
總結MySQL 8種性能優(yōu)化方式
點擊上方藍色字體,選擇“標星公眾號”
優(yōu)質文章,第一時間送達
一、設置索引
索引是一種可以讓SELECT語句提高效率的數(shù)據(jù)結構,可以起到快速定位的作用。
索引的優(yōu)缺點:
優(yōu)點:某些情況下使用select語句大幅度提高效率,合適的索引可以優(yōu)化MySQL服務器的查詢性能,從而起到優(yōu)化MySQL的作用。
缺點:表行數(shù)據(jù)的變化(index、update、delect),簡歷在表列上的索引也會自動維護,一定程度上會使DML操作變慢。索引還會占用磁盤額外的存儲空間。
MySQL索引操作:
給表列創(chuàng)建索引:
建表時創(chuàng)建索引:
create table t(id int,name varchar(20),index idx_name (name));
給表追加索引:
alter table t add unique index idx_id(id);
給表的多列上追加索引
alter table t add index idx_id_name(id,name);
或者:create index idx_id_name on t(id,name);
查看索引
使用show語句查看t表上的索引:
show index from t;
或者:show keys from t;–mysql中索引也被稱作keys?

使用show create table語句查看索引:
show create table t\G
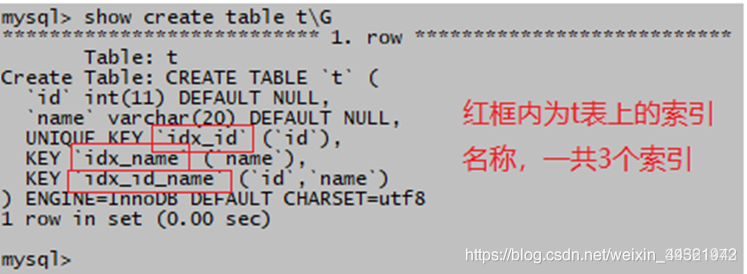
刪除索引:使用alter table命令刪除索引:
alter table 表 drop index 索引名
使用drop index命令刪除索引:
drop index 索引名 on 表
索引原理:
例如一個學生信息表,我們設置學號(stu_id)為索引:
索引頁之間存在一定的關聯(lián)關系,一般為樹形結構;分為根節(jié)點、分支節(jié)點、和葉子節(jié)點
根節(jié)點頁中存放分段stu_id的起始值,以及值所對應的分支索引頁號
分支索引頁中存放分段stu_id的起始值,以及值所對應的葉子索引頁號
葉子索引頁中存放排序后的stu_id值,該值所對應的表頁號, 下一個葉子索引頁的頁號
stu_id建立索引后,執(zhí)行select name,sex,height from stu where stu_id=13查詢過程如下:
索引頁存在關聯(lián)關系,先找索引頁號20的根節(jié)點,13在>=11和<17的范圍內,需要查找25號索引頁
讀取25號索引頁,13在>=11和<14范圍內,得到了26號葉子索引頁
讀取26號葉子索引頁,找到了13這個值,以及該值所對應表頁的頁號161,目前只得到了stu_id的值,還要得到name,sex,height等,因此需要再讀一次編號為161的表頁,里面存放了stu_id之外的值。
讀取161號表頁,獲得sname,sex,height等值
以上4步,只讀取了3個索引頁1個表頁,共4個頁,比讀取所有表頁(5000個頁),按照stu_id=13挨個翻一遍效率要高,這也是有些情況下索引可以加速查詢的原因。二、使用EXPLAIN 來查看你的 SELECT 查詢
關于MySQL服務器是如何執(zhí)行SQL語句的相關信息可以用explain語句來查看,可以用explain語句查看執(zhí)行過程的語句主要有select、insert、update、delete等,其使用方式是explain后接具體的增刪改查SQL語句。
例如:explain select * from test.t; 其返回形式為數(shù)據(jù)表,如下圖所示:
其中每個字段代表的含義如下:
通過:type、possible_keys和key三個字段,我們能清楚的知道查詢語句是否使用了索引和使用了哪個索引。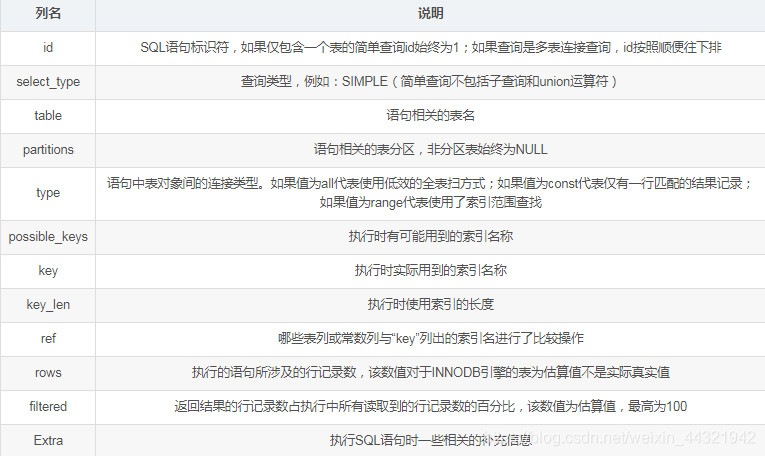
三、不要使用表達式作為查詢條件
假設有一庫為test,其中有一個以百萬行記錄的t表,t表的ID列建有索引。比較以下兩種SQL語句書寫方式,比較運行時間:
方式一:select * from t where id+1<5;
方式二:select * from t where id<5-1;
方式一結果如下:?
