高頻數(shù)據(jù)庫 MySQL 面試題
不點藍字,我們哪來故事?

正文如下
來源 | 網(wǎng)絡(luò)
MySQL 索引使用什么數(shù)據(jù)結(jié)構(gòu)?為什么用 B+做索引?
使用B+樹。
這個問題,可以在腦子里面先思考一下,如果讓你來設(shè)計數(shù)據(jù)庫的索引,你會怎么設(shè)計?
我們還是用Why?What?How?三步法來看這個問題。
為什么會需要索引?索引是什么?索引怎么用的?
再思考為什么需要B+樹?B+樹是什么?B+樹怎么用?
答:大部分程序主要的功能都是對數(shù)據(jù)的處理,寫入、查詢、轉(zhuǎn)化、輸出。最形象的比喻就是樹和內(nèi)容和目錄的關(guān)系,目錄就是索引,我們根據(jù)目錄能快速拿到想要內(nèi)容的頁碼。
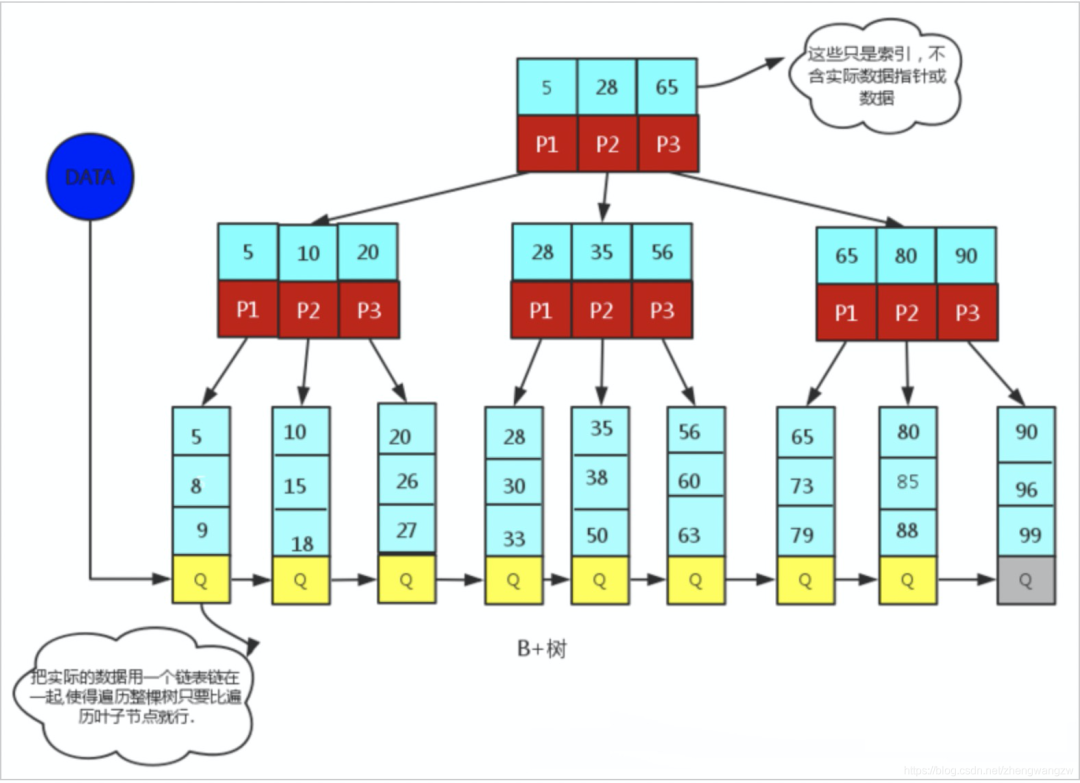
為什么是B+樹,有這個幾個理由:
如果是用AVL平衡二叉樹,樹高度太高,索引查詢需要訪問磁盤,每次訪問以節(jié)點為單位進行磁盤I/O ,需要盡量減少數(shù)據(jù)讀取的I/O操作,所以樹高度一定不能太高,存儲千萬級別的數(shù)據(jù),實踐中 B+ 樹的高度也就 4或者5。 B+樹經(jīng)常用來比較的是B樹,B+樹相比B樹有個很大的特點是B+樹所有關(guān)鍵字都出現(xiàn)在葉子結(jié)點的鏈表中(稠密索引),且鏈表中的關(guān)鍵字恰好是有序的,對于范圍查找,比如15~50,B樹需要中序遍歷二叉樹,但是B+樹直接在葉子節(jié)點順序訪問就可以了。
什么是最左匹配原則?
