
30 個(gè) Python 函數(shù),解決99%的數(shù)據(jù)處理任務(wù)!
我們知道 Pandas 是 Python 中最廣泛使用的數(shù)據(jù)分析和操作庫。它提供了許多功能和方法,可以快速解決數(shù)據(jù)分析中數(shù)據(jù)處理問題。
為了更好的掌握?Python 函數(shù)的使用方法,我以客戶流失數(shù)據(jù)集為例,分享30個(gè)在數(shù)據(jù)分析過程中最常使用的函數(shù)和方法,數(shù)據(jù)文末可以下載。
數(shù)據(jù)如下所示:
import?numpy?as?np
import?pandas?as?pd
df?=?pd.read_csv("Churn_Modelling.csv")
print(df.shape)
df.columns
結(jié)果輸出
(10000,?14)
Index(['RowNumber',?'CustomerId',?'Surname',?'CreditScore',?'Geography','Gender',?'Age',?'Tenure',?'Balance',?'NumOfProducts',?'HasCrCard','IsActiveMember',?'EstimatedSalary',?'Exited'],dtype='object')1.刪除列
df.drop(['RowNumber',?'CustomerId',?'Surname',?'CreditScore'],?axis=1,?inplace=True)
print(df[:2])
print(df.shape)
結(jié)果輸出
??Geography??Gender??Age??Tenure??Balance??NumOfProducts??HasCrCard??\
0????France??Female???42???????2??????0.0??????????????1??????????1???
???IsActiveMember??EstimatedSalary??Exited??
0???????????????1????????101348.88???????1??
(10000,?10)
說明:「axis」 參數(shù)設(shè)置為 1 以放置列,0 設(shè)置為行。「inplace=True」 參數(shù)設(shè)置為 True 以保存更改。我們減了 4 列,因此列數(shù)從 14 個(gè)減少到 10 列。
2.選擇特定列
我們從 csv 文件中讀取部分列數(shù)據(jù)。可以使用 usecols 參數(shù)。
df_spec?=?pd.read_csv("Churn_Modelling.csv",?usecols=['Gender',?'Age',?'Tenure',?'Balance'])
df_spec.head()3.nrows
可以使用 nrows 參數(shù),創(chuàng)建了一個(gè)包含 csv 文件前 5000 行的數(shù)據(jù)幀。還可以使用 skiprows 參數(shù)從文件末尾選擇行。Skiprows=5000 表示我們將在讀取 csv 文件時(shí)跳過前 5000 行。
df_partial?=?pd.read_csv("Churn_Modelling.csv",?nrows=5000)
print(df_partial.shape)4.樣品
創(chuàng)建數(shù)據(jù)框后,我們可能需要一個(gè)小樣本來測試數(shù)據(jù)。我們可以使用 n 或 frac 參數(shù)來確定樣本大小。
df=?pd.read_csv("Churn_Modelling.csv",?usecols=['Gender',?'Age',?'Tenure',?'Balance'])
df_sample?=?df.sample(n=1000)
df_sample2?=?df.sample(frac=0.1)5.檢查缺失值
isna 函數(shù)確定數(shù)據(jù)幀中缺失的值。通過將 isna 與 sum 函數(shù)一起使用,我們可以看到每列中缺失值的數(shù)量。
df.isna().sum()6.使用 loc 和 iloc 添加缺失值
使用 loc 和 iloc 添加缺失值,兩者區(qū)別如下:
loc:選擇帶標(biāo)簽 iloc:選擇索引
我們首先創(chuàng)建 20 個(gè)隨機(jī)索引進(jìn)行選擇
missing_index?=?np.random.randint(10000,?size=20)
我們將使用 loc 將某些值更改為 np.nan(缺失值)。
df.loc[missing_index,?['Balance','Geography']]?=?np.nan
"Balance"和"Geography"列中缺少 20 個(gè)值。讓我們用 iloc 做另一個(gè)示例。
df.iloc[missing_index,?-1]?=?np.nan7.填充缺失值
fillna 函數(shù)用于填充缺失的值。它提供了許多選項(xiàng)。我們可以使用特定值、聚合函數(shù)(例如均值)或上一個(gè)或下一個(gè)值。
avg?=?df['Balance'].mean()
df['Balance'].fillna(value=avg,?inplace=True)
fillna 函數(shù)的方法參數(shù)可用于根據(jù)列中的上一個(gè)或下一個(gè)值(例如方法="ffill")填充缺失值。它可以對順序數(shù)據(jù)(例如時(shí)間序列)非常有用。
8.刪除缺失值
處理缺失值的另一個(gè)方法是刪除它們。以下代碼將刪除具有任何缺失值的行。
df.dropna(axis=0,?how='any',?inplace=True)9.根據(jù)條件選擇行
在某些情況下,我們需要適合某些條件的觀測值(即行)
france_churn?=?df[(df.Geography?==?'France')?&?(df.Exited?==?1)]
france_churn.Geography.value_counts()10.用查詢描述條件
查詢函數(shù)提供了一種更靈活的傳遞條件的方法。我們可以用字符串來描述它們。
df2?=?df.query('80000?)
