
使用 OpenCV 進(jìn)行圖像分割
點擊上方“小白學(xué)視覺”,選擇加"星標(biāo)"或“置頂”
重磅干貨,第一時間送達(dá)


圖像分割是將數(shù)字圖像劃分互不相交的區(qū)域的過程,它可以降低圖像的復(fù)雜性,從而使分析圖像變得更簡單。
在癌細(xì)胞檢測系統(tǒng)中可以看到獨特而著名的應(yīng)用之一,其中圖像分割被證明在從圖像中更快地檢測疾病組織和細(xì)胞方面發(fā)揮了關(guān)鍵作用,從而使醫(yī)生能夠提供及時的治療。
制造制業(yè)現(xiàn)在高度依賴于圖像識別技術(shù)來檢測人眼所忽略掉的異常,因此增加了產(chǎn)品的效率。
我們有以下圖像分割技術(shù):
閾值法
基于邊緣的分割
基于區(qū)域的分割
基于聚類的分割
基于分水嶺的方法
基于人工神經(jīng)網(wǎng)絡(luò)的分割
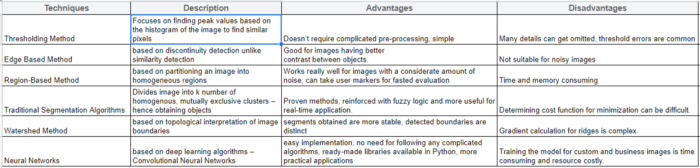
不同技術(shù)之間的比較
在這里,我們選擇了基于聚類的分割。
與分類算法不同,聚類算法是無監(jiān)督算法。在分類算法中,用戶沒有預(yù)定義的一組特征、類或組。聚類算法有助于從數(shù)據(jù)中獲取潛在的、隱藏的信息,例如從啟發(fā)式的角度來看通常是未知的結(jié)構(gòu)、聚類和分組。
基于聚類的技術(shù)將圖像分割成具有相似特征的集群或不相交的像素組。憑借基本的數(shù)據(jù)聚類特性,數(shù)據(jù)元素被分割成集群,使得同一集群中的元素與其他集群相比更加相似。一些更有效的聚類算法,如 k 均值、改進(jìn)的 k 均值、模糊 c 均值 (FCM) 和改進(jìn)的模糊 c 均值算法 (IFCM) 被廣泛用于所提出的基于聚類的方法中。
K 均值聚類算法是一種精選的、流行的方法,因為它的簡單性和計算效率。改進(jìn)的 K 均值算法可以最小化 k 均值算法中通常涉及的迭代次數(shù)。
由于某些相似性,集群指的是聚合在一起的數(shù)據(jù)點集合。對于圖像分割,這里的集群是不同的圖像顏色。
導(dǎo)入庫
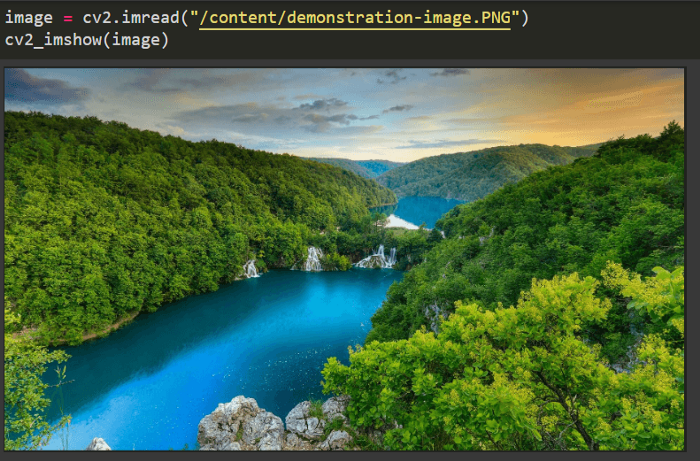
加載輸入圖像并在 OpenCV 上進(jìn)行處理
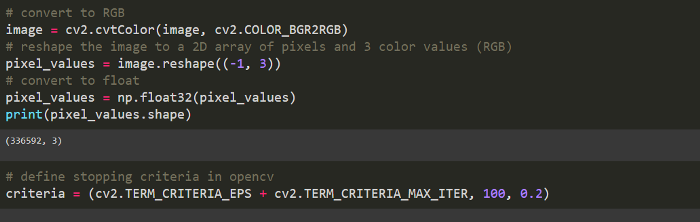
執(zhí)行分段的步驟:
將圖像轉(zhuǎn)換為RGB格式
將圖像重塑為由像素和 3 個顏色值 (RGB) 組成的二維數(shù)組
cv2.kmeans() 函數(shù)將二維數(shù)組作為輸入,因此我們必須將圖像展平
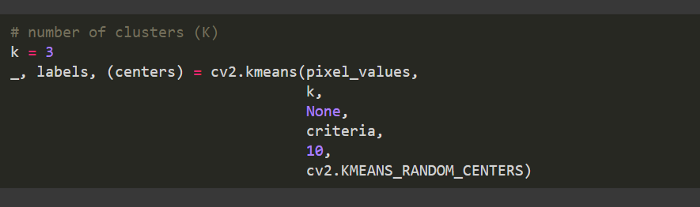
定義集群形成的停止標(biāo)準(zhǔn)
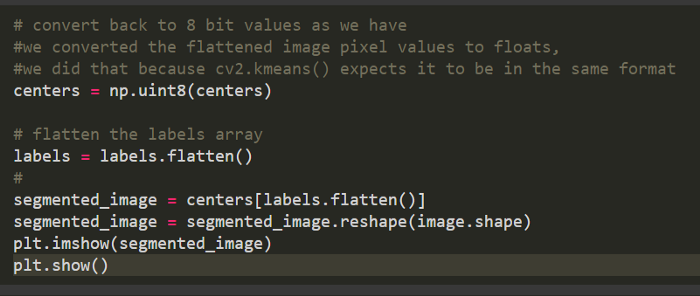
轉(zhuǎn)換回原始圖像形狀并顯示分割后的圖像
K均值是最簡單的無監(jiān)督學(xué)習(xí)算法之一,通常可以解決聚類問題。該過程遵循一種簡單易行的方法,通過一定數(shù)量的先驗固定的集群對給定圖像進(jìn)行分類。
