
關系型數(shù)據(jù)和文檔型數(shù)據(jù)庫區(qū)別
關系型數(shù)據(jù)庫和文檔型數(shù)據(jù)庫有什么區(qū)別
關系型數(shù)據(jù)庫屬于早期的傳統(tǒng)型數(shù)據(jù)庫,它有著標準化的數(shù)據(jù)模型,以及事務和持久化的支持、例如,關系型數(shù)據(jù)庫都會支持的 ACID 特性,也就是原子性(Atomicity)、一致性(Consistency)、隔離性(Isolation)和持久性(Durability),具體含義如下。
1、原子性(Atomicity):是指一個事務中的所有操作,要么全部完成、要么全部不完成,不會存在中間的狀態(tài)。也就是說事務在正常的情況下會執(zhí)行完成;異常的情況下,比如在執(zhí)行的過程中如果出現(xiàn)問題,會回滾成最初的狀態(tài),而非中間狀態(tài)。
2、一致性(Consistency):是指事務從開始執(zhí)行到結束執(zhí)行之間的中間狀態(tài)不會被其他事務看到。
3、隔離性(Isolation):是指數(shù)據(jù)庫允許多個事務同時對數(shù)據(jù)進行讀寫或修改的能力,并且整個過程對各個事務來說是相互隔離的。
4、持久性(Durability):是指每次事務提交之后都不會丟失。
以 MongoDB 為代表的文檔型數(shù)據(jù)庫提供了更高效的讀/寫性能以及可自動容災的數(shù)據(jù)庫集群,還有靈活的數(shù)據(jù)庫結構,從而給系統(tǒng)的數(shù)據(jù)庫存儲帶來了更多可能 性。
關系型數(shù)據(jù)庫一般遵循三范式設計思想
1、第一范式(The First Normal Form,1NF):要求對屬性的原子性,也就是說要求數(shù)據(jù)庫中的字段需要具備原子性,不能再被拆分。

2、第二范式(The Second Normal Form,2NF):要求消除重復出現(xiàn)的情況,避免冗余數(shù)據(jù)的產(chǎn)生

3、第三范式(The Third Normal Form,3NF):想要滿足第三范式必須先滿足第二范式,第三范式要求所有的非主鍵字段必須直接依賴主鍵,且不存在傳遞依賴的情況。
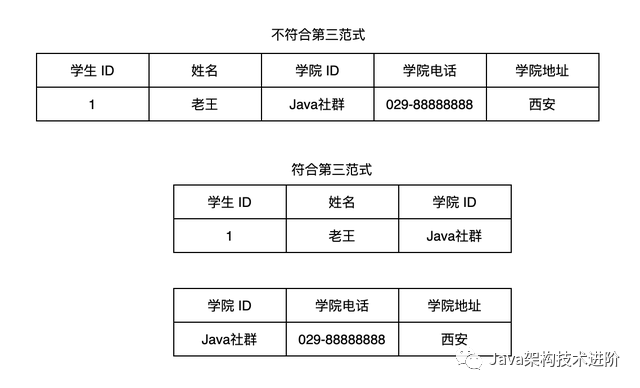
可以看出,使用三范式可以避免數(shù)據(jù)的冗余,而且在更新表操作時,只需要更新單張表就可以了
非關系型數(shù)據(jù)庫和文檔型數(shù)據(jù)庫有什么區(qū)別
非關系型數(shù)據(jù)和文檔型數(shù)據(jù)庫屬于包含關系,非關系型數(shù)據(jù)包含了文檔型數(shù)據(jù)庫,文檔型數(shù)據(jù)庫屬于非關系型數(shù)據(jù)。
非關系型數(shù)據(jù)通常包含 3 種數(shù)據(jù)庫類型:文檔型數(shù)據(jù)庫、鍵值型數(shù)據(jù)庫和全文搜索型數(shù)據(jù)庫,下面分別來看每種類型的具體用途。
1、文檔型數(shù)據(jù)庫
文檔型數(shù)據(jù)庫以 MongoDB 和 Apache CouchDB 為代表,文檔型數(shù)據(jù)庫通常以 JSON 或者 XML 為格式進行數(shù)據(jù)存儲。
文檔型數(shù)據(jù)庫的使用場景如下:
a、敏捷開發(fā),因為 MongoDB 擁有比關系型數(shù)據(jù)庫更快的開發(fā)速度,因此很多敏捷開發(fā)組織,包括紐約時報等都采用了 MongoDB 數(shù)據(jù)庫。使用它可以有效地避免在增加和修改數(shù)據(jù)庫帶來的溝通成本,以及維護和創(chuàng)建數(shù)據(jù)庫模型成本,使用 MongoDB 只需要在程序層面嚴格把關就行,程序提交的數(shù)據(jù)結構可以直接更新到數(shù)據(jù)庫中,并不需要繁雜的設計數(shù)據(jù)庫模型再生成修改語句等過程。