首先說明一點:
最左前綴匹配原則:在MySQL建立聯(lián)合索引時會遵守最左前綴匹配原則,即最左優(yōu)先,在檢索數(shù)據(jù)時從聯(lián)合索引的最左邊開始匹配。
打個比方,我們有張student 表,我們根據(jù)學(xué)院編號+班級建立了一個聯(lián)合索引 index_magor_class(magor,class), 這個索引由二個字段組成。
索引的底層是一顆B+樹,那么聯(lián)合索引的底層也就是一顆B+樹,只不過聯(lián)合索引的B+樹節(jié)點中存儲的是逗號分隔的多個值。
舉例:創(chuàng)建一個 index_magor_class(magor,class) 的聯(lián)合索引,那么它的索引樹就是下圖的樣子。
它是先根據(jù)magor排序,再根據(jù)class排序,如果索引后面還有字段,繼續(xù)以此類推。

我們查詢的where 條件如果只傳入了班級,是走不到聯(lián)合索引的,但是如果只傳了學(xué)院編號,是可能會走到聯(lián)合索引的。(為什么說可能,MYSQL的執(zhí)行計劃和查詢的實際執(zhí)行過程并不完全吻合,比如你數(shù)據(jù)庫數(shù)據(jù)量很少,可能直接全量遍歷速度更快,就不走索引了)
往期推薦
在建表的時候如何設(shè)計索引的?有沒有做過索引優(yōu)化 ?
1、利用覆蓋索引來進行查詢操作,來避免回表操作。
說明:如果一本書需要知道第11章是什么標(biāo)題,會翻開第11章對應(yīng)的那一頁嗎?目錄瀏覽一下就好,這個目錄就是起到覆蓋索引的作用。
什么意思,比如你主鍵索引是學(xué)號,你寫select 語句的時候,直接select 學(xué)號 from table 就可以了,不用select 其他字段,一般除非非常有必要,盡量按需select 字段,少用或不用 select, 不然還需要回表。
這里我解釋一下回表,比如我們表主鍵索引是學(xué)號,另外我們還根據(jù)手機號也建了索引,如果我們where 條件是手機號,分二種情況:
正例:IDB能夠建立索引的種類分為【主鍵索引、唯一索引、普通索引】,而覆蓋索引是一種查詢的一種效果,用explain的結(jié)果,extra列會出現(xiàn):using index.
如果我們select 獲取的字段是學(xué)號,直接在手機號的索引表就能獲取到數(shù)據(jù),不需要回表; 如果我們select 的時候還有其他字段,我們查詢的時候流程是這樣的,先根據(jù)手機號查到學(xué)號,再根據(jù)學(xué)號去主鍵索引表查詢數(shù)據(jù),這個過程叫回表。