該算法實際上從圖像空間被劃分為 k 個像素的開始,表示 k 個組質(zhì)心。然后根據(jù)每個對象與集群的距離將其分配給該組,當(dāng)所有像素都分配給所有集群時,質(zhì)心現(xiàn)在移動并重新分配。重復(fù)這些步驟,直到質(zhì)心不再移動。
在該算法收斂時,我們將圖像中的區(qū)域分割為“K”組,其中組成像素顯示出一定程度的相似性。
輸入?yún)?shù)
samples:它應(yīng)該是np.float32數(shù)據(jù)類型,每個特征應(yīng)該放在一個列中。
nclusters(K)?:?結(jié)束時所需的集群數(shù)量。
criteria:它是迭代終止標(biāo)準(zhǔn)。當(dāng)滿足此條件時,算法迭代停止。實際上,它應(yīng)該是一個包含 3 個參數(shù)的元組,它們是"( type, max_iter, epsilon )"。
a.終止標(biāo)準(zhǔn)的類型,它有 3 個標(biāo)志,如下所示:
cv.TERM_CRITERIA_EPS — 如果達(dá)到指定的精度epsilon,則停止算法迭代。
cv.TERM_CRITERIA_MAX_ITER — 在指定的迭代次數(shù)max_iter后停止算法。
cv.TERM_CRITERIA_EPS + cv.TERM_CRITERIA_MAX_ITER — 當(dāng)滿足上述任何條件時停止迭代。
b.max_iter — 指定最大迭代次數(shù)的整數(shù)。
c.epsilon - 所需的準(zhǔn)確性。
attempts :標(biāo)記以指定使用不同的初始標(biāo)簽執(zhí)行算法的次數(shù)。該算法返回產(chǎn)生最佳緊湊性的標(biāo)簽,這種緊湊性作為輸出返回。
flags:此標(biāo)志用于指定初始中心的使用方式。通常使用兩個標(biāo)志:cv.KMEANS_PP_CENTERS和cv.KMEANS_RANDOM_CENTERS。
compactness :它是每個點到其相應(yīng)中心的距離平方和。
labels :這是標(biāo)簽數(shù)組,其中每個元素都標(biāo)記為“0”、“1”……
centers:這是一系列集群中心。
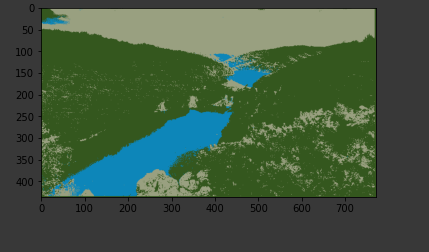
在這里,當(dāng)我們看到圖像時,有三種主要顏色(綠色代表樹木,藍(lán)色代表海洋/湖泊,白色到橙色代表天空),所以我們考慮集群的數(shù)量為 3。
因此,我們將為這張圖片使用三個集群
標(biāo)簽存儲每個像素的集群標(biāo)簽(0/1/2)。
中心存儲到集群的中心點。
cv2.KMEANS_RANDOM_CENTERS 只是指示 OpenCV 最初隨機(jī)分配集群的值。
構(gòu)建分割后的圖像
將所有像素轉(zhuǎn)換為質(zhì)心的顏色
重塑回原始圖像尺寸
顯示圖像
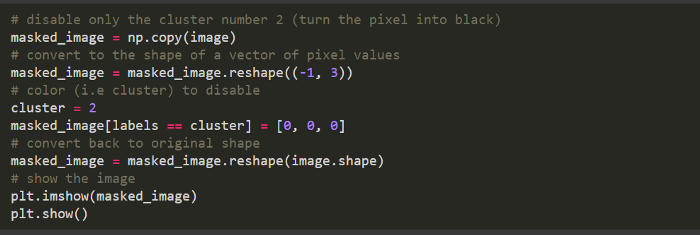
禁用某些集群以可視化它們所代表的段。
輸出:

