
超越所有開源編程大模型和GPT-3.5!華為發(fā)布150億參數(shù)規(guī)模的編程大模型PanGu-Coder2
華為盤古大模型一直是國內(nèi)大模型領(lǐng)域比較早的先行者,不過由于該模型并不針對個(gè)人開放,因此很少有人可以體驗(yàn)到該模型的效果。但是,盤古大模型一直在不斷發(fā)展。2023年7月27日,華為發(fā)布最新的論文,展示了新一代盤古大模型的編程能力。該模型名字為PanGu-Coder2,論文的數(shù)據(jù)顯示該模型目前超越所有開源編程大模型的效果,也超過GPT-3.5,接近GPT-4。

編程大模型再度擴(kuò)張版圖~
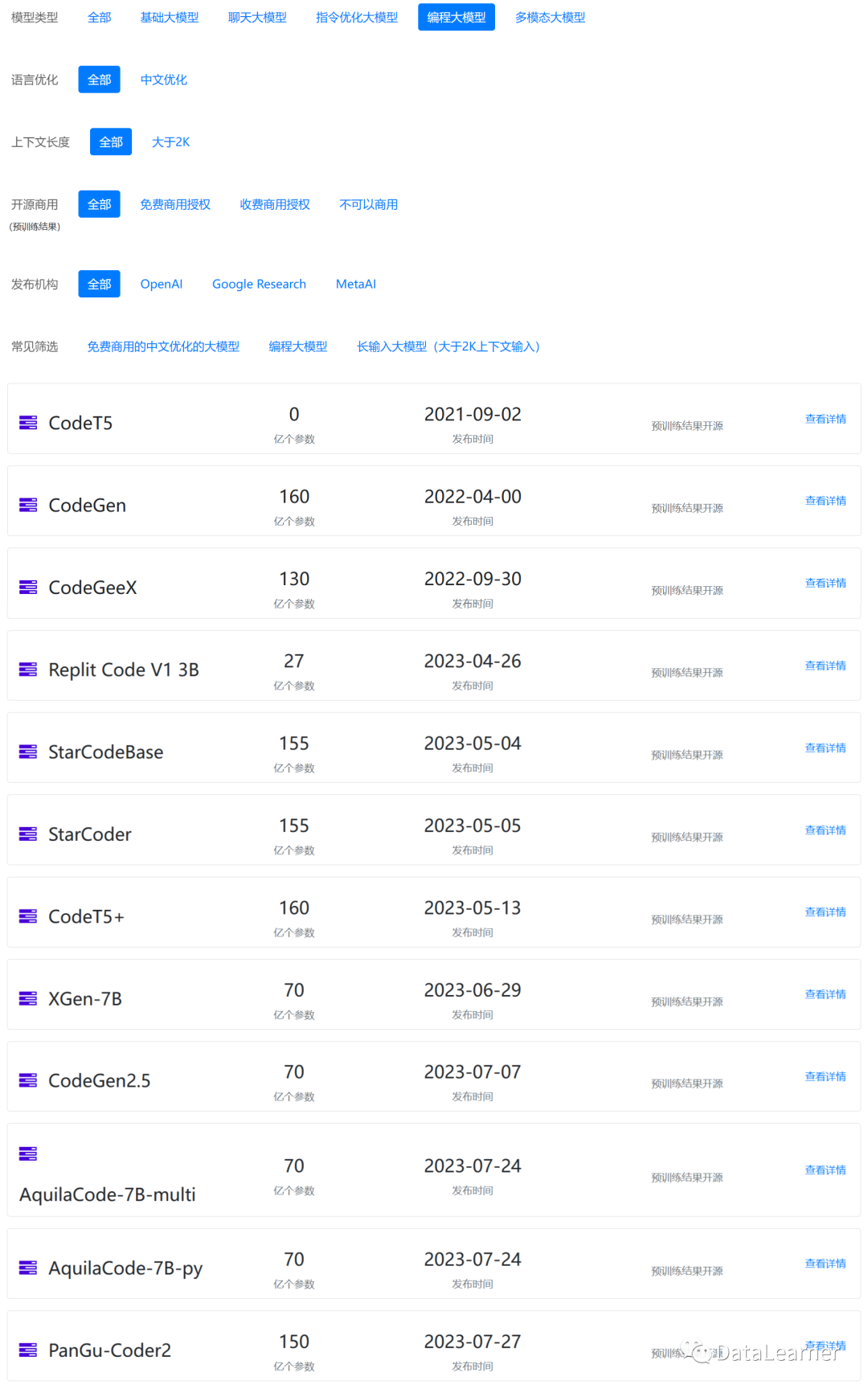
上圖來自DataLearner模型信息卡篩選列表:
https://www.datalearner.com/ai-models/pretrained-models?&aiArea=1002&language=-1&contextLength=-1&openSource=-1&publisher=-1
當(dāng)前編程大模型的問題
強(qiáng)化學(xué)習(xí)是當(dāng)前訓(xùn)練編程大模型最常用的方法之一,它可以為模型設(shè)定特定的獎(jiǎng)勵(lì)函數(shù)以引導(dǎo)大模型可以生成更好的代碼。然而現(xiàn)有強(qiáng)化學(xué)習(xí)方法在代碼大型語言模型(LLMs)中有很大的局限性。華為認(rèn)為現(xiàn)有的基于強(qiáng)化學(xué)習(xí)的方法通常根據(jù)編譯器、調(diào)試器、執(zhí)行器和測試用例的反饋信號(hào)設(shè)計(jì)價(jià)值/獎(jiǎng)勵(lì)函數(shù),但這導(dǎo)致了三個(gè)限制:
直接將測試結(jié)果作為獎(jiǎng)勵(lì)提供給基礎(chǔ)模型的改進(jìn)有限。
采用的強(qiáng)化學(xué)習(xí)算法(如 PPO)實(shí)現(xiàn)復(fù)雜,且難以在大型語言模型上進(jìn)行訓(xùn)練。
在訓(xùn)練模型時(shí)運(yùn)行測試是耗時(shí)的。
