
標簽體系下的用戶畫像建設小指南



二、用戶標簽的分類
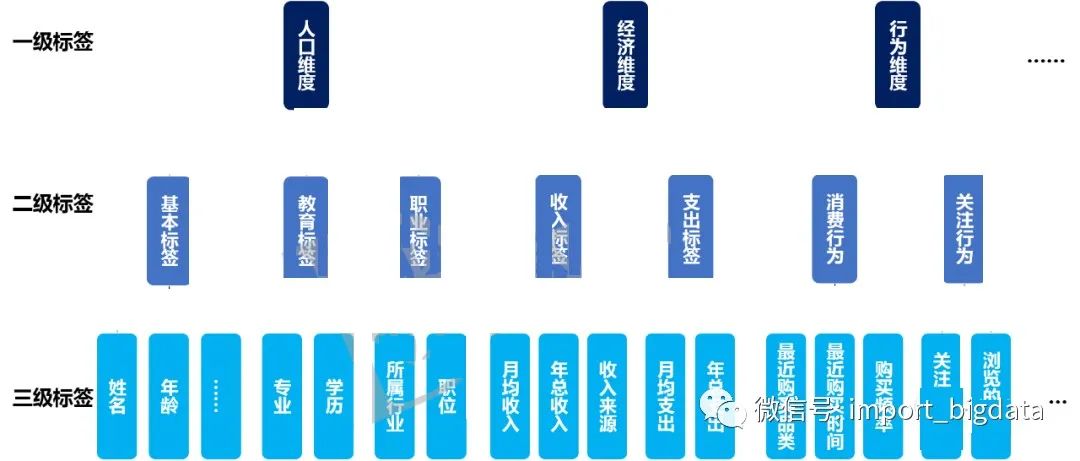



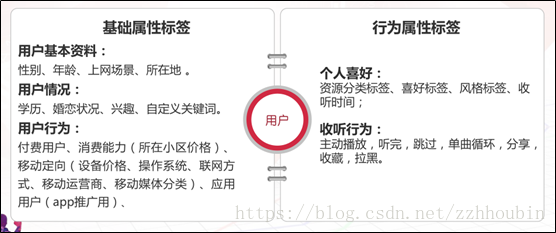






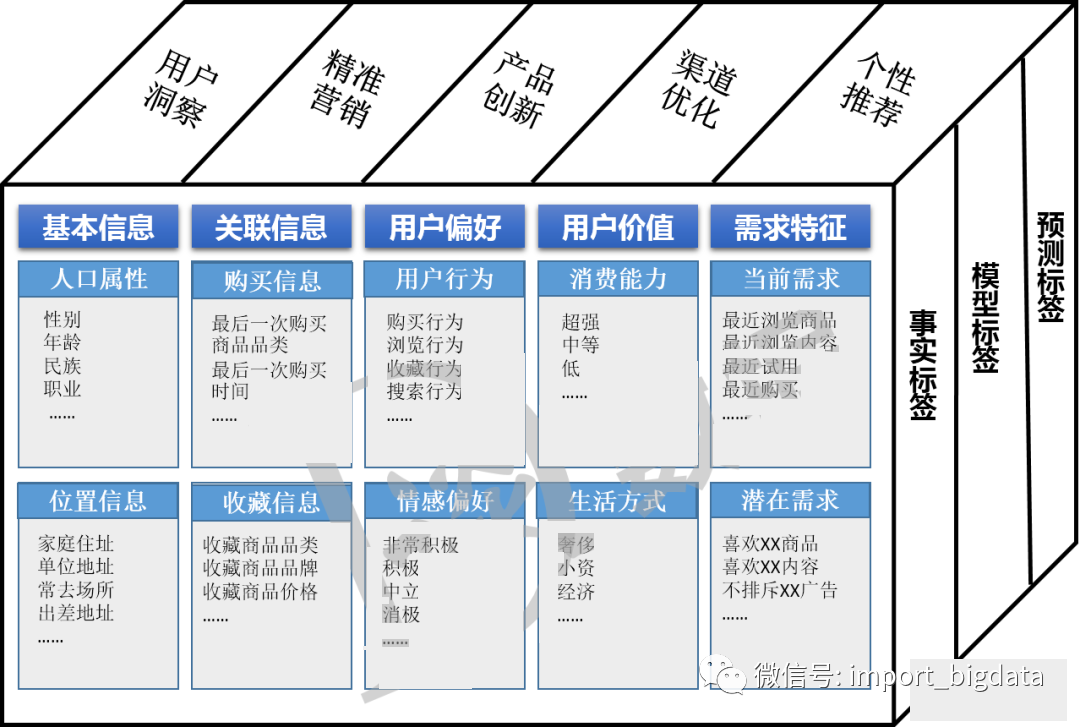
六、用戶畫像的分類

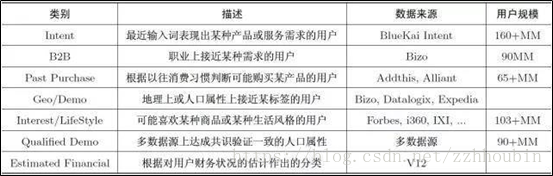
七、用戶畫像需要用到哪些數據
(2)興趣特征:瀏覽內容、收藏內容、閱讀咨詢、購買物品偏好等
(3)消費特征:與消費相關的特征
(4)位置特征:用戶所處城市、所處居住區(qū)域、用戶移動軌跡等
(5)設備屬性:使用的終端特征等
(6)行為數據:訪問時間、瀏覽路徑等用戶在網站的行為日志數據
(7)社交數據:用戶社交相關數據

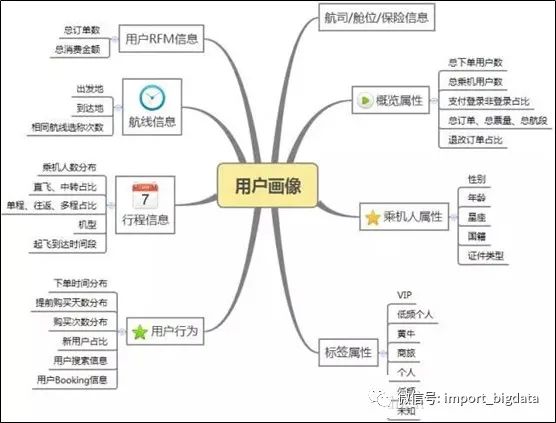

