
突發(fā)!美國(guó)又“出手”了!
大家好,我是 Jack。
今天繼續(xù)聊聊互聯(lián)網(wǎng)上發(fā)生的那些事,又是聊技術(shù)、聊“八卦”的一天~
一、美國(guó)升級(jí)對(duì)華芯片出口限制
去年 10 月,美國(guó)升級(jí)了對(duì)華半導(dǎo)體出口管制,以 Nvidia A100 芯片的性能指標(biāo)作為限制標(biāo)準(zhǔn),限制對(duì)華出口高性能計(jì)算芯片。
時(shí)隔一年,10 月 17 日,美國(guó)再次“出手”,計(jì)劃繼續(xù)升級(jí)出口限制,據(jù)悉 Nvidia A800 和 H800 芯片也將無法出口給中國(guó)。

10 月 16 日晚,美國(guó)商務(wù)部長(zhǎng) Gina Raimondo 曾告訴記者,新政策的目的在于修正去年 10 月發(fā)布的法規(guī),未來可能會(huì)進(jìn)行“至少每年一次”的更新。
此外,美國(guó)商務(wù)部還于 10 月 17 日將壁仞科技、摩爾線程等多家中國(guó) GPU 芯片企業(yè)列入了受限實(shí)體清單。
具體包括:北京壁仞科技開發(fā)有限公司、廣州壁仞集成電路有限公司、杭州壁仞科技開發(fā)有限公司、光線云(杭州)科技有限公司、摩爾線程智能科技(北京)有限責(zé)任公司、摩爾線程智能科技(成都)有限責(zé)任公司、摩爾線程智能科技(上海)有限責(zé)任公司、上海壁仞信息科技有限公司、上海壁仞集成電路有限公司、上海壁仞科技股份有限公司、超燃半導(dǎo)體(南京)有限公司、蘇州芯延半導(dǎo)體科技有限公司、珠海壁仞集成電路有限公司。

二、國(guó)美 APP 罵創(chuàng)始人
最近有一則消息,當(dāng)用戶打開國(guó)美APP上的“幸運(yùn)大轉(zhuǎn)盤”抽獎(jiǎng)頁面時(shí),彈出的文案包含了對(duì)國(guó)美電器董事長(zhǎng)黃秀虹和創(chuàng)始人黃光裕的侮辱性言辭,指控其拖欠工資、拖欠貨款,“早晚得再進(jìn)去蹲幾年”。
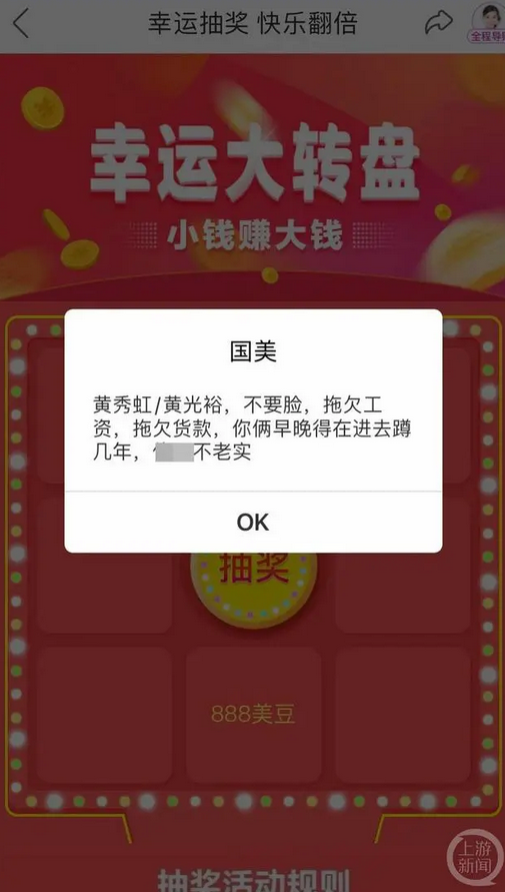
據(jù)說,國(guó)美從去年 10 月份就開始拖欠薪資了 。
網(wǎng)友們調(diào)侃:這是程序員的憤怒和吶喊。
不過這個(gè)“鍋”程序員可不背,畢竟一個(gè)運(yùn)營(yíng)活動(dòng)上線,要經(jīng)過策劃、產(chǎn)品、研發(fā)的通力合作,還要有測(cè)試、運(yùn)營(yíng)的驗(yàn)收。
只能說整條產(chǎn)品線的人,都或多或少參與其中,這也實(shí)屬被逼無奈之舉吧。
當(dāng)然,這種做法并不理智,雖然此舉會(huì)引發(fā)社會(huì)對(duì)于國(guó)美欠薪問題的關(guān)注,但自己也會(huì)受到懲罰。
碰到欠薪行為的公司,明智一些的做法是:及時(shí)止損,趕緊跑路,然后聯(lián)合同事申請(qǐng)勞動(dòng)仲裁。
雖然過程艱辛,但至少是合法維權(quán)途徑。
希望咱們打工人,都不會(huì)遇到這樣的糟心公司和老板。
三、AudioSep
這條上點(diǎn)“干貨”:AudioSep。
我們經(jīng)常會(huì)碰到從紛繁的音頻中提取和分離所需聲音的需求。
比如最簡(jiǎn)單的:從嘈雜的音頻中提取人聲。
最近,有一篇新研究,通過自然語言即可提取想要的音頻。
我們先看 AudioSep 的效果。
這段音頻混合著手風(fēng)琴和其它聲音,想要提取其中干凈的手風(fēng)琴聲音。
那么,只需要對(duì)算法輸入:
accordion
翻譯為:手風(fēng)琴,AudioSep 算法就能自動(dòng)從這段音頻中提取對(duì)應(yīng)的聲音,這是提取后的效果:
再比如,這也是一段音頻:
想要提起其中的吉他原聲,只需要輸入:
acoustic guitar
干凈的音頻就提取出來了:
是不是效果很不錯(cuò)?
