用Python批量下載文獻(xiàn),真香!
點擊上方“菜J學(xué)Python”,選擇“星標(biāo)”公眾號
超級無敵干貨,第一時間送達(dá)!!!
感分割線")

01
前言
說到Python其實應(yīng)該有很多人都看過一個廣告:某某同學(xué)能夠批量下載文獻(xiàn)。作為一個生物相關(guān)專業(yè)學(xué)生黨,我對此表示很好奇,于是在學(xué)了爬蟲之后對文獻(xiàn)網(wǎng)站進(jìn)行了嘗試,然后就有了這次的分享。在文章講解之前,咱們先來看看代碼運行效果:
02
目標(biāo)
對ncbi(美國國家生物信息中心)(emmm,沒錯,我就是生化環(huán)材“四大天坑”之首的學(xué)生)的PubMed文獻(xiàn)庫進(jìn)行爬取:
爬蟲思路如下:
1.對某個查詢詞進(jìn)行爬取,獲取搜索得到的結(jié)果數(shù)
2.爬取到文章的標(biāo)題以及它的doi號(“科技論文的身份證”)
3.根據(jù)doi號鏈接到sci-hub,下載文獻(xiàn)到本地,保存為doi號.pdf
03
實戰(zhàn)
接下來,讓我們開啟愉快的爬蟲之旅吧,go!
首先是需要的庫:
import?requests
from?lxml?import?etree
import?time
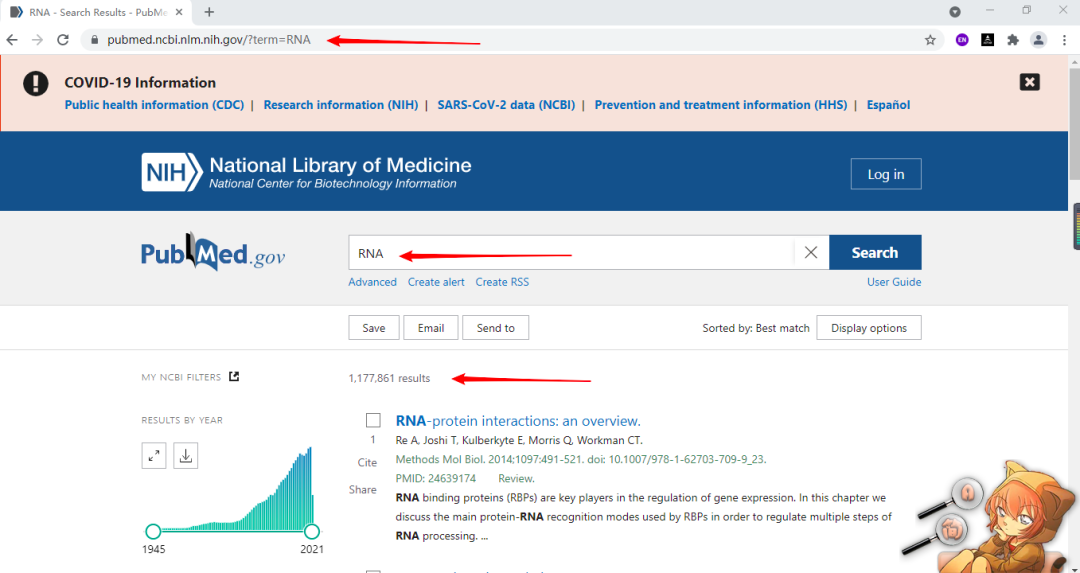
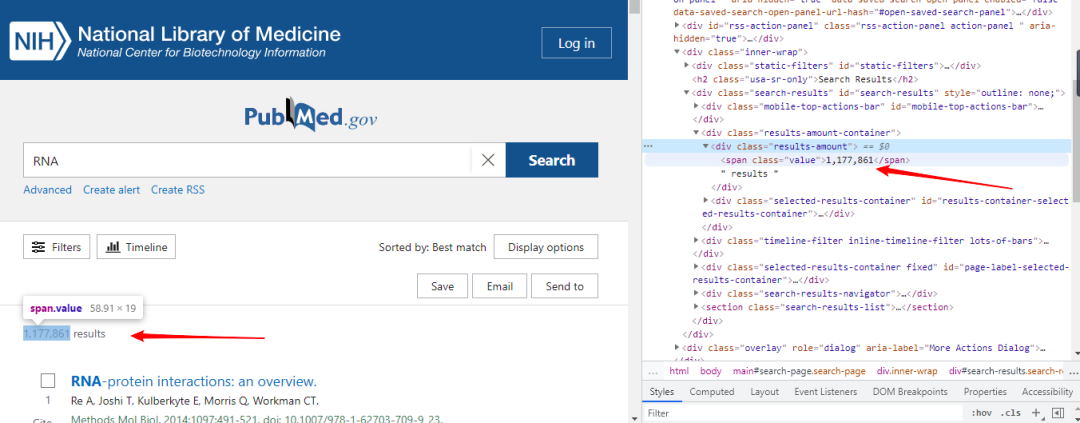
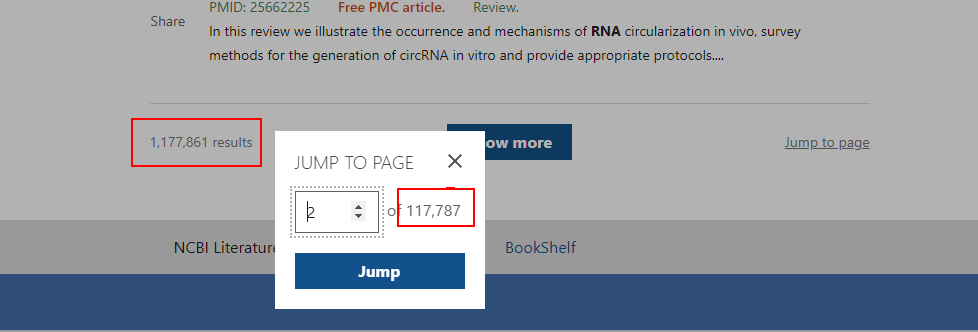
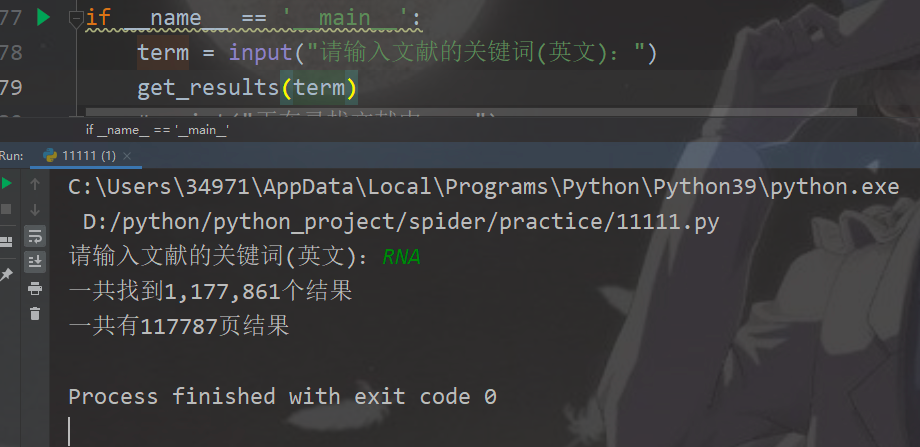
import?reok,第一部分的代碼:獲取查詢到的結(jié)果,可以看到term參數(shù)的值就是我們要查詢的詞(圖一),像以RNA為搜索詞一共查到1177861個結(jié)果,我們把這個部分爬下來(圖二),方便得知一共有多少的結(jié)果。而頁碼數(shù)(圖三),我們可知一頁有10個結(jié)果,頁碼數(shù)就是結(jié)果數(shù)除以10,多出來的結(jié)果不夠10個則自成一頁。
圖一
圖二
圖三
我們傳入一個參數(shù)term(需要查詢的詞),然后構(gòu)造url,這里的f "....{...}"是格式化輸出,類似于format方法: def?get_results(term):
????url?=?f'https://pubmed.ncbi.nlm.nih.gov/?term={term}'
????headers?=?{