#?讓我們通過繪制平衡列的直方圖來確認(rèn)結(jié)果。
df2['Balance'].plot(kind='hist',?figsize=(8,5))11.用 isin 描述條件
條件可能有多個(gè)值。在這種情況下,最好使用 isin 方法,而不是單獨(dú)編寫值。
df[df['Tenure'].isin([4,6,9,10])][:3]

12.Groupby 函數(shù)
Pandas Groupby 函數(shù)是一個(gè)多功能且易于使用的功能,可幫助獲取數(shù)據(jù)概述。它使瀏覽數(shù)據(jù)集和揭示變量之間的基本關(guān)系更加容易。
我們將做幾個(gè)組比函數(shù)的示例。讓我們從簡單的開始。以下代碼將基于 Geography、Gender 組合對行進(jìn)行分組,然后給出每個(gè)組的平均流失率。
df[['Geography','Gender','Exited']].groupby(['Geography','Gender']).mean()13.Groupby與聚合函數(shù)結(jié)合
agg 函數(shù)允許在組上應(yīng)用多個(gè)聚合函數(shù),函數(shù)的列表作為參數(shù)傳遞。
df[['Geography','Gender','Exited']].groupby(['Geography','Gender']).agg(['mean','count'])14.對不同的群體應(yīng)用不同的聚合函數(shù)
df_summary?=?df[['Geography','Exited','Balance']].groupby('Geography').agg({'Exited':'sum',?'Balance':'mean'})
df_summary.rename(columns={'Exited':'#?of?churned?customers',?'Balance':'Average?Balance?of?Customers'},inplace=True)
此外,「NamedAgg 函數(shù)」允許重命名聚合中的列
import?pandas?as?pd
df_summary?=?df[['Geography','Exited','Balance']].groupby('Geography').agg(Number_of_churned_customers?=?pd.NamedAgg('Exited',?'sum'),Average_balance_of_customers?=?pd.NamedAgg('Balance',?'mean'))
print(df_summary)
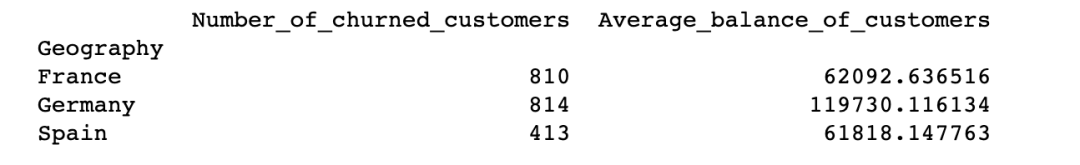
15.重置索引
您是否已經(jīng)注意到上圖的數(shù)據(jù)格式了。我們可以通過重置索引來更改它。
print(df_summary.reset_index())
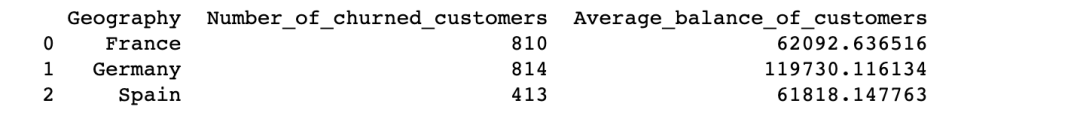
16.重置并刪除原索引
在某些情況下,我們需要重置索引并同時(shí)刪除原始索引。
df[['Geography','Exited','Balance']].sample(n=6).reset_index(drop=True)17.將特定列設(shè)置為索引
我們可以將數(shù)據(jù)幀中的任何列設(shè)置為索引。
df_new.set_index('Geography')18.插入新列
group?=?np.random.randint(10,?size=6)
df_new['Group']?=?group19.where 函數(shù)
它用于根據(jù)條件替換行或列中的值。默認(rèn)替換值為 NaN,但我們也可以指定要作為替換值。
df_new['Balance']?=?df_new['Balance'].where(df_new['Group']?>=?6,?0)20.等級函數(shù)
等級函數(shù)為值分配一個(gè)排名。讓我們創(chuàng)建一個(gè)列,根據(jù)客戶的余額對客戶進(jìn)行排名。
df_new['rank']?=?df_new['Balance'].rank(method='first',?ascending=False).astype('int')21.列中的唯一值數(shù)
它使用分類變量時(shí)派上用場。我們可能需要檢查唯一類別的數(shù)量。我們可以檢查值計(jì)數(shù)函數(shù)返回的序列的大小或使用 nunique 函數(shù)。
df.Geography.nunique22.內(nèi)存使用情況
使用函數(shù) memory_usage,這些值顯示以字節(jié)為單位的內(nèi)存.
