
神器CLIP是如何煉成的!
 點(diǎn)藍(lán)色字關(guān)注“機(jī)器學(xué)習(xí)算法工程師”
點(diǎn)藍(lán)色字關(guān)注“機(jī)器學(xué)習(xí)算法工程師”
設(shè)為星標(biāo),干貨直達(dá)!
2021年見證了vision transformer的大爆發(fā),隨著谷歌提出ViT之后,一大批的vision transformer的工作席卷計(jì)算機(jī)視覺任務(wù)。除了vision transformer,另外一個(gè)對(duì)計(jì)算機(jī)視覺影響比較大的工作就是Open AI在2021年1月份發(fā)布的DALL-E和CLIP,這兩個(gè)都屬于結(jié)合圖像和文本的多模態(tài)模型,其中DALL-E是基于文本來生成模型的模型,而CLIP是用文本作為監(jiān)督信號(hào)來訓(xùn)練可遷移的視覺模型,這兩個(gè)工作也像ViT一樣帶動(dòng)了一波新的研究高潮。這篇文章將首先介紹CLIP的原理以及如何用CLIP實(shí)現(xiàn)zero-shot分類,然后我們將討論CLIP背后的動(dòng)機(jī),最后文章會(huì)介紹CLIP的變種和其它的一些應(yīng)用場(chǎng)景。
CLIP是如何工作的
CLIP的英文全稱是Contrastive Language-Image Pre-training,即一種基于對(duì)比文本-圖像對(duì)的預(yù)訓(xùn)練方法或者模型。CLIP是一種基于對(duì)比學(xué)習(xí)的多模態(tài)模型,與CV中的一些對(duì)比學(xué)習(xí)方法如moco和simclr不同的是,CLIP的訓(xùn)練數(shù)據(jù)是文本-圖像對(duì):一張圖像和它對(duì)應(yīng)的文本描述,這里希望通過對(duì)比學(xué)習(xí),模型能夠?qū)W習(xí)到文本-圖像對(duì)的匹配關(guān)系。如下圖所示,CLIP包括兩個(gè)模型:Text Encoder和Image Encoder,其中Text Encoder用來提取文本的特征,可以采用NLP中常用的text transformer模型;而Image Encoder用來提取圖像的特征,可以采用常用CNN模型或者vision transformer。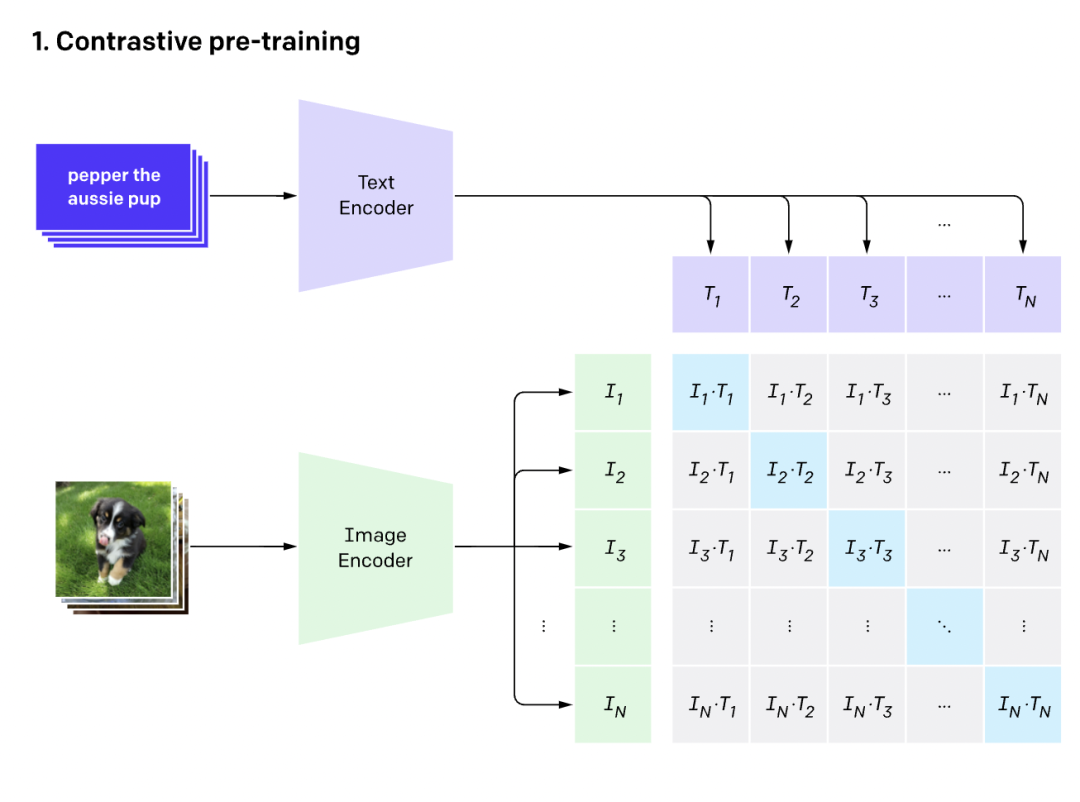 這里對(duì)提取的文本特征和圖像特征進(jìn)行對(duì)比學(xué)習(xí)。對(duì)于一個(gè)包含個(gè)文本-圖像對(duì)的訓(xùn)練batch,將個(gè)文本特征和個(gè)圖像特征兩兩組合,CLIP模型會(huì)預(yù)測(cè)出個(gè)可能的文本-圖像對(duì)的相似度,這里的相似度直接計(jì)算文本特征和圖像特征的余弦相似性(cosine similarity),即上圖所示的矩陣。這里共有個(gè)正樣本,即真正屬于一對(duì)的文本和圖像(矩陣中的對(duì)角線元素),而剩余的個(gè)文本-圖像對(duì)為負(fù)樣本,那么CLIP的訓(xùn)練目標(biāo)就是最大個(gè)正樣本的相似度,同時(shí)最小化個(gè)負(fù)樣本的相似度,對(duì)應(yīng)的偽代碼實(shí)現(xiàn)如下所示:
這里對(duì)提取的文本特征和圖像特征進(jìn)行對(duì)比學(xué)習(xí)。對(duì)于一個(gè)包含個(gè)文本-圖像對(duì)的訓(xùn)練batch,將個(gè)文本特征和個(gè)圖像特征兩兩組合,CLIP模型會(huì)預(yù)測(cè)出個(gè)可能的文本-圖像對(duì)的相似度,這里的相似度直接計(jì)算文本特征和圖像特征的余弦相似性(cosine similarity),即上圖所示的矩陣。這里共有個(gè)正樣本,即真正屬于一對(duì)的文本和圖像(矩陣中的對(duì)角線元素),而剩余的個(gè)文本-圖像對(duì)為負(fù)樣本,那么CLIP的訓(xùn)練目標(biāo)就是最大個(gè)正樣本的相似度,同時(shí)最小化個(gè)負(fù)樣本的相似度,對(duì)應(yīng)的偽代碼實(shí)現(xiàn)如下所示:
#?image_encoder?-?ResNet?or?Vision?Transformer
#?text_encoder?-?CBOW?or?Text?Transformer
#?I[n,?h,?w,?c]?-?minibatch?of?aligned?images
#?T[n,?l]?-?minibatch?of?aligned?texts
#?W_i[d_i,?d_e]?-?learned?proj?of?image?to?embed
#?W_t[d_t,?d_e]?-?learned?proj?of?text?to?embed
#?t?-?learned?temperature?parameter
#?分別提取圖像特征和文本特征
I_f?=?image_encoder(I)?#[n,?d_i]
T_f?=?text_encoder(T)?#[n,?d_t]
#?對(duì)兩個(gè)特征進(jìn)行線性投射,得到相同維度的特征,并進(jìn)行l(wèi)2歸一化
I_e?=?l2_normalize(np.dot(I_f,?W_i),?axis=1)
T_e?=?l2_normalize(np.dot(T_f,?W_t),?axis=1)
#?計(jì)算縮放的余弦相似度:[n, n]
logits?=?np.dot(I_e,?T_e.T)?*?np.exp(t)
#?對(duì)稱的對(duì)比學(xué)習(xí)損失:等價(jià)于N個(gè)類別的cross_entropy_loss
labels?=?np.arange(n)?#?對(duì)角線元素的labels
loss_i?=?cross_entropy_loss(logits,?labels,?axis=0)
loss_t?=?cross_entropy_loss(logits,?labels,?axis=1)
loss?=?(loss_i?+?loss_t)/2