????????"User-Agent":?"Mozilla/5.0?(Windows?NT?10.0;?Win64;?x64)?AppleWebKit/537.36?(KHTML,?like?Gecko)?Chrome/80.0.3987.163?Safari/537.36",
????}
????r?=?requests.get(url,?headers=headers)
????r.encoding?=?'utf-8'
????tree?=?etree.HTML(r.text)
????results?=?tree.xpath('//div[@class="results-amount"]/span/text()')
????if?len(results)?!=0:
????????new_results?=?str(results[0]).replace("\n","")
????????print(f"一共找到{new_results}個結(jié)果")
????????end_results?=?int(new_results.replace(",",""))#字符串中含有,號無法轉(zhuǎn)換成數(shù)字,我們用空來替代它
????????if?end_results?%?10?==?0:
????????????pages?=?end_results?/?10
????????else:
????????????pages?=?int(end_results/10)+1
????????print(f"一共有{str(pages)}頁結(jié)果")
????else:
????????print("沒有結(jié)果")
????????pages?=?0
????return?pages輸出結(jié)果如下: 第二部分我們將每一篇文章的鏈接爬下來,保存到列表里,傳入?yún)?shù)需要查詢的詞term以及需要爬取的頁碼數(shù)。
(ps:遇到的坑之一,由于數(shù)據(jù)很多,盡量不要幾百頁全部爬取,只是學(xué)習(xí)的話可以爬一兩頁試試,如果要爬幾百頁消耗時間太長)
函數(shù)代碼如下: def?get_links(term,pages):
????total_list?=?[]
????for?i?in?range(pages):
????????url?=?f'https://pubmed.ncbi.nlm.nih.gov/?term={term}&page={str(i+1)}'
????????headers?=?{