df.memory_usage()
23.數(shù)據(jù)類型轉(zhuǎn)換
默認(rèn)情況下,分類數(shù)據(jù)與對象數(shù)據(jù)類型一起存儲。但是,它可能會導(dǎo)致不必要的內(nèi)存使用,尤其是當(dāng)分類變量具有較低的基數(shù)。
低基數(shù)意味著列與行數(shù)相比幾乎沒有唯一值。例如,地理列具有 3 個(gè)唯一值和 10000 行。
我們可以通過將其數(shù)據(jù)類型更改為"類別"來節(jié)省內(nèi)存。
df['Geography']?=?df['Geography'].astype('category')24.替換值
替換函數(shù)可用于替換數(shù)據(jù)幀中的值。
df['Geography'].replace({0:'B1',1:'B2'})25.繪制直方圖
pandas 不是一個(gè)數(shù)據(jù)可視化庫,但它使得創(chuàng)建基本繪圖變得非常簡單。
我發(fā)現(xiàn)使用 Pandas 創(chuàng)建基本繪圖更容易,而不是使用其他數(shù)據(jù)可視化庫。
讓我們創(chuàng)建平衡列的直方圖。
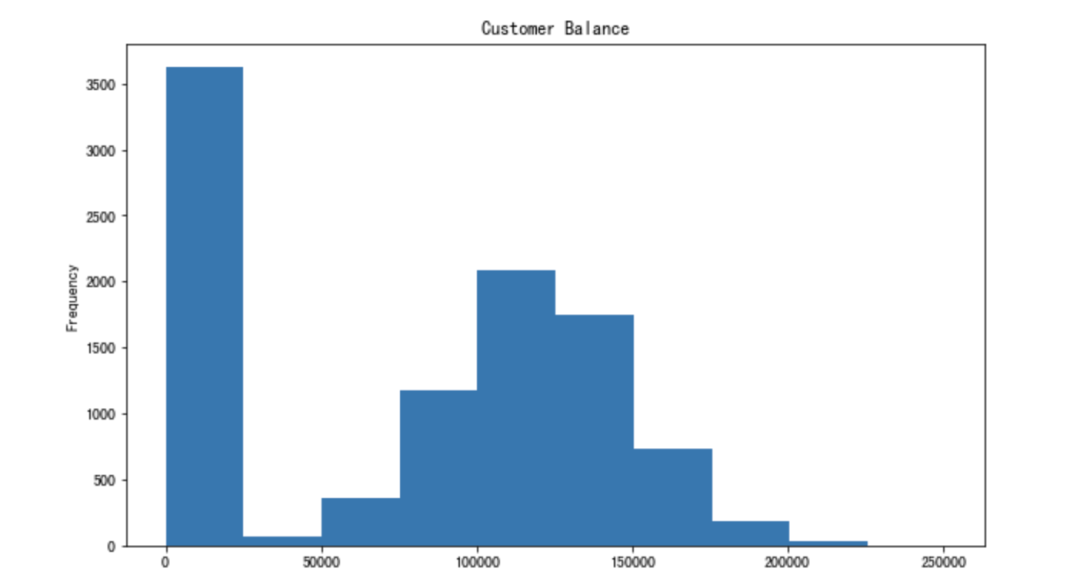
26.減少浮點(diǎn)數(shù)小數(shù)點(diǎn)
pandas 可能會為浮點(diǎn)數(shù)顯示過多的小數(shù)點(diǎn)。我們可以輕松地調(diào)整它。
df['Balance'].plot(kind='hist',?figsize=(10,6),?