不僅是這些音頻,說話、笑聲也可以,比如這是一段帶著背景噪音的笑聲:
只需要輸入:
laughing
就能提取出干凈的笑聲:
各種聲音都可以通過自然語言提取,鍵盤聲、流水聲、貓叫等等。
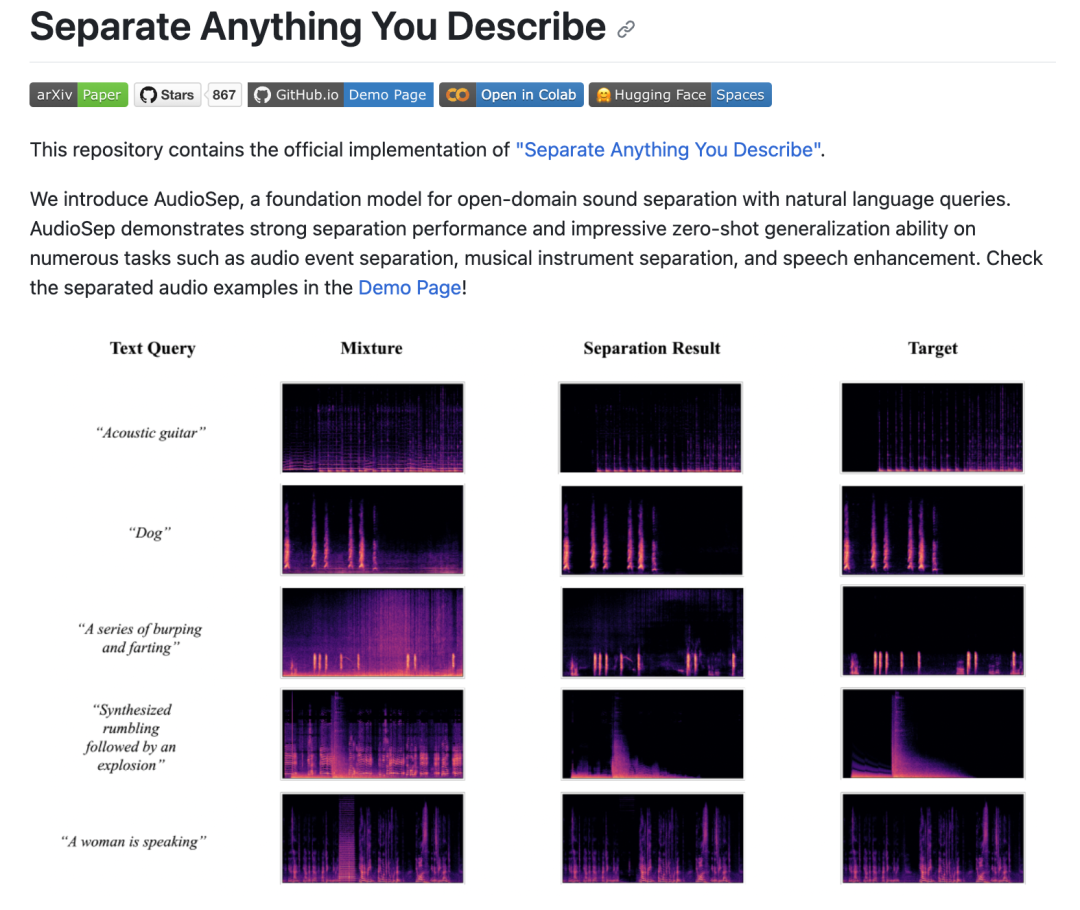
目前算法已經(jīng)開源:
https://github.com/audio-agi/audiosep
使用方法很簡(jiǎn)單,首先配置開發(fā)環(huán)境:
git clone https://github.com/Audio-AGI/AudioSep.git && \
cd AudioSep && \
conda env create -f environment.yml && \
conda activate AudioSep
然后下載模型權(quán)重文件放到 checkpoint 目錄中。
然后就可以通過如下方式調(diào)用,進(jìn)行預(yù)測(cè):
from pipeline import build_audiosep, inference
import torch
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = build_audiosep(
config_yaml='config/audiosep_base.yaml',
checkpoint_path='checkpoint/audiosep_base_4M_steps.ckpt',
device=device)
audio_file = 'path_to_audio_file'
text = 'textual_description'
output_file='separated_audio.wav'
# AudioSep processes the audio at 32 kHz sampling rate
inference(model, audio_file, text, output_file, device)
感興趣的小伙伴不妨試一試!
今天就聊這么多吧,我是 Jack,我們下期見!
 ·················END·················
·················END·················