因此,華為提出了 RRTF(RankResponses to align Test&Teacher Feedback)框架,以解決現(xiàn)有基于強(qiáng)化學(xué)習(xí)的方法的問題,并進(jìn)一步發(fā)掘代碼 LLM 的潛力。RRTF 框架是一種新的工作,成功地將自然語言 LLM 對齊技術(shù)應(yīng)用于代碼 LLM。與之前的工作(如 CodeRL 和 RLTF)不同,RRTF 框架遵循 RLHF(Reinforcement Learning from Human Feedback)的思想,但使用排名響應(yīng)作為反饋,而不是獎(jiǎng)勵(lì)模型的絕對值。
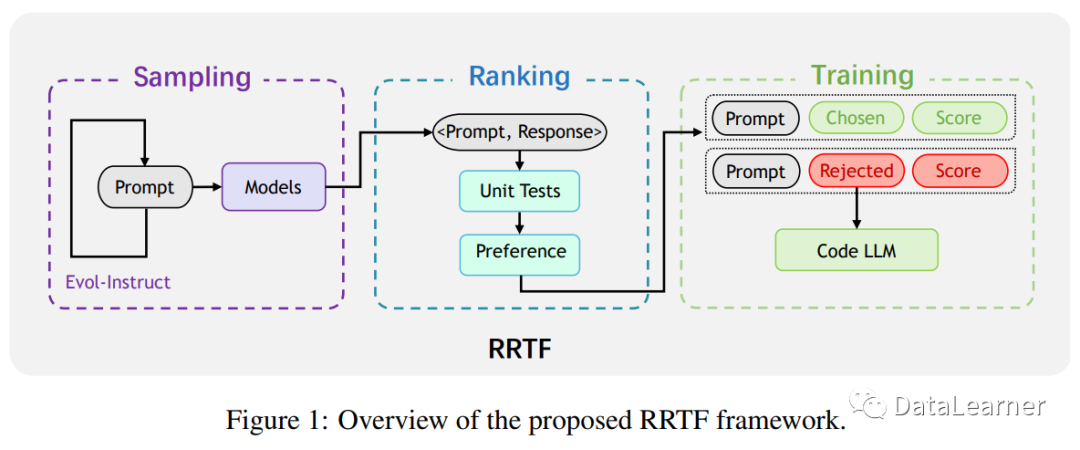
作為概念的證明,華為在 StarCoder 15B 上應(yīng)用了 RRTF,并訓(xùn)練出PanGu-Coder2。
PanGu-Coder2簡介和訓(xùn)練細(xì)節(jié)
PanGu-Coder2 是一種大型語言模型,專門用于代碼生成。它基于RRTF (RankResponses to align Test&Teacher Feedback) 的新框架,該框架結(jié)合了多種先進(jìn)技術(shù),包括指令調(diào)整、Evol-Instruct 方法和強(qiáng)化學(xué)習(xí)。RRTF 的核心思想是通過使用測試信號(hào)和人類偏好作為反饋來對響應(yīng)進(jìn)行排名,從而引導(dǎo)模型生成更高質(zhì)量的代碼。
在模型架構(gòu)方面,PanGu-Coder2 是一個(gè)基于Decoder的 Transformer,具有 Multi-Query-Attention 和學(xué)習(xí)的絕對位置嵌入。同時(shí),它使用了 FlashAttention來減少計(jì)算和內(nèi)存使用量,因此模型的最大長度可以擴(kuò)展到 8192。模型的詳細(xì)超參數(shù)如下:
隱藏層大小:6144
最大長度:8192
注意力頭的數(shù)量:48
Transformer 隱藏層的數(shù)量:40
在訓(xùn)練過程中,PanGu-Coder2 使用了 Evol-Instruct 技術(shù)來構(gòu)建訓(xùn)練語料庫,這種技術(shù)可以通過深度演化來迭代地從 Alpaca 20K 數(shù)據(jù)集中獲取新的編程問題。通過這些問題,模型可以從不同的模型中采樣答案。總的來說,他們收集了一個(gè)包含 100K 編程問題及其答案的初始語料庫,這些問題和答案被稱為指令和解決方案對。此外,他們還對初始語料庫進(jìn)行了數(shù)據(jù)預(yù)處理,并將語料庫的大小減少到了 68K。