????????????"User-Agent":?"Mozilla/5.0?(Windows?NT?10.0;?Win64;?x64)?AppleWebKit/537.36?(KHTML,?like?Gecko)?Chrome/80.0.3987.163?Safari/537.36",
????????}
????????r?=?requests.get(url,headers=headers)
????????r.encoding='utf-8'
????????tree?=etree.HTML(r.text)
????????links?=?tree.xpath('//div[@class="docsum-content"]/a/@href')
????????for?link?in?links:
????????????#構(gòu)造單個文獻(xiàn)的鏈接
????????????new_link?=?'https://pubmed.ncbi.nlm.nih.gov'?+?link
????????????total_list.append(new_link)
????????time.sleep(3)
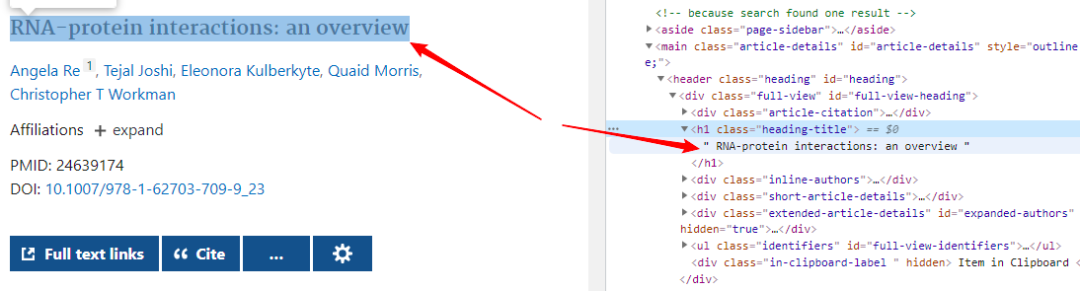
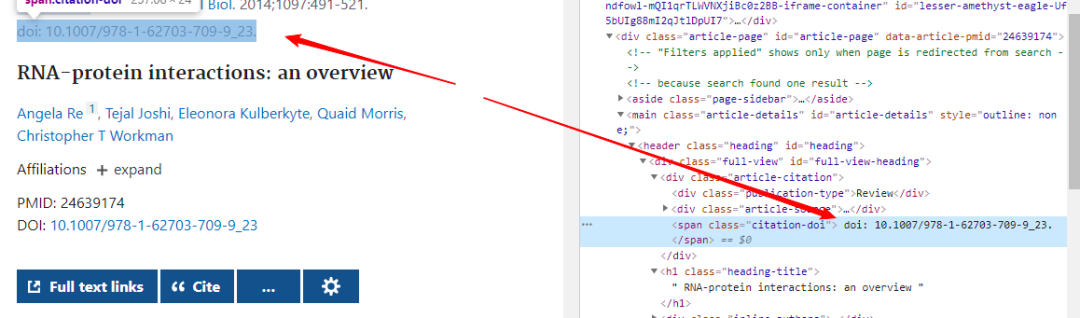
????return?total_list第三部分:遍歷列表里每一個鏈接到文獻(xiàn)詳情頁將文獻(xiàn)題目以及doi號取出,并將doi號進(jìn)行保存用以之后下載文獻(xiàn)使用,若一篇文獻(xiàn)沒有doi號則打印出無doi號:


這部分代碼如下:
def?get_message(total_list):
????doi_list?=?[]
????headers?=?{
????????"User-Agent":?"Mozilla/5.0?(Windows?NT?10.0;?Win64;?x64)?AppleWebKit/537.36?(KHTML,?like?Gecko)?Chrome/80.0.3987.163?Safari/537.36"
????}
????for?url?in?total_list:
????????r?=?requests.get(url,?headers=headers)
????????r.encoding?=?'utf-8'
????????tree?=?etree.HTML(r.text)
????????title?=?tree.xpath('//h1[@class="heading-title"]/text()')[0]
????????new_title?=?str(title).replace("\n",?"")
