
構建高性能隊列,你不得不知道的底層知識!
關注公眾號“彤哥讀源碼”,解鎖更多源碼、基礎、架構知識!

前言
本文收錄于專輯:http://dwz.win/HjK,點擊解鎖更多數(shù)據(jù)結(jié)構與算法的知識。
你好,我是彤哥。
上一節(jié),我們一起學習了如何將遞歸改寫為非遞歸,其中,用到的數(shù)據(jù)結(jié)構主要是棧。
棧和隊列,可以說是除了數(shù)組和鏈表之外最基礎的數(shù)據(jù)結(jié)構了,在很多場景中都有用到,后面我們也會陸陸續(xù)續(xù)的看到。
今天,我想介紹一下,在Java中,如何構建一個高性能的隊列,以及我們需要掌握的底層知識。
學習其他語言的同學,也可以看看,在你的語言中,是如何構建高性能隊列的。
隊列
隊列,是一種先進先出(First In First Out,F(xiàn)IFO)的數(shù)據(jù)結(jié)構,類似于實際生活場景中的排隊,先到的人先得。
使用數(shù)組和鏈表實現(xiàn)簡單的隊列,我們前面都介紹過了,這里就不再贅述了,有興趣的同學可以點擊以下鏈接查看:
重溫四大基礎數(shù)據(jù)結(jié)構:數(shù)組、鏈表、隊列和棧
今天我們主要來學習如何實現(xiàn)高性能的隊列。
說起高性能的隊列,當然是說在高并發(fā)環(huán)境下也能夠工作得很好的隊列,這里的很好主要是指兩個方面:并發(fā)安全、性能好。
并發(fā)安全的隊列
在Java中,默認地,也自帶了一些并發(fā)安全的隊列:
| 隊列 | 有界性 | 鎖 | 數(shù)據(jù)結(jié)構 |
|---|---|---|---|
| ArrayBlockingQueue | 有界 | 加鎖 | 數(shù)組 |
| LinkedBlockingQueue | 可選有界 | 加鎖 | 鏈表 |
| ConcurrentLinkedQueue | 無界 | 無鎖 | 鏈表 |
| SynchronousQueue | 無界 | 無鎖 | 隊列或棧 |
| LinkedTransferQueue | 無界 | 無鎖 | 鏈表 |
| PriorityBlockingQueue | 無界 | 加鎖 | 堆 |
| DelayQueue | 無界 | 加鎖 | 堆 |
這些隊列的源碼解析快捷入口:死磕 Java并發(fā)集合之終結(jié)篇
總結(jié)起來,實現(xiàn)并發(fā)安全隊列的數(shù)據(jù)結(jié)構主要有:數(shù)組、鏈表和堆,堆主要用于實現(xiàn)優(yōu)先級隊列,不具備通用性,暫且不討論。
從有界性來看,只有ArrayBlockingQueue和LinkedBlockingQueue可以實現(xiàn)有界隊列,其它的都是無界隊列。
從加鎖來看,ArrayBlockingQueue和LinkedBlockingQueue都采用了加鎖的方式,其它的都是采用的CAS這種無鎖的技術實現(xiàn)的。
從安全性的角度來說,我們一般都要選擇有界隊列,防止生產(chǎn)者速度過快導致內(nèi)存溢出。
從性能的角度來說,我們一般要考慮無鎖的方式,減少線程上下文切換帶來的性能損耗。
從JVM的角度來說,我們一般選擇數(shù)組的實現(xiàn)方式,因為鏈表會頻繁的增刪節(jié)點,導致頻繁的垃圾回收,這也是一種性能損耗。
所以,最佳的選擇就是:數(shù)組 + 有界 + 無鎖。
而JDK并沒有提供這樣的隊列,因此,很多開源框架都自己實現(xiàn)了高性能的隊列,比如Disruptor,以及Netty中使用的jctools。
高性能隊列
我們這里不討論具體的某一個框架,只介紹實現(xiàn)高性能隊列的通用技術,并自己實現(xiàn)一個。
環(huán)形數(shù)組
通過上面的討論,我們知道實現(xiàn)高性能隊列使用的數(shù)據(jù)結(jié)構只能是數(shù)組,而數(shù)組實現(xiàn)隊列,必然要使用到環(huán)形數(shù)組。
