
【萬級并發(fā)】電商庫存扣減如何設計?不超賣!
隨著中國消費認知的不斷升級,網(wǎng)購走近千家萬戶,越來越被人們所接受。淘寶、唯品會、考拉、京東、拼多多等逐漸成為我們生活的重要組成部分。

除了常規(guī)的購物下單外,這些電商平臺還經(jīng)常搞一些雙十一活動,秒殺、大促、限時購,各種營銷玩法,層出不窮。今天就來跟大家聊一聊電商技術(shù)里的庫存扣減

當有很多人同時在買一件商品時(假設庫存充足),每個人幾乎同時下單成功,給人一種并行的感覺。但真實情況,庫存只是一個數(shù)值,無論是存在mysql數(shù)據(jù)庫還是redis緩存,減值時都要控制順序,只能串行來扣減,當然為了保證安全性,會設計一些鎖控制操作。
?? 庫存扣減關鍵技術(shù)點
同一個SKU,庫存數(shù)量是共享 剩余庫存要大于等于本次扣減的數(shù)量,否則會出現(xiàn) 超賣現(xiàn)象,引發(fā)資損對同一個數(shù)量多用戶并發(fā)扣減時,要注意并發(fā)安全,保證數(shù)據(jù)的一致性 類似于秒殺這樣高QPS的扣減場景,要保證性能與高可用 對于購物車下單場景,多個商品庫存批量扣減,要保證事務 如果有 交易退款,保證庫存扣減可以返還返還的數(shù)據(jù)總量不能大于扣減的總量 返還要保證冪等 可以分多次返還
?? 數(shù)據(jù)庫扣減方案
主要是依賴數(shù)據(jù)庫特性來保證扣減的一致性,邏輯簡單,開發(fā)部署成本很低。
依賴的數(shù)據(jù)庫特性:
依賴數(shù)據(jù)庫的樂觀鎖(比如:版本號或者庫存數(shù)量)保證數(shù)據(jù)并發(fā)扣減的強一致性 借助事務特性,針對購物車下單批量扣減時,部分扣減失敗,數(shù)據(jù)回滾
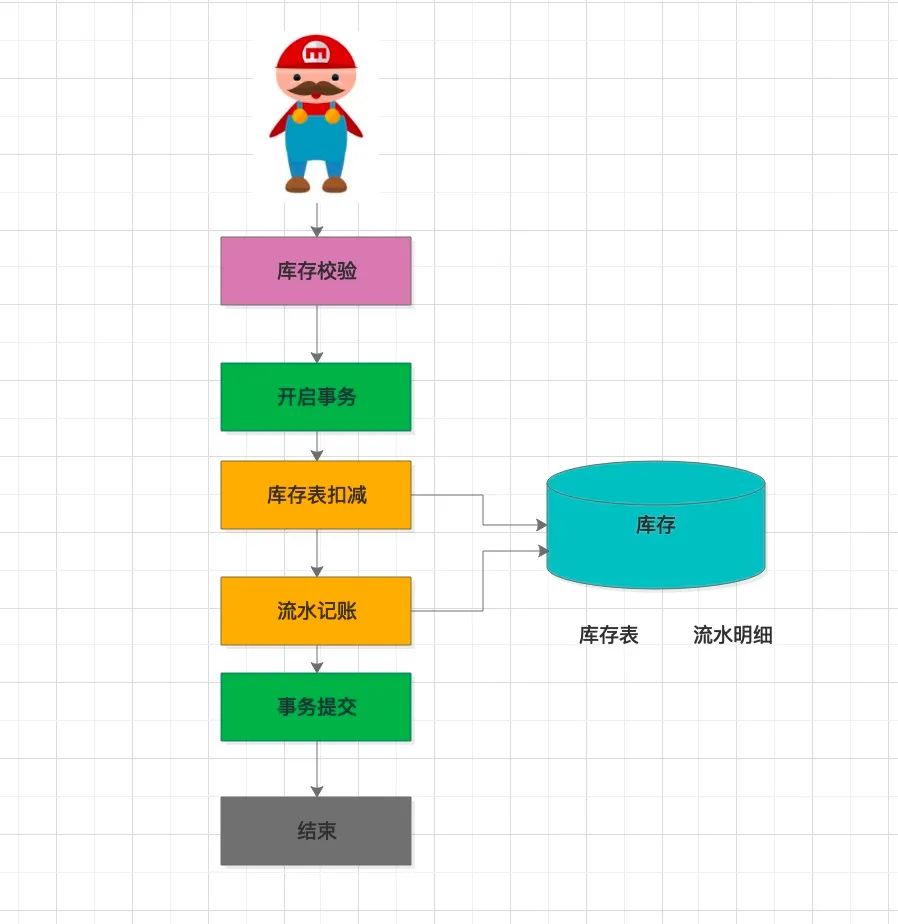
最上面會查詢當前的剩余庫存(可能不準確,但沒關系,這里只是第一步粗略校驗),前置校驗,如果已經(jīng)沒有庫存,前置攔截生效,減少對數(shù)據(jù)庫的寫操作。畢竟讀操作不涉及加鎖,并發(fā)性能高。數(shù)據(jù)庫包含兩張表:庫存表、流水表。
1、庫存表
| 字段 | 說明 |
|---|---|
