
SHEIN提前批NLP面試題5道|含解析


從GCN的角度就是探索更多的權(quán)重矩陣。原文的解釋是MultiHead-Attention 提供了多個“表示子空間”,可以使模型在不同位置上關(guān)注來自不同“表示子空間”的信息。即通過MultiHead,模型可以捕捉到更加豐富的特征信息。這里的多個表示子空間其實就是GCN里的多個權(quán)重矩陣。
問題2:無序數(shù)組的中位數(shù)
方法一:快排一次后,檢查k落在哪個區(qū)域,然后對那個區(qū)域再進行一次快排。如此反復,可得答案。
方法二:同樣使用快排,但是對基準數(shù)不再隨機,而是盡可能找出讓兩段區(qū)域長度相等的劃分。(把原來的數(shù)組分成五份,然后找中位數(shù),然后再在這些中位數(shù)里找出中位數(shù)作為基準)
問題3:一個元素在一個有序數(shù)組的第一次出現(xiàn)位置?
要找到一個元素在一個有序數(shù)組中第一次出現(xiàn)的位置,你可以使用二分查找算法的變種。
def first_occurrence(arr, target):left, right = 0, len(arr) - 1result = -1 # 初始化結(jié)果為-1,表示未找到元素while left <= right:mid = left + (right - left) // 2 # 計算中間索引if arr[mid] == target:result = mid # 找到目標元素,更新結(jié)果right = mid - 1 # 繼續(xù)在左側(cè)查找第一次出現(xiàn)的位置elif arr[mid] < target:left = mid + 1else:right = mid - 1return result# 示例用法arr = [1, 2, 2, 2, 3, 4, 4, 5]target = 2first_index = first_occurrence(arr, target)if first_index != -1:print(f"元素 {target} 第一次出現(xiàn)的位置是 {first_index}")else:print(f"元素 {target} 在數(shù)組中未找到")
這段代碼首先初始化左右指針,然后在循環(huán)中執(zhí)行二分查找,查找目標元素的第一次出現(xiàn)位置。如果找到了目標元素,則更新結(jié)果為中間索引,然后繼續(xù)在左側(cè)查找以找到第一次出現(xiàn)的位置。如果未找到目標元素,返回結(jié)果為-1。
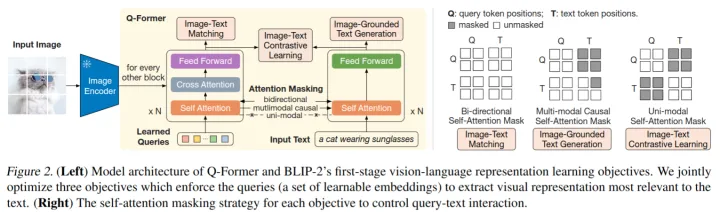
問題4:blip2的架構(gòu),優(yōu)勢和之前多模態(tài)模型的區(qū)別?
blip2是圖像-語言多模態(tài)模型的預訓練方法。這個架構(gòu)是2023年才提出的,也看出來面試緊跟時事了。
blip2的一個常見模式是輸入一張圖片,輸出這張圖片的描述。
bilp2是在凍結(jié)的圖像模型(負責從圖像中提取特征,比如vit)和凍結(jié)的語言模型(負責生成語言)中間放入一個Q-Former,我們的目標就是訓練這個Q-Former。Q-Former包含圖像Transformer和語言Transformer,圖像Transformer包含CA和SA,SA和語言Transformer共享參數(shù),CA只接受圖像模型提取的圖像特征,圖像模型的輸入是一個查詢值,這個查詢值將在SA中和自己交互,在CA中和圖像特征交互。最后圖像Transformer輸出一個綜合圖像特征的向量,同時語言Transformer輸入一個文本,進行encode,得到一個文本的向量。然后根據(jù)具體的任務選擇不同的方式對這兩個向量進行操作。最后,Q-former把得到的向量傳給凍結(jié)的語言模型。語言Transformer訓練的時候做解碼器,預測的時候是解碼器。
訓練的時候先訓練Q-Former和圖像模型的交互,然后把Q-Former的結(jié)果和語言模型連接(中間可以加入全連接,前綴詞等操作)。如下圖
問題5: 知識蒸餾和無監(jiān)督樣本訓練?
知識蒸餾是利用大模型把一個大模型的知識壓縮到一個小模型上。具體來說你在一個訓練集上得到了一個非常好的較大的模型,
然后你把這個模型凍結(jié),作為Teacher模型也叫監(jiān)督模型,然后你再造一個較小參數(shù)的模型叫做Student模型,我們的目標就是利用凍結(jié)的Teacher模型去訓練Student模型。
A.離線蒸餾:Student在訓練集上的loss和與Teacher模型的loss作為總的loss,一起優(yōu)化。
B.半監(jiān)督蒸餾:向Teacher模型輸入一些input得到標簽,然后把input和標簽傳給Student模型
還有個自監(jiān)督蒸餾,直接不要Teacher模型,在最后幾輪epoch,把前面訓練好的模型作為Teacher進行監(jiān)督。
目前知識蒸餾的一個常見應用就是對齊ChatGPT。
然后這個無監(jiān)督樣本訓練,我看不懂意思。如果是傳統(tǒng)的無監(jiān)督學習,那就是聚類,主成分分析等操作。如果是指知識蒸餾的話,就是離線蒸餾的方式,只不過損失只有和Teacher的loss。
免費送


掃碼回復【999】免費領(lǐng)10本電子書
(或找七月在線其他老師領(lǐng)取)
點擊“閱讀原文”搶寵粉福利~
