
【Python基礎(chǔ)】Python正則表達式,從入門到實戰(zhàn),精華都在這里!
??出品:Python數(shù)據(jù)之道(ID:PyDataLab)
作者:Peter,來自讀者投稿
編輯:Lemon
玩轉(zhuǎn)正則表達式
本文中介紹的是主要是 3 個知識點:
正則表達式的相關(guān)知識 Python的中re模塊,主要是用來處理正則表達式一個利用 re模塊通過正則表達式來進行網(wǎng)頁數(shù)據(jù)的爬取和存儲
使用的系統(tǒng) Python 版本和其他環(huán)境分別如下:
npython 3.7.5 MacOS jupyter notebook re ? # re 模塊 requests 2.23.0 ?# 發(fā)送請求
1、正則表達式
1.1 正則表達式及作用
正則表達式的英文是 regular expression,通常簡寫為 regex、regexp 或者RE,屬于計算機領(lǐng)域的一個概念。
正則表達式的主要作用是被用來進行文本的檢索、替換或者是從一個串中提取出符合我們指定條件的子串,它描述了一種字符串匹配的模式 pattern 。
目前正則表達式已經(jīng)被集成到了各種文本編輯器和文本處理工具中。
1.2 應(yīng)用場景
驗證:比如在網(wǎng)站中進行表單提交時,進行用戶名及密碼的驗證
查找:從給定的文本信息中進行快速高效地查找與分析字符串
替換:將我們指定格式的文本進行查找,然后將指定的內(nèi)容進行替換
1.3 網(wǎng)站
在這里介紹幾個用來學習和測試正則表達式的網(wǎng)站:
菜鳥教程-正則表達式
https://www.runoob.com/regexp/regexp-tutorial.html
正則表達式在線測試工具
https://tool.oschina.net/regex/
GoRegex.cn
https://goregex.cn/
官方re模塊學習
https://docs.python.org/zh-cn/3/library/re.html
正則表達式30分鐘入門教程
https://deerchao.cn/tutorials/regex/regex.htm#mission
1.4 常用字符功能