2、業(yè)務(wù)上具有唯一特性的字段,即使是組合字段,也建議建成唯一索引。說明:不要以為唯一索引影響了insert速度,這個速度損耗可以忽略,但提高查找速度是明顯的;另外,即使在應(yīng)用層做了非常完善的校驗和控制,只要沒有唯一索引,根據(jù)墨菲定律,必然有臟數(shù)據(jù)產(chǎn)生。
3、超過三個表禁止join。需要join的字段,數(shù)據(jù)類型保持絕對一致;多表關(guān)聯(lián)查詢時,保證被關(guān)聯(lián)的字段需要有索引。說明:即使雙表join也要注意表索引、SQL性能。
4、在varchar字段上建立索引時,必須指定索引長度,沒必要對全字段建立索引,根據(jù)實際文本區(qū)分度決定索引長度。說明:索引的長度與區(qū)分度是一對矛盾體,一般對字符串類型數(shù)據(jù),長度為20的索引,區(qū)分度會高達90%以上,可以使用count(distinct left(列名, 索引長度))/count(*)的區(qū)分度來確定。
5、頁面搜索嚴(yán)禁左模糊或者全模糊,如果需要請走搜索引擎來解決。說明:索引文件具有B-Tree的最左前綴匹配特性,如果左邊的值未確定,那么無法使用此索引。
6、SQL性能優(yōu)化的目標(biāo):至少要達到 range 級別,要求是ref級別,如果可以是const最好。說明:
1)const 單表中最多只有一個匹配行(主鍵或者唯一索引),在優(yōu)化階段即可讀取到數(shù)據(jù)。 2)ref 指的是使用普通的索引。(normal index) 3)range 對索引進行范圍檢索。反例:explain表的結(jié)果,type=index,索引物理文件全掃描,速度非常慢,這個index級別比較range還低,與全表掃描是小巫見大巫。
7、建組合索引的時候,區(qū)分度最高的在最左邊。正例:如果where a=? and b=? ,a列的幾乎接近于唯一值,那么只需要單建idx_a索引即可。說明:存在非等號和等號混合判斷條件時,在建索引時,請把等號條件的列前置。如:where c>? and d=? 那么即使c的區(qū)分度更高,也必須把d放在索引的最前列,即建立組合索引idx_d_c。
8、防止因字段類型不同造成的隱式轉(zhuǎn)換,導(dǎo)致索引失效。
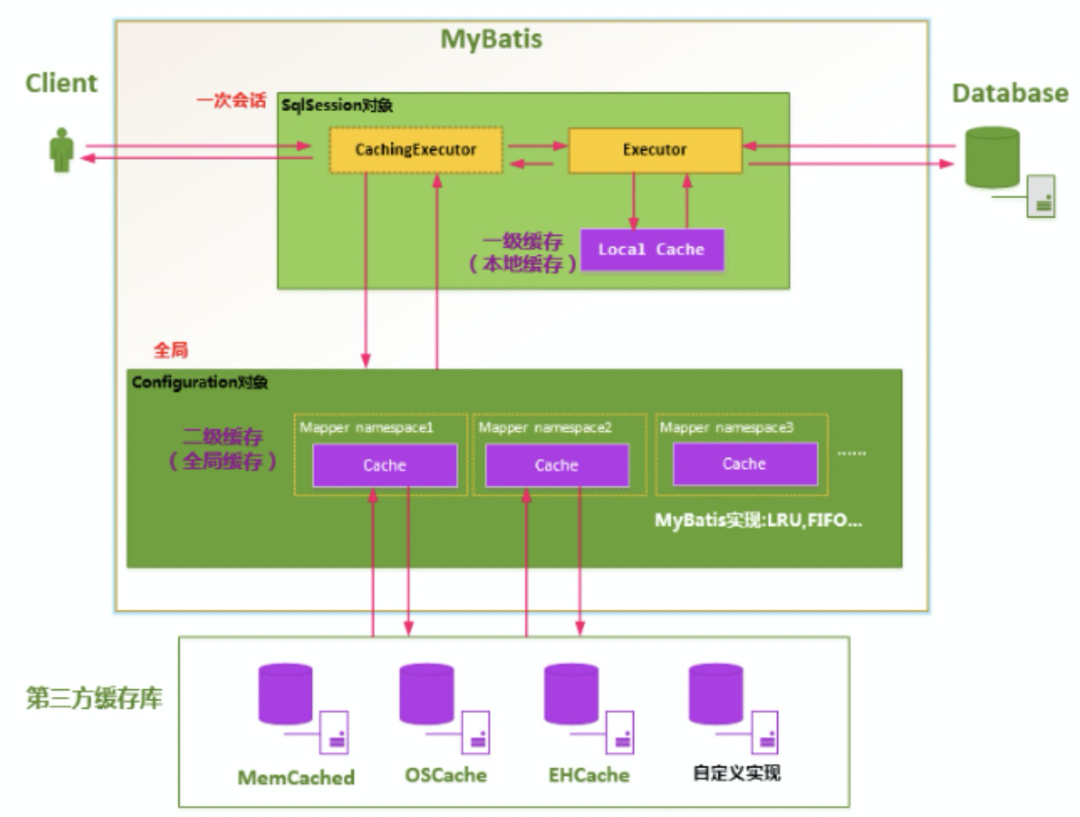
MyBatis用過嗎? 一二級緩存清楚嗎?