b、日志系統(tǒng),使用 MongoDB 數(shù)據(jù)庫非常適合存儲日志,日志對應到數(shù)據(jù)庫中就是很多個文件,而 MongoDB 更擅長存儲和查詢文檔,它提供了更簡單的存儲和更方便的查詢功能。
c、社交系統(tǒng),使用 MongoDB 可以很方便的存儲用戶的位置信息,可以方便的實現(xiàn)查詢附近的人以及附近的地點等功能。
2、鍵值型數(shù)據(jù)庫
鍵值數(shù)據(jù)庫也就是 Key-Value 數(shù)據(jù)庫,它的典型代表數(shù)據(jù)庫是 Redis 和 Memcached,而它們通常被當做非持久化的內(nèi)存型數(shù)據(jù)庫緩存來使用。當然 Redis 數(shù)據(jù)庫是具備可持久化得能力的,但是開啟持久化會降低系統(tǒng)的運行效率,因此在使用時需要根據(jù)實際的情況,選擇開啟或者關閉持久化的功能。
鍵值型數(shù)據(jù)庫以極高的性能著稱,且除了 Key-Value 字符串類型之外,還包含一些其他的數(shù)據(jù)類型。以 Redis 為例,它提供了字符串類型(String)、列表類型(List)、哈希表類型(Hash)、集合類型(Set)、有序集合類型(ZSet)等五種最常用的基礎數(shù)據(jù)類型,還有管道類型(Pipeline)、地理位置類型(GEO)、基數(shù)統(tǒng)計類型(HyperLogLog)和流類型(Stream),并且還提供了消息隊列的功能。
此數(shù)據(jù)庫的優(yōu)點是性能比較高,缺點是對事務的支持不是很好。
3、全文搜索型數(shù)據(jù)庫
傳統(tǒng)的關系型數(shù)據(jù)庫主要是依賴索引來實現(xiàn)快速查詢功能的,而在全文搜索的業(yè)務下,索引很難滿足查詢的需求。因為全文搜索需要支持模糊匹配的,當數(shù)據(jù)量比較大的情況下,傳遞的關系型數(shù)據(jù)庫的查詢效率是非常低的;另一個原因是全文搜索需要支持多條件隨意組合排序,如果要通過索引來實現(xiàn)的話,則需要創(chuàng)建大量的索引,而傳統(tǒng)型數(shù)據(jù)庫也很難實現(xiàn),因此需要專門全文搜索引擎和相關的數(shù)據(jù)庫才能實現(xiàn)此功能。
全文搜索型數(shù)據(jù)庫以 ElasticSearch 和 Solr 為代表,它們的出現(xiàn)解決了關系型數(shù)據(jù)庫全文搜索功能較弱的問題。
MongoDB 支持事務嗎
MongoDB 在 4.0 之前是不支持事務的,不支持的原因也很簡單,因為文檔型數(shù)據(jù)庫和傳統(tǒng)的關系型數(shù)據(jù)庫不一樣,不需要滿足三范式。文檔型數(shù)據(jù)庫之所以性能比較高的另一個主要原因,就是使用文檔型數(shù)據(jù)庫不用進行多表關聯(lián)性查詢,因為文檔型數(shù)據(jù)庫會把相關的信息存放到一張表中。因此,無需關聯(lián)多表查詢的 MongoDB,在這種情況下的查詢性能是比較高的。
把所有相關的數(shù)據(jù)都放入一個表中,這也是 MongoDB 之前很長一段時間內(nèi)不支持事務的原因,它可以保證單表操作的原子性,一條記錄要么成功插入,要么插入失敗,不會存在插入了一半的數(shù)據(jù)。因此,在這種設計思路下,MongoDB 官方認為“事務功能”的實現(xiàn)沒有那么緊迫。
但在 MongoDB 4.0 之后正式添加了事務的功能,并且在 MongoDB 4.2 中實現(xiàn)了分布式事務的功能,至此 MongoDB 開啟了支持事務之旅。