先介紹常用正則表達式中幾種特殊字符的功能:
字符類
| 字符 | 含義 | 例子 |
|---|---|---|
| . | 匹配任意一個字符 | ab.可以匹配abc或者abd |
| [ ] | 匹配括號中的任意1個字符 | [abcd]可以匹配ab、bc、cd |
| - | 在[ ]內(nèi)表示的字符范圍內(nèi)進行匹配 | [0-9a-fA-F]可以匹配任意一個16進制的數(shù)字 |
| ^ | 位于[ ]括號內(nèi)的開頭,匹配除括號中的字符之外的任意1個字符 | [^xy]匹配xy之外的任意一個字符,比如[^xy]1可以匹配A1、B1但是不能匹配x1、y1 |
數(shù)量限定符
| 字符 | 含義 | 例子 |
|---|---|---|
| ? | 匹配前面緊跟字符的0次或者1次 | [0-9]?,匹配1、2、3 |
| + | 匹配前面緊跟字符的1次或者多次 | [0-9]+,匹配1、12、123等 |
| * | 匹配前面緊跟字符的0次或者多次 | [0-9]*,不匹配或者12、123 |
| {N} | 匹配前面緊跟字符精確到N次 | [1-9][0-9]{2},匹配100到999的整數(shù),{2}表示[0-9]匹配兩個數(shù)字 |
| {,M} | 匹配前面緊跟字符最多M次 | [0-9]{,1},指的是最多匹配0-9之間的1個整數(shù),相當于是0次或者1次,等價于[0-9]? |
| {N,M} | 匹配前面緊跟字符的至少N次,最多M次 | [0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3},匹配IP地址,其中.號是特殊字符,需要使用轉(zhuǎn)義字符\ |
位置相關(guān)
| 字符 | 含義 | 例子 | |
|---|---|---|---|
| ^ | 匹配開頭的位置;通過\A | ^hello ?匹配hello開頭的字符內(nèi)容 | |
| $ | 匹配結(jié)束的位置同\Z | ;$ ?匹配一行結(jié)尾的;符號 ? ^$匹配空行 | |
| < | 匹配單詞開頭的位置 | ||
| > | 匹配單詞結(jié)尾的位置 | p> ?匹配leap等,但是不能匹配parent、sleepy等不是p結(jié)尾的單詞 | |