為了訓(xùn)練CLIP,OpenAI從互聯(lián)網(wǎng)收集了共4個(gè)億的文本-圖像對(duì),論文稱之為WebImageText,如果按照文本的單詞量,它和訓(xùn)練GPT-2的WebText規(guī)模類似,如果從數(shù)量上對(duì)比的話,它還比谷歌的JFT-300M數(shù)據(jù)集多一個(gè)億,所以說這是一個(gè)很大規(guī)模的數(shù)據(jù)集。CLIP雖然是多模態(tài)模型,但它主要是用來訓(xùn)練可遷移的視覺模型。論文中Text Encoder固定選擇一個(gè)包含63M參數(shù)的text transformer模型,而Image Encoder采用了兩種的不同的架構(gòu),一是常用的CNN架構(gòu)ResNet,二是基于transformer的ViT,其中ResNet包含5個(gè)不同大小的模型:ResNet50,ResNet101,RN50x4,RN50x16和RNx64(后面三個(gè)模型是按照EfficientNet縮放規(guī)則對(duì)ResNet分別增大4x,16x和64x得到),而ViT選擇3個(gè)不同大小的模型:ViT-B/32,ViT-B/16和ViT-L/14。所有的模型都訓(xùn)練32個(gè)epochs,采用AdamW優(yōu)化器,而且訓(xùn)練過程采用了一個(gè)較大的batch size:32768。由于數(shù)據(jù)量較大,最大的ResNet模型RN50x64需要在592個(gè)V100卡上訓(xùn)練18天,而最大ViT模型ViT-L/14需要在256張V100卡上訓(xùn)練12天,可見要訓(xùn)練CLIP需要耗費(fèi)多大的資源。對(duì)于ViT-L/14,還在336的分辨率下額外finetune了一個(gè)epoch來增強(qiáng)性能,論文發(fā)現(xiàn)這個(gè)模型效果最好,記為ViT-L/14@336,論文中進(jìn)行對(duì)比實(shí)驗(yàn)的CLIP模型也采用這個(gè)。
如何用CLIP實(shí)現(xiàn)zero-shot分類
上面我們介紹了CLIP的原理,可以看到訓(xùn)練后的CLIP其實(shí)是兩個(gè)模型,除了視覺模型外還有一個(gè)文本模型,那么如何對(duì)預(yù)訓(xùn)練好的視覺模型進(jìn)行遷移呢?與CV中常用的先預(yù)訓(xùn)練然后微調(diào)不同,CLIP可以直接實(shí)現(xiàn)zero-shot的圖像分類,即不需要任何訓(xùn)練數(shù)據(jù),就能在某個(gè)具體下游任務(wù)上實(shí)現(xiàn)分類,這也是CLIP亮點(diǎn)和強(qiáng)大之處。用CLIP實(shí)現(xiàn)zero-shot分類很簡(jiǎn)單,只需要簡(jiǎn)單的兩步:
根據(jù)任務(wù)的分類標(biāo)簽構(gòu)建每個(gè)類別的描述文本: A photo of {label},然后將這些文本送入Text Encoder得到對(duì)應(yīng)的文本特征,如果類別數(shù)目為,那么將得到個(gè)文本特征;將要預(yù)測(cè)的圖像送入Image Encoder得到圖像特征,然后與個(gè)文本特征計(jì)算縮放的余弦相似度(和訓(xùn)練過程一致),然后選擇相似度最大的文本對(duì)應(yīng)的類別作為圖像分類預(yù)測(cè)結(jié)果,進(jìn)一步地,可以將這些相似度看成logits,送入softmax可以進(jìn)一步得到每個(gè)類別的預(yù)測(cè)概率。
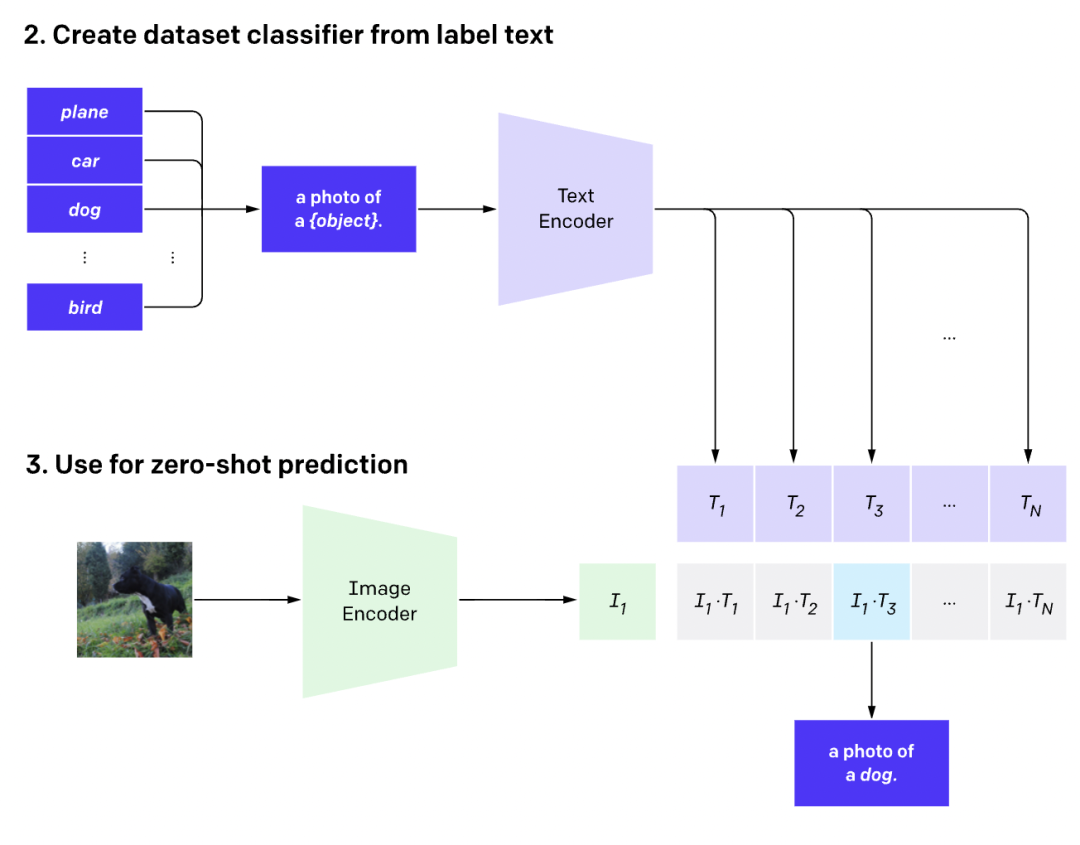
可以看到,我們是利用CLIP的多模態(tài)特性為具體的任務(wù)構(gòu)建了動(dòng)態(tài)的分類器,其中Text Encoder提取的文本特征可以看成分類器的weights,而Image Encoder提取的圖像特征是分類器的輸入。這里我們給出了一個(gè)基于CLIP的一個(gè)實(shí)例(參考官方notebook),這里任務(wù)共有6個(gè)類別:"dog", "cat", "bird", "person", "mushroom", "cup",首先我們創(chuàng)建文本描述,然后提取文本特征:
#?首先生成每個(gè)類別的文本描述
labels?=?["dog",?"cat",?"bird",?"person",?"mushroom",?"cup"]
text_descriptions?=?[f"A?photo?of?a?{label}"?for?label?in?labels]
text_tokens?=?clip.tokenize(text_descriptions).cuda()
#?提取文本特征
with?torch.no_grad():
????text_features?=?model.encode_text(text_tokens).float()
????text_features?/=?text_features.norm(dim=-1,?keepdim=True)
然后我們讀取要預(yù)測(cè)的圖像,輸入Image Encoder提取圖像特征,并計(jì)算與文本特征的余弦相似度:
#?讀取圖像
original_images?=?[]
images?=?[]
texts?=?[]
for?label?in?labels:
????image_file?=?os.path.join("images",?label+".jpg")
????name?=?os.path.basename(image_file).split('.')[0]
????image?=?Image.open(image_file).convert("RGB")
????original_images.append(image)
????images.append(preprocess(image))
????texts.append(name)
image_input?=?torch.tensor(np.stack(images)).cuda()
#?提取圖像特征??
