后每個SVM訓(xùn)練的正負(fù)樣本就是:是這個類別的和不是這個類別的。淦!語言說的不清楚。
舉個例子:a,b,c三個類別。one vs one就是:a|b,a|c,b|c。one vs all就是a|bc,b|ac,c|ab。(值得注意的是,在目標(biāo)檢測中,會多一個類別,叫做背景)
回到RCNN,這里的SVM用的就是one vs all的方式。下圖可以比較好的理解什么是one vs all: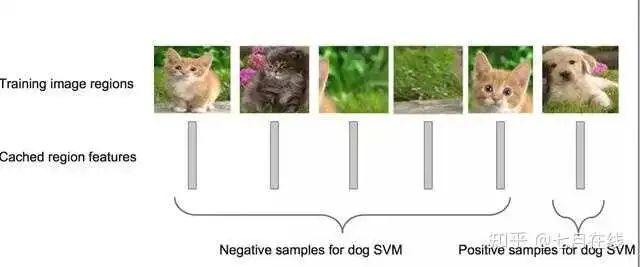
1.4 線性回歸
現(xiàn)在我們知道一個候選框的類別了(通過SVM),但是我們經(jīng)過一開始的拉伸,雖然讓所有圖片都變成了227的大小,但是也會造成圖像的扭曲。如下圖:
所以這時候,訓(xùn)練一個線性回歸模型,來做一個邊框回歸,精細(xì)的調(diào)整候選框(x,y,w,h)四個參數(shù)。這里每一個類別就會訓(xùn)練一個線性回歸模型,根據(jù)SVM的結(jié)果,選擇相應(yīng)類別的線性回歸模型進(jìn)行候選框的矯正。
整個RCNN的過程可以用下面這張圖來概括一下: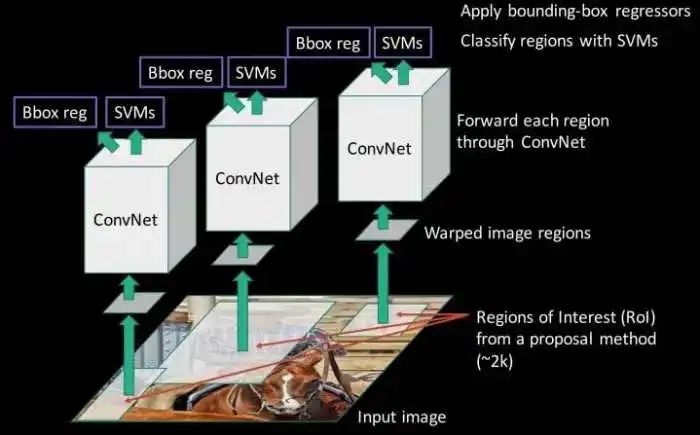
整體四個步驟,精度達(dá)到了當(dāng)時水平的巔峰,但是每一張圖片都會有2000左右的候選框,再加上SVM和線性回歸的推理,一張圖片的推理時間需要47s。慢的雅痞。之后的三個模型,都是不斷改進(jìn)了RCNN的各種問題,做出了各種杰出的提升。
2 SPP Net
SPP:Spatial Pyramid Pooling空間金字塔池化
SPP-Net是出自2015年發(fā)表在IEEE上的論文-《Spatial Pyramid Pooling in Deep ConvolutionalNetworks for Visual Recognition》。
眾所周知,CNN一般都含有卷積部分和全連接部分,其中,卷積層不需要固定尺寸的圖像,而全連接層是需要固定大小的輸入(SVM的輸入也是需要固定大小的輸入)。
所以當(dāng)全連接層面對帶下不同的輸入數(shù)據(jù)的時候,就需要對數(shù)據(jù)做拉伸warp或者剪裁crop,就像是RCNN中把候選框拉伸到227尺寸大小。
【crop與warp】

兩者的效果看下面的圖就懂了吧。
現(xiàn)在的問題是,warp還是crop都會讓圖像變形、物體不全,這樣勢必會對識別的精確度產(chǎn)生影響。
【如何避免使用warp和crop】SPP net使用了SPP空間金字塔池化層,來實(shí)現(xiàn)了這個功能。先看和RCNN的模型結(jié)構(gòu)對比:
RCNN中先通過warp講大小不同的候選框變成227統(tǒng)一大小輸入到conv layers;SPP中直接對大小不同的候選框做conv layers,所以我們得到了大小不同的特征圖。然后將大小不同的特征圖輸入到SPP空間金字塔池化層中,輸出變成大小相同的特征圖
【SPP層如何實(shí)現(xiàn)尺寸輸入不同輸出相同的呢?】ROI pooling是空間金字塔池化層的更底層的結(jié)構(gòu)。準(zhǔn)確的說,是ROI池化層實(shí)現(xiàn)的輸入尺寸不同,輸出相同的功能。。