在訓(xùn)練過程中,PanGu-Coder2 使用了 RRTF 框架,該框架可以根據(jù)人類的偏好對來自不同來源的響應(yīng)進(jìn)行排名,并通過排名損失函數(shù)對模型進(jìn)行調(diào)整。與 RLHF 相比,RRTF 可以有效地將語言模型的輸出概率與人類的偏好對齊,只需要在調(diào)整期間使用 1-2 個(gè)模型,而且在實(shí)現(xiàn)、超參數(shù)調(diào)整和訓(xùn)練方面比 PPO 更簡單。
PanGu-Coder2的評(píng)估結(jié)果以及與清華大學(xué)CodeGeeX2等模型對比
說了這么多還是看效果,我們最主要的是看一下HumanEval評(píng)價(jià),HumanEval 是 OpenAI 提出的一種評(píng)估大型語言模型編程能力的基準(zhǔn)測試。這個(gè)基準(zhǔn)測試包含了 164 個(gè)編程問題,這些問題都是由經(jīng)驗(yàn)豐富的程序員手動(dòng)編寫的,涵蓋了各種編程概念,包括數(shù)據(jù)結(jié)構(gòu)、算法、控制流、字符串處理等。
在 HumanEval 中,模型的任務(wù)是生成 Python 代碼來解決給定的編程問題。然后,這些生成的代碼會(huì)被運(yùn)行并與預(yù)期的輸出進(jìn)行比較,以確定代碼是否正確。模型的性能是根據(jù)其在這些問題上的通過率來評(píng)估的,即生成的代碼能夠成功解決問題的比例。
論文中給出的評(píng)估結(jié)果如下(HumanEval,這里的k=1表示生成第一份解決方案解決問題的指標(biāo))
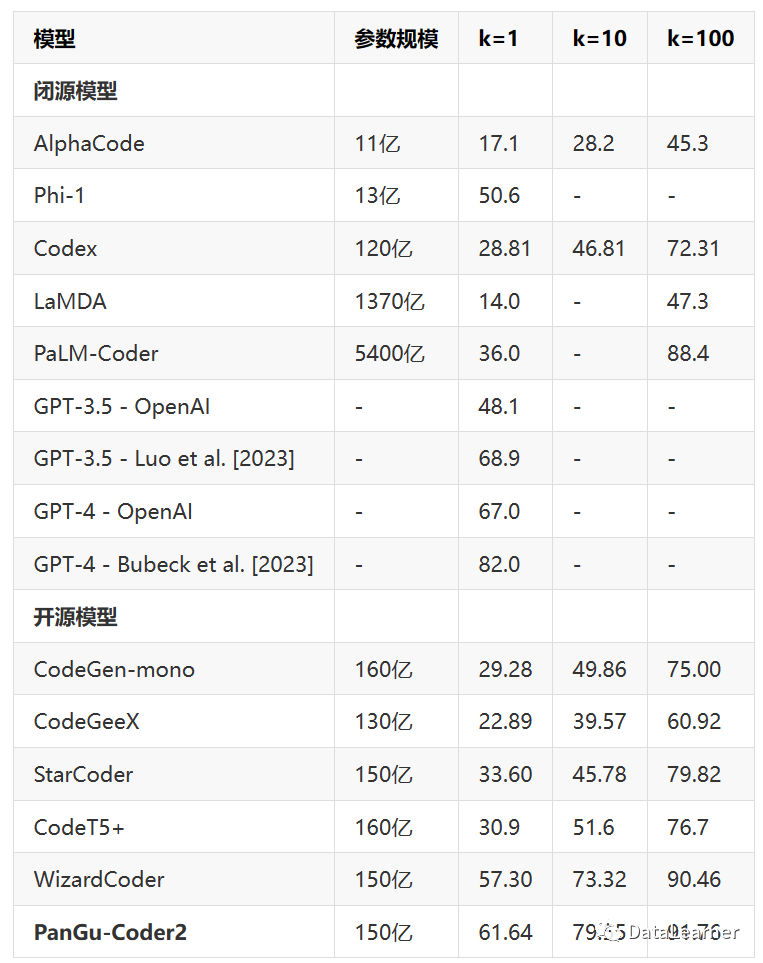
注意,這里像GPT-3.5和GPT-4有兩個(gè)結(jié)果,原因是一個(gè)來自O(shè)penAI官方數(shù)據(jù),一個(gè)是論文的數(shù)據(jù)。可以看到,目前Pass@ 1的測試最強(qiáng)的是GPT-4 (Bubeck),這是來自于微軟的測試結(jié)果(論文名: Sparks of Artificial General Intelligence: Early experiments with GPT-4.)。而微軟官方測試的GPT-3.5和GPT-4水平則是48.1和67。
PanGu-Coder2得分61.64,開源模型第一,比原模型中,OpenAI官方數(shù)據(jù)超過GPT-3.5,接近GPT-4。第三方測試中則接近GPT-3.5,低于GPT-4。
再來看一下前幾天智譜AI發(fā)布的基于ChatGLM2-6B微調(diào)的編程大模型CodeGeeX2-6B和北京智源人工智能研究院發(fā)布的AquilaCode對比:
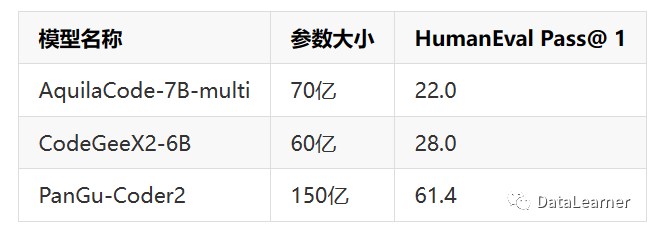
也是遠(yuǎn)超這2個(gè)模型的。
AquilaCode介紹:智源人工智能研究院開源可商用的編程大模型:悟道·天鷹AquilaCode系列,超過清華大學(xué)CodeGeeX - https://www.datalearner.com/blog/1051690174323553CodeGeeX2-6B介紹:智譜AI發(fā)布第二代CodeGeeX編程大模型:CodeGeeX2-6B,最低6GB顯存可運(yùn)行,基于ChatGLM2-6B微調(diào) - https://www.datalearner.com/blog/1051690265117179
PanGu-Coder2的運(yùn)行資源要求
論文中也給出了PanGu-Code2推理的資源要求和速度:
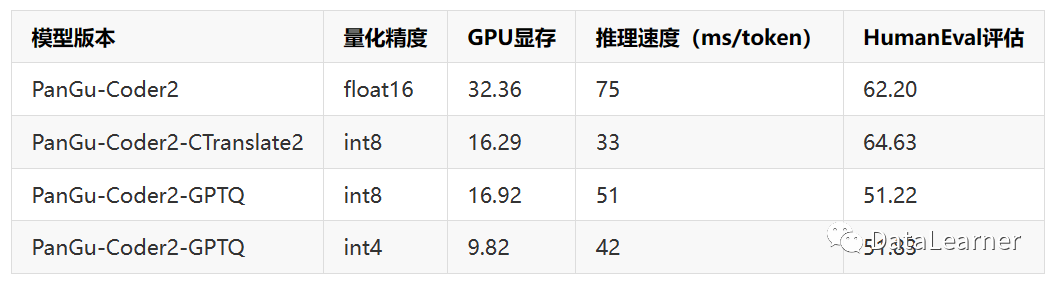
可以看到,完整的PanGu-Coder2模型的顯存要求32.36GB,推理速度是每個(gè)token要75毫秒,也就是每秒13個(gè)tokens左右。而最低的INT4量化版本則只需要10GB顯存左右可以運(yùn)行,速度是每秒23個(gè)tokens左右!還是相當(dāng)吸引人的。
PanGu-Coder2總結(jié)
PanGu-Coder2的模型已經(jīng)在DataLearner模型信息卡更新:https://www.datalearner.com/ai-models/pretrained-models/PanGu-Coder2
不過,這個(gè)模型并不是開源的,也沒有代碼或者預(yù)訓(xùn)練結(jié)果,非常可惜~
號(hào)外!