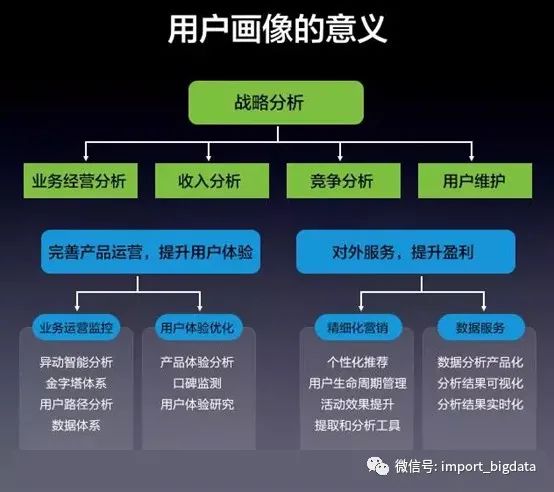
八、用戶畫像的作用
(2)用戶統計:根據用戶的屬性、行為特征對用戶進行分類后,統計不同特征下的用戶數量、分布;分析不同用戶畫像群體的分布特征。
(3)數據挖掘:以用戶畫像為基礎構建推薦系統、搜索引擎、廣告投放系統,提升服務精準度。
(4)服務產品:對產品進行用戶畫像,對產品進行受眾分析,更透徹地理解用戶使用產品的心理動機和行為習慣,完善產品運營,提升服務質量。
(5)行業(yè)報告&用戶研究:通過用戶畫像分析可以了解行業(yè)動態(tài),比如人群消費習慣、消費偏好分析、不同地域品類消費差異分析
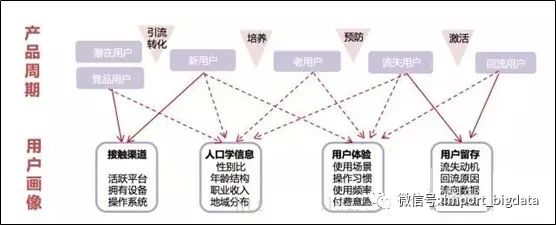


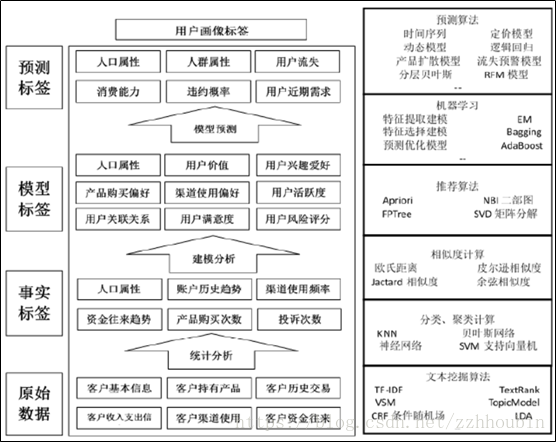
九、用戶畫像的體系架構

十、用戶畫像的建設步驟


評論
圖片
表情