title='Customer?Balance')27.更改顯示選項(xiàng)
我們可以更改各種參數(shù)的默認(rèn)顯示選項(xiàng),而不是每次手動調(diào)整顯示選項(xiàng)。
get_option:返回當(dāng)前選項(xiàng) set_option:更改選項(xiàng) 讓我們將小數(shù)點(diǎn)的顯示選項(xiàng)更改為 2。
pd.set_option("display.precision",?2)
可能要更改的一些其他選項(xiàng)包括:
max_colwidth:列中顯示的最大字符數(shù) max_columns:要顯示的最大列數(shù) max_rows:要顯示的最大行數(shù)
28.通過列計(jì)算百分比變化
pct_change用于計(jì)算序列中值的變化百分比。在計(jì)算時(shí)間序列或元素順序數(shù)組中更改的百分比時(shí),它很有用。
ser=?pd.Series([2,4,5,6,72,4,6,72])
ser.pct_change()29.基于字符串的篩選
我們可能需要根據(jù)文本數(shù)據(jù)(如客戶名稱)篩選觀測值(行)。我已經(jīng)在數(shù)據(jù)幀中添加了df_new名稱。
df_new[df_new.Names.str.startswith('Mi')]

30.設(shè)置數(shù)據(jù)幀樣式
我們可以通過使用返回 Style 對象的 Style 屬性來實(shí)現(xiàn)此目的,它提供了許多用于格式化和顯示數(shù)據(jù)框的選項(xiàng)。例如,我們可以突出顯示最小值或最大值。
它還允許應(yīng)用自定義樣式函數(shù)。
df_new.style.highlight_max(axis=0,?color='darkgreen')
如果你覺得文章還不錯(cuò),請大家?點(diǎn)贊、分享、留言?下,因?yàn)檫@將是我持續(xù)輸出更多優(yōu)質(zhì)文章的最強(qiáng)動力!
老表薦書
圖書介紹:《Python Web開發(fā)從入門到精通》
本書分為3部分:第1部分是基礎(chǔ)篇,帶領(lǐng)初學(xué)者實(shí)踐Python開發(fā)環(huán)境和掌握基本語法,同時(shí)對網(wǎng)絡(luò)協(xié)議、Web客戶端技術(shù)、數(shù)據(jù)庫建模編程等網(wǎng)絡(luò)編程基礎(chǔ)深入淺出地進(jìn)行學(xué)習(xí);
第2部分是框架篇,學(xué)習(xí)當(dāng)前*流行的Python Web框架,即Django、Tornado、Flask和Twisted,達(dá)到對各種Python網(wǎng)絡(luò)技術(shù)融會貫通的目的;第3部分是實(shí)戰(zhàn)篇,分別對幾種常用WEB框架進(jìn)行項(xiàng)目實(shí)踐,利用其各自的特點(diǎn)開發(fā)適用于不同場景的網(wǎng)絡(luò)程序。
《Python Web開發(fā)從入門到精通》內(nèi)容精練、重點(diǎn)突出、實(shí)例豐富、講解通俗,是廣大網(wǎng)絡(luò)應(yīng)用設(shè)計(jì)和開發(fā)人員不可多得的一本參考書,同時(shí)非常適合大中專院校師生學(xué)習(xí)和閱讀,也可作為高等院校計(jì)算機(jī)及相關(guān)培訓(xùn)機(jī)構(gòu)的教材。
掃碼即可加我微信
老表朋友圈經(jīng)常有贈書/紅包福利活動
贈書介紹:
1>?給本文在看+點(diǎn)贊,掃碼加我微信,本文點(diǎn)贊破50后,我將在朋友圈送出1本《Python Web開發(fā)從入門到精通》。
2>?給本文隨意留言(15字以上)+點(diǎn)贊,第一個(gè)留言且關(guān)注滿21天的讀者可以獲得贈書一本。
【注意??】近三個(gè)月內(nèi)獲得贈書的讀者將無法再次獲得贈書,想要多次獲得贈書,可以查看下面的投稿規(guī)則及激勵(lì)。
近期閱讀學(xué)習(xí)推薦:
Python超好用的命令行界面實(shí)現(xiàn)工具
Python自動化處理Excel表格實(shí)戰(zhàn)完整代碼分享(課表解析)
如何找到我:
分享
收藏
點(diǎn)贊
在看