with?torch.no_grad():
????image_features?=?model.encode_image(image_input).float()
????image_features?/=?image_features.norm(dim=-1,?keepdim=True)
#?計(jì)算余弦相似度(未縮放)
similarity?=?text_features.cpu().numpy()?@?image_features.cpu().numpy().T
相似度如下所示,可以看到對(duì)于要預(yù)測(cè)的6個(gè)圖像,按照最大相似度,其均能匹配到正確的文本標(biāo)簽: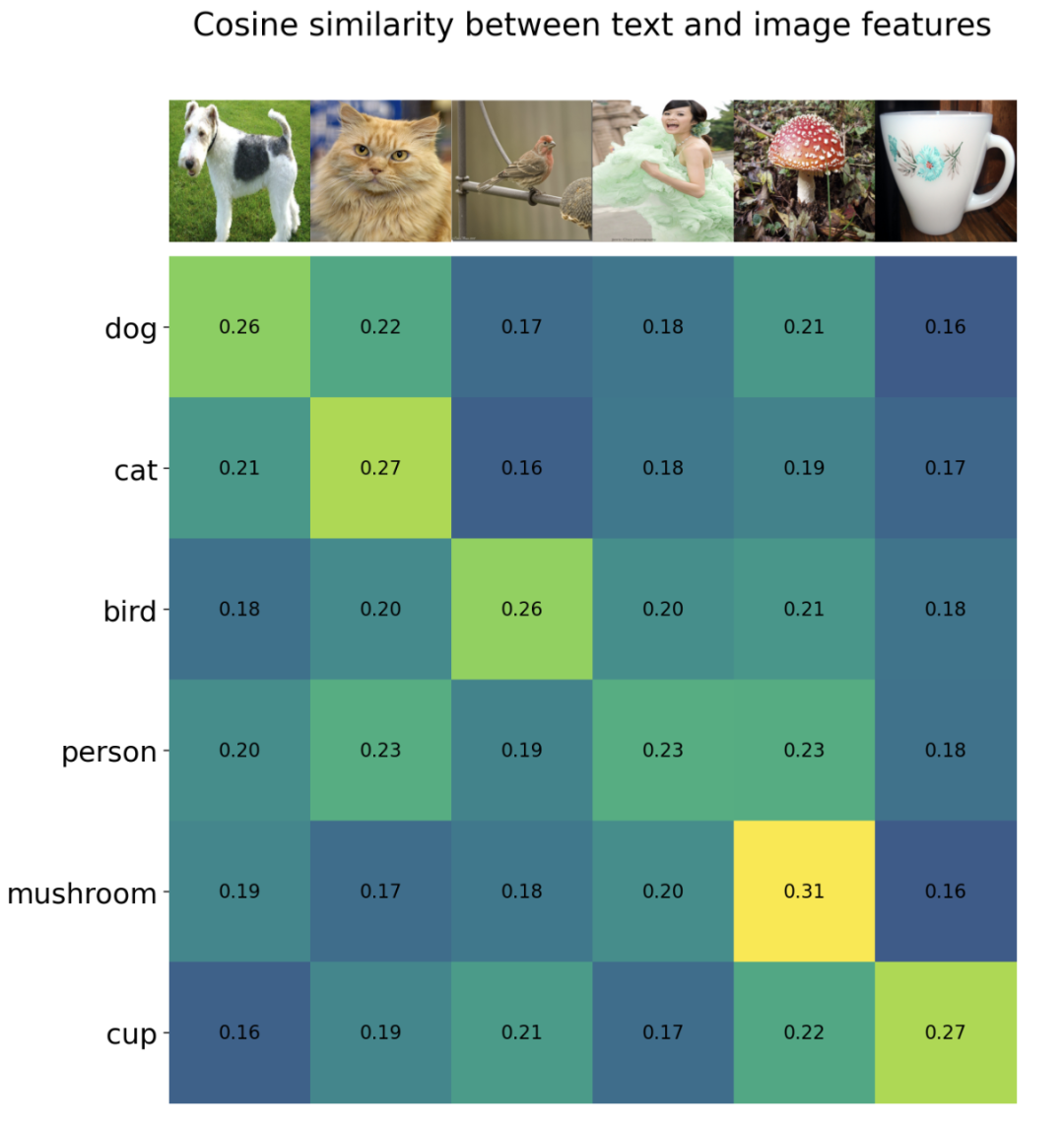 進(jìn)一步地,我們也可以對(duì)得到的余弦相似度計(jì)算softmax,得到每個(gè)預(yù)測(cè)類別的概率值,注意這里要對(duì)相似度進(jìn)行縮放:
進(jìn)一步地,我們也可以對(duì)得到的余弦相似度計(jì)算softmax,得到每個(gè)預(yù)測(cè)類別的概率值,注意這里要對(duì)相似度進(jìn)行縮放:
logit_scale?=?np.exp(model.logit_scale.data.item())
text_probs?=?(logit_scale?*?image_features?@?text_features.T).softmax(dim=-1)
top_probs,?top_labels?=?text_probs.cpu().topk(5,?dim=-1)
得到的預(yù)測(cè)概率如下所示,可以看到6個(gè)圖像,CLIP模型均能夠以絕對(duì)的置信度給出正確的分類結(jié)果:
 使用CLIP進(jìn)行zero-shot分類,另外一個(gè)比較重要的地方是文本描述的生成,上面的例子我們采用
使用CLIP進(jìn)行zero-shot分類,另外一個(gè)比較重要的地方是文本描述的生成,上面的例子我們采用A photo of {label},但其實(shí)也有其它選擇,比如我們直接用類別標(biāo)簽,這其實(shí)屬于最近NLP領(lǐng)域比較火的一個(gè)研究:prompt learning或者prompt engineering,具體可以見這篇綜述論文:Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing,簡(jiǎn)單來說,prompt learning的核心是通過構(gòu)建合適prompt(提示)來使預(yù)訓(xùn)練模型能夠直接應(yīng)用到下游任務(wù),這和之前的預(yù)訓(xùn)練+微調(diào)屬于不同的范式。論文也說了,如果我們直接采用類別標(biāo)簽作為文本描述,那么很多文本就是一個(gè)單詞,缺少具體的上下文,而且也和CLIP的訓(xùn)練數(shù)據(jù)不太一致,效果上會(huì)不如采用A photo of {label}(ImageNet數(shù)據(jù)集上可以提升1.3%)。論文也實(shí)驗(yàn)了采用80個(gè)不同的prompt來進(jìn)行集成,發(fā)現(xiàn)在ImageNet數(shù)據(jù)集上能帶來3.5%的提升,具體見CLIP公開的notebook。下圖對(duì)比了基于ResNet的CLIP模型直接采用類別名與進(jìn)行prompt engineering和ensembling的效果對(duì)比:
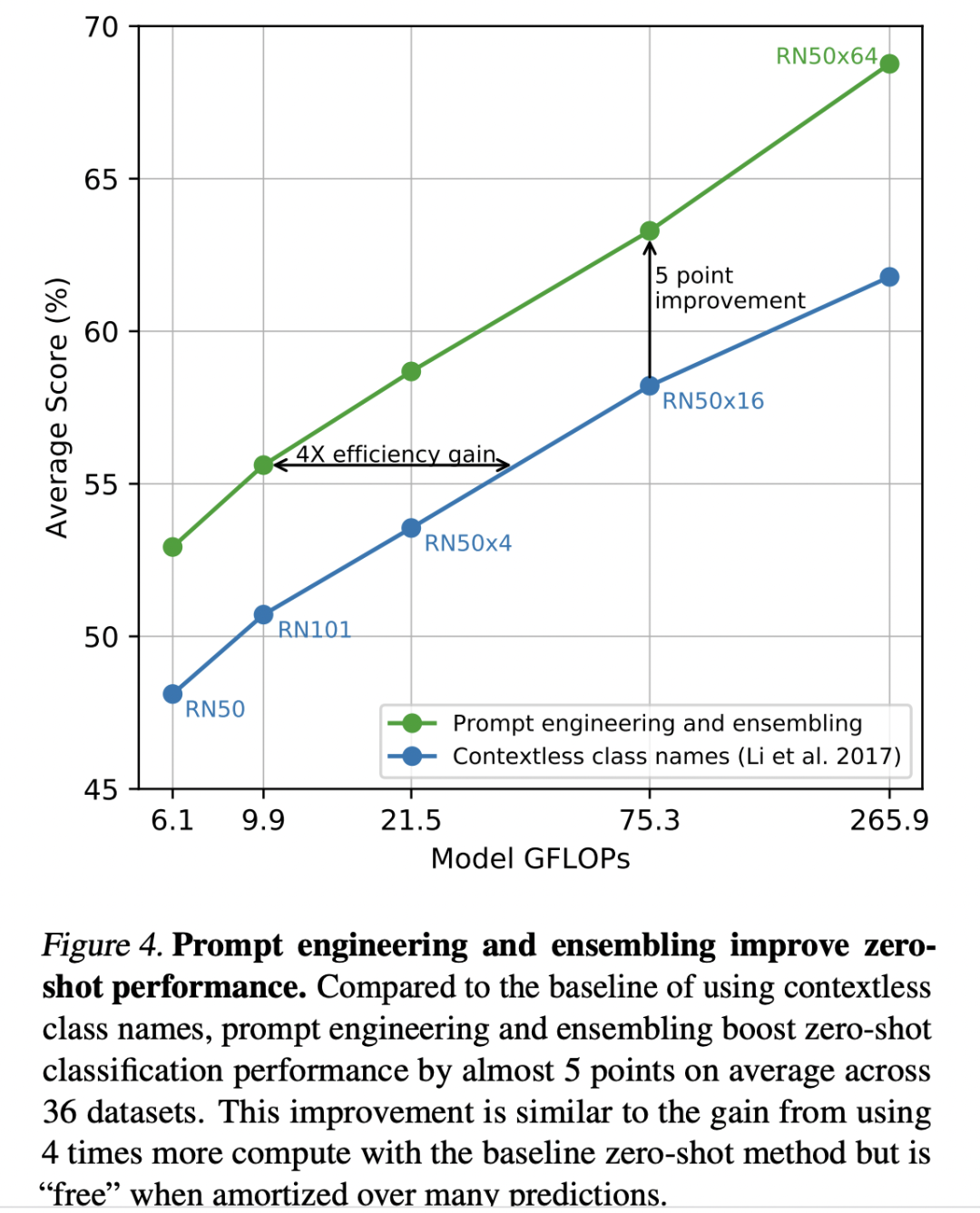 上面我們介紹了如何用CLIP實(shí)現(xiàn)zero-shot分類,下面將簡(jiǎn)單介紹CLIP與其它方法的效果對(duì)比,這個(gè)也是論文中篇幅最多的內(nèi)容。首先是CLIP和17年的一篇工作Learning Visual N-Grams from Web Data的在3個(gè)分類數(shù)據(jù)集上zero-shot效果對(duì)比,如下表所示,可以看到CLIP模型在效果上遠(yuǎn)遠(yuǎn)超過之前的模型,其中在ImageNet數(shù)據(jù)集可以達(dá)到76.2,這和全監(jiān)督的ResNet50效果相當(dāng),不用任何訓(xùn)練數(shù)據(jù)就能達(dá)到這個(gè)效果是相當(dāng)驚艷的。
上面我們介紹了如何用CLIP實(shí)現(xiàn)zero-shot分類,下面將簡(jiǎn)單介紹CLIP與其它方法的效果對(duì)比,這個(gè)也是論文中篇幅最多的內(nèi)容。首先是CLIP和17年的一篇工作Learning Visual N-Grams from Web Data的在3個(gè)分類數(shù)據(jù)集上zero-shot效果對(duì)比,如下表所示,可以看到CLIP模型在效果上遠(yuǎn)遠(yuǎn)超過之前的模型,其中在ImageNet數(shù)據(jù)集可以達(dá)到76.2,這和全監(jiān)督的ResNet50效果相當(dāng),不用任何訓(xùn)練數(shù)據(jù)就能達(dá)到這個(gè)效果是相當(dāng)驚艷的。