環(huán)形數(shù)組,一般通過設置兩個指針實現(xiàn):putIndex和takeIndex,或者叫writeIndex和readIndex,一個用于寫,一個用于讀。
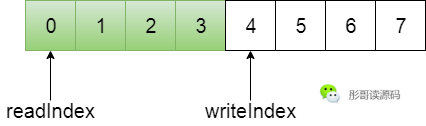
當寫指針到達數(shù)組尾端時,會從頭開始,當然,不能越過讀指針,同理,讀指針到達數(shù)組尾端時,也會從頭開始,當然,不能讀取未寫入的數(shù)據(jù)。
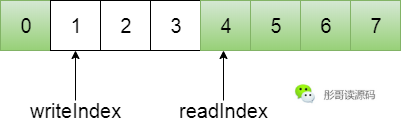
而為了防止寫指針和讀指針重疊的時候,無法分清隊列到底是滿了還是空的狀態(tài),一般會再添加一個size字段:

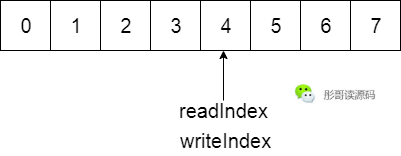
所以,使用環(huán)形數(shù)組實現(xiàn)隊列的數(shù)據(jù)結(jié)構一般為:
public class ArrayQueue<T> {
private T[] array;
private long wrtieIndex;
private long readIndex;
private long size;
}
在單線程的情況下,這樣不會有任何問題,但是,在多線程環(huán)境中,這樣會帶來嚴重的偽共享問題。
偽共享
什么是共享?
在計算機中,有很多存儲單元,我們接觸最多的就是內(nèi)存,又叫做主內(nèi)存,此外,CPU還有三級緩存:L1、L2、L3,L1最貼近CPU,當然,它的存儲空間也很小,L2比L1稍大一些,L3最大,可以同時緩存多個核心的數(shù)據(jù)。CPU取數(shù)據(jù)的時候,先從L1緩存中讀取,如果沒有再從L2緩存中讀取,如果沒有再從L3中讀取,如果三級緩存都沒有,最后會從內(nèi)存中讀取。離CPU核心越遠,則相對的耗時就越長,所以,如果要做一些很頻繁的操作,要盡量保證數(shù)據(jù)緩存在L1中,這樣能極大地提高性能。
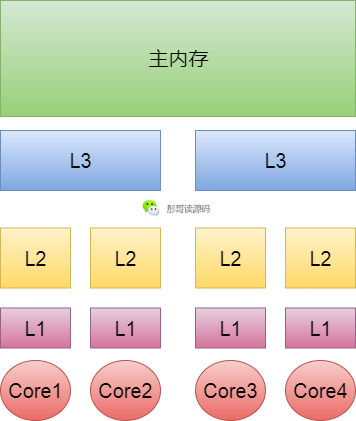
緩存行
而數(shù)據(jù)在三級緩存中,也不是說來一個數(shù)據(jù)緩存一下,而是一次緩存一批數(shù)據(jù),這一批數(shù)據(jù)又稱作緩存行(Cache Line),通常為64字節(jié)。

每一次,當CPU去內(nèi)存中拿數(shù)據(jù)的時候,都會把它后面的數(shù)據(jù)一并拿過來(組成64字節(jié)),我們以long型數(shù)組為例,當CPU取數(shù)組中一個long的時候,同時會把后續(xù)的7個long一起取到緩存行中。
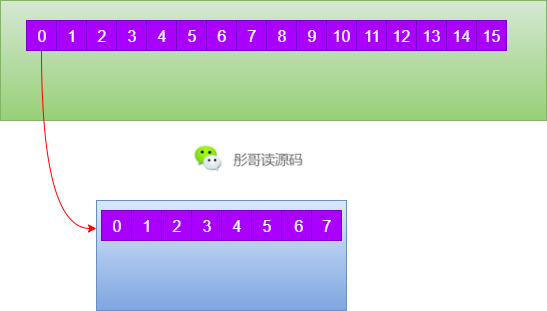
這在一定程度上能夠加快數(shù)據(jù)的處理,因為,此時在處理下標為0的數(shù)據(jù),下一個時刻可能就要處理下標為1的數(shù)據(jù)了,直接從緩存中取要快很多。
但是,這樣又帶來了一個新的問題——偽共享。
偽共享
試想一下,兩個線程(CPU)同時在處理這個數(shù)組中的數(shù)據(jù),兩個CPU都緩存了,一個CPU在對array[0]的數(shù)據(jù)加1,另一個CPU在對array[1]的數(shù)據(jù)加1,那么,回寫到主內(nèi)存的時候,到底以哪個緩存行的數(shù)據(jù)為準(寫回主內(nèi)存的時候也是以緩存行的形式寫回),所以,此時,就需要對這兩個緩存行“加鎖”了,一個CPU先修改數(shù)據(jù),寫回主內(nèi)存,另一個CPU才能讀取數(shù)據(jù)并修改數(shù)據(jù),再寫回主內(nèi)存,這樣勢必會帶來性能的損耗,出現(xiàn)的這種現(xiàn)象就叫做偽共享,這種“加鎖”的方式叫做內(nèi)存屏障,關于內(nèi)存屏障的知識我們就不展開敘述了。
那么,怎么解決偽共享帶來的問題呢?