ROI Pooling=Region of Interest Pooling感興趣區(qū)域池化層
ROI池化層一般跟在卷積層后面,此時網(wǎng)絡(luò)的輸入可以是任意尺度的,ROI pooling的filter會根據(jù)輸入調(diào)整大小。一個簡單的例子,10*10的特征圖輸入到ROI pooling,我們設(shè)置要一個5*5的輸出,所以ROI pooling的filter大小自動計算出是2*2的。假如輸入時20*20的特征圖,計算出來的filter就是4*4大小的,輸出結(jié)果還是5*5。
而SPP之所以稱之為金字塔(希望各位了解圖像金字塔的概念,不了解也沒事哈),是因?yàn)樗昧撕脦讉€ROI pooling,每一個ROI輸出的特征圖大小不同,有1*1的、2*2的、4*4的,然后把不同尺寸的特征圖的特征拉平,變成21個特征變量,就可以輸入到FC層或者SVM了。
下圖正式重現(xiàn)了上面我說的情況,三個不同的ROI總共產(chǎn)生了21個特征進(jìn)行分類。(其中的256是通道數(shù),嚴(yán)格來說是21*256個特征進(jìn)行分類)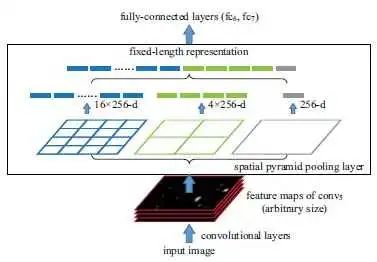
【SPPnet比RCNN好在哪里?】
通過使用SPP結(jié)構(gòu)(ROI池化層),避免了warp和crop的使用,避免了圖像失真; RCNN的處理順序是:先把候選框的圖扣出來,再放到卷積層進(jìn)行訓(xùn)練得到特征圖;SPPNet是先把原圖通過卷積層得到特征圖,然后把候選框的大小映射到特征圖上再摳出來。哪個速度快不用我多說了吧。就好比,我通知個消息,我一個一個好友的轉(zhuǎn)發(fā),與我把好友拉到一個群里,我在群里發(fā)一樣(這是個不太恰當(dāng)?shù)睦涌赡埽?傊@樣RCNN需要卷積2000個候選框,而SPPNet只需要卷積一次,速度提升了100倍。
(最后需要提的一點(diǎn)是,我并不清楚SPPNet最后的分類是用FC層還是依然使用RCNN的SVM分類,不知道SPPNet是否使用了線性回歸的方法做邊框回歸。因?yàn)槲抑皇前裇PPNet看成提出了ROI pooling的一個方法,是RCNN進(jìn)化史中的一個插曲。不過在意的朋友可以自行查找,然后方便的話告訴我哈哈哈,我懶得搞了。到這里已經(jīng)碼字3小時了)
3 Fast RCNN
SPP Net真是個好方法,R-CNN的進(jìn)階版Fast R-CNN就是在R-CNN的基礎(chǔ)上采納了SPP Net方法,對R-CNN作了改進(jìn),使得性能進(jìn)一步提高。
【R-CNN vs Fast R-CNN】
依舊使用selective search的方法來選取候選框bounding box。
**不再使用SVM+線性回歸的方法,而是全部通過神經(jīng)網(wǎng)絡(luò)來實(shí)現(xiàn)分類和邊框回歸的任務(wù)。**Fast-RCNN很重要的一個貢獻(xiàn)是成功的讓人們看到了Region Proposal + CNN這一框架的可行性,不再使用Region Proposal + CNN + SVM + LR的框架了。
現(xiàn)在梳理一些Fast RCNN推理的流程。