更進(jìn)一步地,論文還對(duì)比了zero-shot CLIP和ResNet50 linear probing(ImageNet數(shù)據(jù)上預(yù)訓(xùn)練,在加上線性分類層進(jìn)行finetune)在27個(gè)數(shù)據(jù)集上表現(xiàn),如下圖所示,其中在16個(gè)數(shù)據(jù)集上CLIP可以超過ResNet50。但是在一些特別的,復(fù)雜的或者抽象的數(shù)據(jù)集上CLIP表現(xiàn)較差,比如衛(wèi)星圖像分類,淋巴結(jié)轉(zhuǎn)移檢測(cè),在合成場(chǎng)景中計(jì)數(shù)等,CLIP的效果不如全監(jiān)督的ResNet50,這說明CLIP并不是萬能的,還是有改進(jìn)的空間。如果認(rèn)真看下圖的話,CLIP表現(xiàn)較差的竟然還有MNIST數(shù)據(jù)集,分類準(zhǔn)確度只有88%,這是不可思議的,因?yàn)檫@個(gè)任務(wù)太簡(jiǎn)單了,通過對(duì)CLIP訓(xùn)練數(shù)據(jù)進(jìn)行分析,作者發(fā)現(xiàn)4億的訓(xùn)練數(shù)據(jù)中基本上沒有和MNIST比較相似的數(shù)據(jù),所以這對(duì)CLIP來說就屬于域外數(shù)據(jù)了,表現(xiàn)較差就比較容易理解了。這也表明:CLIP依然無法解決域外泛化這個(gè)深度學(xué)習(xí)難題。
 除了zero-shot對(duì)比,論文還對(duì)比few-shot性能,即只用少量的樣本來微調(diào)模型,這里對(duì)比了3個(gè)模型:在ImageNet21K上訓(xùn)練的BiT-M ResNet-152x2,基于SimCLRv2訓(xùn)練的ResNet50,以及有監(jiān)督訓(xùn)練的ResNet50。可以看到CLIP的zero-shot和最好的模型(BiT-M)在16-shot下的性能相當(dāng),而CLIP在16-shot下效果有進(jìn)一步的提升。另外一個(gè)比較有意思的結(jié)果是:雖然CLIP在few-shot實(shí)驗(yàn)中隨著樣本量增加性能有提升,但是1-shot和2-shot性能比zero-shot還差,這個(gè)作者認(rèn)為主要是CLIP的訓(xùn)練和常規(guī)的有監(jiān)督訓(xùn)練存在一定的差異造成的。
除了zero-shot對(duì)比,論文還對(duì)比few-shot性能,即只用少量的樣本來微調(diào)模型,這里對(duì)比了3個(gè)模型:在ImageNet21K上訓(xùn)練的BiT-M ResNet-152x2,基于SimCLRv2訓(xùn)練的ResNet50,以及有監(jiān)督訓(xùn)練的ResNet50。可以看到CLIP的zero-shot和最好的模型(BiT-M)在16-shot下的性能相當(dāng),而CLIP在16-shot下效果有進(jìn)一步的提升。另外一個(gè)比較有意思的結(jié)果是:雖然CLIP在few-shot實(shí)驗(yàn)中隨著樣本量增加性能有提升,但是1-shot和2-shot性能比zero-shot還差,這個(gè)作者認(rèn)為主要是CLIP的訓(xùn)練和常規(guī)的有監(jiān)督訓(xùn)練存在一定的差異造成的。
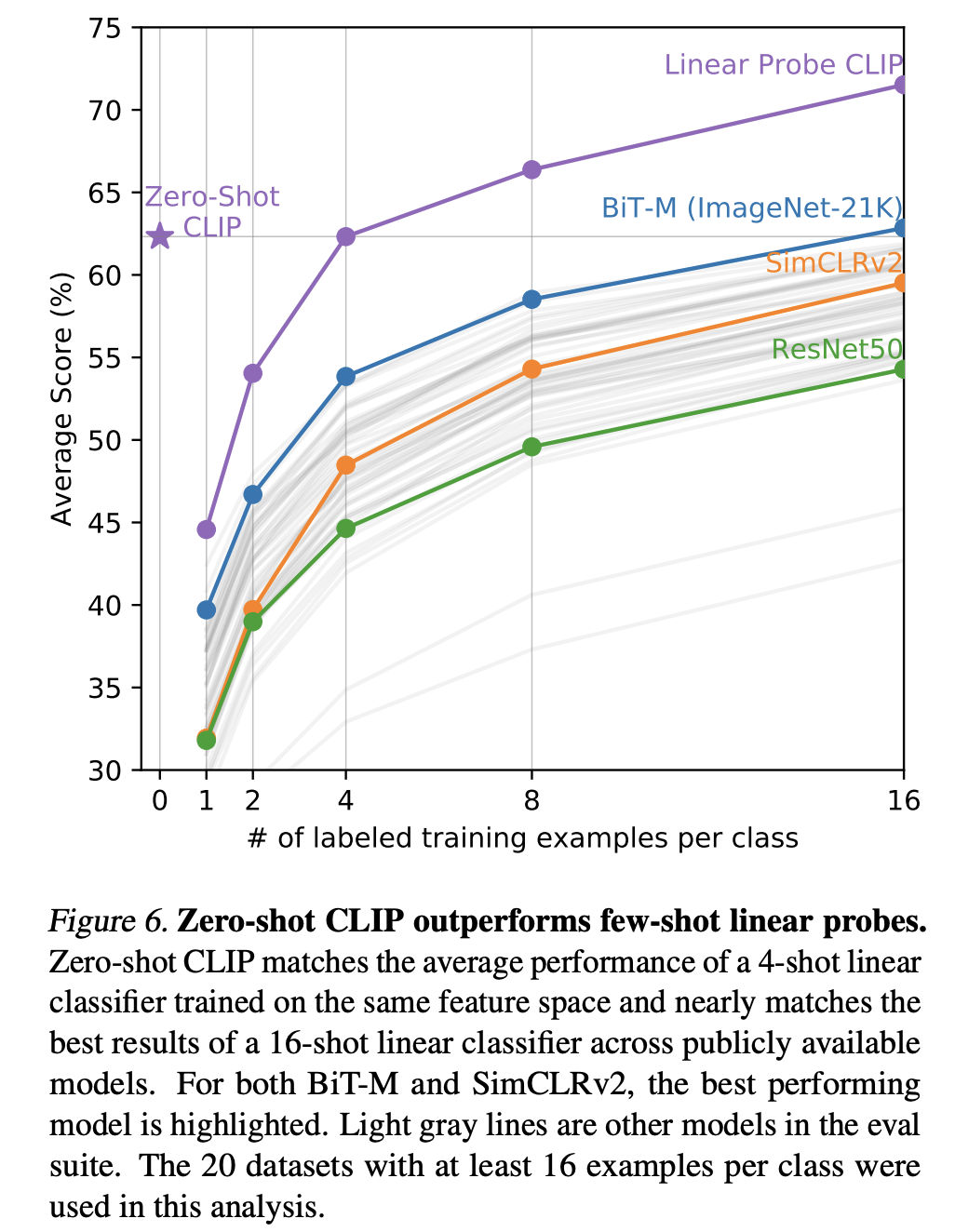 除此之外,論文還進(jìn)行了表征學(xué)習(xí)(representation Learning)實(shí)驗(yàn),即自監(jiān)督學(xué)習(xí)中常用的linear probe:用訓(xùn)練好的模型先提取特征,然后用一個(gè)線性分類器來有監(jiān)督訓(xùn)練。下圖為不同模型在27個(gè)數(shù)據(jù)集上的average linear probe score對(duì)比,可以看到CLIP模型在性能上超過其它模型,而且計(jì)算更高效:
除此之外,論文還進(jìn)行了表征學(xué)習(xí)(representation Learning)實(shí)驗(yàn),即自監(jiān)督學(xué)習(xí)中常用的linear probe:用訓(xùn)練好的模型先提取特征,然后用一個(gè)線性分類器來有監(jiān)督訓(xùn)練。下圖為不同模型在27個(gè)數(shù)據(jù)集上的average linear probe score對(duì)比,可以看到CLIP模型在性能上超過其它模型,而且計(jì)算更高效: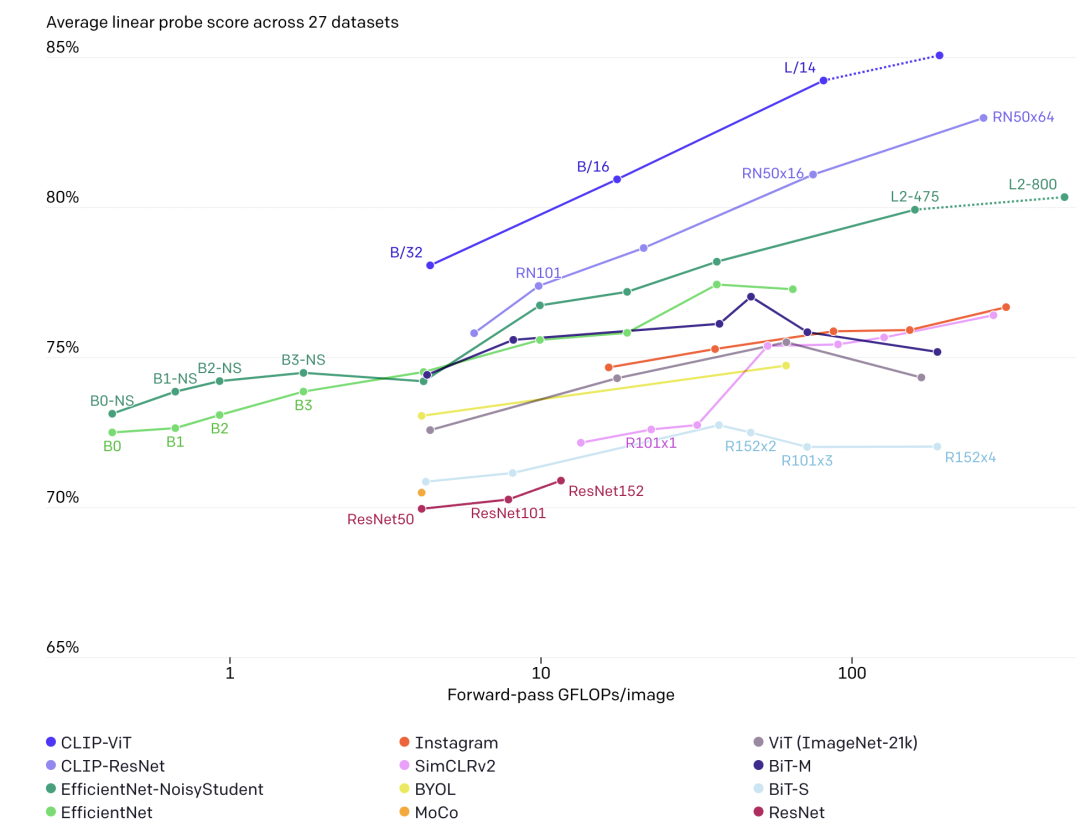
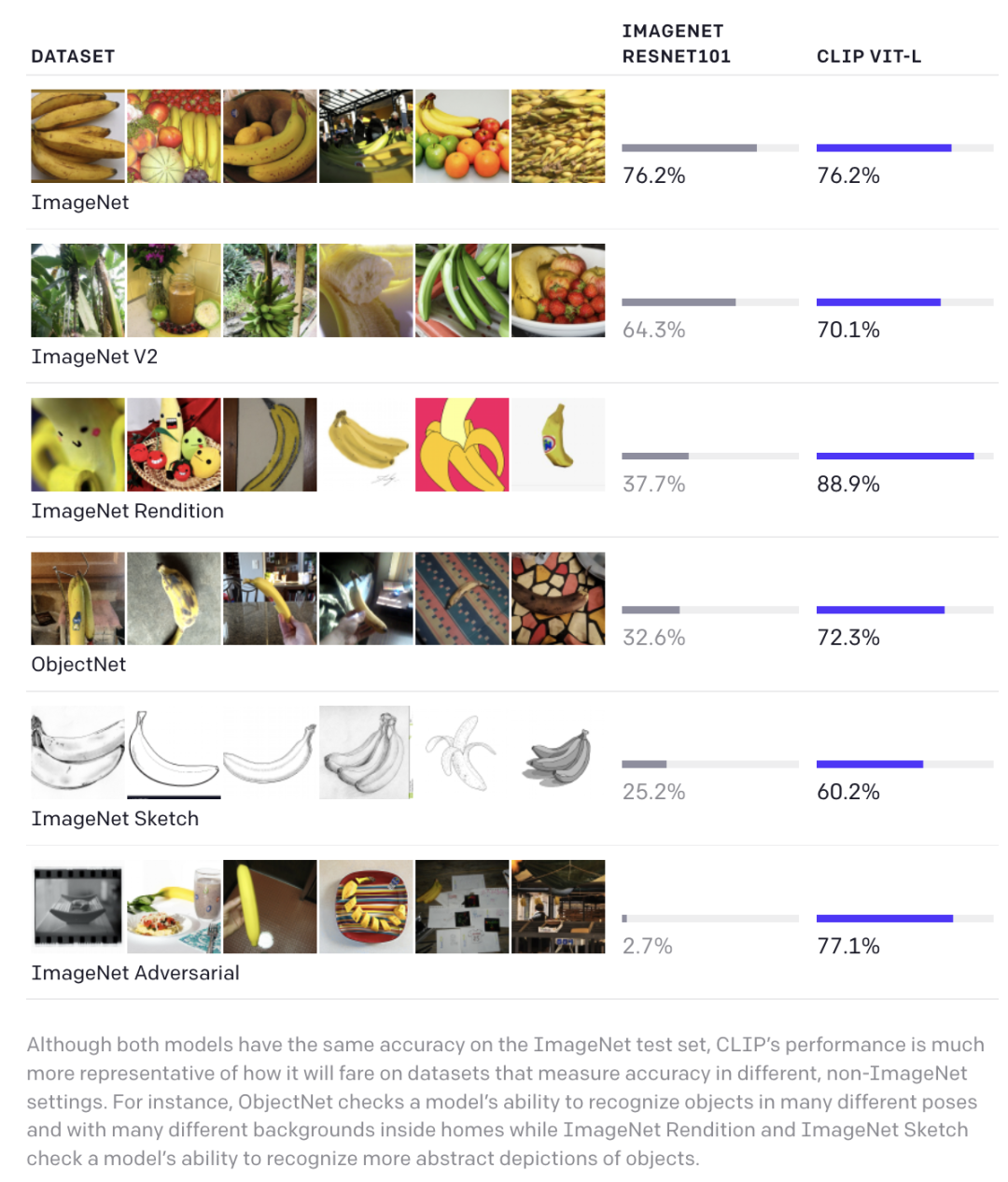