以環(huán)形數(shù)組實現(xiàn)的隊列為例,writeIndex、readIndex、size現(xiàn)在是這樣處理的:
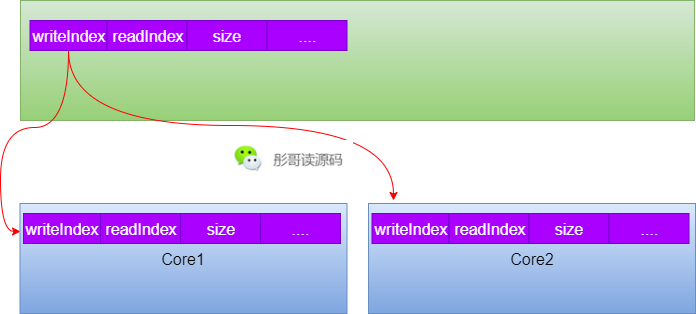
所以,我們只需要在writeIndex和readIndex之間加7個long就可以把它們隔離開,同理,readIndex和size之間也是一樣的。
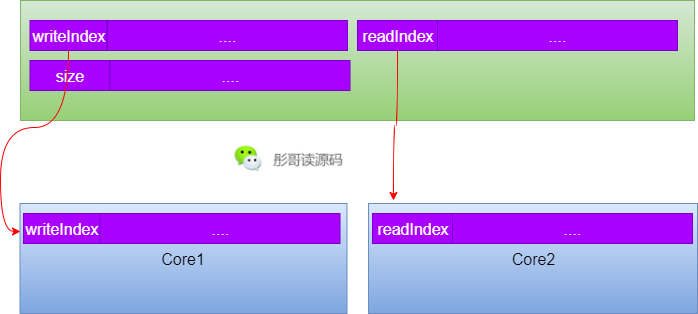
這樣就消除了writeIndex和readIndex之間的偽共享問題,因為writeIndex和readIndex肯定是在兩個不同的線程中更新,所以,消除偽共享之后帶來的性能提升是很明顯的。
假如有多個生產(chǎn)者,writeIndex是肯定會被爭用的,此時,要怎么友好地修改writeIndex呢?即一個生產(chǎn)者線程修改了writeIndex,另一個生產(chǎn)者線程要立馬可見。
你第一時間想到的肯定是volatile,沒錯,可是光volatile還不行哦,volatile只能保證可見性和有序性,不能保證原子性,所以,還需要加上原子指令CAS,CAS是誰提供的?原子類AtomicInteger和AtomicLong都具有CAS的功能,那我們直接使用他們嗎?肯定不是,仔細觀察,發(fā)現(xiàn)他們最終都是調(diào)用Unsafe實現(xiàn)的。
OK,下面就輪到最牛逼的底層殺手登場了——Unsafe。
Unsafe
Unsafe不僅提供了CAS的指令,還提供很多其它操作底層的方法,比如操作直接內(nèi)存、修改私有變量的值、實例化一個類、阻塞/喚醒線程、帶有內(nèi)存屏障的方法等。
關于Unsafe,可以看這篇文章:死磕 java魔法類之Unsafe解析
當然,構建高性能隊列,主要使用的是Unsafe的CAS指令以及帶有內(nèi)存屏障的方法等:
// 原子指令
public final native boolean compareAndSwapLong(Object var1, long var2, long var4, long var6);
// 以volatile的形式獲取值,相當于給變量加了volatile關鍵字
public native long getLongVolatile(Object var1, long var2);
// 延遲更新,對變量的修改不會立即寫回到主內(nèi)存,也就是說,另一個線程不會立即可見
public native void putOrderedLong(Object var1, long var2, long var4);
好了,底層知識介紹的差不多了,是時候展現(xiàn)真正的技術了——手寫高性能隊列。
手寫高性能隊列
我們假設這樣一種場景:有多個生產(chǎn)者(Multiple Producer),卻只有一個消費者(Single Consumer),這是Netty中的經(jīng)典場景,這樣一種隊列該怎么實現(xiàn)?
直接上代碼:
/**
* 多生產(chǎn)者單消費者隊列
*
* @param
*/
public class MpscArrayQueue<T> {
long p01, p02, p03, p04, p05, p06, p07;
// 存放元素的地方
private T[] array;
long p1, p2, p3, p4, p5, p6, p7;
// 寫指針,多個生產(chǎn)者,所以聲明為volatile
private volatile long writeIndex;
long p11, p12, p13, p14, p15, p16, p17;
// 讀指針,只有一個消費者,所以不用聲明為volatile
private long readIndex;
long p21, p22, p23, p24, p25, p26, p27;