集群 1 表示綠色,因為禁用集群 1 或?qū)⑵湓O(shè)為黑色在圖像中很明顯
類似地嘗試將要分割的集群的數(shù)量分割為8并可視化圖像
輸出:
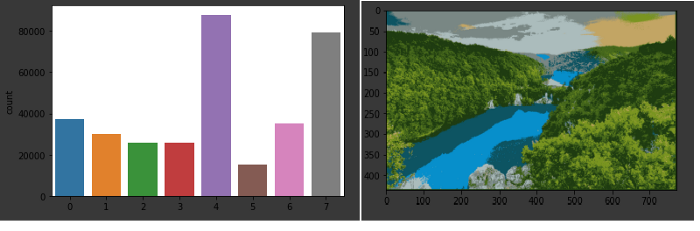 與每個集群關(guān)聯(lián)的計數(shù)
與每個集群關(guān)聯(lián)的計數(shù)
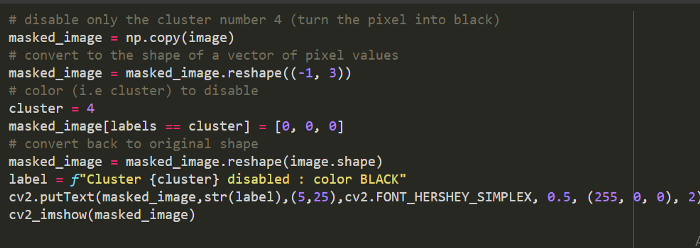 禁用集群 4,為代表段 4 的像素分配黑色
禁用集群 4,為代表段 4 的像素分配黑色輸出:

同樣禁用集群 2

基于聚類的 ML 算法的巨大價值在于我們可以通過使用多個統(tǒng)計參數(shù)來衡量生成的片段的質(zhì)量,例如:輪廓系數(shù)、蘭德指數(shù) (RI) 等。
圖像分割是一組很有前景的技能,因為它在醫(yī)學(xué)成像中發(fā)揮著重要作用,并且各種組織正在努力建立一個有效的醫(yī)學(xué)圖像主動診斷系統(tǒng)。
圖像處理一般以各種編程語言實現(xiàn)——Java、matplotlib、C++ 等。Python 庫像scikit-image、OpenCV、Mahotas、Pillow、matplotlib、SimplelTK 等,被廣泛用于實現(xiàn)圖像處理,尤其是圖像分割。
使用 Python 實現(xiàn)圖像分割是廣受歡迎的技能,并且有很多相關(guān)的培訓(xùn)可供使用。使用 python 庫是一種更簡單的實現(xiàn)方式,它在使用之前不需要任何復(fù)雜的要求——當(dāng)然除了 Python 編程和 Pandas 的基本知識。
好消息,小白學(xué)視覺團(tuán)隊的知識星球開通啦,為了感謝大家的支持與厚愛,團(tuán)隊決定將價值149元的知識星球現(xiàn)時免費加入。各位小伙伴們要抓住機(jī)會哦!

交流群
歡迎加入公眾號讀者群一起和同行交流,目前有SLAM、三維視覺、傳感器、自動駕駛、計算攝影、檢測、分割、識別、醫(yī)學(xué)影像、GAN、算法競賽等微信群(以后會逐漸細(xì)分),請掃描下面微信號加群,備注:”昵稱+學(xué)校/公司+研究方向“,例如:”張三?+?上海交大?+?視覺SLAM“。請按照格式備注,否則不予通過。添加成功后會根據(jù)研究方向邀請進(jìn)入相關(guān)微信群。請勿在群內(nèi)發(fā)送廣告,否則會請出群,謝謝理解~