圖靈獎得主LeCun:不需要監(jiān)督的AI才是未來!
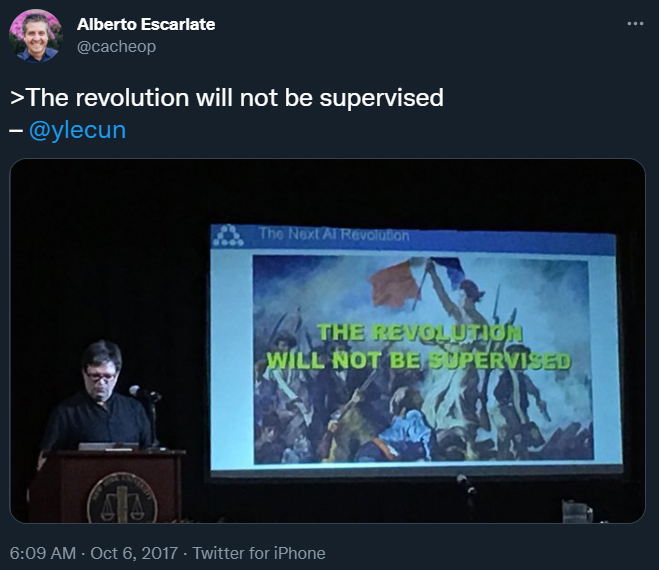
AI 的前進方向是通過更好的數(shù)據(jù)標簽來改善監(jiān)督學習,還是大力發(fā)展自監(jiān)督 / 無監(jiān)督學習?在 IEEE Spectrum 的最近的一次訪談中,圖靈獎得主、Meta 首席 AI 科學家 Yann LeCun 表達了自己的看法。
第一,我們應該使用什么樣的學習范式來訓練世界模型?
第二,世界模型應該使用什么樣的架構?
整理不易,點贊三連↓
評論
圖片
表情
<b id="afajh"><abbr id="afajh"></abbr></b>
 下載APP
下載APPAI 的前進方向是通過更好的數(shù)據(jù)標簽來改善監(jiān)督學習,還是大力發(fā)展自監(jiān)督 / 無監(jiān)督學習?在 IEEE Spectrum 的最近的一次訪談中,圖靈獎得主、Meta 首席 AI 科學家 Yann LeCun 表達了自己的看法。
第一,我們應該使用什么樣的學習范式來訓練世界模型?
第二,世界模型應該使用什么樣的架構?
整理不易,點贊三連↓
<b id="afajh"><abbr id="afajh"></abbr></b>