// 元素個數(shù),生產(chǎn)者和消費者都可能修改,所以聲明為volatile
private volatile long size;
long p31, p32, p33, p34, p35, p36, p37;
// Unsafe變量
private static final Unsafe UNSAFE;
// 數(shù)組基礎偏移量
private static final long ARRAY_BASE_OFFSET;
// 數(shù)組元素偏移量
private static final long ARRAY_ELEMENT_SHIFT;
// writeIndex的偏移量
private static final long WRITE_INDEX_OFFSET;
// readIndex的偏移量
private static final long READ_INDEX_OFFSET;
// size的偏移量
private static final long SIZE_OFFSET;
static {
Field f = null;
try {
// 獲取Unsafe的實例
f = Unsafe.class.getDeclaredField("theUnsafe");
f.setAccessible(true);
UNSAFE = (Unsafe) f.get(null);
// 計算數(shù)組基礎偏移量
ARRAY_BASE_OFFSET = UNSAFE.arrayBaseOffset(Object[].class);
// 計算數(shù)組中元素偏移量
// 簡單點理解,64位系統(tǒng)中有壓縮指針占用4個字節(jié),沒有壓縮指針占用8個字節(jié)
int scale = UNSAFE.arrayIndexScale(Object[].class);
if (4 == scale) {
ARRAY_ELEMENT_SHIFT = 2;
} else if (8 == scale) {
ARRAY_ELEMENT_SHIFT = 3;
} else {
throw new IllegalStateException("未知指針的大小");
}
// 計算writeIndex的偏移量
WRITE_INDEX_OFFSET = UNSAFE
.objectFieldOffset(MpscArrayQueue.class.getDeclaredField("writeIndex"));
// 計算readIndex的偏移量
READ_INDEX_OFFSET = UNSAFE
.objectFieldOffset(MpscArrayQueue.class.getDeclaredField("readIndex"));
// 計算size的偏移量
SIZE_OFFSET = UNSAFE
.objectFieldOffset(MpscArrayQueue.class.getDeclaredField("size"));
} catch (Exception e) {
throw new RuntimeException();
}
}
// 構造方法
public MpscArrayQueue(int capacity) {
// 取整到2的N次方(未考慮越界)
capacity = 1 << (32 - Integer.numberOfLeadingZeros(capacity - 1));
// 實例化數(shù)組
this.array = (T[]) new Object[capacity];
}
// 生產(chǎn)元素
public boolean put(T t) {
if (t == null) {
return false;
}
long size;
long writeIndex;
do {
// 每次循環(huán)都重新獲取size的大小
size = this.size;
// 隊列滿了直接返回
if (size >= this.array.length) {
