
何愷明編年史
及時獲取最優(yōu)質(zhì)的CV內(nèi)容

榮譽
別人的榮譽都是在某某大廠工作,拿過什么大獎,而何愷明的榮譽是best,best,best ......,裂開了

研究興趣
據(jù)我觀察,何愷明的研究興趣大致分成這么幾個階段:
傳統(tǒng)視覺時代:Haze Removal(3篇)、Image Completion(2篇)、Image Warping(3篇)、Binary Encoding(6篇)
深度學(xué)習(xí)時代:Neural Architecture(11篇)、Object Detection(7篇)、Semantic Segmentation(11篇)、Video Understanding(4篇)、Self-Supervised(8篇)
代表作
2009 CVPR best paper?Single Image Haze Removal Using Dark Channel Prior
利用實驗觀察到的暗通道先驗,巧妙的構(gòu)造了圖像去霧算法。現(xiàn)在主流的圖像去霧算法還是在Dark Channel Prior的基礎(chǔ)上做的改進。
2016 CVPR best paper?Deep Residual Learning for Image Recognition
通過殘差連接,可以訓(xùn)練非常深的卷積神經(jīng)網(wǎng)絡(luò)。不管是之前的CNN,還是最近的ViT、MLP-Mixer架構(gòu),仍然擺脫不了殘差連接的影響。
2017 ICCV best paper?Mask R-CNN
在Faster R-CNN的基礎(chǔ)上,增加一個實例分割分支,并且將RoI Pooling替換成了RoI Align,使得實例分割精度大幅度提升。雖然最新的實例分割算法層出不窮,但是精度上依然難以超越Mask R-CNN。
2017 ICCV best student paper?Focal Loss for Dense Object Detection
構(gòu)建了一個One-Stage檢測器RetinaNet,同時提出Focal Loss來處理One-Stage的類別不均衡問題,在目標檢測任務(wù)上首次One-Stage檢測器的速度和精度都優(yōu)于Two-Stage檢測器。近些年的One-Stage檢測器(如FCOS、ATSS),仍然以RetinaNet為基礎(chǔ)進行改進。
2020 CVPR Best Paper Nominee?Momentum Contrast for Unsupervised Visual Representation Learning
19年末,NLP領(lǐng)域的Transformer進一步應(yīng)用于Unsupervised representation learning,產(chǎn)生后來影響深遠的BERT和GPT系列模型,反觀CV領(lǐng)域,ImageNet刷到飽和,似乎遇到了怎么也跨不過的屏障。就在CV領(lǐng)域停滯不前的時候,Kaiming He帶著MoCo橫空出世,橫掃了包括PASCAL VOC和COCO在內(nèi)的7大數(shù)據(jù)集,至此,CV拉開了Self-Supervised研究新篇章。
近期工作
62-Exploring Simple Siamese Representation Learning
SimSiam:孿生網(wǎng)絡(luò)表征學(xué)習(xí)的頂級理論解釋
65-Masked Autoencoders Are Scalable Vision Learners
NLP和CV的雙子星,注入Mask的預(yù)訓(xùn)練模型BERT和MAE
時間線
1-Single Image Haze Removal Using Dark Channel Prior

kaiming he通過大量無霧圖片統(tǒng)計發(fā)現(xiàn)了dark channel prior—在無霧圖的局部區(qū)域中,3個通道的最小亮度值非常小接近于0(不包括天空區(qū)域)。
dark channel prior通過暗通道先驗對haze imaging model進行化簡,近似計算得到粗糙的transmission,然后將haze imaging model和matting model聯(lián)系起來,巧妙的將圖像去霧問題轉(zhuǎn)化為摳圖問題,得到refined transmission,精彩!