另外,論文還發(fā)現(xiàn)CLIP在自然分布漂移上表現(xiàn)更魯棒,比如CLIP和基于ImageNet上有監(jiān)督訓(xùn)練的ResNet101在ImageNet驗(yàn)證集都能達(dá)到76.2%,但是在ImageNetV2數(shù)據(jù)集上,CLIP要超過ResNet101。在另外的4個(gè)分布漂移的數(shù)據(jù)集上,ResNet101性能下降得比較厲害,但是CLIP能依然保持較大的準(zhǔn)確度,比如在ImageNet-A數(shù)據(jù)集上,ResNet101性能只有2.7%,而CLIP能達(dá)到77.1%。
 CLIP能實(shí)現(xiàn)這么好的zero-shot性能,大家很可能質(zhì)疑CLIP的訓(xùn)練數(shù)據(jù)集可能包含一些測(cè)試數(shù)據(jù)集中的樣例,即所謂的數(shù)據(jù)泄漏。關(guān)于這點(diǎn),論文也采用一個(gè)重復(fù)檢測(cè)器對(duì)評(píng)測(cè)的數(shù)據(jù)集重合做了檢查,發(fā)現(xiàn)重合率的中位數(shù)為2.2%,而平均值在3.2%,去重前后大部分?jǐn)?shù)據(jù)集的性能沒有太大的變化,如下所示:
CLIP能實(shí)現(xiàn)這么好的zero-shot性能,大家很可能質(zhì)疑CLIP的訓(xùn)練數(shù)據(jù)集可能包含一些測(cè)試數(shù)據(jù)集中的樣例,即所謂的數(shù)據(jù)泄漏。關(guān)于這點(diǎn),論文也采用一個(gè)重復(fù)檢測(cè)器對(duì)評(píng)測(cè)的數(shù)據(jù)集重合做了檢查,發(fā)現(xiàn)重合率的中位數(shù)為2.2%,而平均值在3.2%,去重前后大部分?jǐn)?shù)據(jù)集的性能沒有太大的變化,如下所示: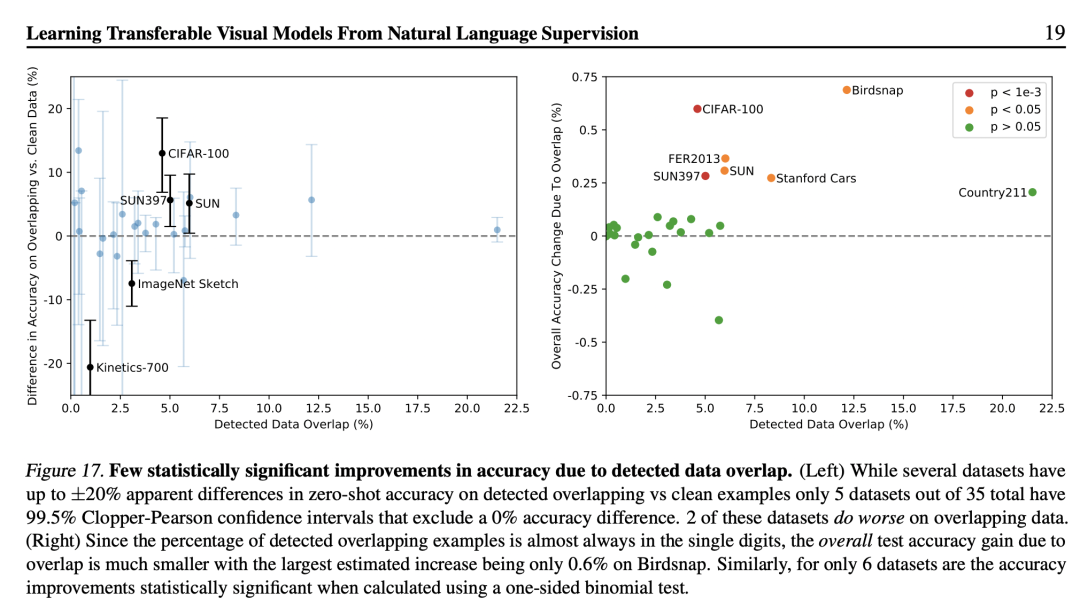
論文的最后也對(duì)CLIP的局限性做了討論,這里簡(jiǎn)單總結(jié)其中比較重要的幾點(diǎn):
CLIP的zero-shot性能雖然和有監(jiān)督的ResNet50相當(dāng),但是還不是SOTA,作者估計(jì)要達(dá)到SOTA的效果,CLIP還需要增加1000x的計(jì)算量,這是難以想象的; CLIP的zero-shot在某些數(shù)據(jù)集上表現(xiàn)較差,如細(xì)粒度分類,抽象任務(wù)等; CLIP在自然分布漂移上表現(xiàn)魯棒,但是依然存在域外泛化問題,即如果測(cè)試數(shù)據(jù)集的分布和訓(xùn)練集相差較大,CLIP會(huì)表現(xiàn)較差; CLIP并沒有解決深度學(xué)習(xí)的數(shù)據(jù)效率低下難題,訓(xùn)練CLIP需要大量的數(shù)據(jù);
為什么是CLIP
前面介紹了CLIP的原理和應(yīng)用,這里我們?cè)倩剡^頭來看另外一個(gè)問題:為什么是CLIP,即CLIP這篇工作的motivation。在計(jì)算機(jī)視覺領(lǐng)域,最常采用的遷移學(xué)習(xí)方式就是先在一個(gè)較大規(guī)模的數(shù)據(jù)集如ImageNet上預(yù)訓(xùn)練,然后在具體的下游任務(wù)上再進(jìn)行微調(diào)。這里的預(yù)訓(xùn)練是基于有監(jiān)督訓(xùn)練的,需要大量的數(shù)據(jù)標(biāo)注,因此成本較高。近年來,出現(xiàn)了一些基于自監(jiān)督的方法,這包括基于對(duì)比學(xué)習(xí)的方法如MoCo和SimCLR,和基于圖像掩碼的方法如MAE和BeiT,自監(jiān)督方法的好處是不再需要標(biāo)注。但是無論是有監(jiān)督還是自監(jiān)督方法,它們?cè)谶w移到下游任務(wù)時(shí),還是需要進(jìn)行有監(jiān)督微調(diào),而無法實(shí)現(xiàn)zero-shot。對(duì)于有監(jiān)督模型,由于它們?cè)陬A(yù)訓(xùn)練數(shù)據(jù)集上采用固定類別數(shù)的分類器,所以在新的數(shù)據(jù)集上需要定義新的分類器來重新訓(xùn)練。對(duì)于自監(jiān)督模型,代理任務(wù)往往是輔助來進(jìn)行表征學(xué)習(xí),在遷移到其它數(shù)據(jù)集時(shí)也需要加上新的分類器來進(jìn)行有監(jiān)督訓(xùn)練。但是NLP領(lǐng)域,基于自回歸或者語言掩碼的預(yù)訓(xùn)練方法已經(jīng)取得相對(duì)成熟,而且預(yù)訓(xùn)練模型很容易直接zero-shot遷移到下游任務(wù),比如OpenAI的GPT-3。這種差異一方面是由于文本和圖像屬于兩個(gè)完全不同的模態(tài),另外一個(gè)原因就是NLP模型可以采用從互聯(lián)網(wǎng)上收集的大量文本。那么問題來了:能不能基于互聯(lián)網(wǎng)上的大量文本來預(yù)訓(xùn)練視覺模型?