| sku_id | 商品規(guī)格id |
| leaved_amount | 剩余可購買數(shù)量 |
當用戶進行取消訂單、申請退貨退款,需要把數(shù)量加回來 如果商家補過庫存,需要在此基礎上額外加上增量庫存
2、 流水表
| 字段 | 說明 |
|---|---|
| id | 主鍵id |
| sku_id | 商品規(guī)格id |
| order_detail_id | 訂單明細id |
| quantity_trade | 本次購買扣減的數(shù)量 |
用于查看明細、對賬、盤貨、排查問題等 在扣減后,某些場景下需要返還也依賴流水
單條商品的扣減SQL大致如下:
update?inventory?
set?leaved_amount?=?leaved_amount?-?#{count}?
where?sku_id='123'?and?leaved_amount?>=?#{count}
此 SQL 采用數(shù)據(jù)庫自帶行鎖機制,在 where 條件里判斷此次購買的數(shù)量小于等于剩余的數(shù)量。在扣減服務的代碼里,判斷此 SQL 的返回值,如果值為 1 ,表示扣減成功。否則,返回 0 ,表示庫存不足,需要回滾。
扣減成功后,需要記錄扣減流水,并與訂單明細記錄做關聯(lián)。
當用戶歸還數(shù)量時,需要帶回此編號,用來標識此次返還屬于歷史上的具體哪次扣減。
進行冪等性控制。當用戶調(diào)用扣減接口出現(xiàn)超時時,因為用戶不知道是否成功,用此編號進行重試或反查。在重試時,使用此編號進行標識防重。
?? 【數(shù)據(jù)庫扣減方案】第一次升級
舉個極端的例子:最新款iPhone秒殺,庫存只有5件,活動期間峰值QPS預估在10W,活動結(jié)束后,上面的流水表最終只會插入5條記錄,但是查詢的QPS卻接近 10W QPS,讀的壓力非常大。
所以,數(shù)據(jù)庫扣減方案第一次升級主要是針對庫存前置校驗模塊的優(yōu)化,作為前置攔截器,承載的流量很大,如果將流量全部壓到主庫上,很容易把數(shù)據(jù)壓垮。我們考慮把數(shù)據(jù)庫架構(gòu)升級。

采用了讀寫分離方式,新增加了一套從庫,借助mysql自帶的數(shù)據(jù)同步能力。庫存校驗時讀取從數(shù)據(jù)庫。