用時0.62秒,通過explain查看使用的查詢key發(fā)現(xiàn)并沒有使用索引來進行查詢: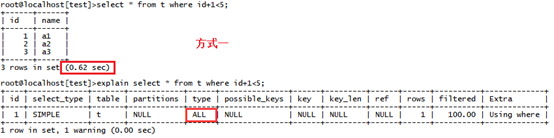
方式二結果如下:
用時小于0.00秒,通過explain查看使用的查詢key發(fā)現(xiàn)使用了索引進行查詢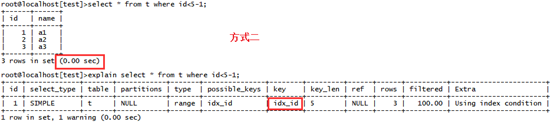
從實驗結果看出,如果采用方式一(運行時間0.62秒),使用采用表達式的方式作為查詢條件,條件列中的索引會失效,即便返回行數(shù)非常少,優(yōu)化器也會使用低效的全表掃方式來解析SQL語句;如果同樣效果的語句采用方式二的寫法,索引不會失效,查詢效率高。
發(fā)生這種事情的深層原因在于:
大多數(shù)的MySQL服務器都開啟了查詢緩存。這是提高性最有效的方法之一,而且這是被MySQL的數(shù)據(jù)庫引擎處理的。當有很多相同的查詢被執(zhí)行了多次的時候,這些查詢結果會被放到一個緩存中,這樣,后續(xù)的相同的查詢就不用操作表而直接訪問緩存結果了。但是當使用表達式的時候,就會不使用緩存,因為這些函數(shù)的返回是會不定的易變的
四、盡量使用in運行符來替代or運算
比較以下兩種SQL語句書寫方式,比較運行時間:
方式一:select * from t where id=1 or id=2 or id=3;
方式二:select * from t where id in (1,2,3);
由于t表id列已添加索引,可以使用MySQL自帶壓力測試工具mysqlslap,增加并發(fā)用戶數(shù)量和查詢次數(shù)比較兩種方式的運行效率。
mysqlslap命令常用選項如下所示:
-u:連接數(shù)據(jù)庫用戶名
-p:鏈接數(shù)據(jù)庫密碼
-concurrency:并發(fā)諒解客戶端數(shù)量
-query:運行的測試SQL語句
-create-schema:測試SQL語句所在數(shù)據(jù)庫
-number-of-queries:所有鏈接客戶端運行測試SQL語句的次數(shù)
-itreations:本次測試的重復執(zhí)行次數(shù)
將方式一和方式二的SQL語句,使用mysqlslap進行測試,采用100個并發(fā)客戶端,所有客戶端一共運行5000次,可以寫成以下方式:
方式一:
mysqlslap -uroot -p --create-schrma=test --query=‘select * from t where id=1 or id=2 or id=3’ --concurrency=100 --number-of-queries=5000
方式二:
mysqlslap -uroot -p --create-schema=test --query=‘select * from t where id in (1,2,3)’ --concurrency=100 --number-of-queries=5000
測試結果如下: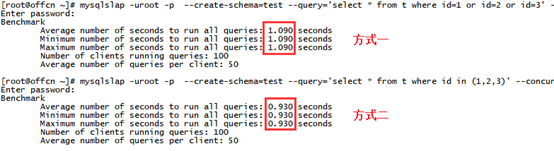
從實驗結果可以看出,SQL語句采用方式一的or方式50個并發(fā)用戶執(zhí)行5000次查詢所用的時間為1.09秒;SQL語句采用方式二的in方式50個并發(fā)用戶執(zhí)行5000次查詢所用的時間為0.93秒,在寫法等效的情況下,使用IN來替代OR效率更高。
五、條件列表值如果連續(xù)使用between替代in
繼續(xù)以上實驗,從t表中僅要找出id值為1,2,3的行,因為id值連續(xù),可以使用以下第三種方式書寫SQL語句:
方式三:select * from t where id between 1and 3
使用mysqlslap驗證執(zhí)行效率:
mysqlslap -uroot -p --create-schema=test --query=‘select * from t where id between 1 and 3’ --concurrency=100 --number-of-queries=5000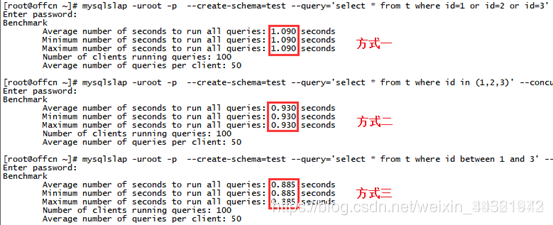
結果如下