return false;
}
// 每次循環(huán)都重新獲取writeIndex的值
writeIndex = this.writeIndex;
// while循環(huán)中原子更新writeIndex的值
// 如果失敗了重新走上面的過程
} while (!UNSAFE.compareAndSwapLong(this, WRITE_INDEX_OFFSET, writeIndex, writeIndex + 1));
// 到這里,說明上述原子更新成功了
// 那么,就把元素的值放到writeIndex的位置
// 且更新size
long eleOffset = calcElementOffset(writeIndex, this.array.length-1);
// 延遲更新到主內(nèi)存,讀取的時候才更新
UNSAFE.putOrderedObject(this.array, eleOffset, t);
// 往死里更新直到成功
do {
size = this.size;
} while (!UNSAFE.compareAndSwapLong(this, SIZE_OFFSET, size, size + 1));
return true;
}
// 消費元素
public T take() {
long size = this.size;
// 如果size為0,表示隊列為空,直接返回
if (size <= 0) {
return null;
}
// size大于0,肯定有值
// 只有一個消費者,不用考慮線程安全的問題
long readIndex = this.readIndex;
// 計算讀指針處元素的偏移量
long offset = calcElementOffset(readIndex, this.array.length-1);
// 獲取讀指針處的元素,使用volatile語法,強制更新生產(chǎn)者的數(shù)據(jù)到主內(nèi)存
T e = (T) UNSAFE.getObjectVolatile(this.array, offset);
// 增加讀指針
UNSAFE.putOrderedLong(this, READ_INDEX_OFFSET, readIndex+1);
// 減小size
do {
size = this.size;
} while (!UNSAFE.compareAndSwapLong(this, SIZE_OFFSET, size, size-1));
return e;
}
private long calcElementOffset(long index, long mask) {
// index & mask 相當于取余數(shù),表示index到達數(shù)組尾端了從頭開始
return ARRAY_BASE_OFFSET + ((index & mask) << ARRAY_ELEMENT_SHIFT);
}
}
是不是看不懂?那就對了,多看幾遍吧,面試又能吹一波了。
這里使用的是每兩個變量之間加7個long類型的變量來消除偽共享,有的開源框架你可能會看到通過繼承的方式實現(xiàn)的,還有的是加15個long類型,另外,JDK8中也提供了一個注解@Contended來消除偽共享。
本例其實還有優(yōu)化的空間,比如,size的使用,能不能不使用size?不使用size又該如何實現(xiàn)?
后記
本節(jié),我們一起學習了在Java中如何構建高性能的隊列,并學習了一些底層的知識,毫不夸張地講,學會了這些底層知識,面試的時候光隊列就能跟面試官吹一個小時。
另外,最近收到一些同學的反饋,說哈希、哈希表、哈希函數(shù)他們之間有關系嗎?有怎樣的關系?為什么Object中要放一個hash()方法?跟equals()方法怎么又扯上關系了呢?
下一節(jié),我們就來看看關于哈希的一切,想及時獲取最新推文嗎?還不快點來關注我!