????????print(new_title[26:])
????????doi?=?tree.xpath('//span[@class="citation-doi"]/text()')
????????if?len(doi)?==?0:
????????????print("這篇文章沒有doi號")
????????else:
????????????new_dois?=?str(doi[0]).replace("?",?"")
????????????new_doi?=?new_dois[5:-2]
????????????doi_list.append(new_doi)
????????????print(f"這篇文章的doi號是:{new_doi}")
????return?doi_list
最后一部分就是下載了,相關(guān)專業(yè)的應(yīng)該知道下載文獻(xiàn)的一個網(wǎng)站叫sci-hub,這次我們就鏈接到這個網(wǎng)站進(jìn)行下載,將doi號輸入該網(wǎng)站,就會跳轉(zhuǎn)得到一個PDF,如圖:

分析網(wǎng)頁可以得到下載地址在這里:
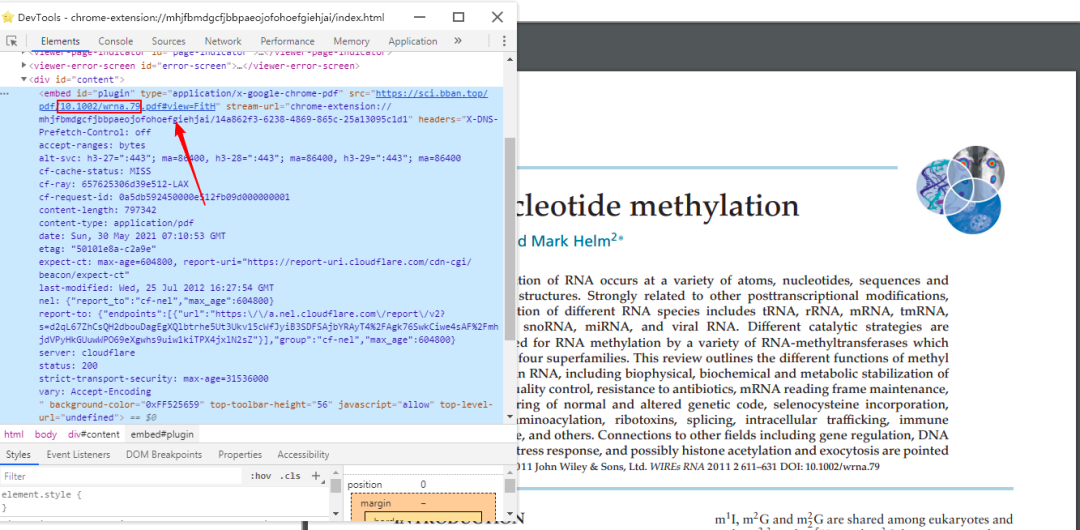
接下來就簡單了,我們直接上代碼,把它保存下來:
def?get_content(dois):
????for?doi?in?dois:
????????urls?=?f'https://sci.bban.top/pdf/{doi}.pdf#view=FitH'
????????headers?=?{
????????????"User-Agent":?"Mozilla/5.0?(Windows?NT?10.0;?Win64;?x64)?AppleWebKit/537.36?(KHTML,?like?Gecko)?Chrome/80.0.3987.163?Safari/537.36"
????????}
????????r?=?requests.get(urls,?headers=headers)
????????title?=?re.findall("(.*?)/",doi)
????????with?open(f"{title[0]}.pdf",'wb')as?f:
????????????f.write(r.content)
????????????time.sleep(2)
最后就是運行了,為了好看一點,可以多打印點文字。
if?__name__?==?'__main__':
????term?=?input("請輸入文獻(xiàn)的關(guān)鍵詞(英文):")
????print("正在尋找文獻(xiàn)中....")