那么其實(shí)之前已經(jīng)有一些工作研究用文本來作為監(jiān)督信號(hào)來訓(xùn)練視覺模型,比如16年的工作Learning Visual Features from Large Weakly Supervised Data將這轉(zhuǎn)化成一個(gè)多標(biāo)簽分類任務(wù)來預(yù)測(cè)圖像對(duì)應(yīng)的文本的bag of words;17年的工作Learning Visual N-Grams from Web Data進(jìn)一步擴(kuò)展了這個(gè)方法來預(yù)測(cè)n-grams。最近的一些工作采用新的模型架構(gòu)和預(yù)訓(xùn)練方法來從文本學(xué)習(xí)視覺特征,比如VirTex基于transformer的語言模型,ICMLM基于語言掩碼的方法,ConVIRT基于對(duì)比學(xué)習(xí)的方法。整體來看,這方面的工作不是太多,這主要是因?yàn)檫@些方法難以實(shí)現(xiàn)較高的性能,比如17年的那篇工作只在ImageNet上實(shí)現(xiàn)了11.5%的zero-shot性能,這遠(yuǎn)遠(yuǎn)低于ImageNet上的SOTA。另外,還有另外的是一個(gè)方向,就是基于文本弱監(jiān)督來提升性能,比如谷歌的BiT和ViT基于JFT-300M數(shù)據(jù)集來預(yù)訓(xùn)練模型在ImageNet上取得SOTA,JFT-300M數(shù)據(jù)集是谷歌從互聯(lián)網(wǎng)上收集的,通過一些自動(dòng)化的手段來將web text來轉(zhuǎn)化成18291個(gè)類別,但是存在一定的噪音。雖然谷歌基于JFT-300M數(shù)據(jù)集取得了較好的結(jié)果,但是這些模型依然采用固定類別的softmax分類器進(jìn)行預(yù)訓(xùn)練,這大大限制了它的遷移能力和擴(kuò)展性。
作者認(rèn)為谷歌的弱監(jiān)督方法和之前的方法的一個(gè)重要的區(qū)別在于規(guī)模,或者說算力和數(shù)據(jù)的規(guī)模不同。JFT-300M數(shù)據(jù)量達(dá)到了上億級(jí)別,而且谷歌用了強(qiáng)大的算力來進(jìn)行預(yù)訓(xùn)練。而VirTex,ICMLM和ConVIRT只在10萬級(jí)別的數(shù)據(jù)上訓(xùn)練了幾天。為了彌補(bǔ)數(shù)據(jù)上的差異,OpenAI從網(wǎng)上收集了4億的數(shù)據(jù)來實(shí)驗(yàn)。但是新的問題來了:采用什么樣的方法來訓(xùn)練。OpenAI首先嘗試了VirTex模型,即聯(lián)合訓(xùn)練一個(gè)CNN和文本transformer來預(yù)測(cè)圖像的文本(image caption),但是發(fā)現(xiàn)這種方法的訓(xùn)練效率(用ImageNet數(shù)據(jù)集上的zero-shot性能來評(píng)估)還不如直接預(yù)測(cè)bag of words,如下圖所示,兩者的訓(xùn)練效率能相差3倍。如果進(jìn)一步采用ConVIRT,即基于對(duì)比學(xué)習(xí)的方法,訓(xùn)練效率可以進(jìn)一步提升4倍。