
五行Python代碼輕松實現(xiàn)OCR文字識別
關(guān)注")
◆?◆?◆ ?◆?◆
今天周六,閑來無事打開百度搜索了一下——渣男語錄。
萬萬沒想到,百度文庫竟然不讓我復(fù)制這些語句。
這我不能忍!!!!我可是會Python的男孩紙~
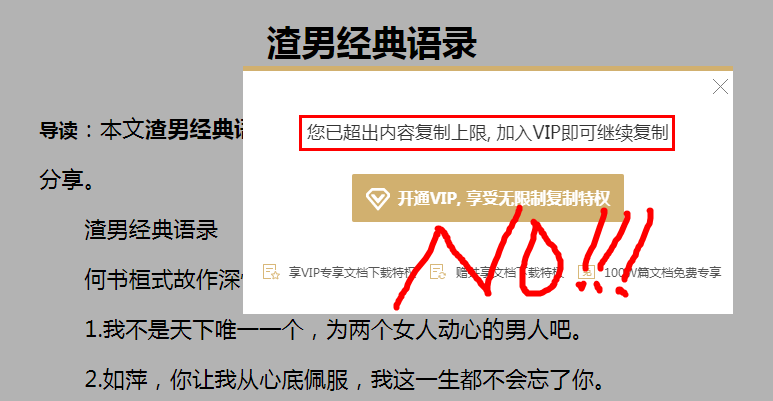
我可是嚴(yán)小樣兒啊!于是,我成功復(fù)制了渣男語錄!
今天,我就用五行Python代碼輕松教你實現(xiàn)OCR,秒變渣男~ 嘿嘿嘿
#?第一步:導(dǎo)包from?aip?import?Aipocr as ocr#?第二步:讀取with?open(path,'rb')?as?f:????img?=?f.read()# 第三步:調(diào)用cli?=?ocr(appId,?apiKey,?secretKey)#?第四步:識別rlt = cli.general(img)# 第五步:輸出for?line?in?rlt['words_result']:????print(line.get('words'))









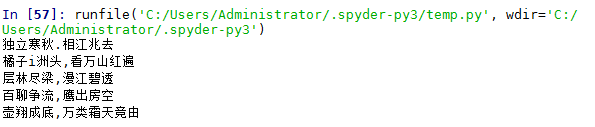
雖說可能些許有點瑕疵,但是如果是正式文件或者是楷體字,對于那些想要把圖片上的文字扒下來的需求已經(jīng)足夠了。我不會告訴你,我曾經(jīng)有一份工作真的需要把圖片的文字轉(zhuǎn)換成word文檔,那時候廢了老勁了~
為了方便其他人員使用,我們可以用pyinstaller庫進(jìn)行封裝生成exe可執(zhí)行文件。
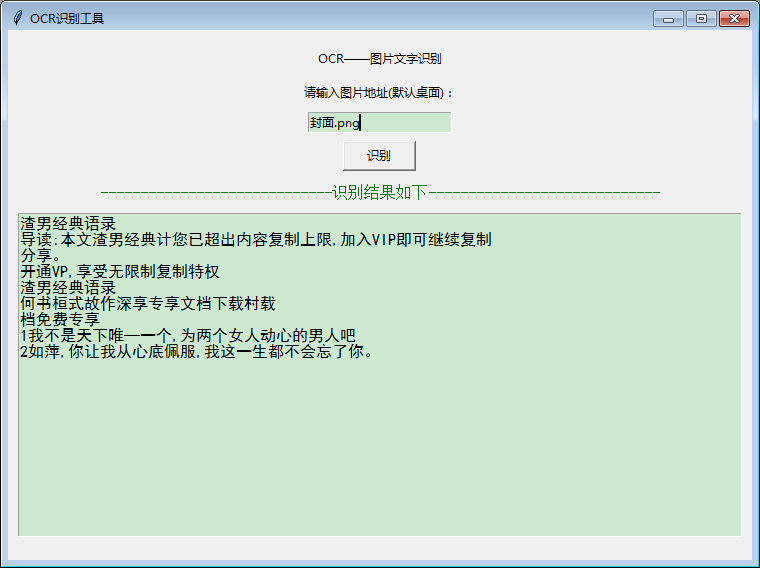
<以下內(nèi)容,點擊跳轉(zhuǎn)>

評論
圖片
表情