| \b | 匹配單詞開頭或結(jié)尾的位置 | \bat 匹配…at…,但是不能匹配cat、atexit、batch(非at開頭) | |
| \B | 匹配非單詞開頭或者結(jié)尾的單詞 | \Bat匹配battery,但是不能匹配attend/hat等以at開頭的單詞 |
特殊字符
| 字符 | 含義 | 例子 |
|---|---|---|
| \ | 轉(zhuǎn)義字符,保持后面字符的原義,使其不被轉(zhuǎn)義 | \. 輸出. |
| ( ) | 將表達式的一部分括起來,可以對整個單元使用數(shù)量限定符,匹配括號中的內(nèi)容 | ([0-9]{1,3}\.){3}[0-9]{1,3}表示將括號內(nèi)的內(nèi)容匹配3次 |
| | | 連接兩個子表達式,相當于或的關(guān)系 | n(o|either)匹配no或者neither |
| \d | 數(shù)字字符 | 相當于是[0-9] |
| \D | 非數(shù)字字符 | 相當于是[^0-9] |
| \w | 數(shù)字字母下劃線 | [a-zA-Z0-9_] |
| \W | 非數(shù)字字母下劃線,匹配特殊字符 | [^\w] |
| \s | 空白區(qū)域 | [\r\t\n\f]表格、換行等空白區(qū)域 |
| \S | [^\s] | 非空白區(qū)域 |
2、re 模塊
2.1 re 模塊簡介
在 Python 中主要是利用 re 模塊進行正則表達式的處理,涉及到 4 個常用的方法:
re.match() re.search() re.findall() re.sub() re.split()
5 個方法的基本使用語法是:
import?re???#?使用之前先進行導(dǎo)入re模塊
re.match(pattern,?string,?flags)???#?match方法為例
上面參數(shù)的說明:
| 參數(shù) | 描述 |
|---|---|
| pattern | 匹配的正則表達式 |
| string | 要匹配的字符串 |
| flags | 標志位,用于控制正則表達式的匹配方式,如:是否區(qū)分大小寫,多行匹配等等。 |
2.2 標志位 flags