SQL語句采用方式三between的寫法,在50個并發(fā)用戶執(zhí)行5000次查詢的測試時間為0.885秒,參照前述實驗的測試結果,執(zhí)行效率進一步提高。可以看出如果條件列表數(shù)值連續(xù)的情況下,SQL語句采用BETWEEN的方式比用IN方式效率更高。
六、無重復記錄的結果集使用union all合并
MySQL數(shù)據(jù)庫中使用union或union all運算符將一個或多個列數(shù)相同的查詢結果集上下合并成為一個查詢結果集。其中union會合并各個結果集中相同的記錄行,重復記錄只顯示一次外加自動排序,而union all運算符不去重不排序。因此,對于無重復記錄的多個查詢結果集應當使用union all合并。參見如下實驗:
方法一:select * from t where id=1 union select * from t where id=2;
方法二:select * from t where id=1 union all select * from t where id=2;
結果如下
使用mysqlslap測試:
方法一:mysqlslap -uroot -p --create-schema=test --query=‘select * from t where id=1 union select * from t where id=2’ --concurrency=100 --number-of-queries=5000;
方法二:mysqlslap -uroot -p --create-schema=test --query=‘select * from t where id=1 union all select * from t where id=2’ --concurrency=100 --number-of-queries=5000;
在50個并發(fā)用戶執(zhí)行5000次查詢的測試中執(zhí)行效率有所差異,如下圖所示: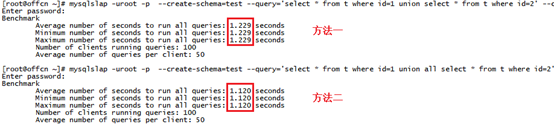
從測試結果可以看出,使用union運算符由于需要去除重復記錄和排序,查詢時間為1.229秒高于union all運算符的1.120秒。因此,對于無重復記錄的結果集使用union all合并的效率要高。
七、有條件使用where就不使用having
在SELECT查詢語句中,where子句和having子句都起到對行記錄過濾的作用,主要區(qū)別在于having子句是對group by子句產(chǎn)生的結果(可能包含聚合函數(shù)),而where子句先于having子句運行,主要目的是縮減查詢結果集的行記錄數(shù)。實驗需要復雜一些的數(shù)據(jù)表,可以通過http://downloads.mysql.com/docs/world.sql.zip鏈接下載MySQL例子數(shù)據(jù)庫。該數(shù)據(jù)庫包含,country(國家),city(城市)和countrylanguage(國家語言)三張數(shù)據(jù)表。例子數(shù)據(jù)庫下載解壓后包含world.sql文件,使用mysql客戶端的source命令運行后,會創(chuàng)建包含前述三張表的world數(shù)據(jù)庫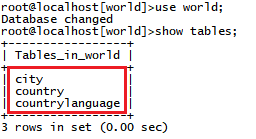
mysql> select Code,Name from country where Name=‘China’;
中國的國家編號是“CHN”,如果要在city(城市)表中統(tǒng)計中國的城市數(shù)量,可以通過以下兩種方式SQL語句獲取,其結果集相同:
方式一:select CountryCode,count() from city where CountryCode=‘CHN’;
方式二:select CountryCode,count() from city group by CountryCode having CountryCode=‘CHN’;
將方式一和方式二的SQL語句,使用mysqlslap進行測試,采用100個并發(fā)客戶端,所有客戶端一共運行5000次,可以寫成以下方式:
方式一:
mysqlslap -uroot -p --concurrency=100 --iterations=1 --number-of-queries=5000 --create-schema=world --query=“select CountryCode,count() from city where CountryCode=‘CHN’"