當然,數(shù)據(jù)同步有一定的時間延遲,從庫的數(shù)據(jù)新鮮度有一定的滯后性,所以這個庫存校驗結(jié)果并不一定準確,但卻能攔截大部分的無效流量。最終能不能成功購買,由主庫的樂觀扣減SQL來控制,并不會影響最終扣減的準確性。大大減輕主庫的查詢壓力。
?? 【數(shù)據(jù)庫扣減方案】第二次升級
引入了從庫,確實能分攤主庫很大一部分壓力,但是面對秒殺這種萬級QPS流量,mysql的千級TPS根本支撐不了,需要進一步升級讀取的性能。
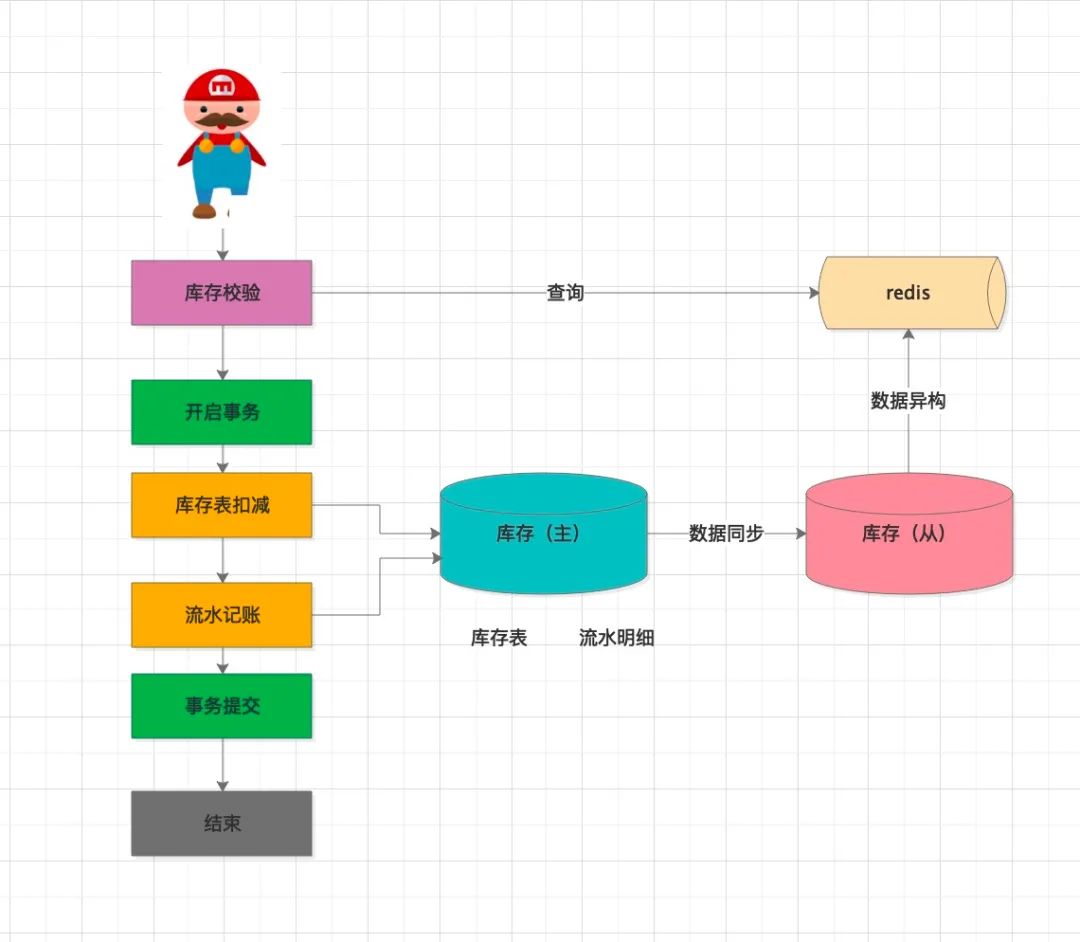
此時引入緩存中間件(如Redis),將mysql的數(shù)據(jù)定時同步到緩存中 庫存校驗模塊,從redis中查詢剩余的庫存數(shù)據(jù)。由于緩存基于內(nèi)存操作,性能比數(shù)據(jù)庫高出幾個數(shù)量級,單臺redis實例可以達到10W QPS的讀性能
該方案升級后,基本上解決了在前置庫存校驗環(huán)節(jié)及獲取庫存數(shù)量接口的性能問題,提高了系統(tǒng)整體性能,提供較好的用戶體驗。
補充說明:
如果并發(fā)量還是很高的話,可以考慮引入緩存集群,將不同的秒殺商品sku盡量均勻分布在多個redis節(jié)點中,從而分攤掉整體的峰值QPS壓力。(參考緩存熱點的解決方案)
數(shù)據(jù)庫方案的優(yōu)點:
借助數(shù)據(jù)庫的 ACID特性,業(yè)務上不會出現(xiàn)超賣、少買現(xiàn)象實現(xiàn)簡單,如果項目工期緊張,或者開發(fā)資源不足情況下非常適用
數(shù)據(jù)庫方案的不足:
如果參與秒殺的SKU非常多,最后的寫操作都是基于 庫存主庫,性能壓力會比較大。
?? 純緩存扣減方案
Redis采用單線程的事件模型,具有原子性的特性。當有多個客戶端給Redis發(fā)送命令時,Redis會按照接收到的順序串行化執(zhí)行。對于還未被調(diào)度的命令,則放在隊列里排隊等待。
庫存扣減為了保證數(shù)據(jù)并發(fā)安全,要求原子性,而Redis正好滿足扣減類的特殊性要求,是個不錯的技術(shù)選型。
下面,我們簡單來看看基于Redis如何來設計庫存扣減?