現(xiàn)在有一個原圖,先通過selective search得到候選框; 將原圖放到CNN中進(jìn)行特征處理,得到特征圖,然后將候選框映射到特征圖上,得到大小不同的特征圖的候選框。 把特征圖候選框放到ROI pooling層中(只有一個,不是SPP的3個ROI結(jié)構(gòu)了),輸出7*7的特征圖,這時候有512個通道,所以在ROI輸出之后,把7*7*512個特征放到FC層中。 FC層后接入了兩個不同的FC層(分支結(jié)構(gòu)),分別輸出兩個不同的結(jié)果。第一個結(jié)果加上softmax變成候選框的類別概率,第二個結(jié)果就是候選框的4個參數(shù)的邊框回歸的值。
整個流程可以看下面的圖: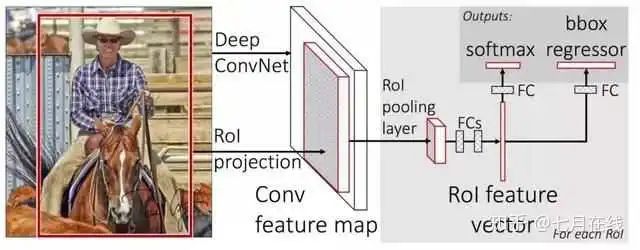
現(xiàn)在,目標(biāo)檢測一張圖片,只需要0.32秒鐘,之前的RCNN可是47秒。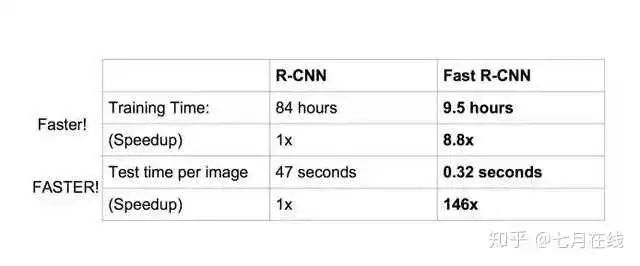
【Fast RCNN的貢獻(xiàn)】再說一下Fast RCNN的改進(jìn),其實(shí)主要改進(jìn)都是SPP Net的,用了ROI和先卷積再扣除候選框的方法(SPPNet的兩個優(yōu)點(diǎn)都用了),此外,還是用FC層直接代替了SVM和LR,這個Fast RCNN的最大貢獻(xiàn)。
4 Faster RCNN
之前Fast RCNN最消耗時間的地方,在于使用selective search來找候選框
為了更快,使用神經(jīng)網(wǎng)絡(luò)來代替selective search,所以現(xiàn)在,F(xiàn)aster RCNN整體就是一個神經(jīng)網(wǎng)絡(luò)來搞,一個端對端的模型。(輸入圖片,輸出候選框,一個模型完成所有任務(wù)所以是端對端)。
【區(qū)域候選網(wǎng)絡(luò)RPN】Faster RCNN最大的貢獻(xiàn)在一引入了Region Proposal Network(RPN)網(wǎng)絡(luò)來代替selective search。
RPN網(wǎng)絡(luò)直接放在最后一個卷積層的后面,通過一個滑動窗口,在feature map上滑動。每一個滑動窗口會給出一個置信度,置信度低的可以理解為這個窗口是沒有目標(biāo)的,置信度高的再考慮不同類別的概率。
【Archor box先驗(yàn)框】 這里還會有一個archor box的概念,因?yàn)榛瑒哟翱谝话闶钦叫蔚模菍?shí)際的目標(biāo)檢測可能是長方形。也許比較近似正方形的長方形可以通過邊框回歸矯正,但是其他的長方形物體就非常難辦了。這里事先設(shè)置了幾種不同形狀大小的候選框,除了正方形之外,還有長方形,小正方形等,這樣雖然成倍的增加了計算量,但是可以提高準(zhǔn)確度。而且這樣增加候選框的計算量消耗依然是小于selective search的。