????if?get_results(term)?!=?0:
????????page?=?int(input("請輸入下載的頁數(shù):"))
????????print("正在下載文獻(xiàn),注意只能下載含doi號的文獻(xiàn)")
????????get_content(get_message(get_links(term=term,pages=page)))
????????print("下載已完成")
????else:
????????print("對不起,沒有文獻(xiàn)可以下載")
04
運行
運行結(jié)果(因為時間原因只運行一頁來嘗試):
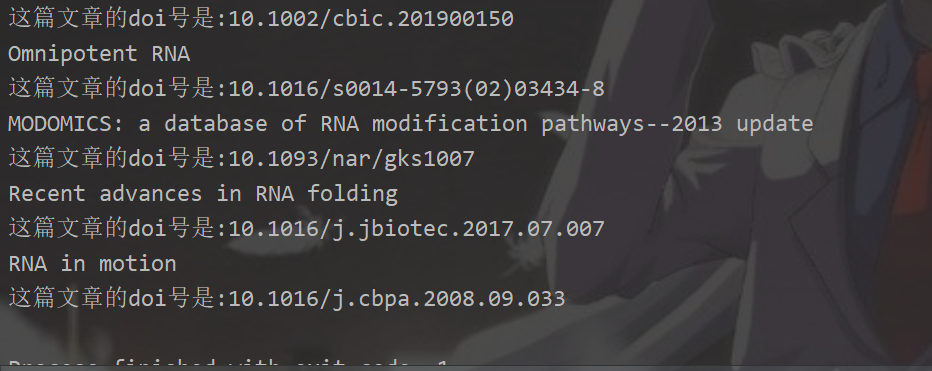

寫在最后,運行結(jié)果后發(fā)現(xiàn)也有一些PDF只有1k,發(fā)現(xiàn)出現(xiàn)此結(jié)果的原因可能如下:
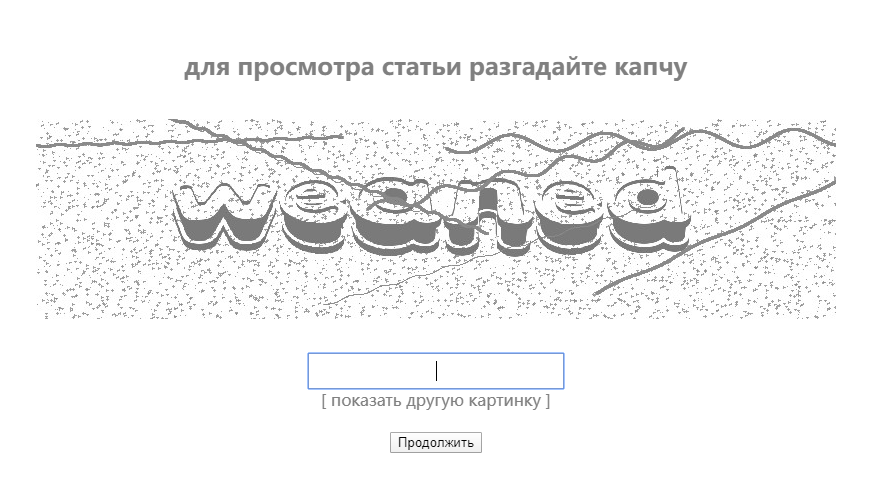
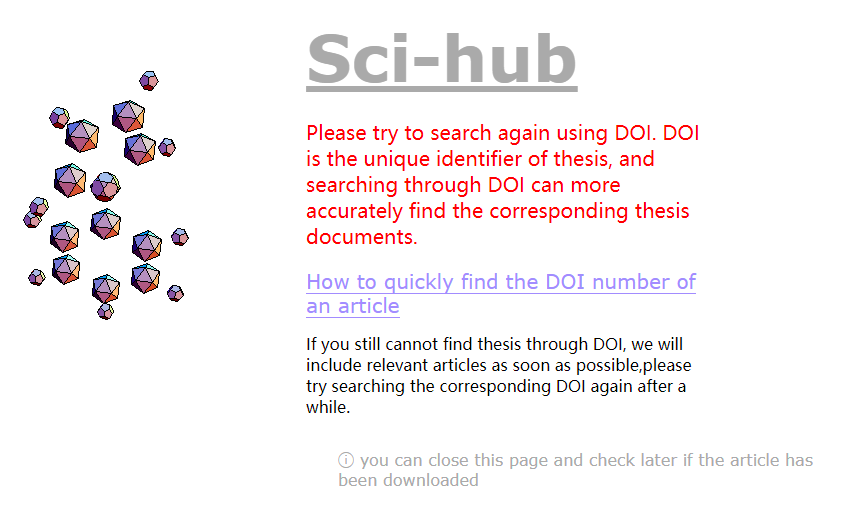
使用Python下載文獻(xiàn)也并不是非常快,代碼也需要持續(xù)優(yōu)化,寫這個案例的目的主要是鞏固一下自己的基礎(chǔ)知識,希望能和小伙伴們一起改進(jìn)代碼,繼續(xù)進(jìn)步!
05
源碼
關(guān)注「數(shù)據(jù)有道」公眾號,回復(fù)「有道15」領(lǐng)取本文源碼
既往專輯

 |
|
|
|
 |
|
|
|