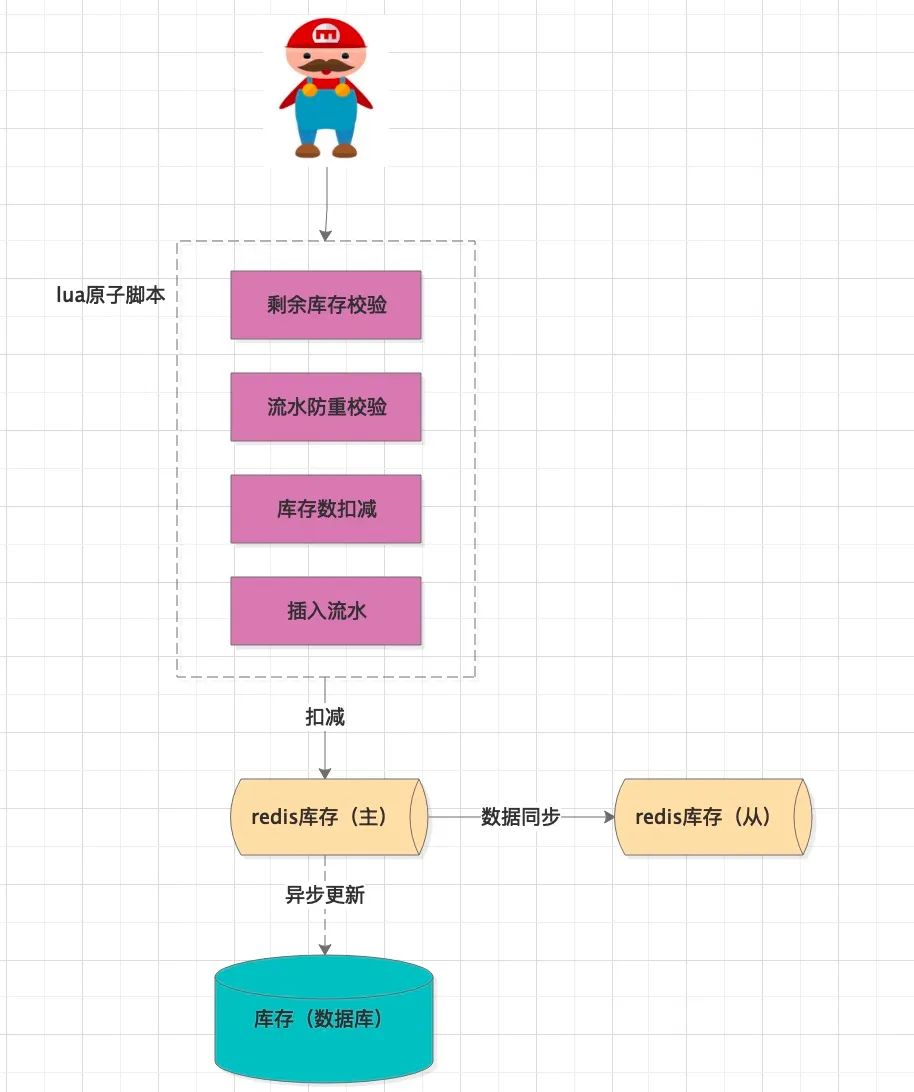
首先,設計Redis的數(shù)據(jù)模型:
剩余庫存(k-v結(jié)構(gòu)):
key:sku_leaved_amount_{sku_id}
value:剩余的庫存數(shù)值
流水(hash結(jié)構(gòu)):
key:inventory_flow_{sku_id}
hash—key:訂單明細id(不同業(yè)務場景的全局性id,用來做冪等控制)
hash—value:本次購買的數(shù)量
對于購物車下單,多個sku批量扣減,我們需要按單個sku循環(huán)發(fā)起Redis調(diào)用。但是多個Redis命令無法保證原子性。我們可以采用lua腳本形式,將這些命令打包到一個腳本中,作為一個命令發(fā)送給Redis執(zhí)行,從而保證了原子性。
lua 是一個類似 JavaScript、Shell 等的解釋性語言,它可以完成 Redis 已有命令不支持的功能。用戶在編寫完 lua 腳本之后,將此腳本上傳至 Redis 服務端,服務端會返回一個標識碼代表此腳本。在實際執(zhí)行具體請求時,將數(shù)據(jù)和此標識碼發(fā)送至 Redis 即可。Redis 會和執(zhí)行普通命令一樣,采用單線程執(zhí)行此 lua 腳本和對應數(shù)據(jù)。
Lua 腳本執(zhí)行流程:
批量扣減是對單個扣減的循環(huán)調(diào)用,所以這里介紹的流程只講單次扣減的處理步驟。
首先根據(jù) 訂單明細id查詢扣減流水,是否已經(jīng)操作過,做冪等性校驗然后查詢sku的剩余庫存,并根據(jù) 下單購買數(shù)做校驗,只要有一個sku 數(shù)量不足,則返回失敗修改所有sku的緩存中的剩余庫存數(shù) 緩存中插入扣減流水記錄
當Redis扣減成功后,應用程序再將此次扣減異步化保存到數(shù)據(jù)庫中,持久化存儲,畢竟Redis只是臨時性存儲,有宕機風險,會丟失數(shù)據(jù)。
緩存方案利弊分析:
Redis緩存方案,借助了緩存的高性能,承載更高的并發(fā)。但是沒有數(shù)據(jù)庫的ACID特性,極端情況下,可能出現(xiàn)少賣情況為了避免 少賣情況發(fā)生,純緩存方案需要做大量的對賬、異常處理的設計,系統(tǒng)復雜度增加很多。純緩存方案適合一些高并發(fā)、大流量場景,但對數(shù)據(jù)準確度要求不是特別苛刻的業(yè)務場景。
風險:
上述Lua腳本把多條命令打包在一起,雖然保證了原子性,但不具備事務回滾特性。比如,庫存扣減成功了,此時Redis宕機,扣減流水并沒有插入成功,應用程序認為本次Redis調(diào)用是失敗的,前臺給用戶反饋錯誤提示,但是已經(jīng)扣減的數(shù)量不會回滾。當Redis故障修復后,再次啟動,此時恢復的數(shù)據(jù)已經(jīng)存在不一致了。需要結(jié)合Redis和數(shù)據(jù)庫做數(shù)據(jù)核對check,并結(jié)合扣減服務的日志,做數(shù)據(jù)的增量修復。
?? 基于分庫分表的扣減方案
上面提到的數(shù)據(jù)庫方式是基于單庫單表玩法,雖然借助ACID特性能保證數(shù)據(jù)的一致性,但是單臺mysql的并發(fā)能力有限,如何提升性能?
除了純緩存化方案外,我們還可以考慮將庫存表進行水平拆分,分攤洪峰壓力。

假如庫存表的QPS要求是1.6萬,經(jīng)過拆分成16張表后,如果數(shù)據(jù)分布均勻,每個物理表預計處理 1000 QPS,完全處于mysql單實例的承載范圍之內(nèi)。
另外拆分后,單表的數(shù)據(jù)量也會相應減少很多,假如分表前有一個億數(shù)據(jù),分表后每張表不到1千萬,索引查詢性能也會快很多。
注意:
同一次扣減業(yè)務,庫存扣減和插入流水要放在同一個分庫中,通過事務保證一致性,滿足同時成功或同時失敗。如果數(shù)據(jù)分布和業(yè)務請求足夠均勻,理論上經(jīng)過分庫分表設計后,整個系統(tǒng)的吞吐量將會是線性的增長,主要取決于分表實例的數(shù)量。
?? 其他扣減方案
還有其他的一些解決方案,這里只是提供一些思路,方案細節(jié)就不展開了
1、如果某個sku_id的庫存扣減過熱,單臺實例支撐不了(mysql官方測評:一般單行更新的QPS在500以內(nèi)),可以考慮將一個sku的大庫存拆分成N份,放在不同的庫中(也就是說所有子庫的庫存數(shù)總和才是一件sku的真實庫存),由于前臺的訪問流量非常大,按照均分原則,每個子庫分到的流量應該差不多。上層路由時只需要在sku_id后面拼接一個范圍內(nèi)的隨機數(shù),即可找到對應的子庫,有效減輕系統(tǒng)壓力。
2、單條sku庫存記錄更新過熱,也可以采用批量提交方式,將多次扣減累計計數(shù),集中成一次扣減,從而實現(xiàn)了將串行處理變成了批處理,也可以大大減輕數(shù)據(jù)庫壓力。
3、引入RocketMQ消息隊列,經(jīng)過前置校驗后,如果有剩余庫存,則把創(chuàng)建訂單的操作封裝成消息發(fā)送給MQ,訂單系統(tǒng)從RocketMQ中以特定的頻率消費,創(chuàng)建訂單,該方案有一定的延遲性。
碼字不易,請不要白嫖。如果對您的工作有幫助,請轉(zhuǎn)發(fā)分享,點個 “贊”