正則表達式可以包含一些可選標志修飾符來控制匹配的模式。修飾符被指定為一個可選的標志,如 re.I | re.M 被同時設(shè)置成 I 和 M 標志:
| 修飾符 | 描述 |
|---|---|
| re.I | 忽略大小寫(常用) |
| re.L | 做本地化識別(locale-aware)匹配 |
| re.M | 多行匹配,影響 ^ 和 $ |
| re.S | 使 . 匹配包括換行在內(nèi)的所有字符 |
| re.U | 根據(jù)Unicode字符集解析字符。這個標志影響 \w, \W, \b, \B. |
| re.X | 該標志通過給予更靈活的格式,以便將正則表達式寫得更易于理解。 |
2.3 match
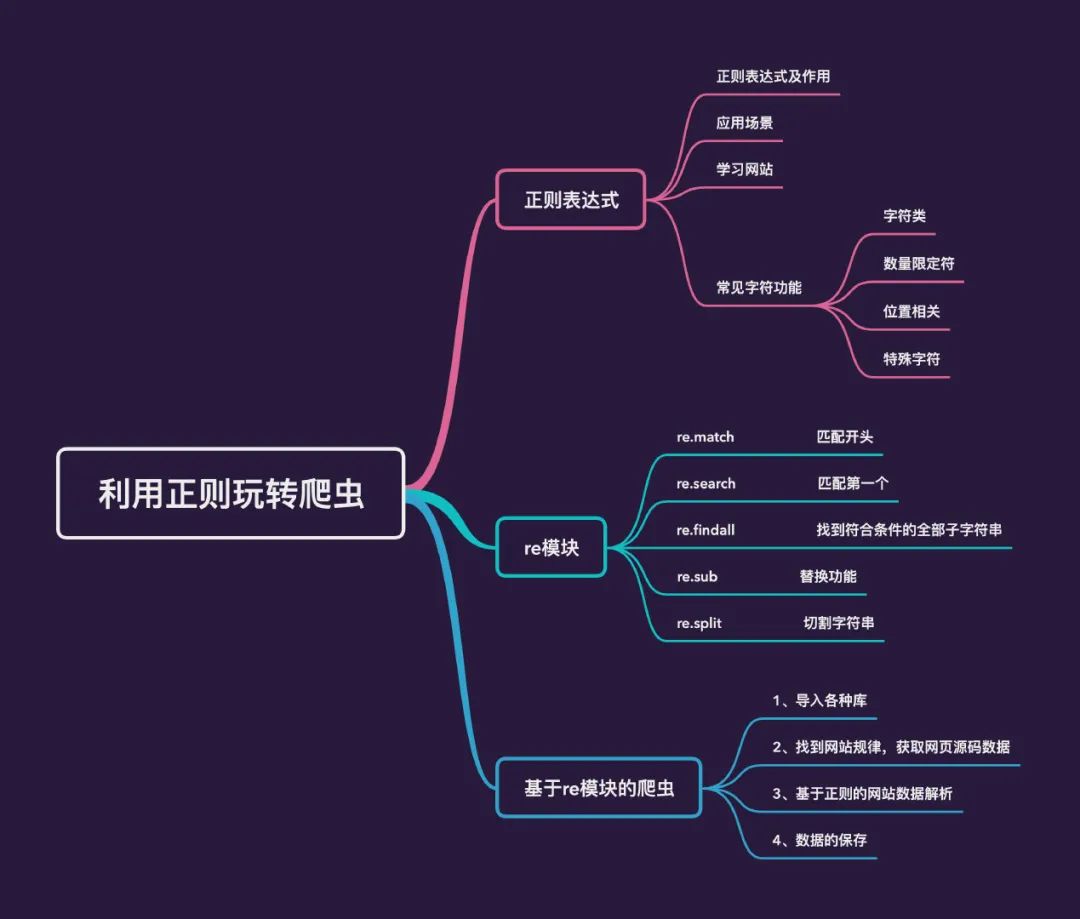
從指定字符串的開始位置進行匹配。開始位置匹配成功則繼續(xù)匹配,否則輸出None。
該方法的結(jié)果是返回一個正則匹配對象,通過兩個方法獲取相關(guān)內(nèi)容:
通過 group()來獲取內(nèi)容通過 span()來獲取范圍:匹配到字符的開始和結(jié)束的索引位置
開始位置沒有匹配成功,返回 None:

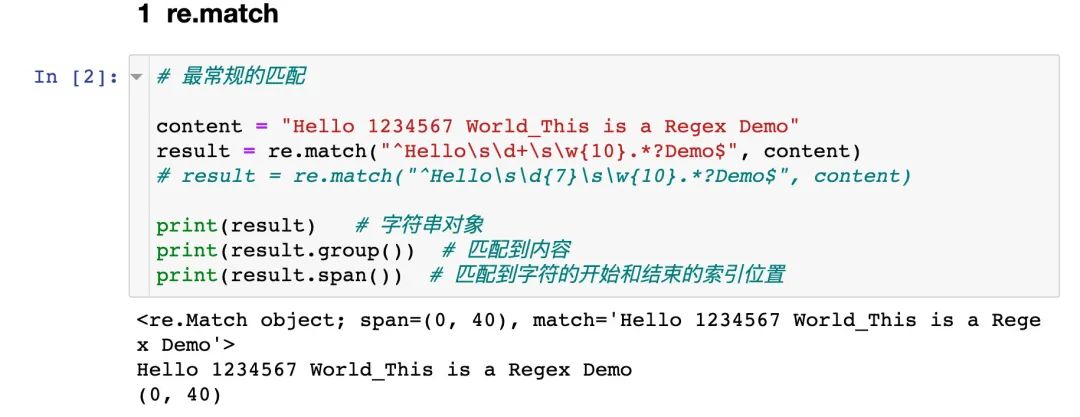
存在換行的字符串內(nèi)容,使用 re.S:
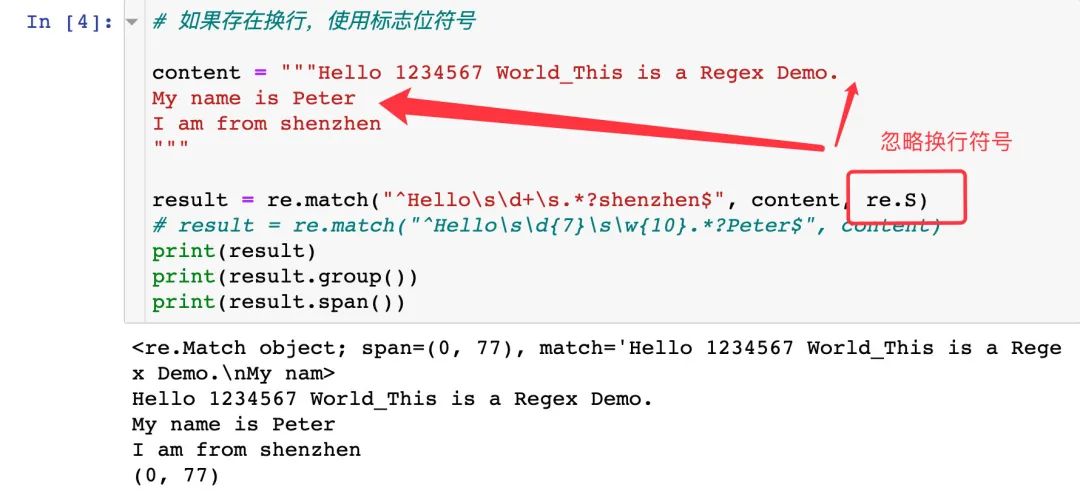
group() 方法獲取內(nèi)容的時候,索引符號從 1 開始:
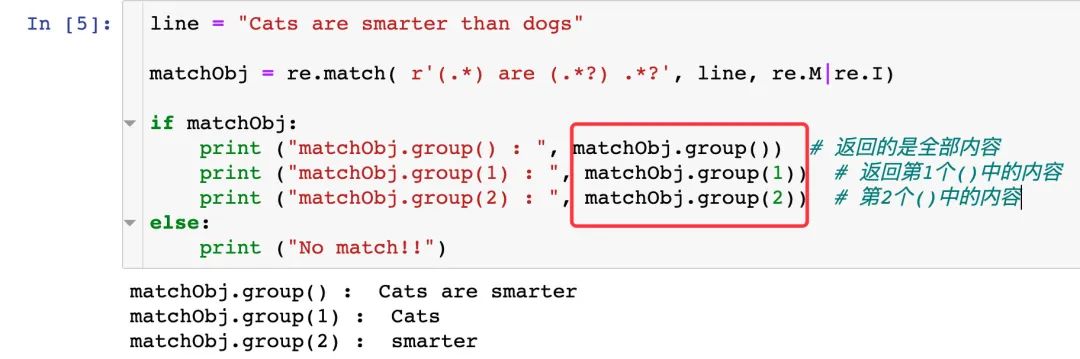
2.4 search
re.search 方法掃描整個字符串,返回的是第一個成功匹配的字符串,否則就返回 None


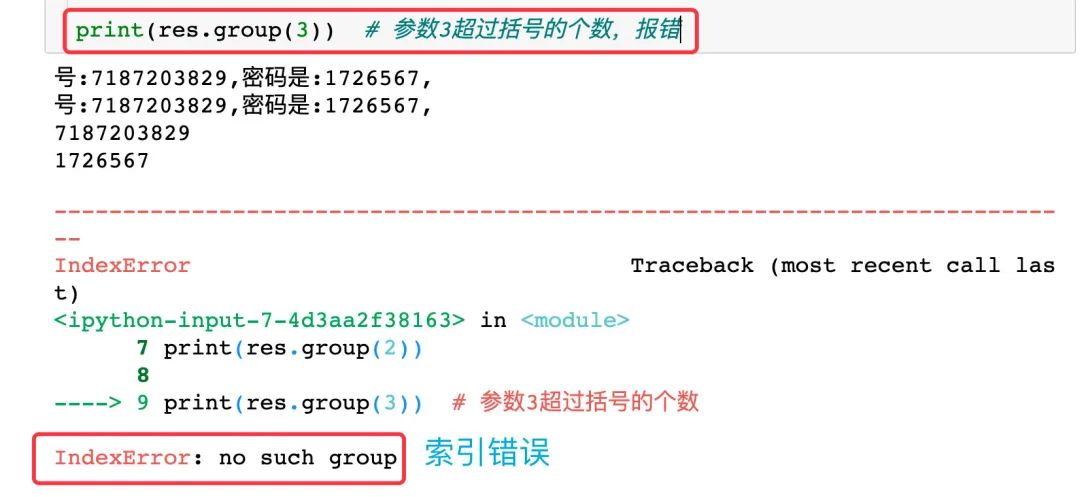
group(N) 中的參數(shù)N不能超過正則表達式中括號的個數(shù),若超過則報錯:
2.5 findall
re.findall() 是掃描整個字符串,通過列表形式返回所有符合的字符串
注意:
re.search是返回第一個符合要求的字符

如果存在多個 .*? ,則返回的內(nèi)容中使用列表中嵌套元組的形式:

2.6 sub
re.sub 方法是用來替換字符串中的某些內(nèi)容
直接替換 通過函數(shù)替換
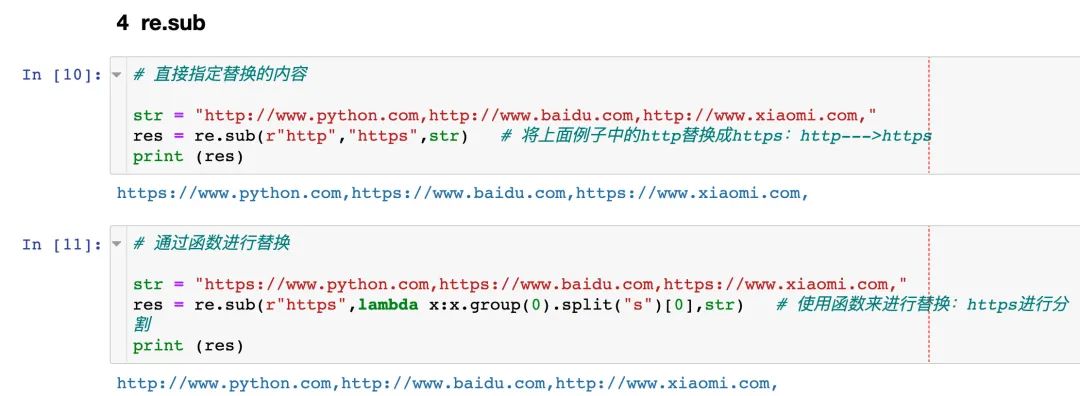
指定具體的替換內(nèi)容:將空格替換成短橫線

略微復(fù)雜的替換

2.7 split
用法
主要適用于將字符串進行分割:
re.split(pattern,?string,maxsplit=0,flags=0)
用 pattern 分開 string 。如果在 pattern 中捕獲到括號,那么所有的組里的文字也會包含在列表里。
如果 maxsplit 非零, 最多進行 maxsplit 次分隔, 剩下的字符全部返回到列表的最后一個元素。

如何理解是否保留匹配項

第二種寫法就是保留了匹配項
2.8 貪婪模式與非貪婪模式
貪婪與非貪婪模式影響的是被量詞修飾的子表達式的匹配行為。
貪婪模式在整個表達式匹配成功的前提下,盡可能多的匹配;而非貪婪模式在整個表達式匹配成功的前提下,盡可能少的匹配
我們在正則表達式中經(jīng)常會使用 3 個符號:
點 .:表示匹配的是除去換行符之外的任意字符問號 ?:表示匹配 0 個或者 1 個星號 *:表示匹配 0 個或者任意個字符
貪婪模式與非貪婪模式:
.*??非貪婪模式.*? 貪婪模式
看一個例子來比較 re 模塊中兩種匹配方式的不同:

在上面的非貪婪模式中,使用了問號 ?,當匹配到aaaacb已經(jīng)達到了要求,停止第一次匹配;接下來再開始匹配到ab;再匹配到adceb;所以存在多個匹配結(jié)果在貪婪模式中,程序會找到最長的那個符合要求的字符串
關(guān)于正則表達式中貪婪和非貪婪模式的詳解,請參考文章 https://www.cnblogs.com/520yang/articles/7473596.html,寫的非常清楚。
3、基于正則的爬蟲
字符串是在我們編程中涉及最多的一種數(shù)據(jù)結(jié)構(gòu),對字符串進行操作的需求幾乎無處不在。
比如我們編寫好了爬蟲程序,在得到了網(wǎng)頁的源碼之后,怎么從茫茫數(shù)據(jù)中提取出來我們指定的數(shù)據(jù)?這個通過正則表達式提取就是其中的方法之一。
接下來講解的通過 re 模塊來爬取某個網(wǎng)站的內(nèi)容。
