
非常硬核的解釋!
知乎上搜到一個比較有意思的話題:如何理解「進(jìn)入內(nèi)核態(tài)」,要回答好這個問題需要對內(nèi)存管理及程序的運(yùn)行機(jī)制有比較深刻的了解,比如你需要了解內(nèi)存的分段,分頁,中斷,特權(quán)級等機(jī)制,信息量比較大,本文將會從 Intel CPU 的發(fā)展歷史講起,循序漸近地幫助大家徹底掌握這一概念,相信大家看了肯定有幫助,本文目錄如下
CPU 運(yùn)行機(jī)制
Intel CPU 歷史發(fā)展史
分段
保護(hù)模式
特權(quán)級
系統(tǒng)調(diào)用
中斷
分段內(nèi)存的優(yōu)缺點(diǎn)
內(nèi)存分頁
總結(jié)
CPU 運(yùn)行機(jī)制
我們先簡單地回顧一下 CPU 的工作機(jī)制,重新溫習(xí)一下一些基本概念,因為我在查閱資料的過程發(fā)現(xiàn)一些網(wǎng)友對尋址,CPU 是幾位的概念理解得有些模糊,理解了這些概念再去看 CPU 的發(fā)展史就不會再困惑。
CPU 是如何工作的呢?它是根據(jù)一條條的機(jī)器指令來執(zhí)行的,而機(jī)器指令= 操作碼+操作數(shù),操作數(shù)主要有三類:寄存器地址、內(nèi)存地址或立即數(shù)(即常量)。
我們所熟悉的程序就是一堆指令和數(shù)據(jù)的集合,當(dāng)打開程序時,裝載器把程序中的指令和數(shù)據(jù)加載到內(nèi)存中,然后由 CPU 進(jìn)行取指執(zhí)行指令。
在內(nèi)存中是以字節(jié)為基本單位來讀寫數(shù)據(jù)的,我們可以把內(nèi)存看作是一個個的小格子(一般我們稱其為內(nèi)存單元),而每個小格子是一個字節(jié),那么對于 B8 0123H 這條指令來說,它在內(nèi)存中占三字節(jié),如下,CPU 該怎么找到這些格子呢,我們需要給這些格子編號,這些編號也就是我們說的內(nèi)存地址,根據(jù)內(nèi)存地址就是可以定位指令所在位置,從而取出里面的數(shù)據(jù)
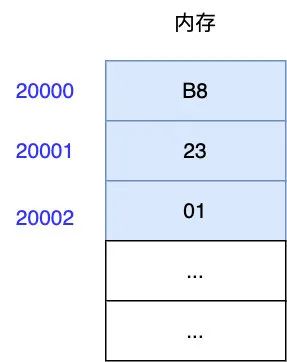
如圖示:內(nèi)存被分成了一個個的格子,每個格子一個字節(jié),20000~20002 分別為對應(yīng)格子的編號(即內(nèi)存地址)
CPU 執(zhí)行指令主要分為以下幾個步驟
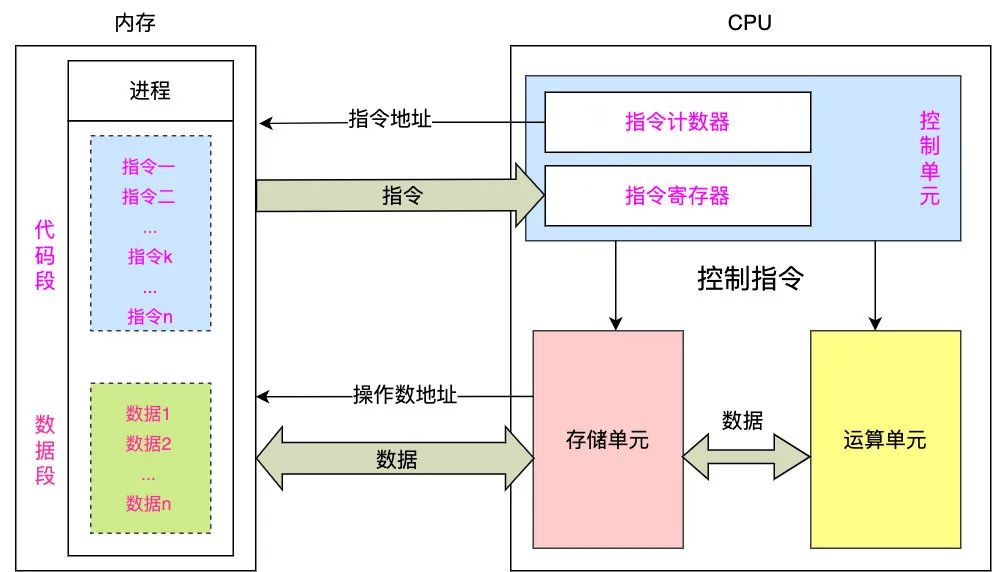
取指令,CPU 怎么知道要去取哪條指令呢,它里面有一個 IP 寄存器指向了對應(yīng)要取的指令的內(nèi)存地址, 然后這個內(nèi)存地址會通過地址總線找到對應(yīng)的格子,我們把這個過程稱為尋址,不難發(fā)現(xiàn)尋址能力決定于地址總線的位寬,假設(shè)地址總線位數(shù)為 20 位,那么內(nèi)存的可尋址空間為 2^20 * 1Byte = 1M,將格子(內(nèi)存單元)里面的數(shù)據(jù)(指令)取出來后,再通過數(shù)據(jù)總線發(fā)往 CPU 中的指令緩存區(qū)(指令寄存器),那么一次能傳多少數(shù)據(jù)呢,取決于數(shù)據(jù)總線的位寬,如果數(shù)據(jù)總線為 16 位,那么一次可以傳 16 bit 也就是兩個字節(jié)。
譯碼:指令緩沖區(qū)中的指令經(jīng)過譯碼以確定該進(jìn)行什么操作
執(zhí)行:譯碼后會由控制單元向運(yùn)算器發(fā)送控制指令進(jìn)行操作(比如執(zhí)行加減乘除等),執(zhí)行是由運(yùn)算器操縱數(shù)據(jù)也就是操作數(shù)進(jìn)行計算,而操作數(shù)保存在存儲單元(即片內(nèi)的緩存和寄存器組)中,由于操作數(shù)有可能是內(nèi)存地址,所以執(zhí)行中可能需要到內(nèi)存中獲取數(shù)據(jù)(這個過程稱為訪存),執(zhí)行后的結(jié)果保存在寄存器或寫回內(nèi)存中
以指令 mov ax, 0123H 為例,它表示將數(shù)據(jù) 0123H 存到寄存器 AX 中,在此例中 AX 為 16 位寄存器,一次可以操作 16 位也就是 2 Byte 的數(shù)據(jù),所以我們將其稱為 16 位 CPU,CPU 是多少位取決于它一次執(zhí)行指令的數(shù)據(jù)帶寬,而數(shù)據(jù)帶寬又取決于通用寄存 器的位寬
更新 IP:執(zhí)行完一條指令后,更新 IP 中的值,將其指向下一條指令的起始地址,然后重復(fù)步驟 1
由以上總結(jié)可知尋址能力與寄存器位數(shù)有關(guān)。
接下來我們以執(zhí)行四條指令為例再來仔細(xì)看下 CPU 是如何執(zhí)行指令的,動圖如下:
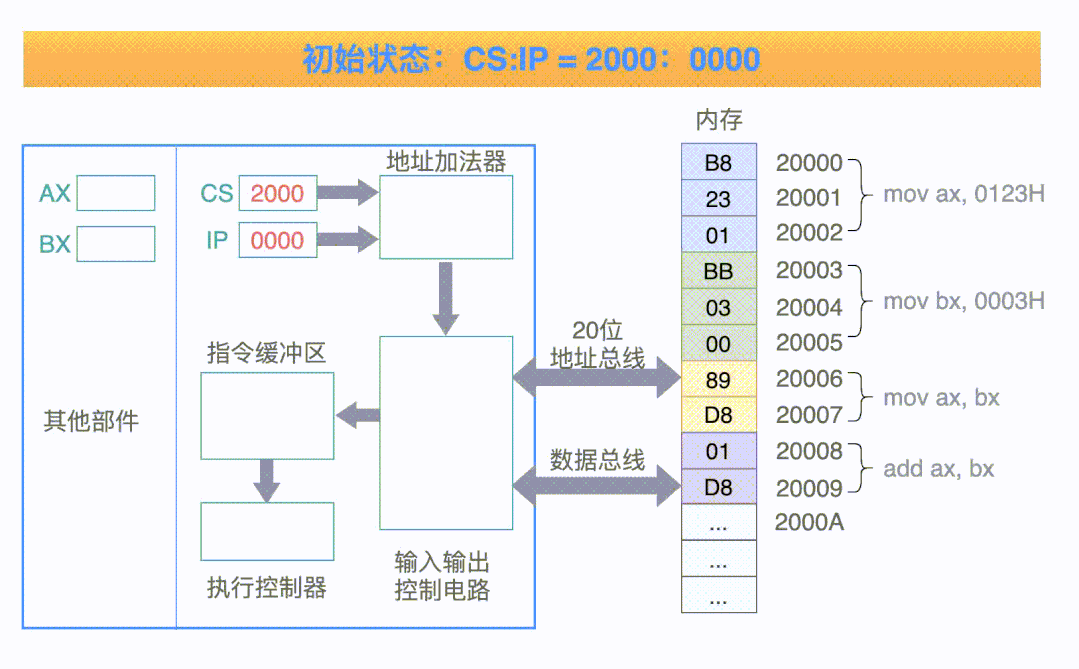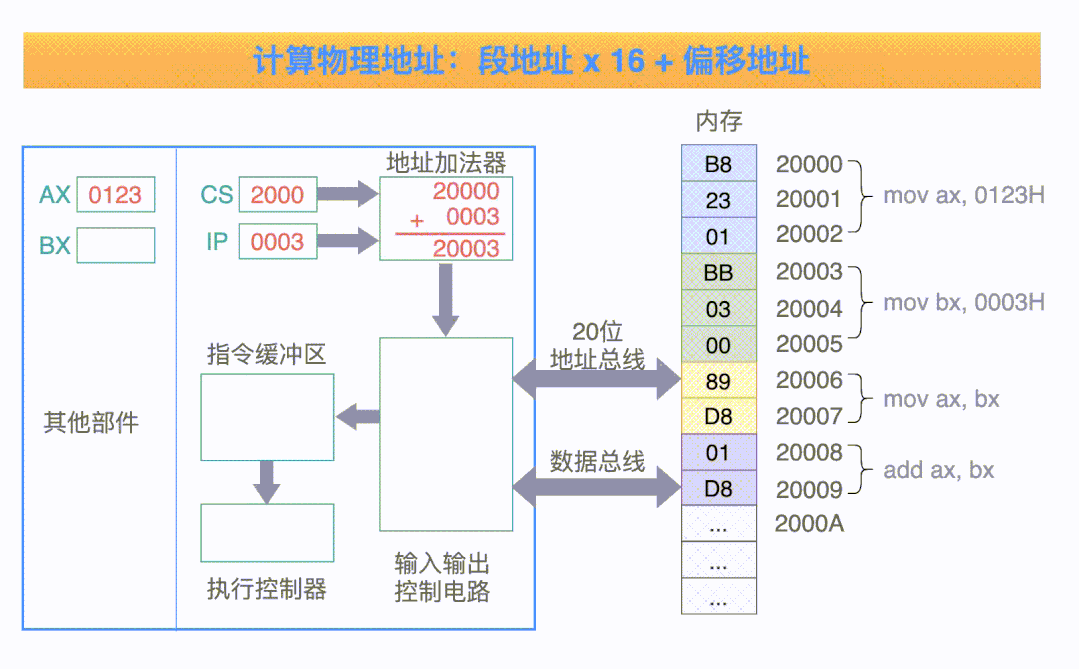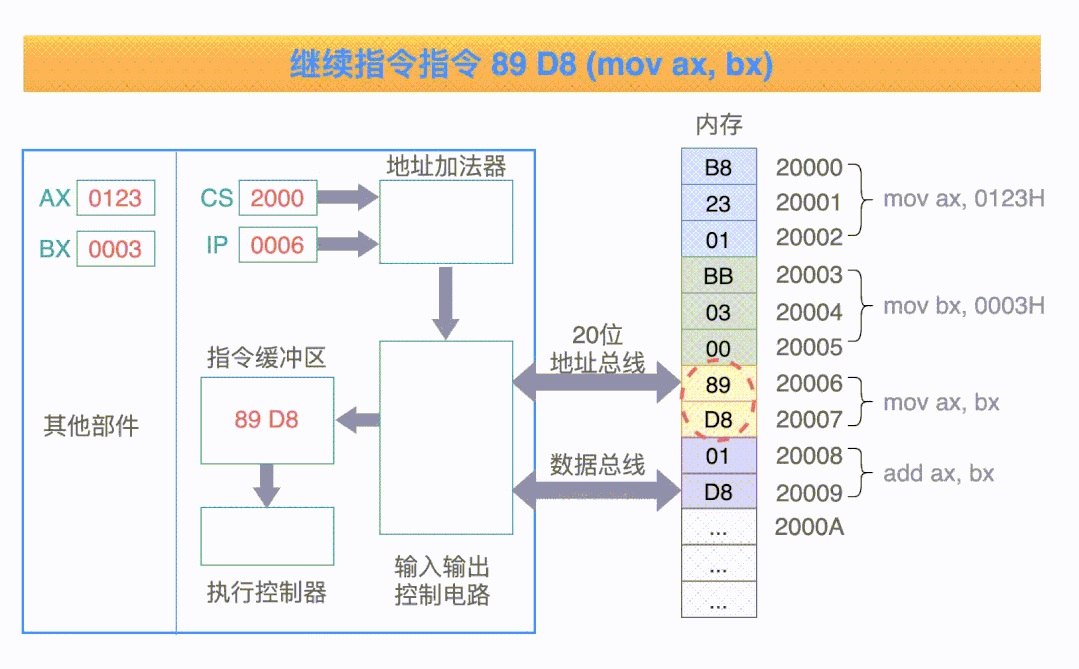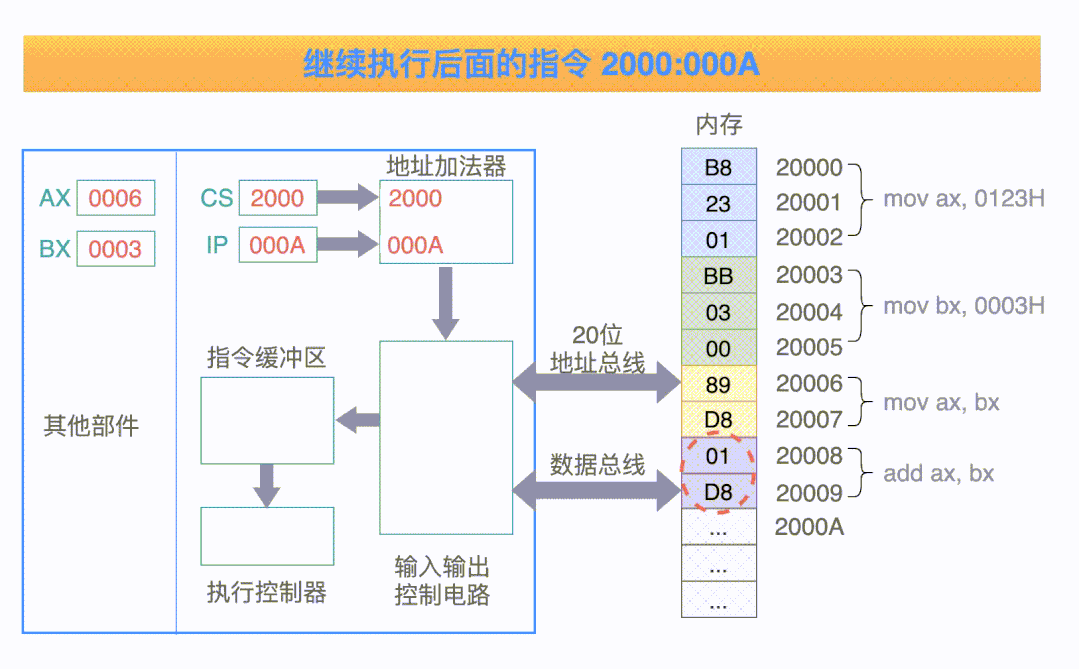
看到上面這個動圖,細(xì)心地你可能會發(fā)現(xiàn)兩個問題
前文說指令地址是根據(jù) IP 來獲取的嗎,但上圖顯示指令地址卻是由「CS 左移四位 + IP」計算而來的,與我們所闡述的指令保存在 IP 寄存器中似乎有些出入,這是怎么回事呢?
動圖顯示的地址是真實物理地址,這樣進(jìn)程之間可以互相訪問/改寫對方的物理地址,顯然是不安全的,那如何才能做到安全訪問或者說進(jìn)程間內(nèi)存的隔離呢
以上兩點(diǎn)其實只要我們了解一下 CPU 的發(fā)展歷史就明白解決方案了,有了以上的鋪墊,在明白了尋址,16/32/64 位 CPU 等術(shù)語的含義后,再去了解 CPU 的發(fā)展故事會更容易得多,話不多說,發(fā)車
Intel CPU 歷史發(fā)展史
1971 年世界上第一塊 4 位 CPU-4004 微處理器橫空出世,1974 年 Intel 研發(fā)成功了 8 位 CPU-8080,這兩款 CPU 都是使用的絕對物理地址來尋址的,指令地址只存在于 IP 寄存器中(即只使用 IP 寄存器即可確定內(nèi)存地址)。由于是使用絕對物理地址尋址,也就意味著進(jìn)程之間的內(nèi)存數(shù)據(jù)可能會互相覆蓋,很不安全,所以這兩者只支持單進(jìn)程
分段
1978 年英特爾又研究成功了第一款 16 位 CPU - 8086,這款 CPU 可以說是 x86 系列的鼻祖了,設(shè)計了 16 位的寄存器和 20 位的地址總線,所以內(nèi)存地址可以達(dá)到 2^20 Byte 即 1M,極大地擴(kuò)展了地址空間,但是問題來了,由于寄存器只有 16 位,那么 16 位的 IP 寄存器如何能尋址 20 位的地址呢,首先 Intel 工程師設(shè)計了一種分段的方法:1M 內(nèi)存可以分為 16 個大小為 64 K 的段,那么內(nèi)存地址就可以由「段的起始地址(也叫段基址) + 段內(nèi)偏移(IP 寄存器中的值)」組成,對于進(jìn)程說只需要關(guān)心 4 個段 ,代碼段,數(shù)據(jù)段,堆棧段,附加段,這幾個段的段基址分別保存在 CS,DS,SS,ES 這四個寄存器中
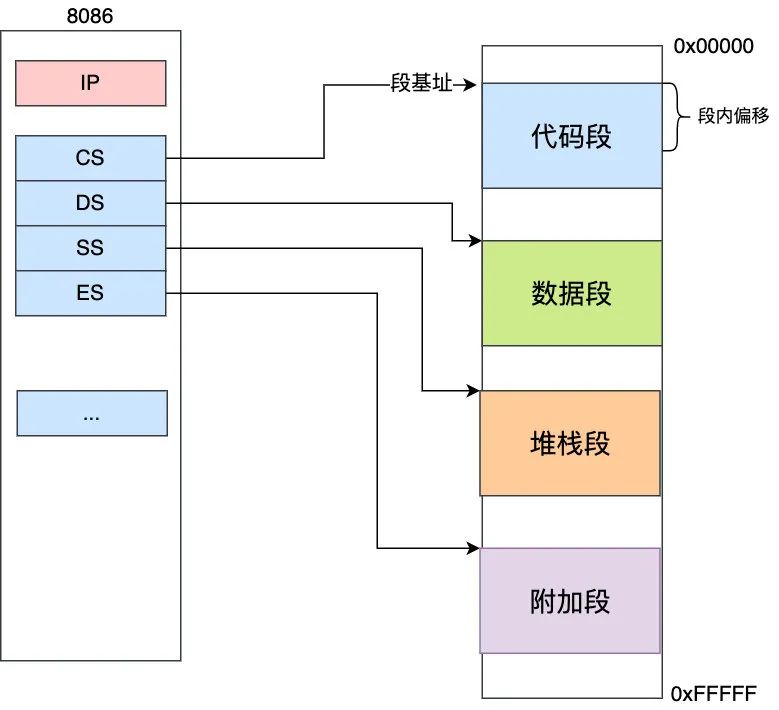
這四個寄存器也是 16 位,那怎么訪問 20 位的內(nèi)存地址呢,實現(xiàn)也很簡單,將每個寄存器的值左移四位,然后再加上段內(nèi)偏移即為尋址地址,CPU 都是取代碼段 中的指令來執(zhí)行的,我們以代碼段內(nèi)的尋址為例來計算內(nèi)存地址,指令的地址 = CS << 4 + IP ,這種方式做到了 20 位的尋址,只要改變 CS,IP 的值,即可實現(xiàn)在 0 到最大地址 0xFFFFF 全部 20 位地址的尋址
舉個例子:假設(shè) CS 存的數(shù)據(jù)為 0x2000,IP 為 0x0003,那么對應(yīng)的指令地址為
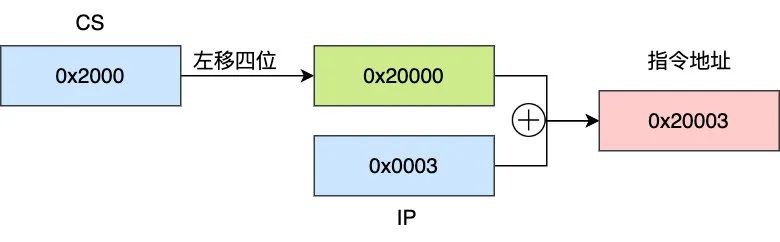
圖示為真實的物理地址計算方式,從中可知, CS 其實保存的是真實物理地址的高 16 位
分段的初衷是為了解決尋址問題,但本質(zhì)上段寄存器中保存的還是真實物理地址的段基礎(chǔ),且可以隨意指定,所以它也無法支持多進(jìn)程,因為這意味著進(jìn)程可以隨意修改 CS:IP 將其指向任意地址,很可能會覆蓋正在運(yùn)行的其他進(jìn)程的內(nèi)存,造成災(zāi)難性后果。
我們把這種使用真實物理地址且未加任何限制的尋址方式稱為實模式(real mode,即實際地址模式)
保護(hù)模式
實模式上的物理地址由段寄存器中的段基址:IP 計算而來,而段基址可由用戶隨意指定,顯然非常不安全,于是 Intel 在之后推出了 80286 中啟用了保護(hù)模式,這個保護(hù)是怎么做的呢
首先段寄存器保存的不再是段基址了,而是段選擇子(Selector),其結(jié)構(gòu)如下

其中第 3 到 15 位保存的是描述符索引,此索引會根據(jù) TI 的值是 0 還是 1 來選擇是到 GDT(全局描述符表,一般也稱為段表)還是 LDT 來找段描述符,段描述符保存的是段基址和段長度,找到段基址后再加上保存在 IP 寄存器中的段偏移量即為物理地址,段描述符的長度統(tǒng)一為 8 個字節(jié),而 GDT/LDT 表的基地址保存在 gdtr/ldtr 寄存器中,以 GDT (此時 TI 值為 0)為例來看看此時 CPU 是如何尋址的
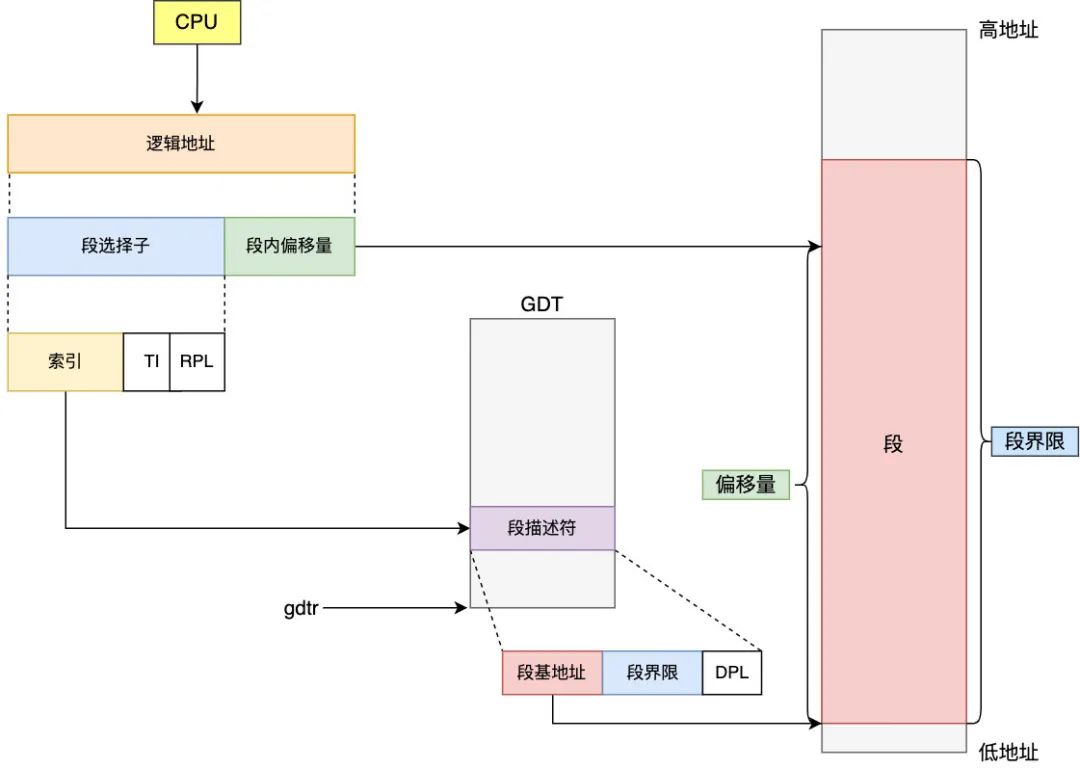
可以看到程序中的地址是由段選擇子:段內(nèi)偏移量組成的,也叫邏輯地址,在只有分段內(nèi)存管理的情況下它也被稱為虛擬內(nèi)存
GDT 及段描述符的分配都是由操作系統(tǒng)管理的,進(jìn)程也無法更新 CS 等寄存器中值,這樣就避免了直接操作其他進(jìn)程以及自身的物理地址,達(dá)到了保護(hù)內(nèi)存的效果,從而為多進(jìn)程運(yùn)行提供了可能,我們把這種尋址方式稱為保護(hù)模式
那么保護(hù)模式是如何實現(xiàn)的呢,細(xì)心的你可能發(fā)現(xiàn)了上圖中在段選擇子和段描述符中里出現(xiàn)了 RPL 和 DPL 這兩個新名詞,這兩個表示啥意思呢?這就涉及到一個概念:特權(quán)級
特權(quán)級
我們知道 CPU 是根據(jù)機(jī)器指令來執(zhí)行的,但這些指令有些是非常危險的,比如清內(nèi)存,置時鐘,分配系統(tǒng)資源等,這些指令顯然不能讓普通的進(jìn)程隨意執(zhí)行,應(yīng)該始終控制在操作系統(tǒng)中執(zhí)行,所以要把操作系統(tǒng)和普通的用戶進(jìn)程區(qū)分開來
我們把一個進(jìn)程的虛擬地址劃分為兩個空間,用戶空間和內(nèi)核空間,用戶空間即普通進(jìn)程所處空間,內(nèi)核空間即操作系統(tǒng)所處空間
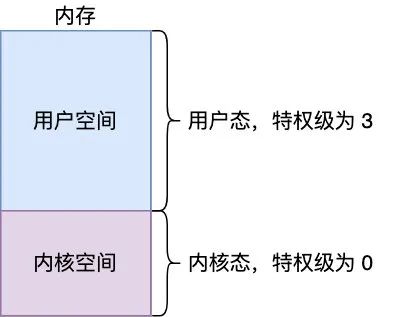
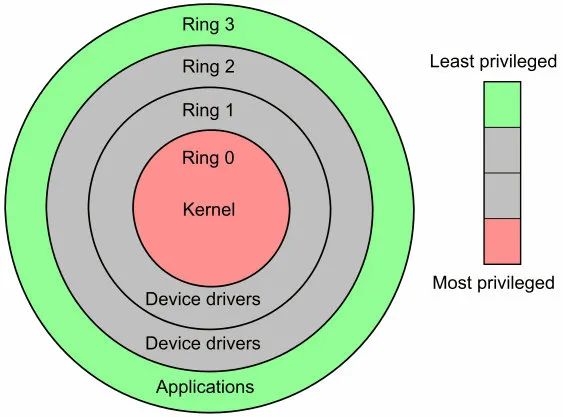
當(dāng) CPU 運(yùn)行于用戶空間(執(zhí)行用戶空間的指令)時,它處于用戶態(tài),只能執(zhí)行普通的 CPU 指令 ,當(dāng) CPU 運(yùn)行于內(nèi)核空間(執(zhí)行內(nèi)核空間的指令)時,它處于內(nèi)核態(tài),可以執(zhí)行清內(nèi)存,置時鐘,讀寫文件等特權(quán)指令,那怎么區(qū)分 CPU 是在用戶態(tài)還是內(nèi)核態(tài)呢,CPU 定義了四個特權(quán)等級,如下,從 0 到 3,特權(quán)等級依次遞減,當(dāng)特權(quán)級為 0 時,CPU 處于內(nèi)核態(tài),可以執(zhí)行任何指令,當(dāng)特權(quán)級為 3 時,CPU 處于用戶態(tài),在 Linux 中只用了 Ring 0,Ring 3 兩個特權(quán)等級
那么問題來了,怎么知道 CPU 處于哪一個特權(quán)等級呢,還記得上文中我們提到的段選擇子嗎
其中的 RPL 表示請求特權(quán)((Requested privilege level))我們把當(dāng)前保存于 CS 段寄存器的段選擇子中的 RPL 稱為 CPL(current priviledge level),即當(dāng)前特權(quán)等級,可以看到 RPL 有兩位,剛好對應(yīng)著 0,1,2,3 四個特權(quán)級,而上文提到的 DPL 表示段描述符中的特權(quán)等級(Descriptor privilege level)知道了這兩個概念也就知道保護(hù)模式的實現(xiàn)原理了,CPU 會在兩個關(guān)鍵點(diǎn)上對內(nèi)存進(jìn)行保護(hù)
目標(biāo)段選擇子被加載時
當(dāng)通過線性地址(在只有段式內(nèi)存情況下,線性地址為物理地址)訪問一個內(nèi)存頁時。由此可見,保護(hù)也反映在內(nèi)存地址轉(zhuǎn)換的過程之中,既包括分段又包括分頁(后文分提到分頁)
CPU 是怎么保護(hù)內(nèi)存的呢,它會對 CPL,RPL,DPL 進(jìn)行如下檢查
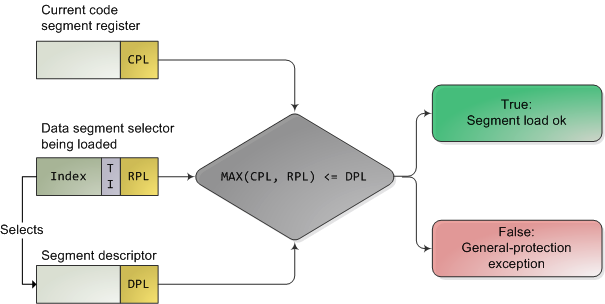
只有 CPL <= DPL 且 RPL <= DPL 時,才會加載目標(biāo)代碼段執(zhí)行,否則會報一般保護(hù)異常 (General-protection exception)
那么特權(quán)等級(也就是 CPL)是怎么變化的呢,我們之前說了 CPU 運(yùn)行于用戶空間時,處于用戶態(tài),特權(quán)等級為 3,運(yùn)行于內(nèi)核空間時,處于內(nèi)核態(tài),特權(quán)等級為 0,所以也可以換個問法 CPU 是如何從用戶空間切換到內(nèi)核空間或者從內(nèi)核空間切換到用戶空間的,這就涉及到一個概念:系統(tǒng)調(diào)用
系統(tǒng)調(diào)用
我們知道用戶進(jìn)程雖然不能執(zhí)行特權(quán)指令,但有時候也需要執(zhí)行一些讀寫文件,發(fā)送網(wǎng)絡(luò)包等操作,而這些操作又只能讓操作系統(tǒng)來執(zhí)行,那該怎么辦呢,可以讓操作系統(tǒng)提供接口,讓用戶進(jìn)程來調(diào)用即可,我們把這種方式叫做系統(tǒng)調(diào)用,系統(tǒng)調(diào)用可以直接由應(yīng)用程序調(diào)用,或者通過調(diào)用一些公用函數(shù)庫或 shell(這些函數(shù)庫或 shell 都封裝了系統(tǒng)調(diào)用接口)等也可以達(dá)到間接調(diào)用系統(tǒng)調(diào)用的目的。通過系統(tǒng)調(diào)用,應(yīng)用程序?qū)崿F(xiàn)了陷入(trap)內(nèi)核態(tài)的目的,這樣就從用戶態(tài)切換到了內(nèi)核態(tài)中,如下
用程序通過系統(tǒng)調(diào)用陷入內(nèi)核態(tài)")
那么系統(tǒng)調(diào)用又是怎么實現(xiàn)的呢,主要是靠中斷實現(xiàn)的,接下來我們就來了解一下什么是中斷
中斷
陷入內(nèi)核態(tài)的系統(tǒng)調(diào)用主要是通過一種 trap gate(陷阱門)來實現(xiàn)的,它其實是軟件中斷的一種,由 CPU 主動觸發(fā)給自己一個中斷向量號,然后 CPU 根據(jù)此中斷向量號就可以去中斷向量表找到對應(yīng)的門描述符,門描述符與 GDT 中的段描述符相似,也是 8 個字節(jié),門描述符中包含段選擇子,段內(nèi)偏移,DPL 等字段 ,然后再根據(jù)段選擇子去 GDT(或者 LDT,下圖以 GDT 為例) 中查找對應(yīng)的段描述符,再找到段基地址,然后根據(jù)中斷描述符表的段內(nèi)偏移即可找到中斷處理例程的入口點(diǎn),整個中斷處理流程如下
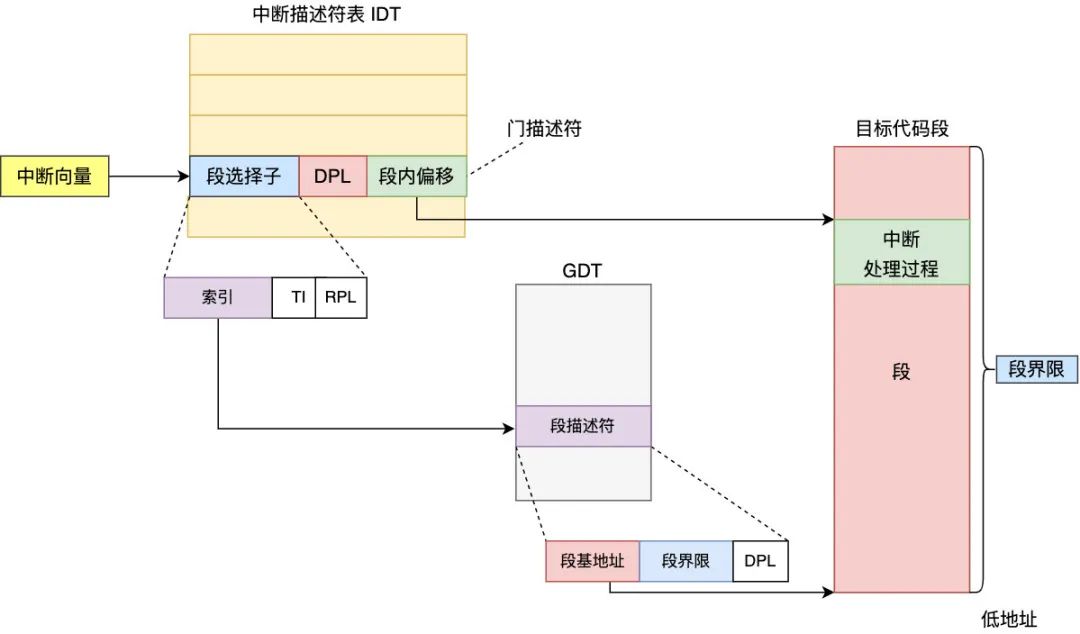
畫外音:上圖中門描述符和段描述符只畫出了關(guān)鍵的幾個字段,省略了其它次要字段
當(dāng)然了,不是隨便發(fā)一個中斷向量都能被執(zhí)行,只有滿足一定條件的中斷才允許被普通的應(yīng)用程序調(diào)用,從發(fā)出軟件中斷再到執(zhí)行中斷對應(yīng)的代碼段會做如下的檢查
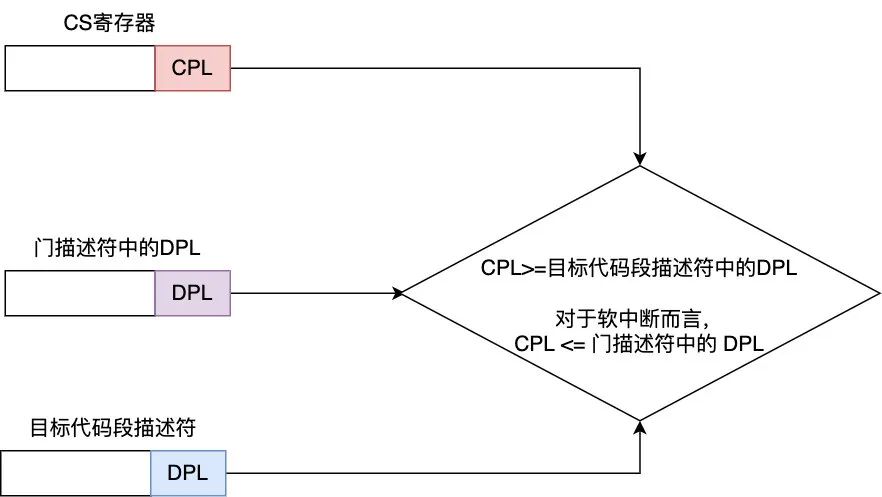
一般應(yīng)用程序發(fā)出軟件中斷對應(yīng)的向量號是大家熟悉的 int 0x80(int 代表 interrupt),它的門描述符中的 DPL 為 3,所以能被所有的用戶程序調(diào)用,而它對應(yīng)的目標(biāo)代碼段描述符中的 DPL 為 0,所以當(dāng)通過中斷門檢查后(即 CPL <= 門描述符中的 DPL 成立),CPU 就會將 CS 寄存器中的 RPL(3) 替換為目標(biāo)代碼段描述符的 DPL(0),替換后的 CPL 也就變成了 0,通過這種方式完成了從用戶態(tài)到內(nèi)核態(tài)的替換,當(dāng)中斷代碼執(zhí)行后執(zhí)行 iret 指令又會切換回用戶態(tài)
另外當(dāng)執(zhí)行中斷程序時,還需要首先把當(dāng)前用戶進(jìn)程中對應(yīng)的堆棧,返回地址等信息,以便切回到用戶態(tài)時能恢復(fù)現(xiàn)場
可以看到 int 80h 這種軟件中斷的執(zhí)行又是檢查特權(quán)級,又是從用戶態(tài)切換到內(nèi)核態(tài),又是保存寄存器的值,可謂是非常的耗時,光看一下以下圖示就知道像 int 0x80 這樣的軟件中斷開銷是有多大了
調(diào)用")
所以后來又開發(fā)出了 SYSENTER/SYSCALL 這樣快速系統(tǒng)調(diào)用的指令,它們?nèi)∠藱?quán)限檢查,也不需要在中斷描述表(Interrupt Descriptor Table、IDT)中查找系統(tǒng)調(diào)用對應(yīng)的執(zhí)行過程,也不需要保存堆棧和返回地址等信息,而是直接進(jìn)入CPL 0,并將新值加載到與代碼和堆棧有關(guān)的寄存器當(dāng)中(cs,eip,ss 和 esp),所以極大地提升了性能
分段內(nèi)存的優(yōu)缺點(diǎn)
使用了保護(hù)模式后,程序員就可以在代碼中使用了段選擇子:段偏移量的方式來尋址,這不僅讓多進(jìn)程運(yùn)行成為了可能,而且也解放了程序員的生產(chǎn)力,我們完全可以認(rèn)為程序擁有所有的內(nèi)存空間(虛擬空間),因為段選擇子是由操作系統(tǒng)分配的,只要操作系統(tǒng)保證不同進(jìn)程的段的虛擬空間映射到不同的物理空間上,不要重疊即可,也就是說雖然各個程序的虛擬空間是一樣的,但由于它們映射的物理地址是不同且不重疊的,所以是能正常工作的,但是為了方便映射,一般要求在物理空間中分配的段是連續(xù)的(這樣只要維護(hù)映射關(guān)系的起始地址和對應(yīng)的空間大小即可)
存管理-虛擬空間與實際物理內(nèi)存的映射")
但段式內(nèi)存管理缺點(diǎn)也很明顯:內(nèi)存碎片可能很大,舉個例子
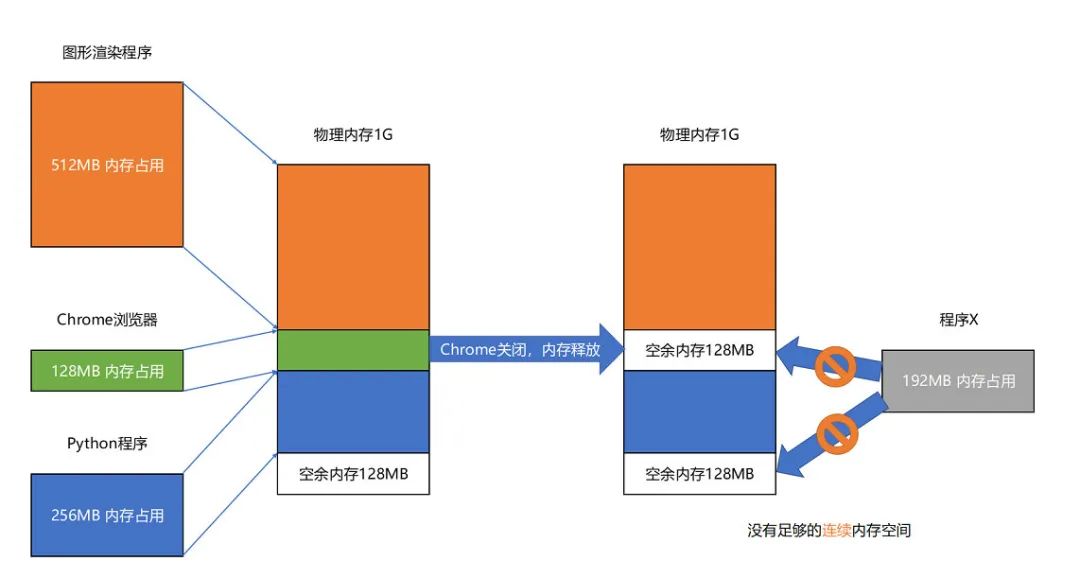
如上圖示,連續(xù)加載了三個程序到內(nèi)存中,如果把 Chrome 關(guān)閉了,此時內(nèi)存中有兩段 128 M的空閑內(nèi)存,但如果此時要加載一個 192 M 的程序 X 卻有心無力了 ,因為段式內(nèi)存需要劃分出一塊連續(xù)的內(nèi)存空間,此時你可以選擇把占 256 M 的 Python 程序先 swap 到磁盤中,然后緊跟著 512 M 內(nèi)存的后面劃分出 256 M 內(nèi)存,再給 Python 程序 swap 到這塊物理內(nèi)存中,這樣就騰出了連續(xù)的 256 M 內(nèi)存,從而可以加載程序 X 了,但這種頻繁地將幾十上百兆內(nèi)存與硬盤進(jìn)行 swap 顯然會對性能造成嚴(yán)重的影響,畢竟誰都知道內(nèi)存和硬盤的讀寫速度可是一個天上一個地上,如果一定要交換,能否每次 swap 得能少一點(diǎn),比如只有幾 K,這樣就能滿足我們的需求,分頁內(nèi)存管理就誕生了
內(nèi)存分頁
1985 年 intel 推出了 32 位處理器 80386,也是首款支持分頁內(nèi)存的 CPU
和分段這樣連續(xù)分配一整段的空間給程序相比,分頁是把整個物理空間切成一段段固定尺寸的大小,當(dāng)然為了映射,虛擬地址也需要切成一段段固定尺寸的大小,這種固定尺寸的大小我們一般稱其為頁,在 LInux 中一般每頁的大小為 4KB,這樣虛擬地址和物理地址就通過頁來映射起來了
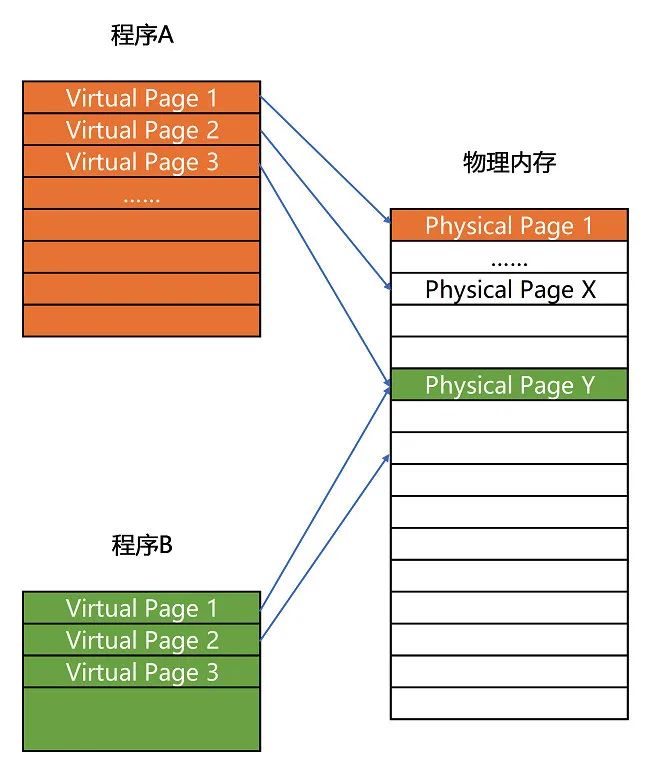
當(dāng)然了這種映射關(guān)系是需要一個映射表來記錄的,這樣才能把虛擬地址映射到物理內(nèi)存中,給定一個虛擬地址,它最終肯定在某個物理頁內(nèi),所以虛擬地址一般由「頁號+頁內(nèi)偏移」組成,而映射表項需要包含物理內(nèi)存的頁號,這樣只要將頁號對應(yīng)起來,再加上頁內(nèi)偏移,即可獲取最終的物理內(nèi)存
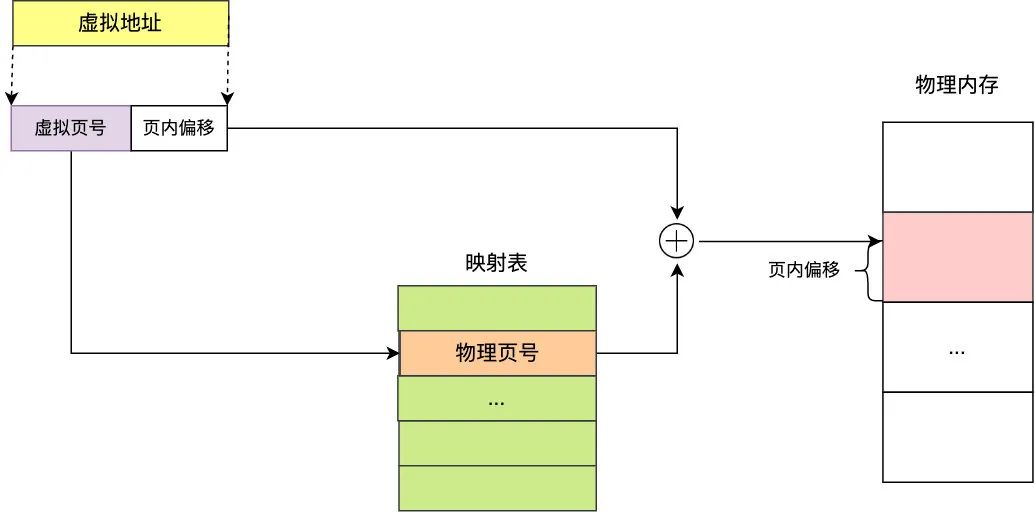
于是問題來了,映射表(也稱頁表)該怎么設(shè)計呢,我們以 32 位虛擬地址位置來看看,假設(shè)頁大小為 4K(2^12),那么至少需要 2^20 也就是 100 多萬個頁表項才能完全覆蓋所有的虛擬地址,假設(shè)每一個頁表項 4 個字節(jié),那就意味著為一個進(jìn)程的虛擬地址就需要準(zhǔn)備 2^20 * 4 B = 4 M 的頁表大小,如果有 100 個進(jìn)程,就意味著光是頁表就要占用 400M 的空間了,這顯然是非常巨大的開銷,那該怎么解決這個頁表空間占用巨大的問題呢
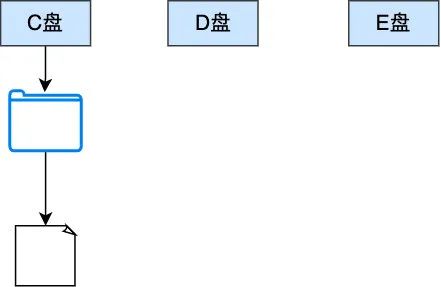
我們注意到現(xiàn)在的做法是一次性為進(jìn)程分配了占用其所有虛擬空間的頁表項,但實際上一個進(jìn)程根本用不到這么巨大的虛擬空間,所以這種分配方式無疑導(dǎo)致很多分配的頁表項白白浪費(fèi)了,那該怎么辦,答案是分級管理,等真正需要分配物理空間的時候再分配,其實大家可以想想我們熟悉的 windows 是怎么分配的,是不是一開始只分配了 C 盤,D盤,E盤,等要存儲的時候,先確定是哪個盤,再在這個盤下分配目錄,然后再把文件存到這個目錄下,并不會一開始就把所有盤的空間給分配完的
同樣的道理,以 32 位虛擬地址為例,我們也可以對頁表進(jìn)行分級管理, 頁表項 2^20 = 2^10 * 2^10 = 1024 * 1024,我們把一個頁表分成兩級頁表,第一級頁表 1024 項,每一項都指向一個包含有 1024 個頁表項的二級頁表
》")
這樣只有在一級頁表中的頁表項被分配的時候才會分配二級頁表,極大的節(jié)省了空間,我們簡單算下,假設(shè) 4G 的虛擬空間進(jìn)程只用了 20%(已經(jīng)很大了,大部分用不到這么多),那么由于一級頁表空間為 1024 *4 = 4K,總的頁表空間為 4K+ 0.2 * 4M = 0.804M,相比于原來的 4M 是個巨大的提升!
那么對于分頁保護(hù)模式又是如何起作用的呢,同樣以 32 位為例,它的二級頁表項(也稱 page table entry)其實是以下結(jié)構(gòu)

注意第三位(也就是 2 對應(yīng)的位置)有個 U/S,它其實就是代表特權(quán)級,表示的是用戶/超級用戶標(biāo)志。為 1 時,允許所有特權(quán)級別的程序訪問;為 0 時,僅允許特權(quán)級為0、1、2(Linux 中沒有 1,2)的程序(也就是內(nèi)核)訪問。頁目錄中的這個位對其所映射的所有頁面起作用
既然分頁這么好,那么分段是不是可以去掉了呢,理論上確實可以,但 Intel 的 CPU 嚴(yán)格執(zhí)行了 backward compatibility(回溯兼容),也就是說最新的 CPU 永遠(yuǎn)可以運(yùn)行針對早期 CPU 開發(fā)的程序,否則早期的程序就得針對新 CPU 架構(gòu)重新開發(fā)了(早期程序針對的是 CPU 的段式管理進(jìn)行開發(fā)),這無論對用戶還是開發(fā)者都是不能接受的(別忘了安騰死亡的一大原因就是由于不兼容之前版本的指令),兼容性雖然意味著每款新的 CPU 都得兼容老的指令,所背的歷史包袱越來越重,但對程序來說能運(yùn)行肯定比重新開發(fā)好,所以既然早期的 CPU 支持段,那么自從 80386 開始的所有 CPU 也都得支持段,而分頁反而是可選的,也就意味著這些 CPU 的內(nèi)存管理都是段頁式管理,邏輯地址要先經(jīng)過段式管理單元轉(zhuǎn)成線性地址(也稱虛擬地址),然后再經(jīng)過頁式管理單元轉(zhuǎn)成物理內(nèi)存,如下

在 Linux 中,雖然也是段頁式內(nèi)存管理,但它統(tǒng)一把 CS,DS,SS,ES 的段基址設(shè)置為了 0,段界限也設(shè)置為了整個虛擬內(nèi)存的長度,所有段都分布在同一個地址空間,這種內(nèi)存模式也叫平坦內(nèi)存模型(flat memory model)
存模型")
我們知道邏輯地址由段選擇子:段內(nèi)偏移地址組成,既然段選擇子指向的段基地址為 0,那也就意味著段內(nèi)偏移地址即為即為線性地址(也就是虛擬地址),由此可知 Linux 中所有程序的代碼都使用了虛擬地址,通過這種方式巧妙地繞開了分段管理,分段只起到了訪問控制和權(quán)限的作用(別忘了各種權(quán)限檢查依賴 DPL,RPL 等特權(quán)字段,特權(quán)極轉(zhuǎn)移也依賴于段選擇子中的 DPL 來切換的)
總結(jié)
看完本文相信大家對實模式,保護(hù)模式,特權(quán)級轉(zhuǎn)換,分段,分頁等概念應(yīng)該有了比較清晰的認(rèn)識。
我們簡單總結(jié)一下,CPU 誕生之間,使用的絕對物理內(nèi)存來尋址(也就是實模式),隨后隨著 8086 的誕生,由于工藝的原因,雖然地址總線是 20 位,但寄存器卻只有 16 位,一個難題出現(xiàn)了,16 位的寄存器該怎么尋址 20 位的內(nèi)存地址呢,于是段的概念被提出了,段的出現(xiàn)雖然解決了尋址問題,但本質(zhì)上 CS << 4 + IP 的尋址方式依然還是絕對物理地址,這樣的話由于地址會互相覆蓋,顯然無法做到多進(jìn)程運(yùn)行,于是保護(hù)模式被提出了,保護(hù)就是為了物理內(nèi)存免受非法訪問,于是用戶空間,內(nèi)核空間,特權(quán)級也被提出來了,段寄存器里保存的不再是段基址,而是段選擇子,由操作系統(tǒng)分配,用戶也無法隨意修改段選擇子,必須通過中斷的形式才能從用戶態(tài)陷入內(nèi)核態(tài),中斷執(zhí)行的過程也需要經(jīng)歷特權(quán)級的檢查,檢查通過之后特權(quán)級從 3 切換到了 0,于是就可以放心合法的執(zhí)行特權(quán)指令了。可以看到,通過操作系統(tǒng)分配段選擇子+中斷的方式內(nèi)存得到了有效保護(hù),但是分段可能造成內(nèi)存碎片過大以致頻繁 swap 會影響性能的問題,于是分頁出現(xiàn)了,保護(hù)模式+分頁終于可以讓多進(jìn)程,高效調(diào)度成為了可能
福利環(huán)節(jié)
最后給大家推薦一本有趣的Java入門書——《漫畫 Java》。本書以漫畫的形式介紹了 Java 語言的相關(guān)知識。全書共20章,書中首先介紹了 Java 語言的歷史、特點(diǎn)、開發(fā)環(huán)境、運(yùn)算符、數(shù)據(jù)類型、數(shù)組、字符串、判斷語句、循環(huán)語句等基礎(chǔ)知識,接著討論了函數(shù)式編程、類與對象、異常、文件操作、集合、圖形用戶界面、網(wǎng)絡(luò)通信、多線程等進(jìn)階內(nèi)容,最后通過一個案例向大家介紹如何爬取圖片。本書適合對 Java 感興趣的零基礎(chǔ)初學(xué)者閱讀,包括對編程感興趣的中小學(xué)生和想從事編程工作的人員。想入門 Java 的小伙伴推薦給大家!本書詳情:https://u.jd.com/lMumkTt

我會在留言區(qū)選中三位朋友(個人認(rèn)為比較用心的三位位),并且明早 9:00 會在我的朋友圈點(diǎn)贊抽獎送出三本(歡迎大家加我的微信: becomecxuan)
參考
CPU 是怎么執(zhí)行指令的 https://z.itpub.net/article/detail/1468ED259C713472E41638CE8890DA5C
好家伙!原來硬中斷就是這樣的:(https://mp.weixin.qq.com/s/OWrw6VNTNVZRj5lJqEgY3w)
RPL 的故事 https://string.quest/read/15152681
RPL,DPL 區(qū)別 https://stackoverflow.com/questions/36617718/difference-between-dpl-and-rpl-in-x86