一級緩存 Mybatis的一級緩存是指SQLSession,一級緩存的作用域是SQlSession, Mabits默認(rèn)開啟一級緩存。在同一個SqlSession中,執(zhí)行相同的SQL查詢時;第一次會去查詢數(shù)據(jù)庫,并寫在緩存中,第二次會直接從緩存中取。當(dāng)執(zhí)行SQL時候兩次查詢中間發(fā)生了增刪改的操作,則SQLSession的緩存會被清空。每次查詢會先去緩存中找,如果找不到,再去數(shù)據(jù)庫查詢,然后把結(jié)果寫到緩存中。Mybatis的內(nèi)部緩存使用一個HashMap,key為hashcode+statementId+sql語句。Value為查詢出來的結(jié)果集映射成的java對象。SqlSession執(zhí)行insert、update、delete等操作commit后會清空該SQLSession緩存。 二級緩存 二級緩存是 mapper級別的,Mybatis默認(rèn)是沒有開啟二級緩存的。第一次調(diào)用mapper下的SQL去查詢用戶的信息,查詢到的信息會存放在該mapper對應(yīng)的二級緩存區(qū)域。第二次調(diào)用namespace下的mapper映射文件中,相同的sql去查詢用戶信息,會去對應(yīng)的二級緩存內(nèi)取結(jié)果。
MySQL 主從同步怎么做的?binlog清楚嗎?
Master 數(shù)據(jù)庫只要發(fā)生變化,立馬記錄到Binary log 日志文件中 Slave數(shù)據(jù)庫啟動一個I/O thread連接Master數(shù)據(jù)庫,請求Master變化的二進制日志 Slave I/O獲取到的二進制日志,保存到自己的Relay log 日志文件中。 Slave 有一個 SQL thread定時檢查Realy log是否變化,變化那么就更新數(shù)據(jù)

MySQL 有沒有做分庫分表?怎么設(shè)計的?
Why?:
當(dāng)一張表的數(shù)據(jù)達到幾千萬時,你查詢一次所花的時間會變多,如果有聯(lián)合查詢的話,我想有可能會死在那兒了。分表的目的就在于此,減小數(shù)據(jù)庫的負擔(dān),縮短查詢時間。
mysql中有一種機制是表鎖定和行鎖定,是為了保證數(shù)據(jù)的完整性。表鎖定表示你們都不能對這張表進行操作,必須等我對表操作完才行。行鎖定也一樣,別的sql必須等我對這條數(shù)據(jù)操作完了,才能對這條數(shù)據(jù)進行操作。
When?(什么時候需要分表?):
單表行數(shù)超過500萬行或者單表容量超過2GB,才推薦進行分庫分表。說明:如果預(yù)計三年后的數(shù)據(jù)量根本達不到這個級別,請不要在創(chuàng)建表時就分庫分表。
反例:某業(yè)務(wù)三年總數(shù)據(jù)量才2萬行,卻分成1024張表,問:你為什么這么設(shè)計?答:分1024張表,不是標(biāo)配嗎?
How?(分庫分表有幾種策略):
垂直拆分 or 水平拆分
拆分中間件,詳細可以參考:
Sharding-sphere,前身是sharding-jdbc;當(dāng)當(dāng)?shù)姆謳旆直碇虚g件 TDDL:jar,Taobao Distribute Data Layer; Mycat:中間件。
注:工具的利弊,請自行調(diào)研,官網(wǎng)和社區(qū)優(yōu)先。
按照userId緯度拆分,安琪拉見過的常見的有,根據(jù) userId % 64 取模拆0~63編號的64張表, 固定位拆,取userId 指定二位,例如倒數(shù)2,3位組成00~99 一共100張表的,百庫表表。 hash: userId hash一下,然后 % 表數(shù); Range: 另外還有按照userId 指定范圍拆的,0-1千萬一張表,這種用的比較少,容易產(chǎn)生熱點。 把不同業(yè)務(wù)域的表拆成不同庫,例如訂單相關(guān)表、用戶信息相關(guān)表、營銷相關(guān)表分開在不同庫; 把大字段獨立存儲到一張表中 把不常用的字段單獨拿出來存儲到一張表
用userId做的分庫分表,現(xiàn)在需要用電話號碼查詢怎么辦?
和回表邏輯一樣,單獨建一個電話號碼索引表,存放電話號碼和userId,查詢時先根據(jù)電話號碼查詢userId,然后再根據(jù)userId查詢數(shù)據(jù)。
往期推薦
(推薦頭條列表)
END
若覺得文章對你有幫助,隨手轉(zhuǎn)發(fā)分享,也是我們繼續(xù)更新的動力。
長按二維碼,掃掃關(guān)注哦
?「C語言中文網(wǎng)」官方公眾號,關(guān)注手機閱讀教程 ?