方式二:
mysqlslap -uroot -p --concurrency=100 --iterations=1 --number-of-queries=5000 --create-schema=world --query="select CountryCode,count() from city group by CountryCode having CountryCode=‘CHN’”
從以上測試結果看,使用where子句的方式一的SQL書寫方式僅僅耗時1.463秒,遠低于耗時6.897秒的使用having子句的SQL書寫方式二。其主要原因是方式二的SQL寫法是在分組統(tǒng)計了所有國家城市的數(shù)量,然后再使用having子句將統(tǒng)計結果過濾出僅僅是中國的城市數(shù)量,SQL解析器耗費了大量資源統(tǒng)計了與需求無關的數(shù)據(jù),致使查詢效率下降。因此,當需求明確時,應盡量使用where子句縮小查詢結果集,然后再使用相關聚合函數(shù)進行統(tǒng)計分析。
八、使用like操作符時通配符要放在右側
在書寫SQL語句時,如果在where或having子句中使用like模糊匹配操作符,通配符“%”或“_”不要寫在匹配字符串的左側,參見以下兩種書寫方式:
方式一:select * from t where name like ‘150’;
方式二:select * from t where name like ‘a(chǎn)150_’;
為test庫t表的name列添加索引,索引名稱idx_name:
mysql> create index idx_name on t(name);
mysql> show index from name;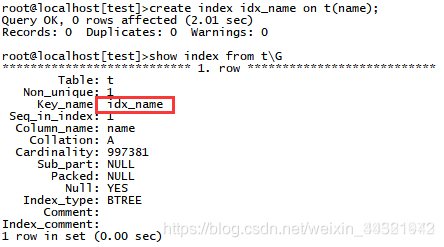
對比方式一和方式二的執(zhí)行效果
結果如下: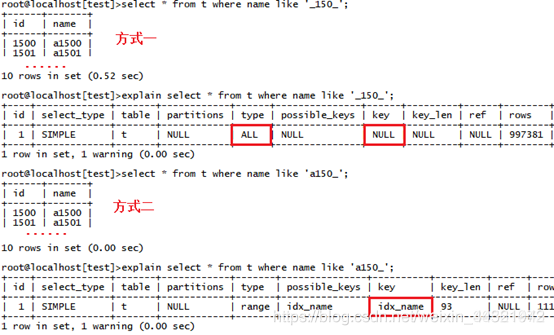
從測試結果可以看出,使用like操作符的查詢條件列帶有索引時,如果通配符放在最左邊,索引會失效,SQL優(yōu)化器會選擇效率低的全表掃解析方式,主要原因是對字符串類型創(chuàng)建索引時,MySQL將從最左開始選取一部分(767字符,最多到3072字符)字符串,將其內容存入到索引中。如果查詢條件最左側是可以匹配任意字符的通配符,無法定位具體的索引鍵值,優(yōu)化器就會選擇其他獲取數(shù)據(jù)的方式而忽略索引的存在。因此,當帶有索引的查詢條件列是字符類型,如果使用模糊匹配操作符,不要將其放在最左側,要放到第一個具體字符的右側。
九、補充:
數(shù)據(jù)庫怎么優(yōu)化查詢效率?
儲存引擎選擇:如果數(shù)據(jù)表需要事務處理,應該考慮使用 InnoDB,因為它完全符合 ACID 特性。
如果不需要事務處理,使用默認存儲引擎 MyISAM 是比較明智的
分表分庫,主從。
對查詢進行優(yōu)化,要盡量避免全表掃描,首先應考慮在 where 及 order by 涉及的列上建立索
引
應盡量避免在 where 子句中對字段進行 null 值判斷,否則將導致引擎放棄使用索引而進行全
表掃描
應盡量避免在 where 子句中使用 != 或 <> 操作符,否則將引擎放棄使用索引而進行全表掃
描
應盡量避免在 where 子句中使用 or 來連接條件,如果一個字段有索引,一個字段沒有索引,
將導致引擎放棄使用索引而進行全表掃描
Update 語句,如果只更改 1、2 個字段,不要 Update 全部字段,否則頻繁調用會引起明顯的
性能消耗,同時帶來大量日志
對于多張大數(shù)據(jù)量(這里幾百條就算大了)的表 JOIN,要先分頁再 JOIN,否則邏輯讀會很高,
性能很差。
版權聲明:本文為博主原創(chuàng)文章,遵循 CC 4.0 BY-SA 版權協(xié)議,轉載請附上原文出處鏈接和本聲明。
本文鏈接:
https://blog.csdn.net/weixin_44321942/article/details/89161781
粉絲福利:Java從入門到入土學習路線圖
???

?長按上方微信二維碼?2 秒
感謝點贊支持下哈?