由于訓(xùn)練數(shù)據(jù)量和模型計(jì)算量較大,訓(xùn)練效率成為一個(gè)至關(guān)重要的因素。這就是作者最終選擇對(duì)比學(xué)習(xí)的方法來訓(xùn)練的原因。之所出現(xiàn)這個(gè)差異,這不難理解,訓(xùn)練數(shù)據(jù)所包含的文本-圖像對(duì)是從互聯(lián)網(wǎng)收集來的,它們存在一定的噪音,就是說文本和圖像可能并不完全匹配,這個(gè)時(shí)候適當(dāng)?shù)慕档陀?xùn)練目標(biāo),反而能取得更好的收斂。而從任務(wù)難度來看:Transformer Language Model > Bag of Words Prediction > Bag of Words Contrastive (CLIP)。
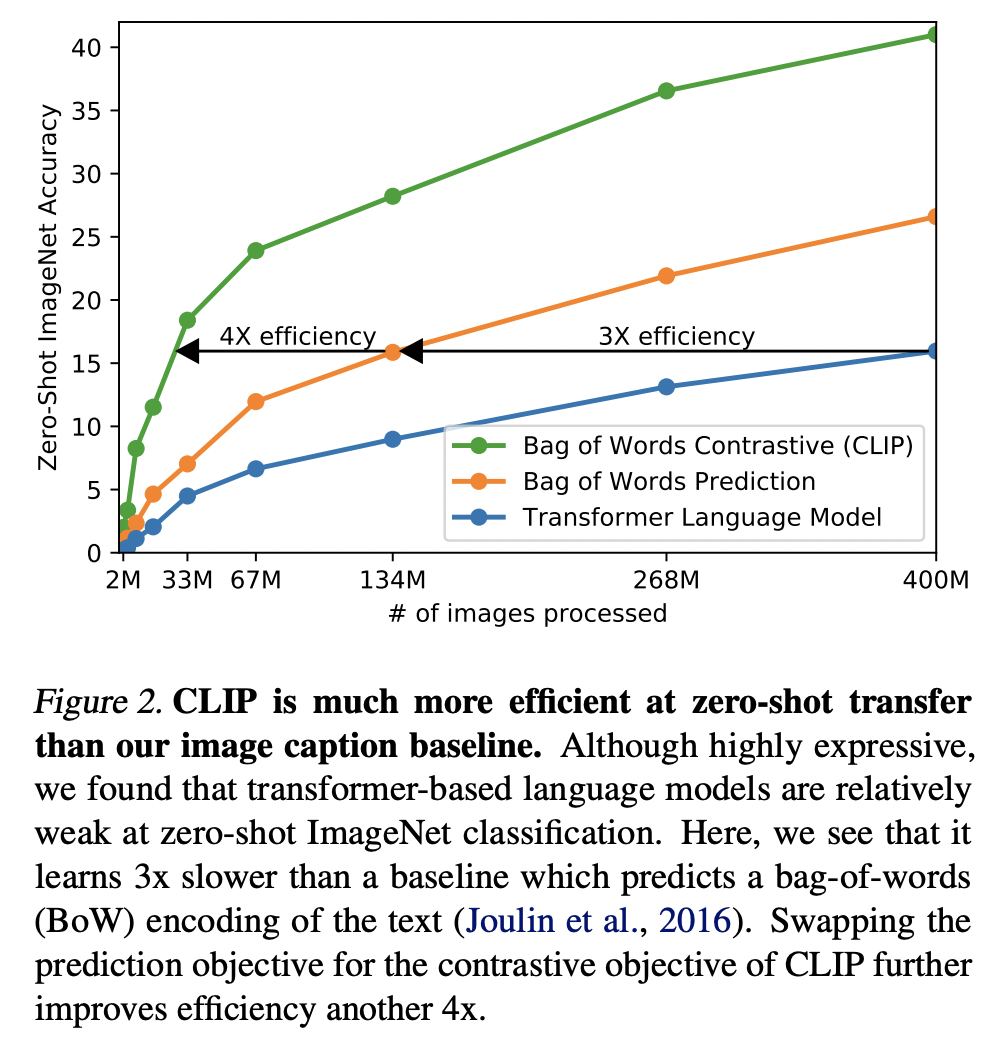 從本質(zhì)上來講,CLIP其實(shí)并沒有太大的創(chuàng)新,它只是將ConVIRT方法進(jìn)行簡(jiǎn)化,并采用更大規(guī)模的文本-圖像對(duì)數(shù)據(jù)集來訓(xùn)練。
從本質(zhì)上來講,CLIP其實(shí)并沒有太大的創(chuàng)新,它只是將ConVIRT方法進(jìn)行簡(jiǎn)化,并采用更大規(guī)模的文本-圖像對(duì)數(shù)據(jù)集來訓(xùn)練。
在論文的最后,作者也談到了由于訓(xùn)練效率的制約,他們采用了對(duì)比學(xué)習(xí)的方法,但是他們依然想做的是直接用圖像生成文本,這個(gè)如果能成功,那么就和DALL-E這個(gè)工作形成閉環(huán)了:文本 -> 圖像 -> 文本。而且基于生成式訓(xùn)練出來的模型,同樣可以實(shí)現(xiàn)zero-shot分類,我們可以通過預(yù)測(cè)句子中的單詞(標(biāo)簽)來實(shí)現(xiàn):A photo of [?]。
CLIP還可以做什么
雖然論文中只對(duì)用CLIP進(jìn)行zero-shot分類做了實(shí)驗(yàn),但其實(shí)CLIP的應(yīng)用價(jià)值遠(yuǎn)不止此,CLIP之后出現(xiàn)了很多基于CLIP的應(yīng)用研究,這里我們列出一些應(yīng)用場(chǎng)景
zero-shot檢測(cè)
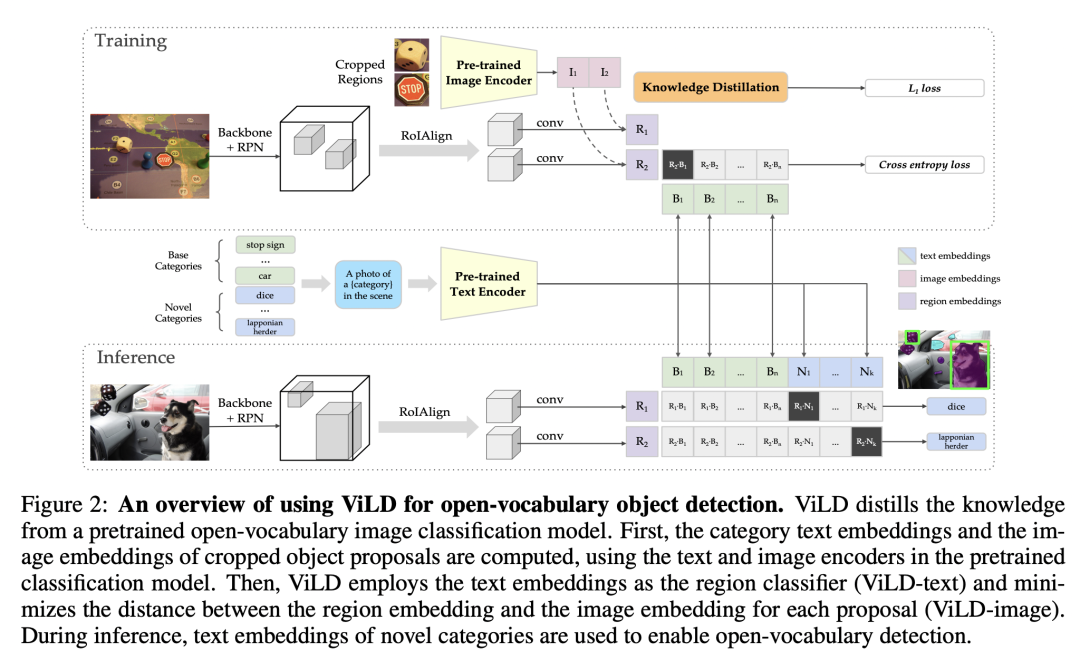
CLIP可以應(yīng)用在目標(biāo)檢測(cè)任務(wù)上,實(shí)現(xiàn)zero-shot檢測(cè),即檢測(cè)訓(xùn)練數(shù)據(jù)集沒有包含的類別,比如谷歌提出的ViLD基于CLIP實(shí)現(xiàn)了開放詞匯的物體檢測(cè),其主體架構(gòu)如下所示,其基本思路和zero-shot分類相似,只不過這里是用文本特征和ROI特征來計(jì)算相似度。
 Meta AI的最新工作Detic可以檢測(cè)2000個(gè)類,背后也用到了CLIP:
Meta AI的最新工作Detic可以檢測(cè)2000個(gè)類,背后也用到了CLIP: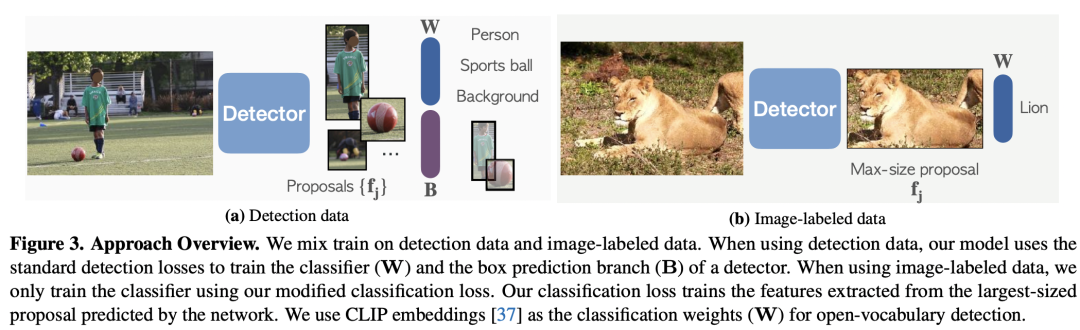
圖像檢索
基于文本來搜索圖像是CLIP最能直接實(shí)現(xiàn)的一個(gè)應(yīng)用,其實(shí)CLIP也是作為DALL-E的排序模型,即從生成的圖像中選擇和文本相關(guān)性較高的。
