
總結(jié) Kafka 背后的優(yōu)秀設(shè)計(jì)

一、應(yīng)用場(chǎng)景
異步解構(gòu):在上下游沒有強(qiáng)依賴的業(yè)務(wù)關(guān)系或針對(duì)單次請(qǐng)求不需要立刻處理的業(yè)務(wù)
系統(tǒng)緩沖:有利于解決服務(wù)系統(tǒng)的吞吐量不一致的情況,尤其對(duì)處理速度較慢的服務(wù)來說起到緩沖作用
消峰作用:對(duì)于短時(shí)間偶現(xiàn)的極端流量,對(duì)后端的服務(wù)可以啟動(dòng)保護(hù)作用
數(shù)據(jù)流處理:集成 spark 做實(shí)時(shí)數(shù)據(jù)流處理
二、Kafka 拓?fù)鋱D(多副本機(jī)制)
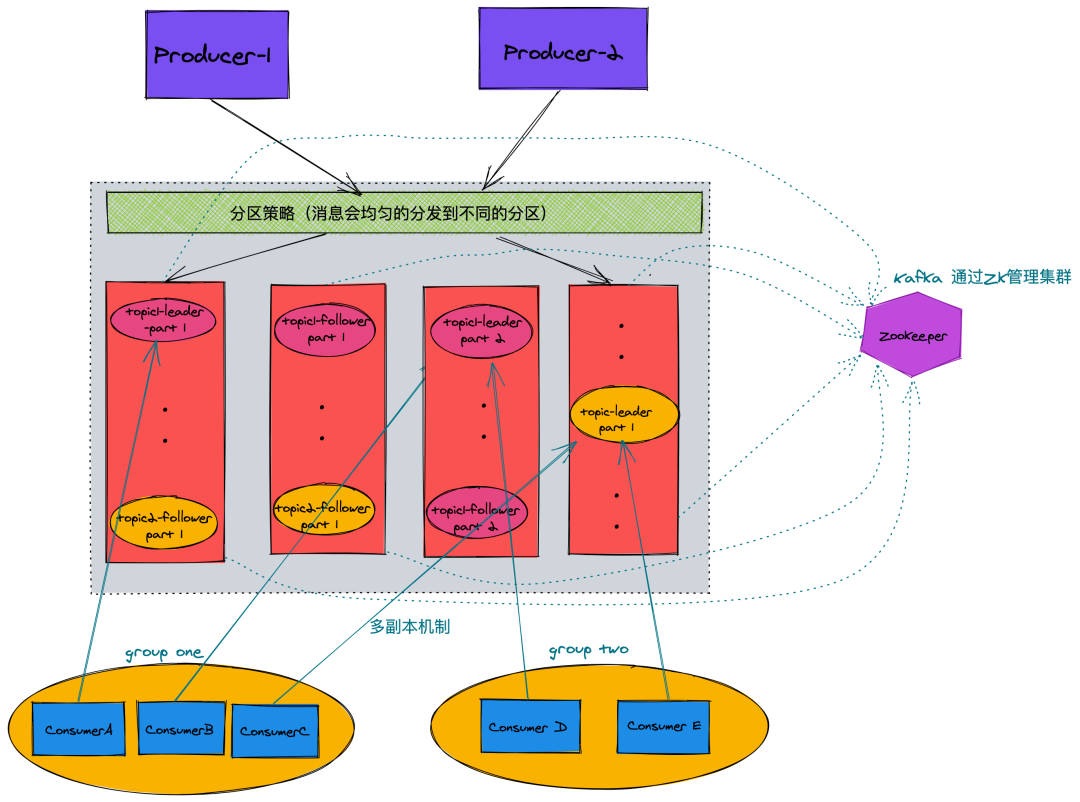
三、Kafka 核心組件
1. broker
Kafka 服務(wù)器,負(fù)責(zé)消息存儲(chǔ)和轉(zhuǎn)發(fā);一個(gè) broker 就代表一個(gè) kafka 節(jié)點(diǎn)。一個(gè) broker 可以包含多個(gè) topic。
2. topic
消息類別,Kafka 按照 topic 來分類消息。
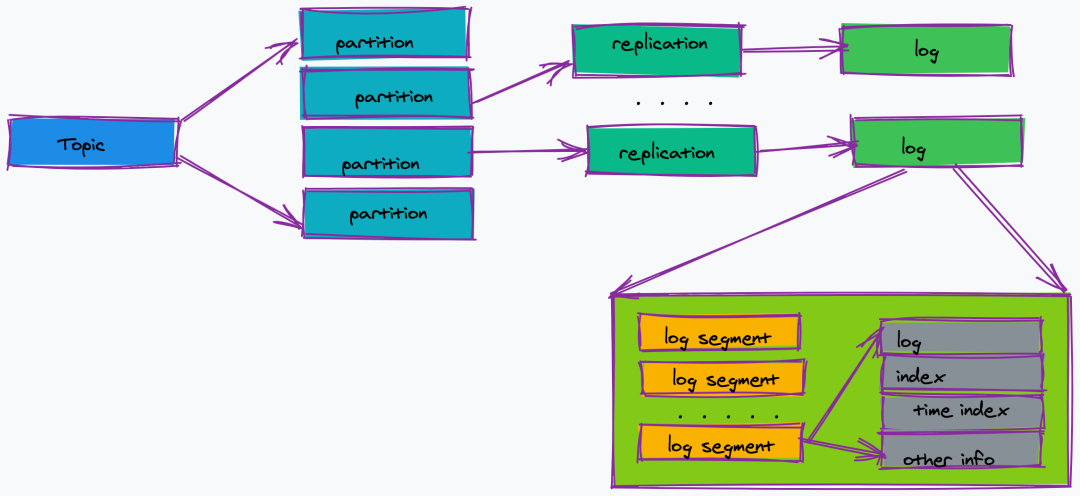
topic 的分區(qū),一個(gè) topic 可以包含多個(gè) partition,topic 消息保存在各個(gè) partition 上;由于一個(gè) topic 能被分到多個(gè)分區(qū)上,給 kafka 提供給了并行的處理能力,這也正是 kafka 高吞吐的原因之一。
partition 物理上由多個(gè) segment 文件組成,每個(gè) segment 大小相等,順序讀寫(這也是 kafka 比較快的原因之一,不需要隨機(jī)寫)。每個(gè) Segment 數(shù)據(jù)文件以該段中最小的 offset ,文件擴(kuò)展名為.log。當(dāng)查找 offset 的 Message 的時(shí)候,通過二分查找快找到 Message 所處于的 Segment 中。
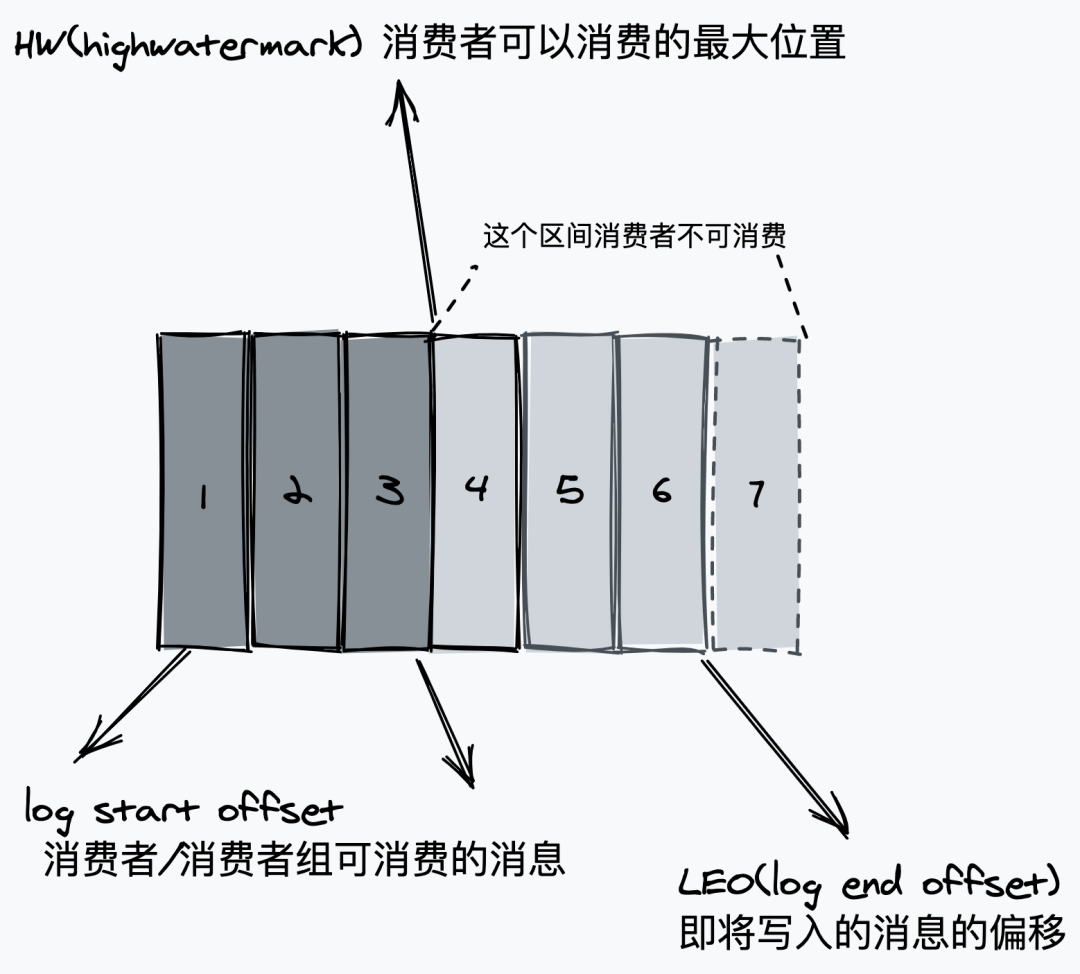
消息在日志中的位置,可以理解是消息在 partition 上的偏移量,也是代表該消息的唯一序號(hào)。
同時(shí)也是主從之間的需要同步的信息。
生產(chǎn)者,負(fù)責(zé)向 Kafka Broker 發(fā)消息的客戶端。
消息消者,負(fù)責(zé)消費(fèi) Kafka Broker 中的消息。
消費(fèi)者組,每個(gè) Consumer 必須屬于一個(gè) group;(注意:一個(gè)分區(qū)只能由組內(nèi)一個(gè)消費(fèi)者消費(fèi),消費(fèi)者組之間互不影響。)
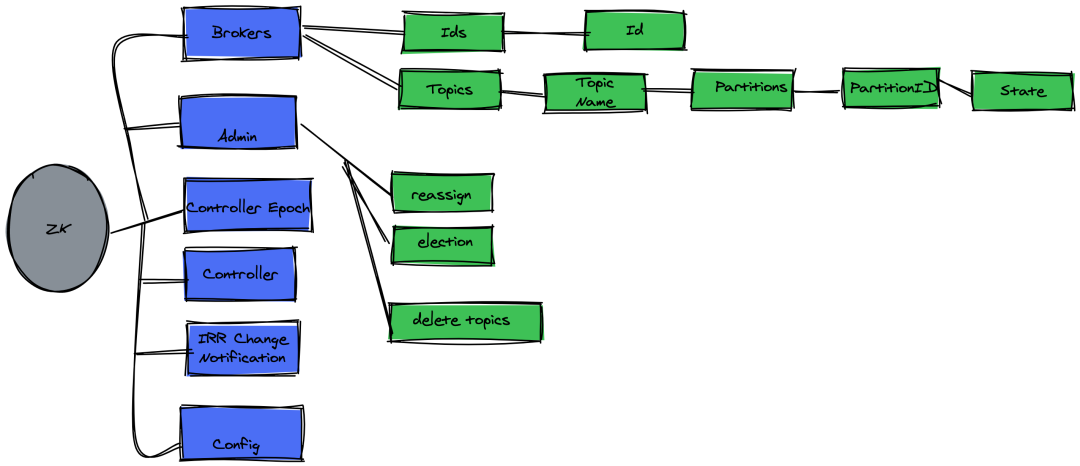
管理 kafka 集群,負(fù)責(zé)存儲(chǔ)了集群 broker、topic、partition 等 meta 數(shù)據(jù)存儲(chǔ),同時(shí)也負(fù)責(zé) broker 故障發(fā)現(xiàn),partition leader 選舉,負(fù)載均衡等功能。
四、服務(wù)治理
1. 數(shù)據(jù)同步
2. ISR
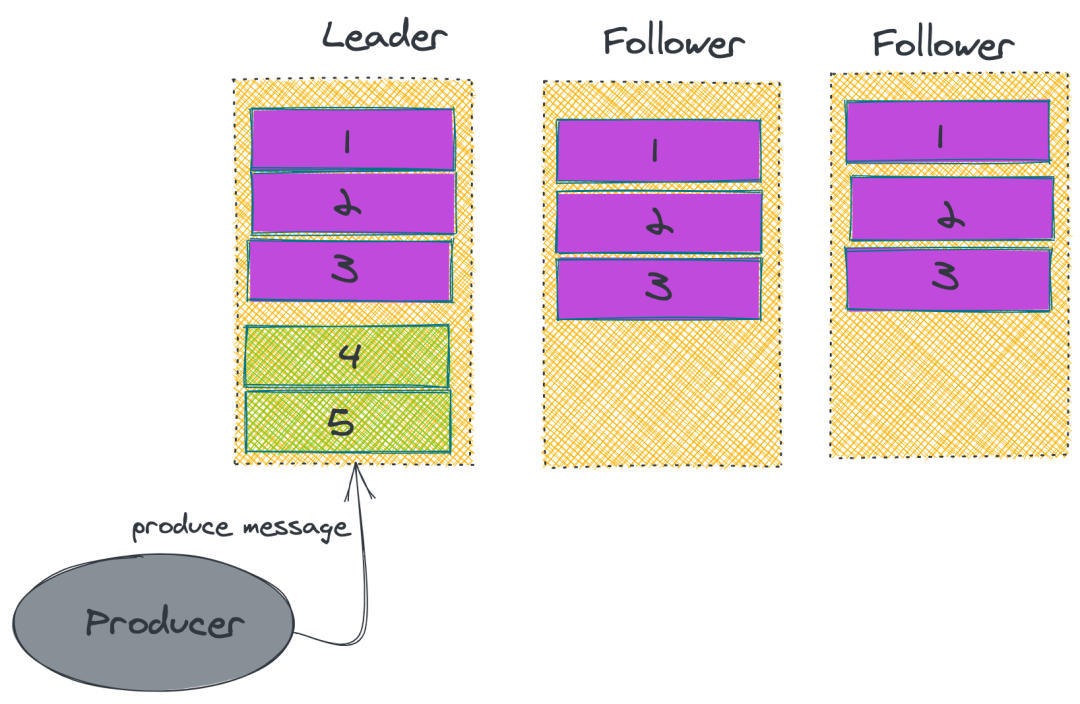
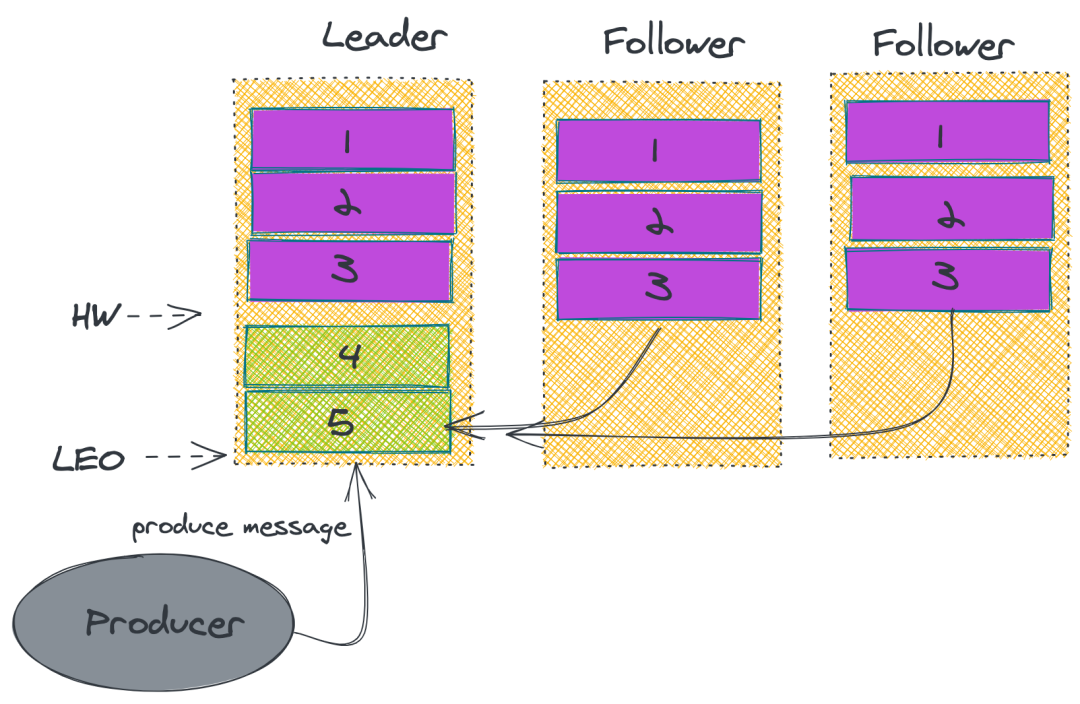
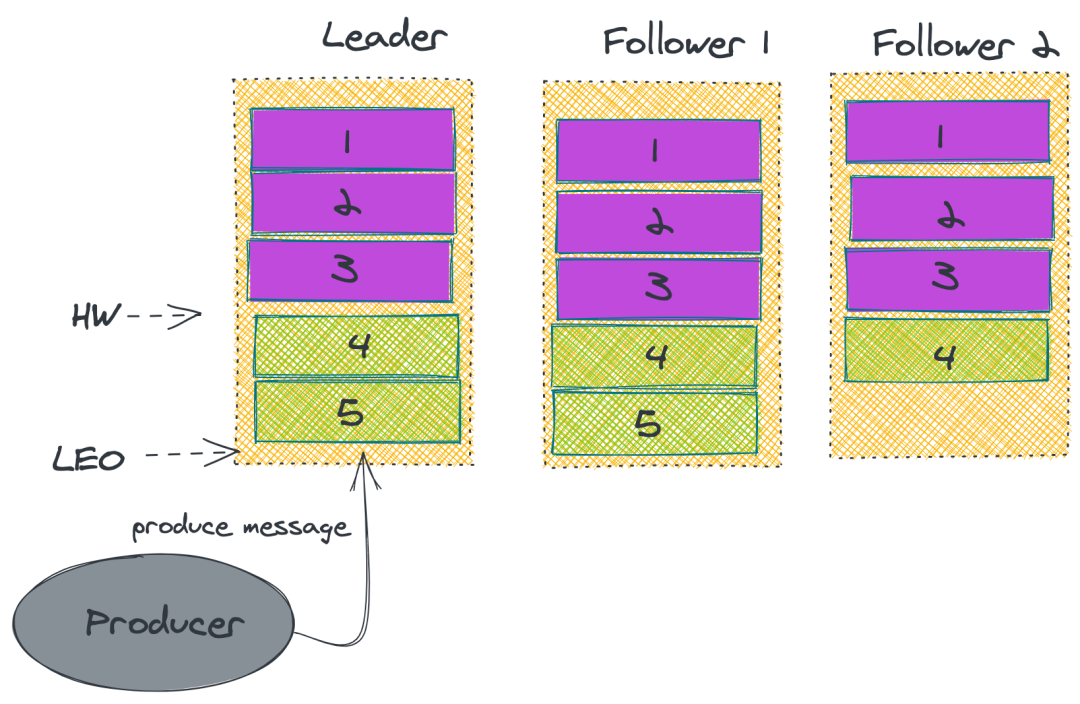
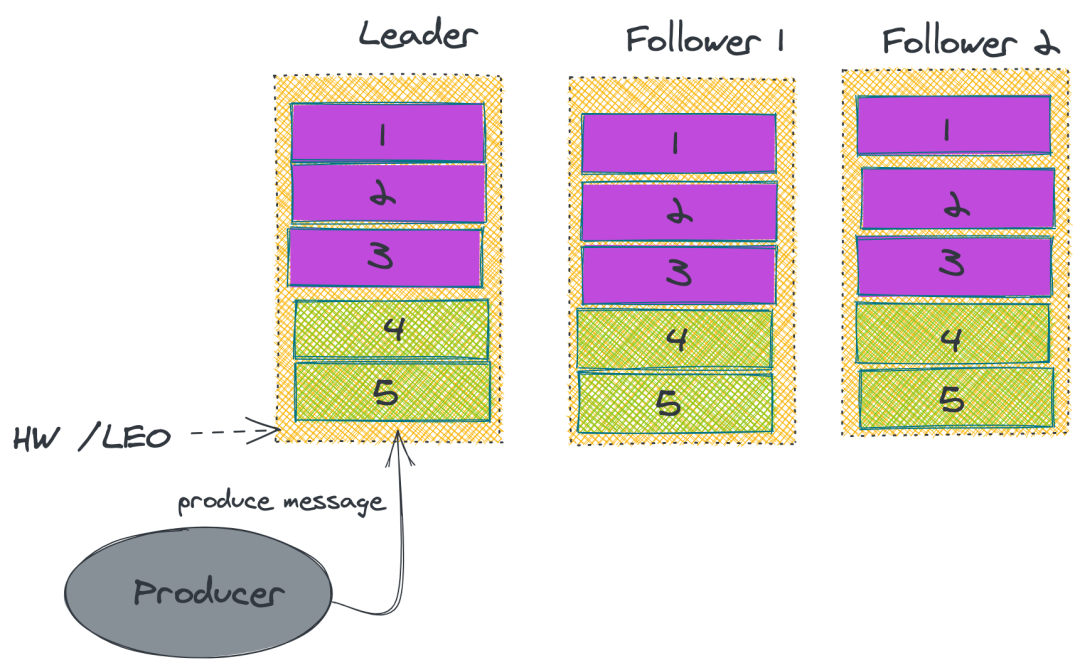
上述的做法并無法保證 Kafka 一定不丟消息。雖然 Kafka 通過多副本機(jī)制中最大限度保證消息不會(huì)丟失,但是如果數(shù)據(jù)已經(jīng)寫入系統(tǒng) page cache 中但是還沒來得及刷入磁盤,此時(shí)突然機(jī)器宕機(jī)或者掉電,那消息自然而然地就會(huì)丟失。
3. Kafka 故障恢復(fù)
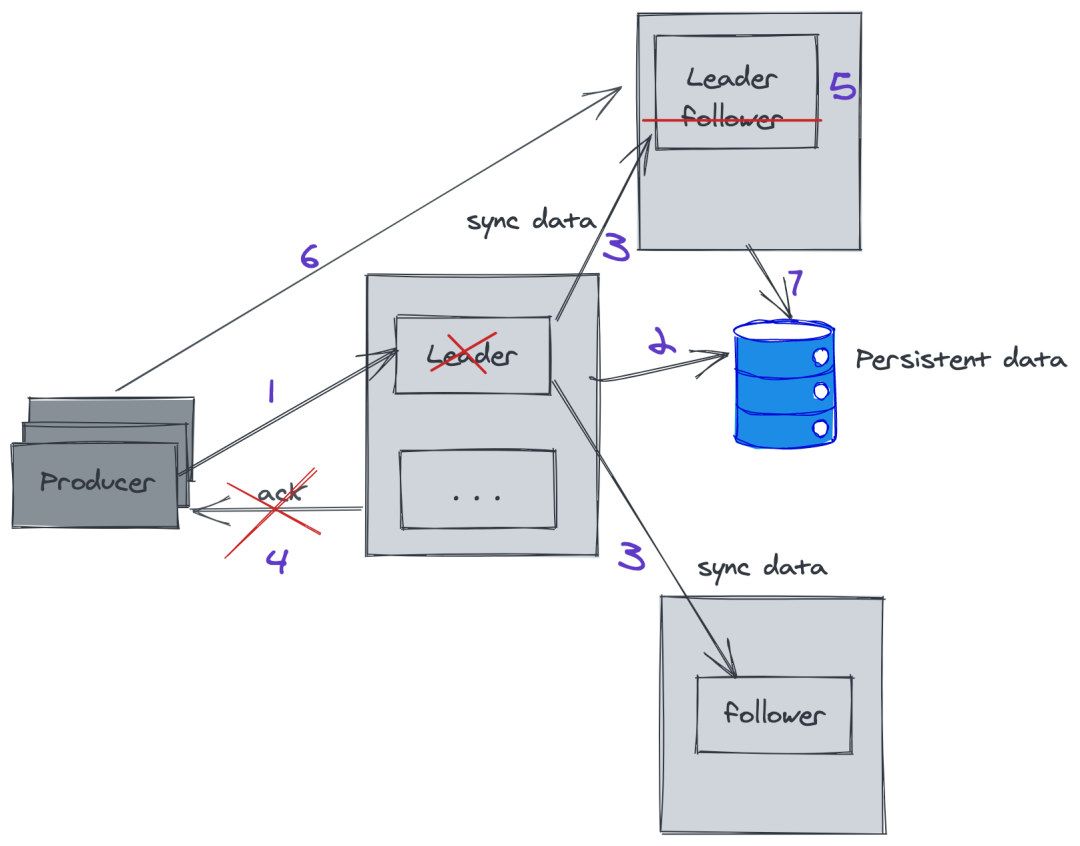
Kafka 通過 Zookeeper 連坐集群的管理,所以這里的選舉機(jī)制采用的是Zab(zookeeper 使用)。
生產(chǎn)者發(fā)生消息給 leader ,這個(gè)時(shí)候 leader 完成數(shù)據(jù)存儲(chǔ),突然發(fā)生故障,沒有給 producer 返回 ack;
通過 ZK 選舉,其中一個(gè) follower 成為 leader ,這個(gè)時(shí)候 producer 重新請(qǐng)求新的 leader,并存儲(chǔ)數(shù)據(jù)。
五、Kafka 為什么這么快
Kafka 采用了順序?qū)懘疟P,而由于順序?qū)懘疟P相對(duì)隨機(jī)寫,減少了尋地址的耗費(fèi)時(shí)間。(在 Kafka 的每一個(gè)分區(qū)里面消息是有序的)
Kafka 在 OS 系統(tǒng)方面使用了 Page Cache 而不是我們平常所用的 Buffer。Page Cache 其實(shí)不陌生,也不是什么新鮮事物。

我們?cè)?linux 上查看內(nèi)存的時(shí)候,經(jīng)常可以看到 buff/cache,兩者都是用來加速 IO 讀寫用的,而 cache 是作用于讀,也就是說,磁盤的內(nèi)容可以讀到 cache 里面,這樣應(yīng)用程序讀磁盤就非常快;而 buff 是作用于寫,我們開發(fā)寫磁盤都是,一般如果寫入一個(gè) buff 里面再 flush 就非常快。而 kafka 正是把這兩者發(fā)揮到了極致:Kafka 雖然是 scala 寫的,但是依舊在 Java 的虛擬機(jī)上運(yùn)行,盡管如此,kafka 它還是盡量避開了 JVM 的限制,它利用了 Page cache 來存儲(chǔ),這樣躲開了數(shù)據(jù)在 JVM 因?yàn)?GC 而發(fā)生的 STW。另一方面也是 Page Cache 使得它實(shí)現(xiàn)了零拷貝,具體下面會(huì)講。
無論是優(yōu)秀的 Netty 還是其他優(yōu)秀的 Java 框架,基本都在零拷貝減少了 CPU 的上下文切換和磁盤的 IO。當(dāng)然 Kafka 也不例外。零拷貝的概念具體這里不作太詳細(xì)的復(fù)述,大致地給大家講一下這個(gè)概念。
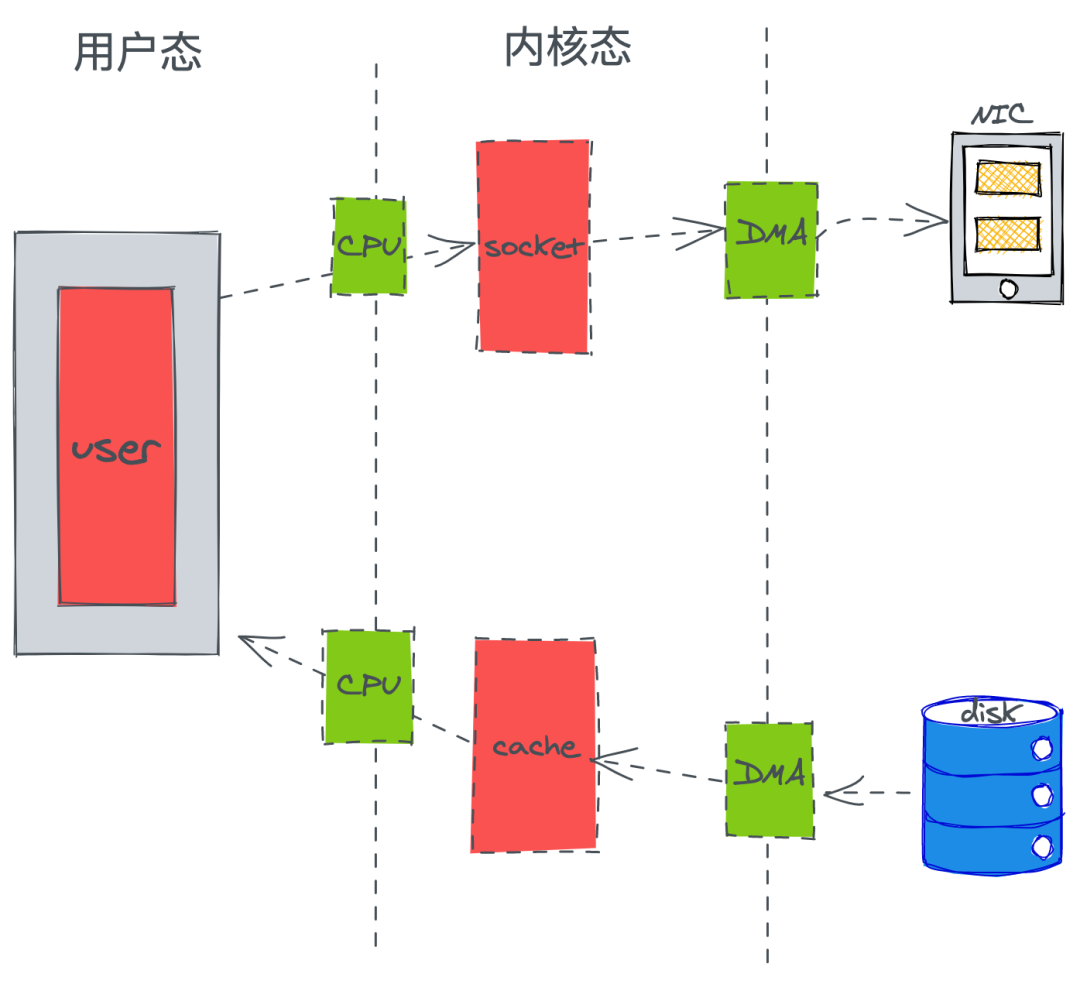
傳統(tǒng)的一次應(yīng)用程請(qǐng)求數(shù)據(jù)的過程:
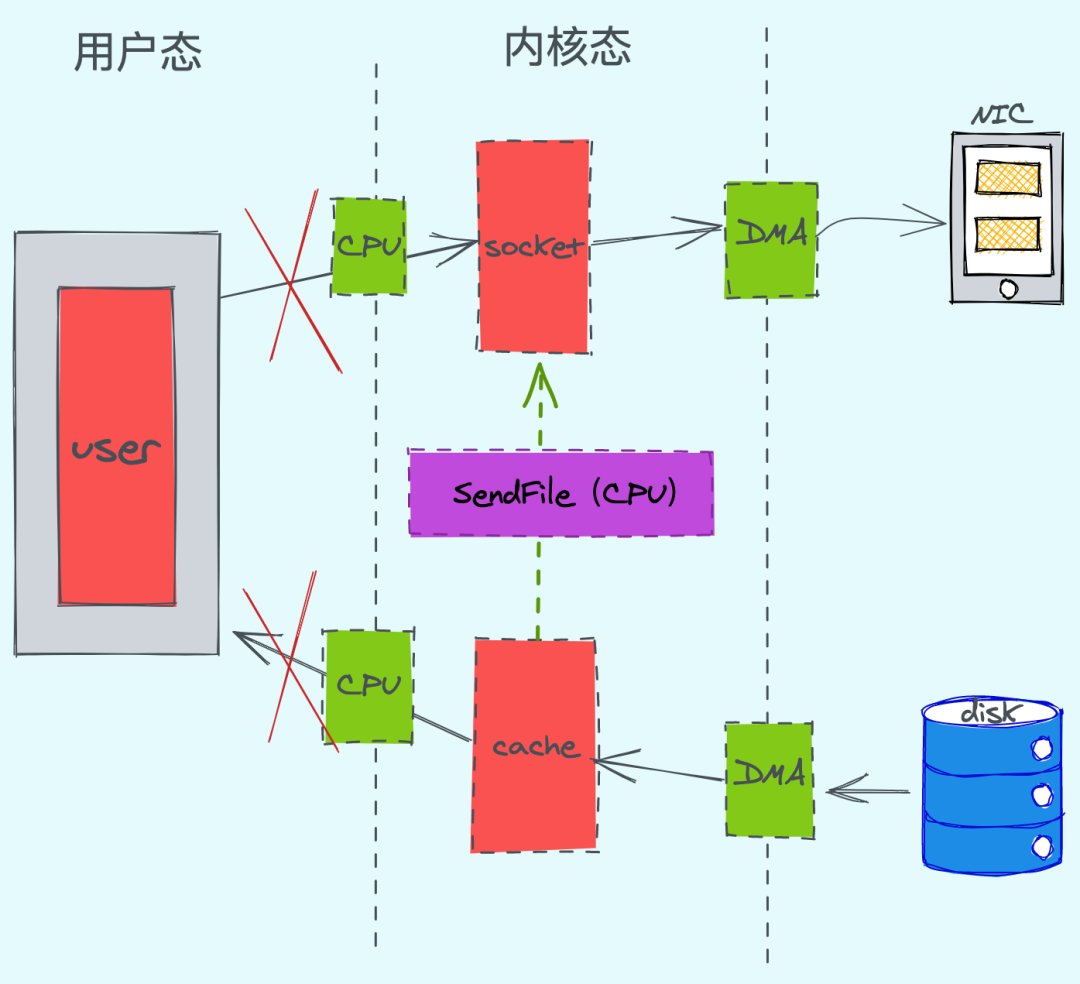
通過優(yōu)化我們可以發(fā)現(xiàn),CPU 只發(fā)生了2次的上下文切換和3次數(shù)據(jù)拷貝。(linux 系統(tǒng)提供了系統(tǒng)事故調(diào)用函數(shù)“sendfile()”,這樣系統(tǒng)調(diào)用,可以直接把內(nèi)核緩沖區(qū)里的數(shù)據(jù)拷貝到 socket 緩沖區(qū)里,不再拷貝到用戶態(tài))
六、Kafka 安裝
yum -y list Java*安裝你想要的版本,這里我是1.8
yum install java-1.8.0-openjdk-devel.x86_64查看是否安裝成功
Java -versiontar -zxvf zookeeper-3.4.9.tar.gz要做的就是將這個(gè)文件復(fù)制一份,并命名為:zoo.cfg,然后在 zoo.cfg 中修改自己的配置即可
cp zoo_sample.cfg zoo.cfgvim zoo.cfg
主要配置解釋如下:
# zookeeper內(nèi)部的基本單位,單位是毫秒,這個(gè)表示一個(gè)tickTime為2000毫秒,在zookeeper的其他配置中,都是基于tickTime來做換算的tickTime=2000# 集群中的follower服務(wù)器(F)與leader服務(wù)器(L)之間 初始連接 時(shí)能容忍的最多心跳數(shù)(tickTime的數(shù)量)。initLimit=10#syncLimit:集群中的follower服務(wù)器(F)與leader服務(wù)器(L)之間 請(qǐng)求和應(yīng)答 之間能容忍的最多心跳數(shù)(tickTime的數(shù)量)syncLimit=5# 數(shù)據(jù)存放文件夾,zookeeper運(yùn)行過程中有兩個(gè)數(shù)據(jù)需要存儲(chǔ),一個(gè)是快照數(shù)據(jù)(持久化數(shù)據(jù))另一個(gè)是事務(wù)日志dataDir=/tmp/zookeeper## 客戶端訪問端口clientPort=2181
配置環(huán)境變量
vim ~/.bash_profileexport ZK=/usr/local/src/apache-zookeeper-3.7.0-binexport PATH=$PATH:$ZK/binexport PATH// 啟動(dòng)zkServer.sh start
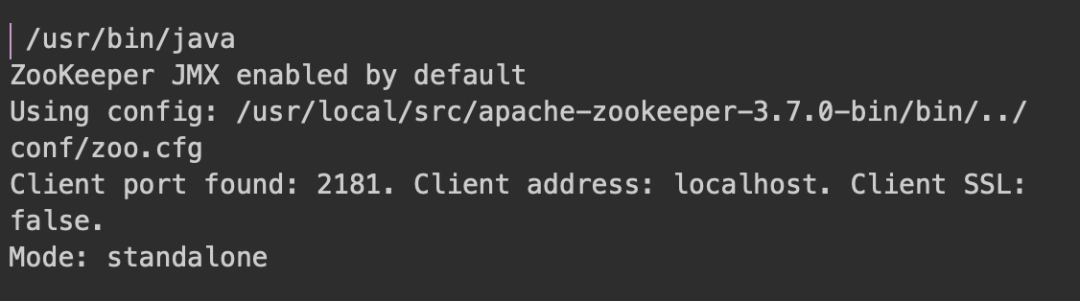
下面能看啟動(dòng)成功

tar -xzvf kafka_2.12-2.0.0.tgz export ZK=/usr/local/src/apache-zookeeper-3.7.0-binexport PATH=$PATH:$ZK/binexport KAFKA=/usr/local/src/kafkaexport PATH=$PATH:$KAFKA/bin
nohup kafka-server-start.sh 自己的配置文件路徑/server.properties &
6月5日,Techo TVP 開發(fā)者峰會(huì) ServerlessDays China 2021,即將重磅來襲!
掃碼立即參會(huì)贏好禮??