何愷明經(jīng)典之作—2009 CVPR Best Paper | Dark Channel Prior
3-Guided Image Filtering
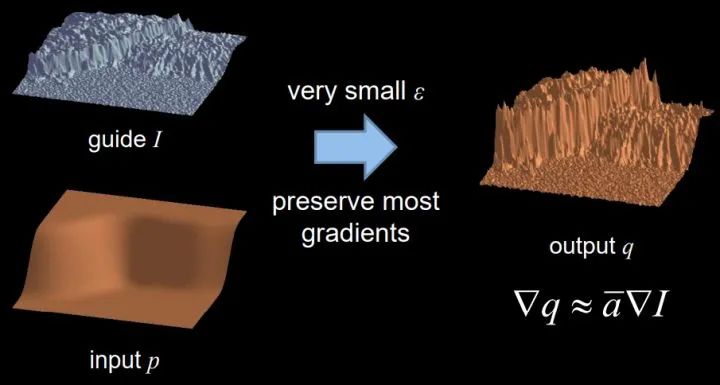
Guided image filtering是結(jié)合兩幅圖片信息的過程,一個filtering input image(表示為p)和一個guide image(表示為I)生成一個filtering output image(表示為q)。p決定了q的顏色,亮度,和色調(diào),I決定了q的邊緣。對于圖像去霧來說,transmission就是p,霧圖就是I,refined transmission就是q。
guided filter則通過公式轉(zhuǎn)換,和濾波聯(lián)系起來,提出新穎的guided filter,巧妙的避開了linear system的計算過程,極大加快了transmission優(yōu)化的速度。
何愷明經(jīng)典之作—2009 CVPR Best Paper | Dark Channel Prior
37-Focal Loss for Dense Object Detection
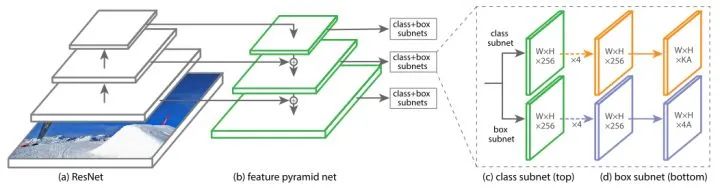
構(gòu)建了一個One-Stage檢測器RetinaNet,同時提出Focal Loss來處理One-Stage的類別不均衡問題,在目標檢測任務(wù)上首次One-Stage檢測器的速度和精度都優(yōu)于Two-Stage檢測器。近些年的One-Stage檢測器(如FCOS、ATSS),仍然以RetinaNet為基礎(chǔ)進行改進。
38-Mask R-CNN
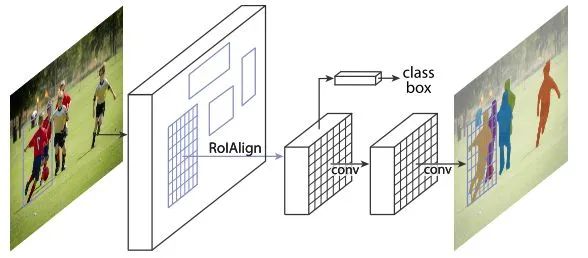
在Faster R-CNN的基礎(chǔ)上,增加一個實例分割分支,并且將RoI Pooling替換成了RoI Align,使得實例分割精度大幅度提升。雖然最新的實例分割算法層出不窮,但是精度上依然難以超越Mask R-CNN。
62-Exploring Simple Siamese Representation Learning

SimSiam的理論解釋意味著帶stop-gradient的孿生網(wǎng)絡(luò)表征學(xué)習(xí)都可以用EM算法解釋。stop-gradient起到至關(guān)重要的作用,并且需要一個預(yù)測期望E的方法進行輔助使用。但是SimSiam仍然無法解釋模型坍塌現(xiàn)象,SimSiam以及它的變體不坍塌現(xiàn)象仍然是一個經(jīng)驗性的觀察,模型坍塌仍然需要后續(xù)的工作進一步討論。
SimSiam:孿生網(wǎng)絡(luò)表征學(xué)習(xí)的頂級理論解釋
63-A Large-Scale Study on Unsupervised Spatiotemporal Representation Learning