視頻理解
CLIP是基于文本-圖像對(duì)來做的,但是它可以擴(kuò)展到文本-視頻,比如VideoCLIP就是將CLIP應(yīng)用在視頻領(lǐng)域來實(shí)現(xiàn)一些zero-shot視頻理解任務(wù)。
圖像編輯
CLIP可以用在指導(dǎo)圖像編輯任務(wù)上,HairCLIP這篇工作用CLIP來定制化修改發(fā)型: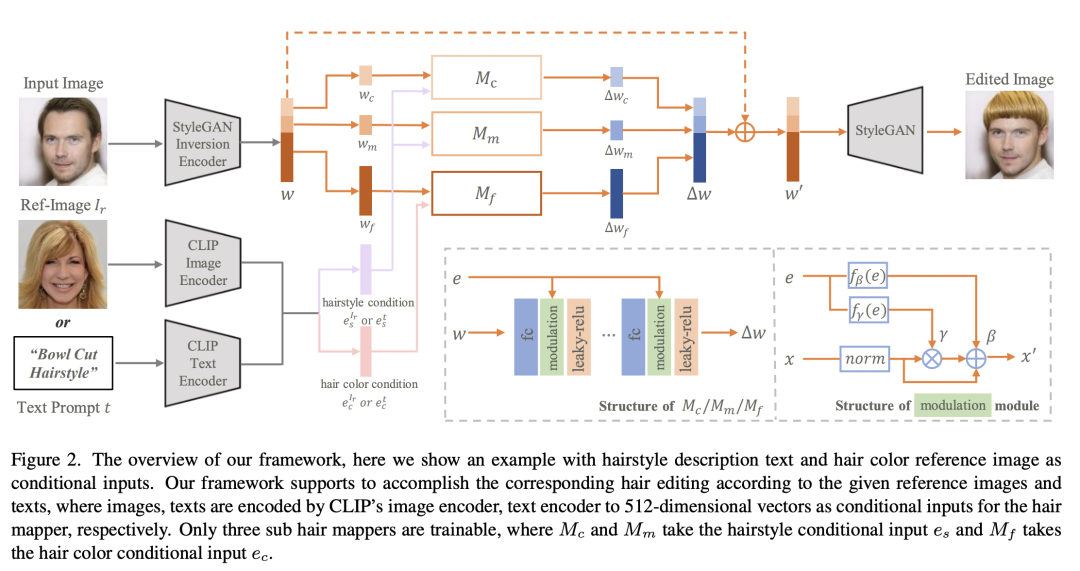
圖像生成
CLIP還可以應(yīng)用在圖像生成上,比如StyleCLIP這篇工作用CLIP實(shí)現(xiàn)了文本引導(dǎo)的StyleGAN: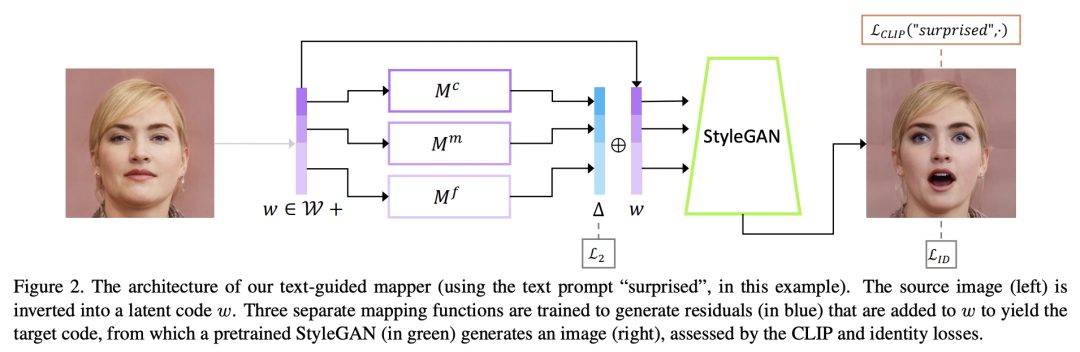 CLIP-GEN這篇工作基于CLIP來訓(xùn)練文本生成圖像模型,訓(xùn)練無需直接采用任何文本數(shù)據(jù):
CLIP-GEN這篇工作基于CLIP來訓(xùn)練文本生成圖像模型,訓(xùn)練無需直接采用任何文本數(shù)據(jù):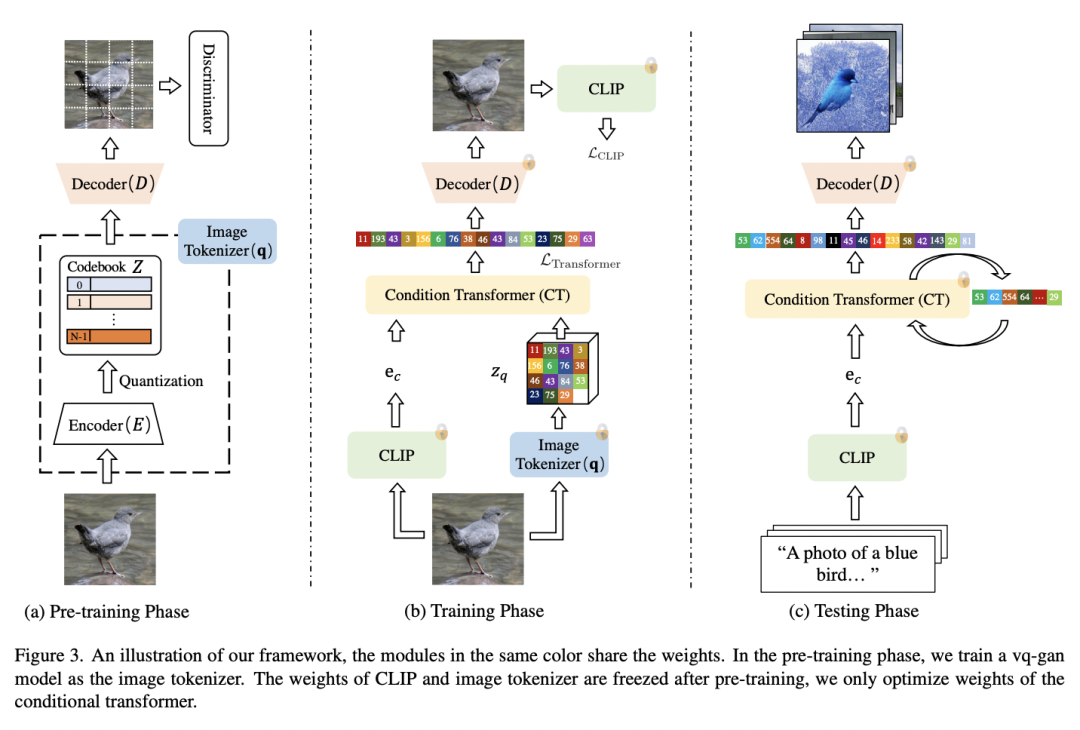
自監(jiān)督學(xué)習(xí)
最近華為的工作MVP更是采用CLIP來進(jìn)行視覺自監(jiān)督訓(xùn)練: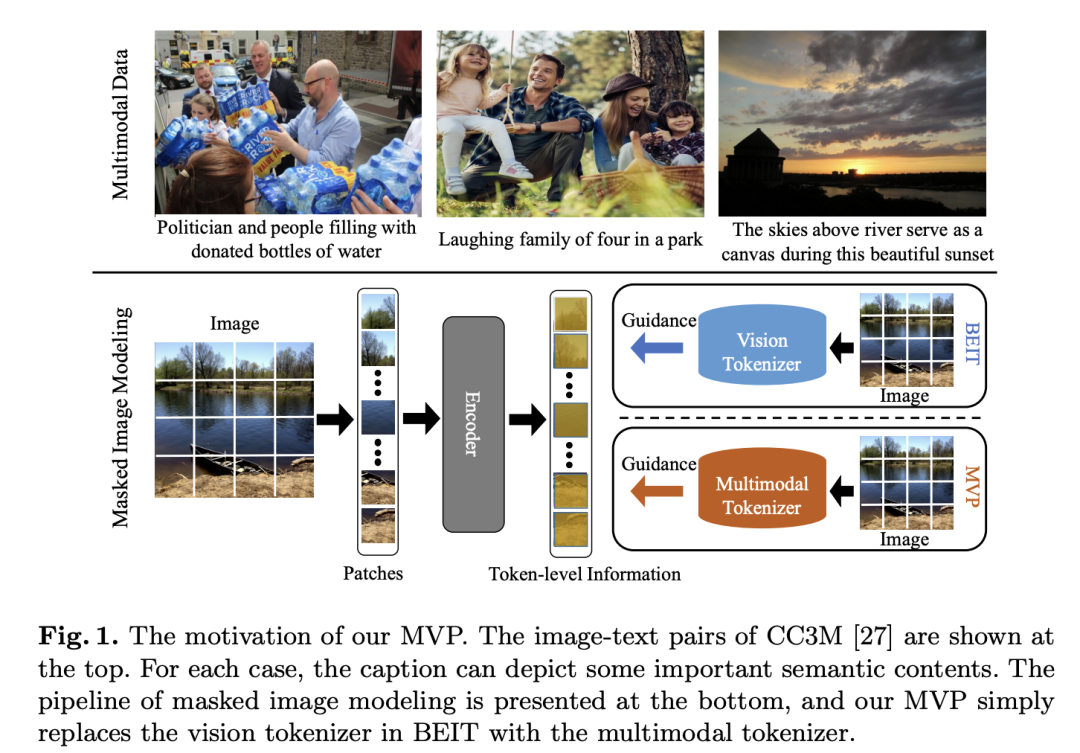 從這些具體的應(yīng)用可以進(jìn)一步看到CLIP的強(qiáng)大。
從這些具體的應(yīng)用可以進(jìn)一步看到CLIP的強(qiáng)大。
除了一些應(yīng)用研究工作,其實(shí)還有針對(duì)CLIP的一些改進(jìn)工作,最新的一篇論文Democratizing Contrastive Language-Image Pre-training: A CLIP Benchmark of Data, Model, and Supervision總結(jié)了幾種對(duì)CLIP的改進(jìn):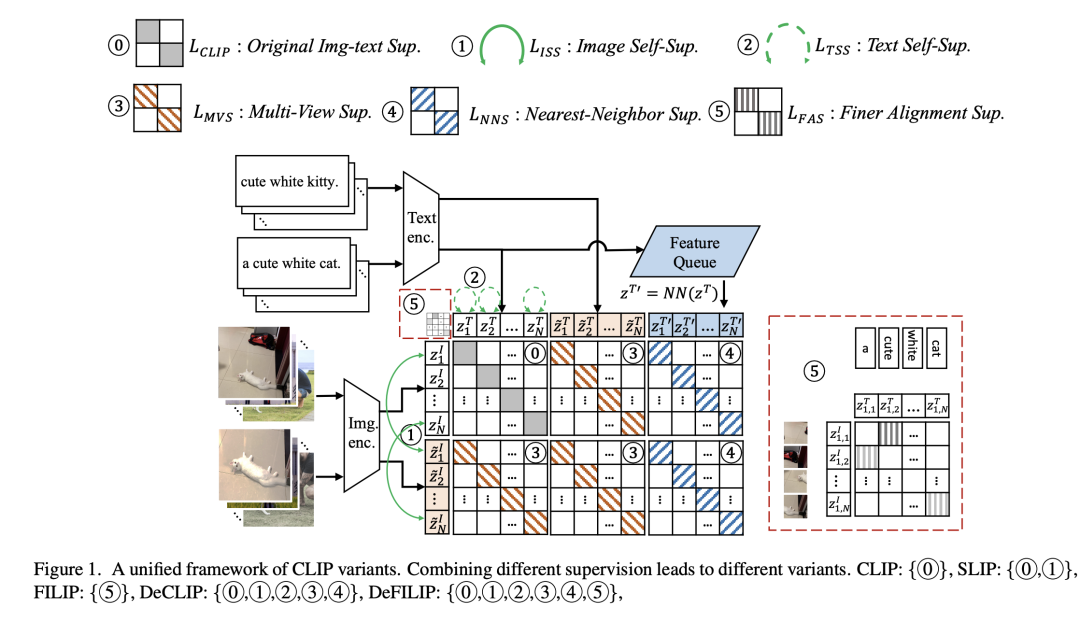
總結(jié)
這篇文章系統(tǒng)地總結(jié)了CLIP的原理以及它的具體應(yīng)用,我個(gè)人認(rèn)為:CLIP要和ViT一樣屬于相同量級(jí)的工作,它們都打破了計(jì)算機(jī)視覺的原有范式,必將在CV歷史上留名。
參考
https://openai.com/blog/clip/ https://github.com/openai/CLIP Learning Transferable Visual Models From Natural Language Supervision https://www.zhihu.com/zvideo/1475706654562299904 https://github.com/yzhuoning/Awesome-CLIP
推薦閱讀
輔助模塊加速收斂,精度大幅提升!移動(dòng)端實(shí)時(shí)的NanoDet-Plus來了!
SSD的torchvision版本實(shí)現(xiàn)詳解
機(jī)器學(xué)習(xí)算法工程師
? ??? ? ? ? ? ? ? ? ? ? ????????? ??一個(gè)用心的公眾號(hào)