3.1 網(wǎng)頁結(jié)構(gòu)
分析的網(wǎng)頁結(jié)構(gòu)和源碼的相關(guān)對應(yīng)信息:
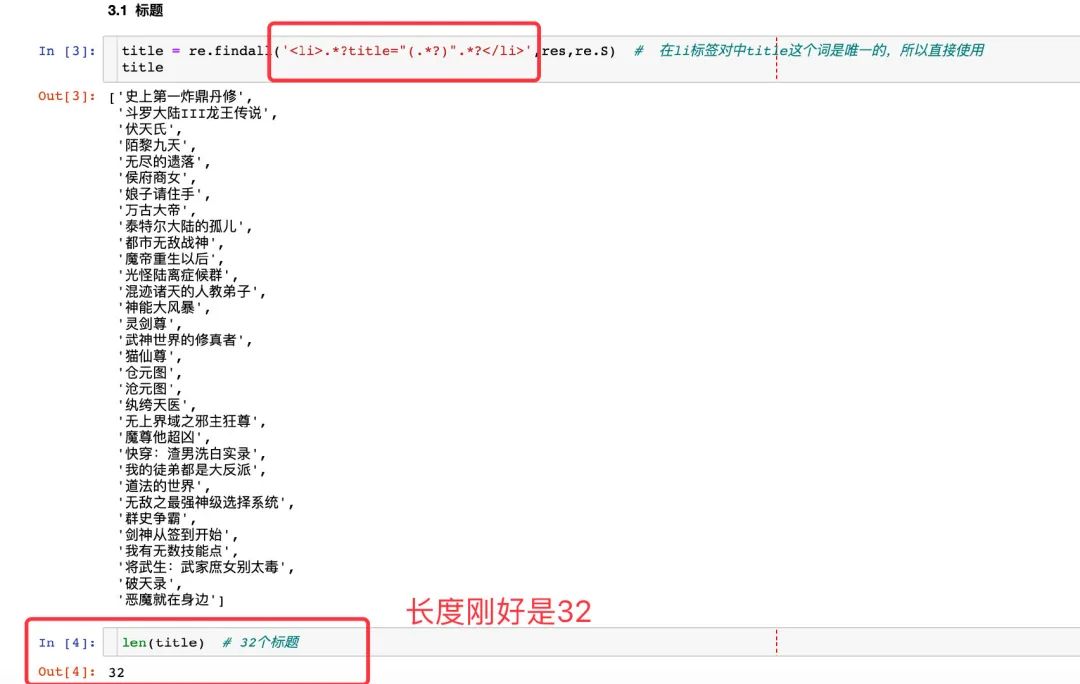
在每個網(wǎng)頁中有 32 篇小說

這 32 篇小說的信息存在于 32 個 對中:
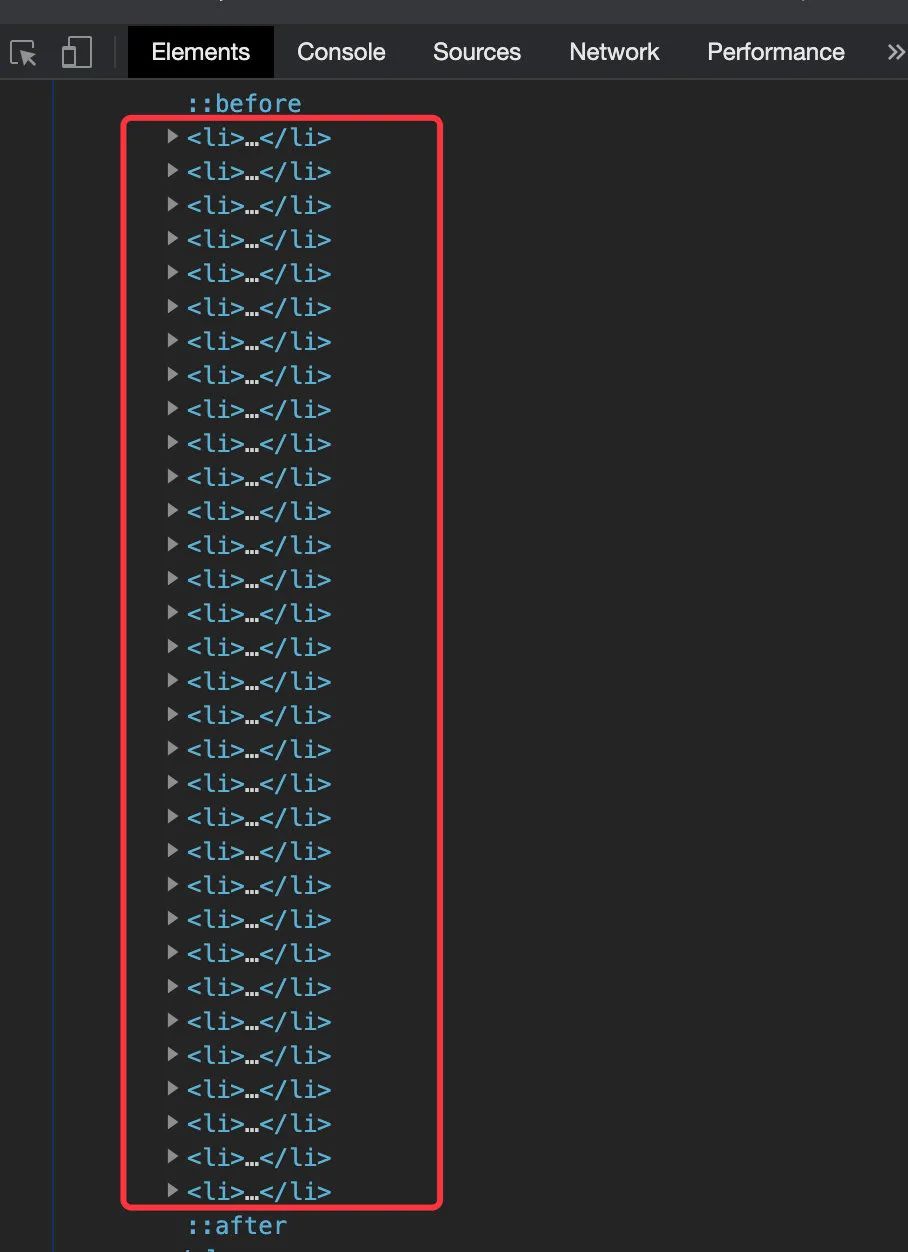
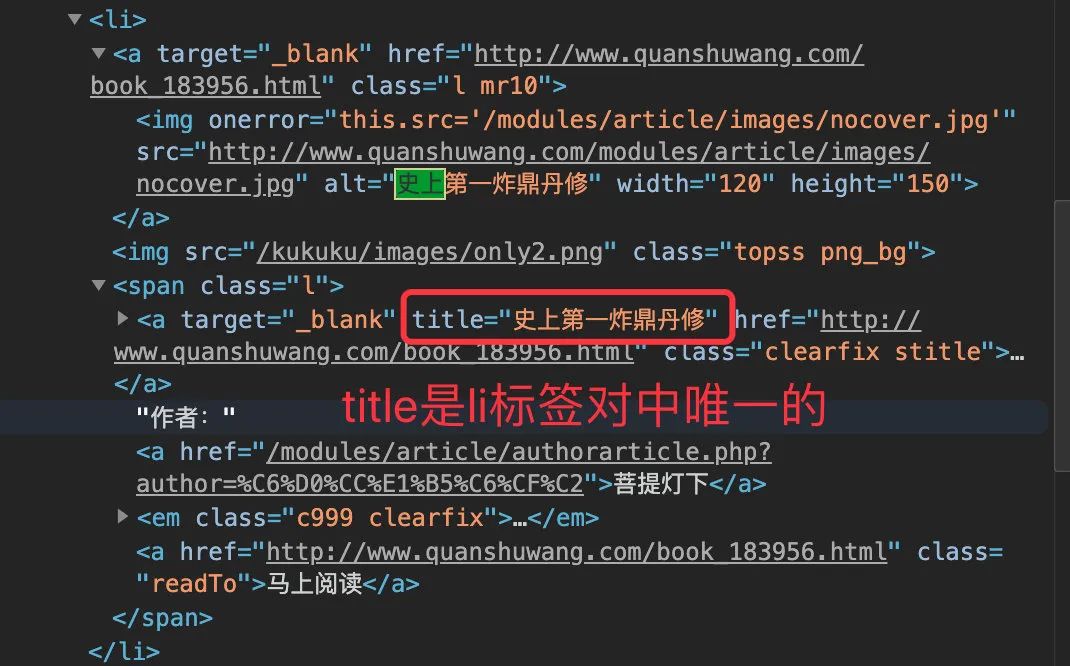
每篇信息存在一個 li中,比如第一篇:
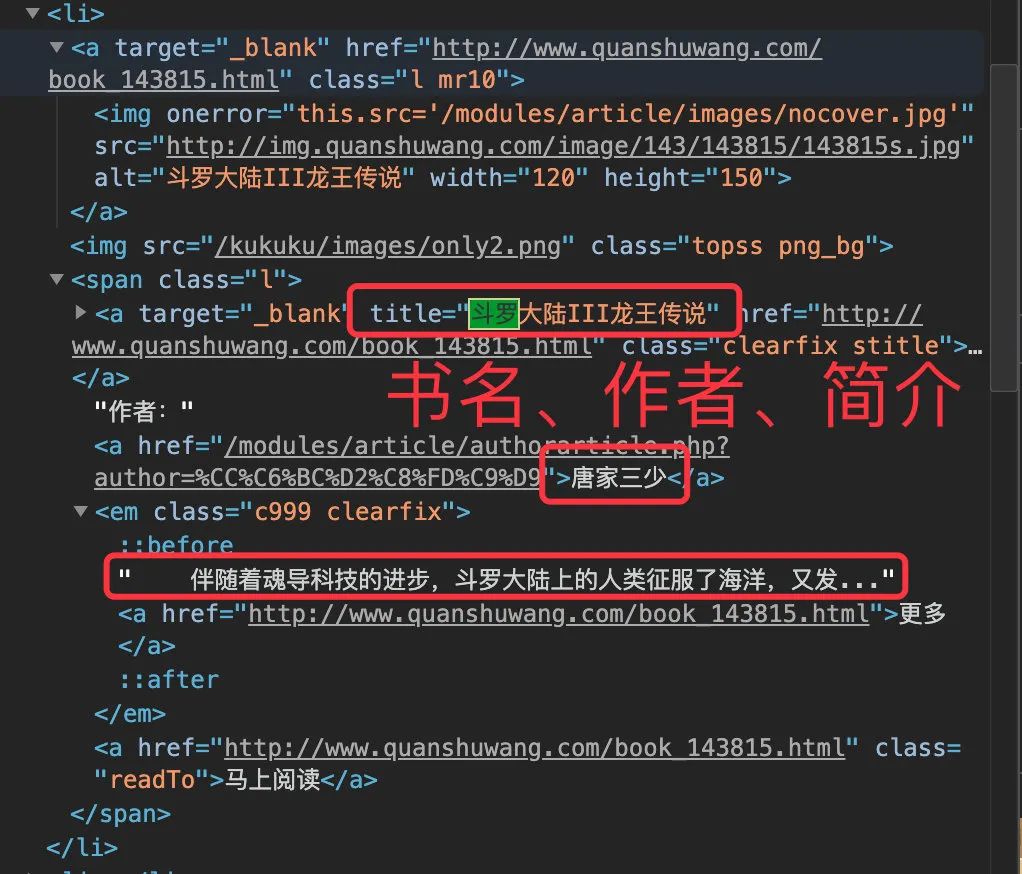
源碼和網(wǎng)頁中的對應(yīng)位置

3.2 網(wǎng)頁地址
第一頁的地址是 ?http://www.quanshuwang.com/list/1_1.html ?,第二頁是 http://www.quanshuwang.com/list/1_2.html ?,網(wǎng)頁地址的規(guī)律
for?i?in?range(1,?1156):??#?總共1155頁
??url?=?"http://www.quanshuwang.com/list/1_{}.html".format(i)
3.3 爬取信息
導(dǎo)入庫爬蟲中需要的庫
import?re??#?解析數(shù)據(jù)
import?requests?#?發(fā)送請求
import?csv??#?存入數(shù)據(jù)
import?pandas?as?pd
爬取第一頁
爬取第一頁的內(nèi)容進行測試
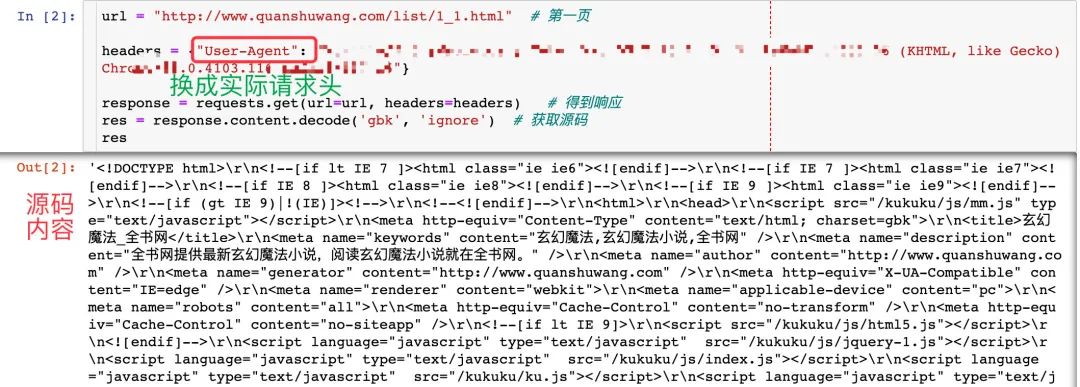
url?=?"http://www.quanshuwang.com/list/1_1.html"??#?第一頁
headers?=?{"User-Agent":?"自己的請求頭"}
response?=?requests.get(url=url,?headers=headers)???#?得到響應(yīng)
res?=?response.content.decode('gbk',?'ignore')??#?獲取源碼,實際編碼是gbk
res??