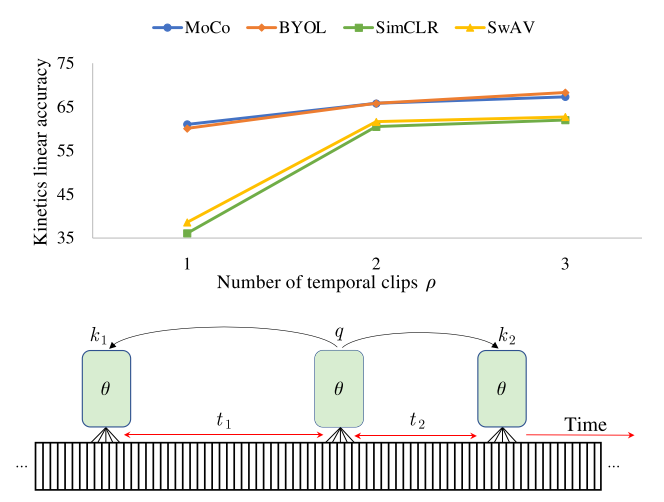
指出時空的Self-Supervised采樣同一個視頻的positive pair時間跨度越長效果越好,momentum encoder比優(yōu)化目標重要,訓(xùn)練時間、backbone、數(shù)據(jù)增強和精選數(shù)據(jù)對于得到更好性能至關(guān)重要。
何愷明+Ross Girshick:深入探究無監(jiān)督時空表征學(xué)習(xí)
64-An Empirical Study of Training Self-Supervised Vision Transformers
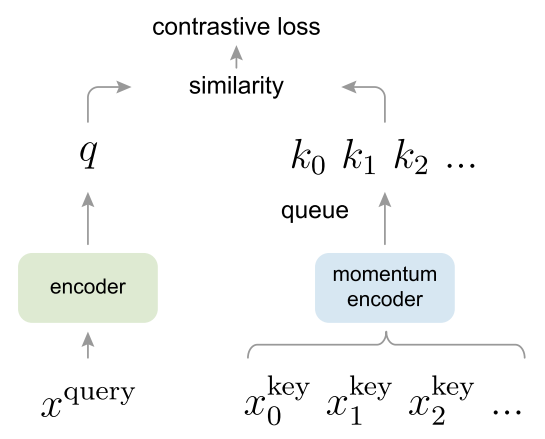
MoCov1通過dictionary as a queue和momentum encoder和shuffle BN三個巧妙設(shè)計,使得能夠不斷增加K的數(shù)量,將Self-Supervised的威力發(fā)揮的淋漓盡致。MoCov2在MoCov1的基礎(chǔ)上,增加了SimCLR實驗成功的tricks,然后反超SimCLR重新成為當時的SOTA,F(xiàn)AIR和Google Research爭鋒相對之作,頗有華山論劍的意思。MoCov3通過實驗探究洞察到了Self-Supervised+Transformer存在的問題,并且使用簡單的方法緩解了這個問題,這給以后的研究者探索Self-Supervised+Transformer提供了很好的啟示。
65-Masked Autoencoders Are Scalable Vision Learners
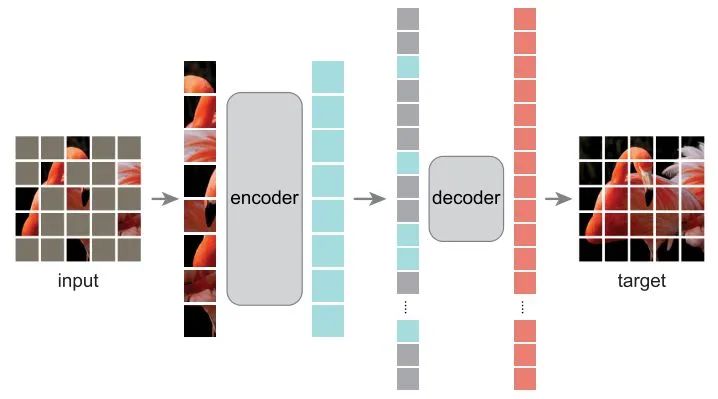
MAE設(shè)計了一個encoder-decoder預(yù)訓(xùn)練框架,encoder只送入image token,decoder同時送入image token和mask token,對patch序列進行重建,最后還原成圖片。相比于BEiT,省去了繁瑣的訓(xùn)練tokenizer的過程,同時對image token和mask token進行解耦,特征提取和圖像重建進行解耦,encoder只負責image token的特征提取,decoder專注于圖像重建,這種設(shè)計直接導(dǎo)致了訓(xùn)練速度大幅度提升,同時提升精度,真稱得上MAE文章中所說的win-win scenario了。
NLP和CV的雙子星,注入Mask的預(yù)訓(xùn)練模型BERT和MAE
kaiming科研嗅覺頂級,每次都能精準的踩在最關(guān)鍵的問題上,提出的方法簡潔明了,同時又蘊含著深刻的思考,文章賞心悅目,實驗詳盡扎實,工作質(zhì)量說明一切。
長按掃描下方二維碼添加小助手。
可以一起討論遇到的問題
聲明:轉(zhuǎn)載請說明出處
掃描下方二維碼關(guān)注【集智書童】公眾號,獲取更多實踐項目源碼和論文解讀,非常期待你我的相遇,讓我們以夢為馬,砥礪前行!