下圖來理解之前講解的概念: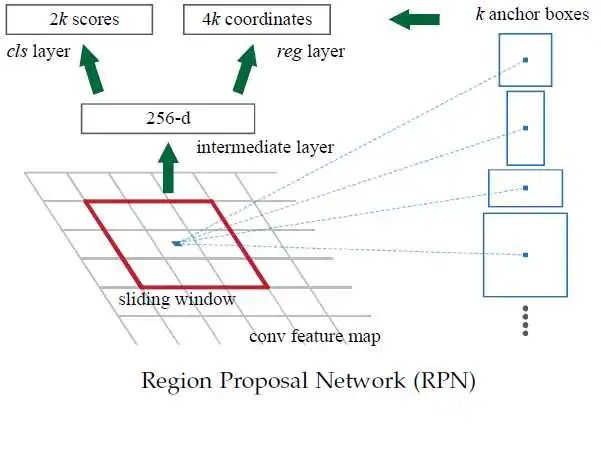 圖中有四種不同的archor box,意味著滑動到某一個位置的時候,以那個點(diǎn)為中心,產(chǎn)生四個不同大小的候選框,然后預(yù)測得到 是否是目標(biāo)物體二分類結(jié)果 和 邊框回歸四分類結(jié)果。下圖會清晰的理解這個過程:
圖中有四種不同的archor box,意味著滑動到某一個位置的時候,以那個點(diǎn)為中心,產(chǎn)生四個不同大小的候選框,然后預(yù)測得到 是否是目標(biāo)物體二分類結(jié)果 和 邊框回歸四分類結(jié)果。下圖會清晰的理解這個過程: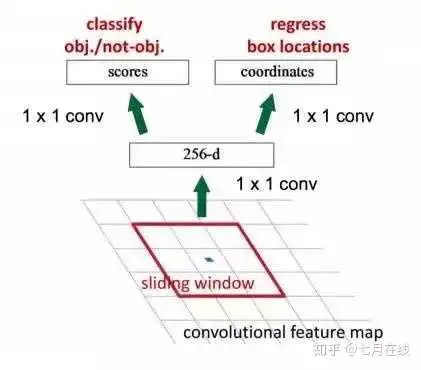
總的來說,RPN做的事情是:? 在feature map上滑動窗口 ? 建一個神經(jīng)網(wǎng)絡(luò)用于物體分類+框位置的回歸 ? 滑動窗口的位置提供了物體的大體位置信息 ? 框的回歸提供了框更精確的位置
整個網(wǎng)絡(luò)有四個損失函數(shù):
RPN的二分類損失函數(shù) RPN的邊框回歸損失函數(shù) FAST RCNN的多分類損失函數(shù) Fast RCNN的邊框回歸損失函數(shù) 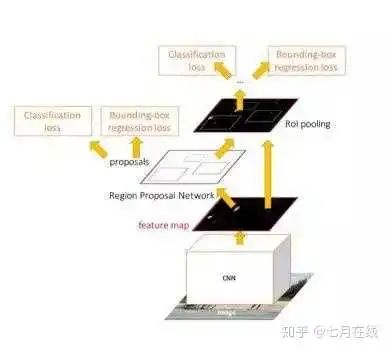
然后看看速度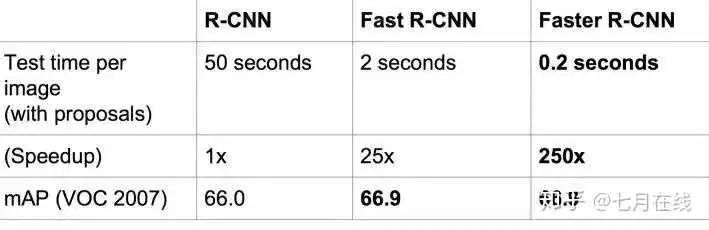 比Fast RCNN更快了。Faster R-CNN的主要貢獻(xiàn)就是設(shè)計了提取候選區(qū)域的網(wǎng)絡(luò)RPN,代替了費(fèi)時的選擇性搜索Selective Search,使得檢測速度大幅提高。
比Fast RCNN更快了。Faster R-CNN的主要貢獻(xiàn)就是設(shè)計了提取候選區(qū)域的網(wǎng)絡(luò)RPN,代替了費(fèi)時的選擇性搜索Selective Search,使得檢測速度大幅提高。
5 總結(jié)
這里有個圖來總結(jié):
項目 | R-CNN | Fast R-CNN | Faster R-CNN |
提取候選框 | Selective Search | Selective Search | RPN網(wǎng)絡(luò) |
提取特征 | 卷積神經(jīng)網(wǎng)絡(luò)(CNN) | 卷積神經(jīng)網(wǎng)絡(luò)+ROI池化 | |
特征分類 | SVM | ||
R-CNN(Selective Search + CNN + SVM)
SPP-net(ROI Pooling)
Fast R-CNN(Selective Search + CNN + ROI)
Faster R-CNN(RPN + CNN + ROI)
往期精彩回顧
獲取一折本站知識星球優(yōu)惠券,復(fù)制鏈接直接打開:
https://t.zsxq.com/yFQV7am
本站qq群1003271085。
加入微信群請掃碼進(jìn)群: