
各種 Optimizer 梯度下降優(yōu)化算法總結(jié)
來源:https://zhuanlan.zhihu.com/p/343564175
論文標(biāo)題:An overview of gradient descent optimization algorithms
原文鏈接:https://arxiv.org/pdf/1609.04747.pdfGithub:NLP相關(guān)Paper筆記和代碼復(fù)現(xiàn)(https://github.com/DengBoCong/nlp-paper)
說明:閱讀論文時進(jìn)行相關(guān)思想、結(jié)構(gòu)、優(yōu)缺點(diǎn),內(nèi)容進(jìn)行提煉和記錄,論文和相關(guān)引用會標(biāo)明出處,引用之處如有侵權(quán),煩請告知刪除。
寫在前面
計算目標(biāo)函數(shù)關(guān)于當(dāng)前參數(shù)的梯度: 根據(jù)歷史梯度計算一階動量和二階動量: 計算當(dāng)前時刻的下降梯度: 根據(jù)下降梯度進(jìn)行更新:
鞍點(diǎn):一個光滑函數(shù)的鞍點(diǎn)鄰域的曲線,曲面,或超曲面,都位于這點(diǎn)的切線的不同邊。例如這個二維圖形,像個馬鞍:在x-軸方向往上曲,在y-軸方向往下曲,鞍點(diǎn)就是(0,0)。

指數(shù)加權(quán)平均、偏差修正:可參見這篇文章
Gradient Descent(GD)

訓(xùn)練速度慢:在應(yīng)用于大型數(shù)據(jù)集中,每輸入一個樣本都要更新一次參數(shù),且每次迭代都要遍歷所有的樣本,會使得訓(xùn)練過程及其緩慢,需要花費(fèi)很長時間才能得到收斂解。 容易陷入局部最優(yōu)解:由于是在有限視距內(nèi)尋找下山的反向,當(dāng)陷入平坦的洼地,會誤以為到達(dá)了山地的最低點(diǎn),從而不會繼續(xù)往下走。所謂的局部最優(yōu)解就是鞍點(diǎn),落入鞍點(diǎn),梯度為0,使得模型參數(shù)不在繼續(xù)更新。
Batch Gradient Descent(BGD)
Stochastic Gradient Descent(SGD)

雖然看起來SGD波動非常大,會走很多彎路,但是對梯度的要求很低(計算梯度快),而且對于引入噪聲,大量的理論和實踐工作證明,只要噪聲不是特別大,SGD都能很好地收斂。 應(yīng)用大型數(shù)據(jù)集時,訓(xùn)練速度很快。比如每次從百萬數(shù)據(jù)樣本中,取幾百個數(shù)據(jù)點(diǎn),算一個SGD梯度,更新一下模型參數(shù)。相比于標(biāo)準(zhǔn)梯度下降法的遍歷全部樣本,每輸入一個樣本更新一次參數(shù),要快得多。
SGD在隨機(jī)選擇梯度的同時會引入噪聲,使得權(quán)值更新的方向不一定正確(次要)。 SGD也沒能單獨(dú)克服局部最優(yōu)解的問題(主要)。
Mini-batch Gradient Descent(MBGD,也叫作SGD)
Mini-batch gradient descent 不能保證很好的收斂性,learning rate 如果選擇的太小,收斂速度會很慢,如果太大,loss function 就會在極小值處不停地震蕩甚至偏離(有一種措施是先設(shè)定大一點(diǎn)的學(xué)習(xí)率,當(dāng)兩次迭代之間的變化低于某個閾值后,就減小 learning rate,不過這個閾值的設(shè)定需要提前寫好,這樣的話就不能夠適應(yīng)數(shù)據(jù)集的特點(diǎn))。對于非凸函數(shù),還要避免陷于局部極小值處,或者鞍點(diǎn)處,因為鞍點(diǎn)所有維度的梯度都接近于0,SGD 很容易被困在這里(會在鞍點(diǎn)或者局部最小點(diǎn)震蕩跳動,因為在此點(diǎn)處,如果是BGD的訓(xùn)練集全集帶入,則優(yōu)化會停止不動,如果是mini-batch或者SGD,每次找到的梯度都是不同的,就會發(fā)生震蕩,來回跳動)。 SGD對所有參數(shù)更新時應(yīng)用同樣的 learning rate,如果我們的數(shù)據(jù)是稀疏的,我們更希望對出現(xiàn)頻率低的特征進(jìn)行大一點(diǎn)的更新, 且learning rate會隨著更新的次數(shù)逐漸變小。
Momentum

隨機(jī)梯度的方法(引入的噪聲) Hessian矩陣病態(tài)問題(可以理解為SGD在收斂過程中和正確梯度相比來回擺動比較大的問題)。
Nesterov Accelerated Gradient

Adagrad
仍需要手工設(shè)置一個全局學(xué)習(xí)率 , 如果 設(shè)置過大的話,會使regularizer過于敏感,對梯度的調(diào)節(jié)太大 中后期,分母上梯度累加的平方和會越來越大,使得參數(shù)更新量趨近于0,使得訓(xùn)練提前結(jié)束,無法學(xué)習(xí)
Adadelta
訓(xùn)練初中期,加速效果不錯,很快 訓(xùn)練后期,反復(fù)在局部最小值附近抖動
RMSprop
其實RMSprop依然依賴于全局學(xué)習(xí)率 RMSprop算是Adagrad的一種發(fā)展,和Adadelta的變體,效果趨于二者之間 適合處理非平穩(wěn)目標(biāo)(包括季節(jié)性和周期性)——對于RNN效果很好
Adaptive Moment Estimation(Adam)
Adam梯度經(jīng)過偏置校正后,每一次迭代學(xué)習(xí)率都有一個固定范圍,使得參數(shù)比較平穩(wěn)。 結(jié)合了Adagrad善于處理稀疏梯度和RMSprop善于處理非平穩(wěn)目標(biāo)的優(yōu)點(diǎn) 為不同的參數(shù)計算不同的自適應(yīng)學(xué)習(xí)率 也適用于大多非凸優(yōu)化問題——適用于大數(shù)據(jù)集和高維空間。
AdaMax
Nadam
下圖描述了在一個曲面上,6種優(yōu)化器的表現(xiàn):

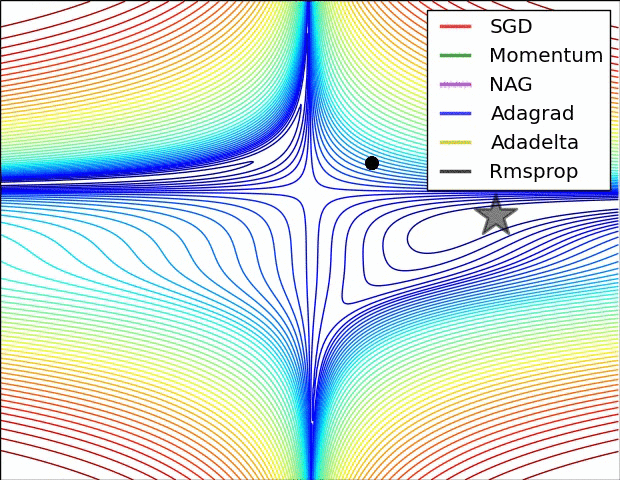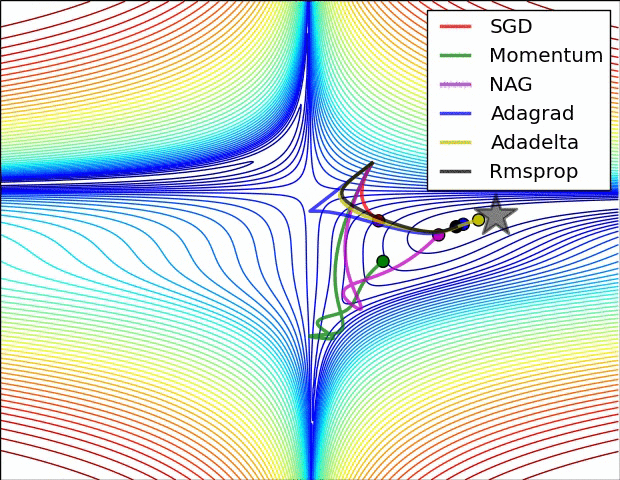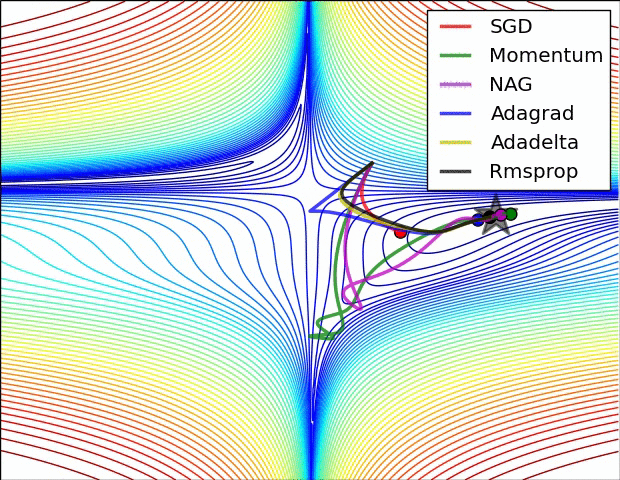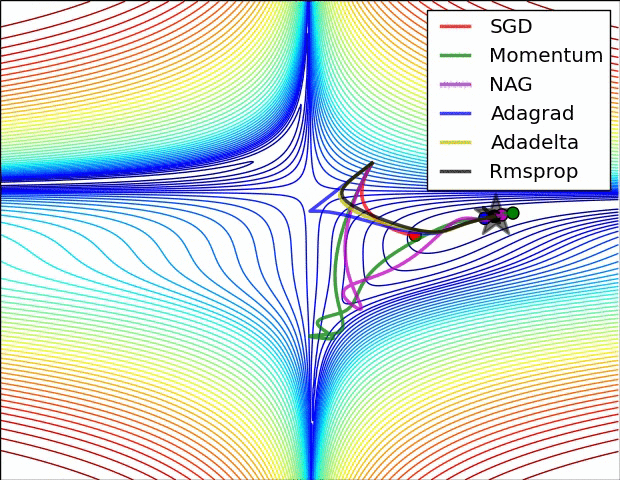
下圖在一個存在鞍點(diǎn)的曲面,比較6中優(yōu)化器的性能表現(xiàn):

下圖圖比較了6種優(yōu)化器收斂到目標(biāo)點(diǎn)(五角星)的運(yùn)行過程
總結(jié)
對于稀疏數(shù)據(jù),盡量使用學(xué)習(xí)率可自適應(yīng)的優(yōu)化方法,不用手動調(diào)節(jié),而且最好采用默認(rèn)值 SGD通常訓(xùn)練時間更長,但是在好的初始化和學(xué)習(xí)率調(diào)度方案的情況下,結(jié)果更可靠 如果在意更快的收斂,并且需要訓(xùn)練較深較復(fù)雜的網(wǎng)絡(luò)時,推薦使用學(xué)習(xí)率自適應(yīng)的優(yōu)化方法。 Adadelta,RMSprop,Adam是比較相近的算法,在相似的情況下表現(xiàn)差不多。 在想使用帶動量的RMSprop,或者Adam的地方,大多可以使用Nadam取得更好的效果 如果驗證損失較長時間沒有得到改善,可以停止訓(xùn)練。 添加梯度噪聲(高斯分布 )到參數(shù)更新,可使網(wǎng)絡(luò)對不良初始化更加健壯,并有助于訓(xùn)練特別深而復(fù)雜的網(wǎng)絡(luò)。
An overview of gradient descent optimization algorithms(https://ruder.io/optimizing-gradient-descent/) 深度學(xué)習(xí)最全優(yōu)化方法總結(jié)比較(SGD,Adagrad,Adadelta,Adam,Adamax,Nadam)(https://zhuanlan.zhihu.com/p/22252270) visualize_optimizers(https://github.com/snnclsr/visualize_optimizers) lossfunctions(https://lossfunctions.tumblr.com/) 優(yōu)化算法Optimizer比較和總結(jié)(https://zhuanlan.zhihu.com/p/55150256) 一個框架看懂優(yōu)化算法之異同 SGD/AdaGrad/Adam(https://zhuanlan.zhihu.com/p/32230623) 深度學(xué)習(xí)——優(yōu)化器算法Optimizer詳解(BGD、SGD、MBGD、Momentum、NAG、Adagrad、Adadelta、RMSprop、Adam)(https://www.cnblogs.com/guoyaohua/p/8542554.html) 機(jī)器學(xué)習(xí):各種優(yōu)化器Optimizer的總結(jié)與比較(https://blog.csdn.net/weixin_40170902/article/details/80092628) optimizer優(yōu)化算法總結(jié)(https://blog.csdn.net/muyu709287760/article/details/62531509#%E4%B8%89%E7%A7%8Dgradient-descent%E5%AF%B9%E6%AF%94)
評論
圖片
表情