下面進行 3 個字段信息的爬取:
標題title
title 是 li 標簽對中唯一的,所以可以直接獲取雙引號中的內(nèi)容,最后檢驗下長度剛好是 32 :
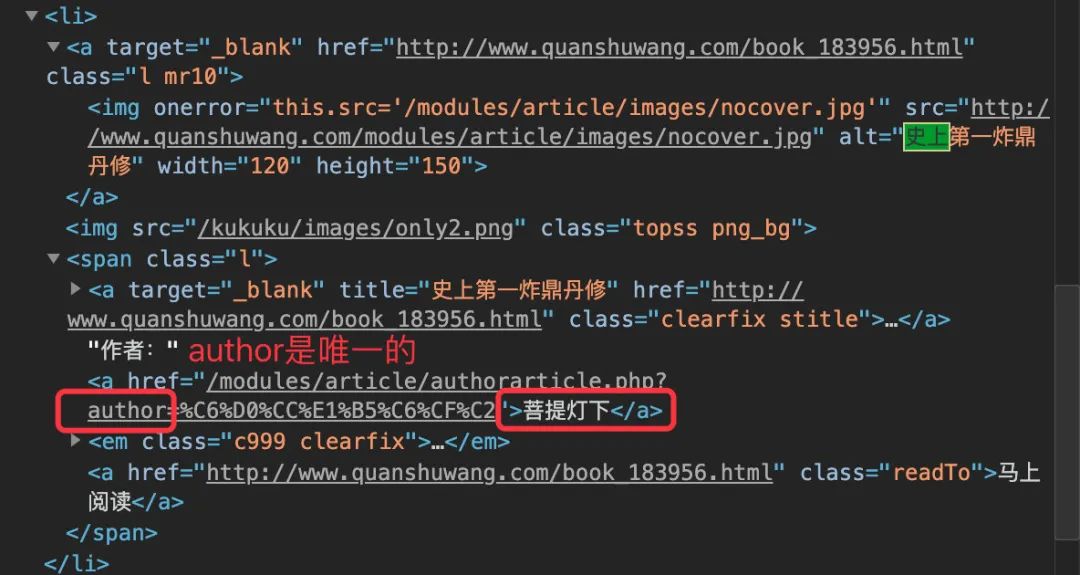
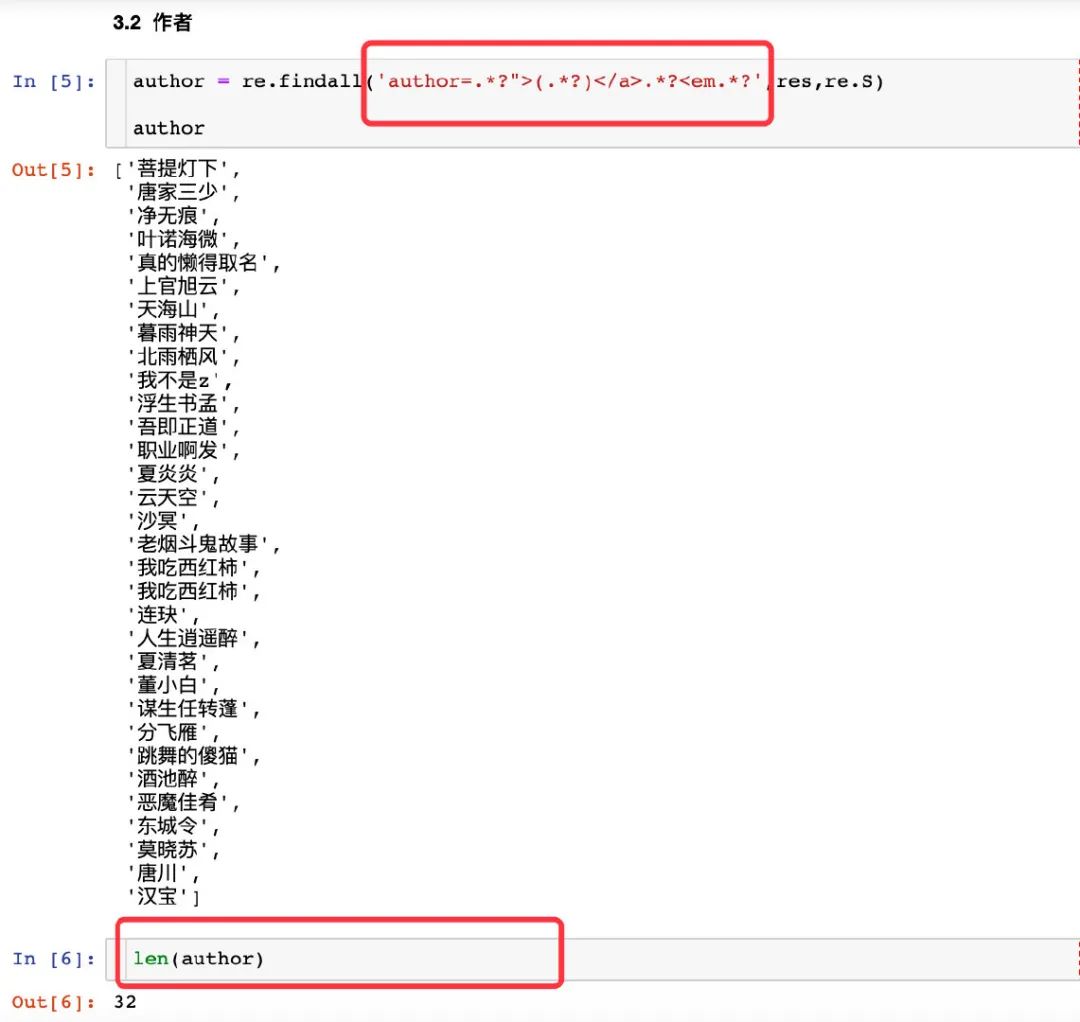
作者 author
author 是源碼中唯一的內(nèi)容,直接通過 author 后面的內(nèi)容進行獲取,檢驗長度也是 32
在 author 和 em 標簽中進行限制來獲取內(nèi)容
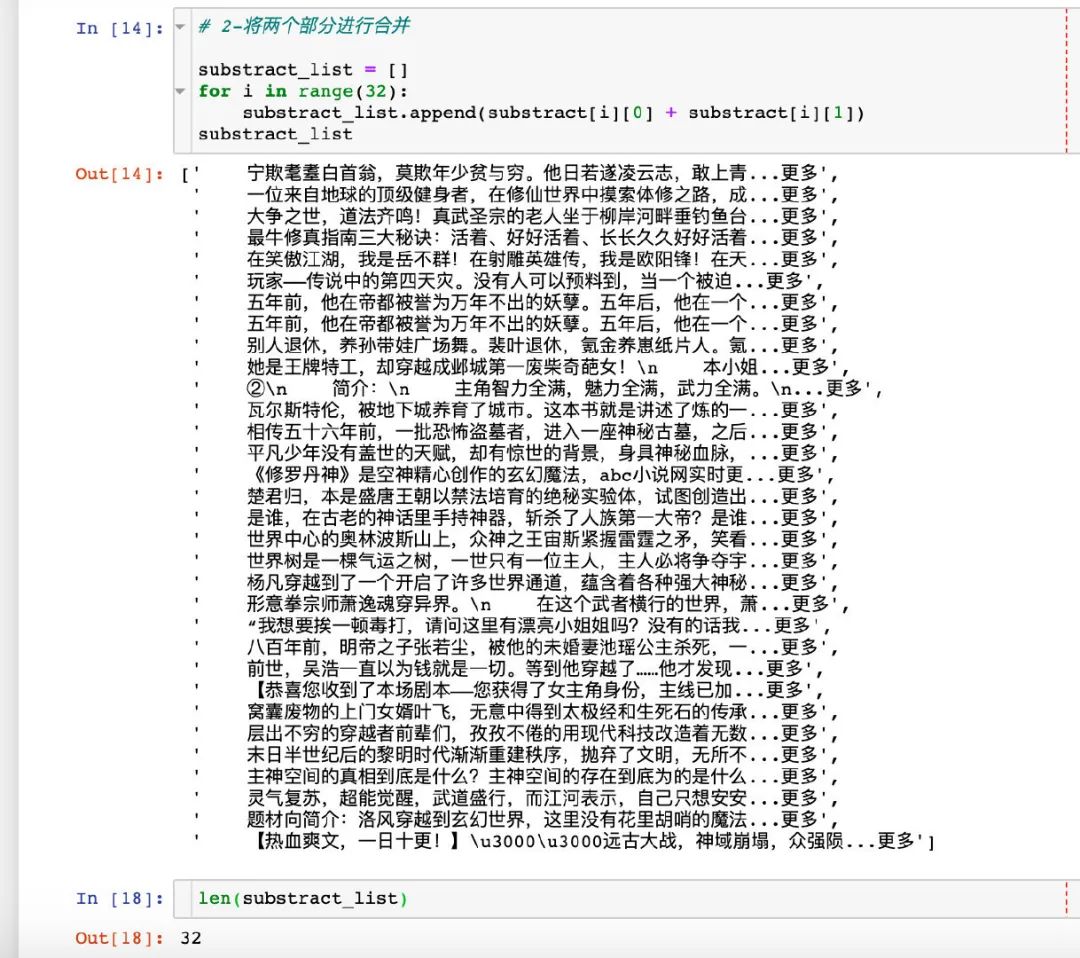
簡介 substract
對簡介的提取分為兩個部分:正文部分+更多。因為有些小說沒有簡介,只有更多 2 個字,所以需要特殊下
通過元組的形式單獨提取出兩個信息

將兩個信息進行合并,放到一個大列表中,同時檢驗長度仍然是 32
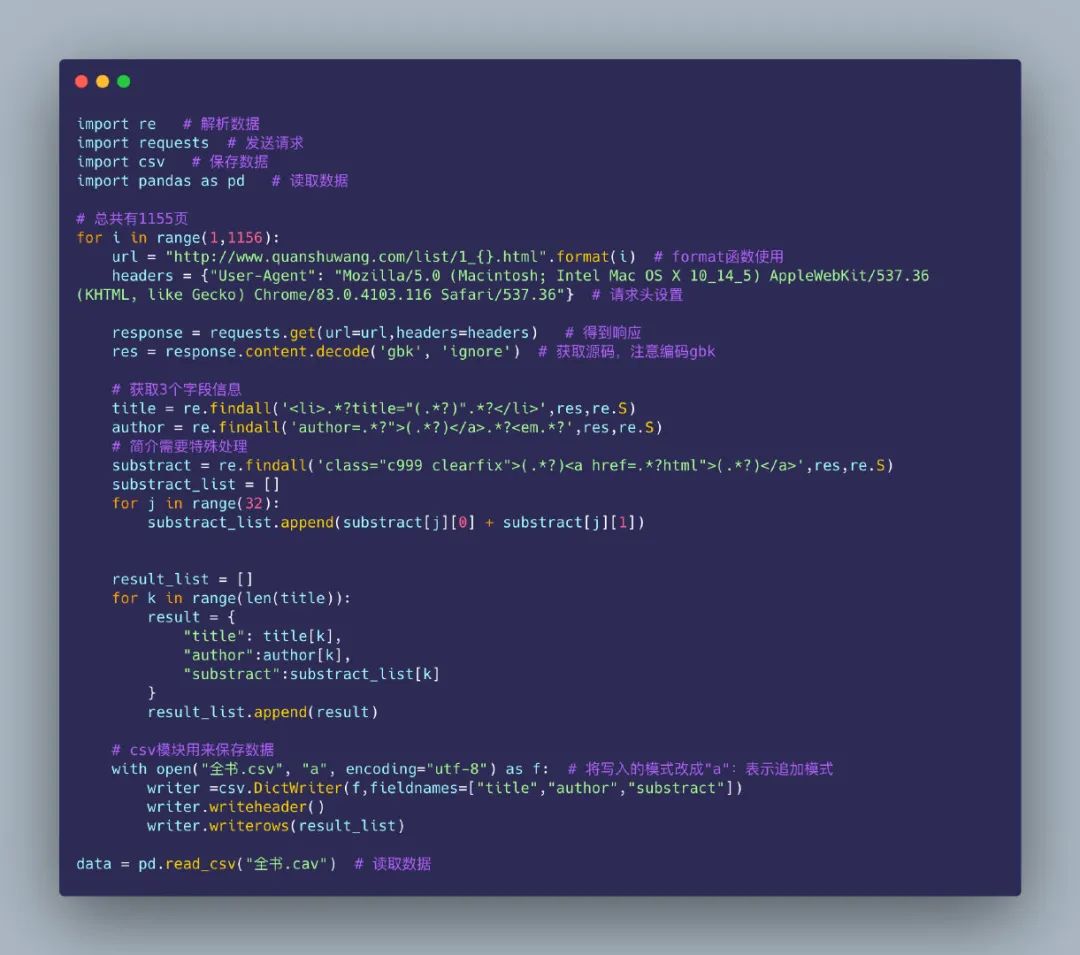
3.4 完整代碼
下面是完整的源碼,包含:
訪問鏈接獲取源碼數(shù)據(jù) 利用 re 模塊解析數(shù)據(jù) 利用 csv 模塊保存數(shù)據(jù) 讀取數(shù)據(jù)
作者簡介
Peter,碩士畢業(yè)僧一枚,從電子專業(yè)自學Python入門數(shù)據(jù)行業(yè),擅長數(shù)據(jù)分析及可視化。喜歡數(shù)據(jù),堅持跑步,熱愛閱讀,樂觀生活。個人格言:不浮于世,不負于己
個人站點:www.renpeter.cn,歡迎常來小屋逛逛
往期精彩回顧