
RabbitMQ和Kafka到底怎么選?
來源:cnblogs.com/haolujun/p/9632835.html
前言
開源社區(qū)有好多優(yōu)秀的隊列中間件,比如RabbitMQ和Kafka,每個隊列都貌似有其特性,在進行工程選擇時,往往眼花繚亂,不知所措。對于RabbitMQ和Kafka,到底應該選哪個?
RabbitMQ架構
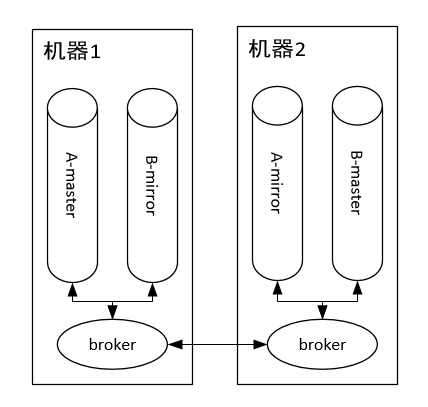
隊列消費

隊列生產(chǎn)
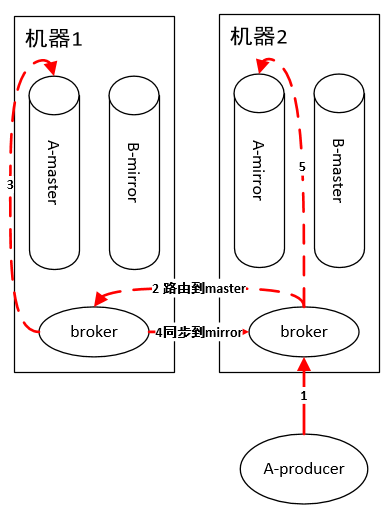
所以,到這里小伙伴們就可以看到 RabbitMQ的不足:由于master queue單節(jié)點,導致性能瓶頸,吞吐量受限。雖然為了提高性能,內(nèi)部使用了Erlang這個語言實現(xiàn),但是終究擺脫不了架構設計上的致命缺陷。
Kafka
另外,關注互聯(lián)網(wǎng)架構師公眾號,回復“面試”,送你一份面試題寶典!
這里面的每個master queue 在Kafka中叫做Partition,即一個分片。一個隊列有多個主分片,每個主分片又有若干副分片做備份,同步機制類似于RabbitMQ。
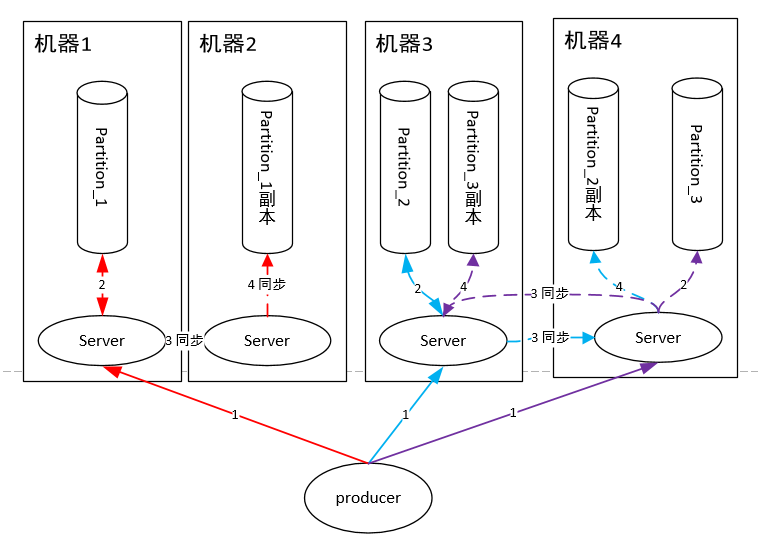
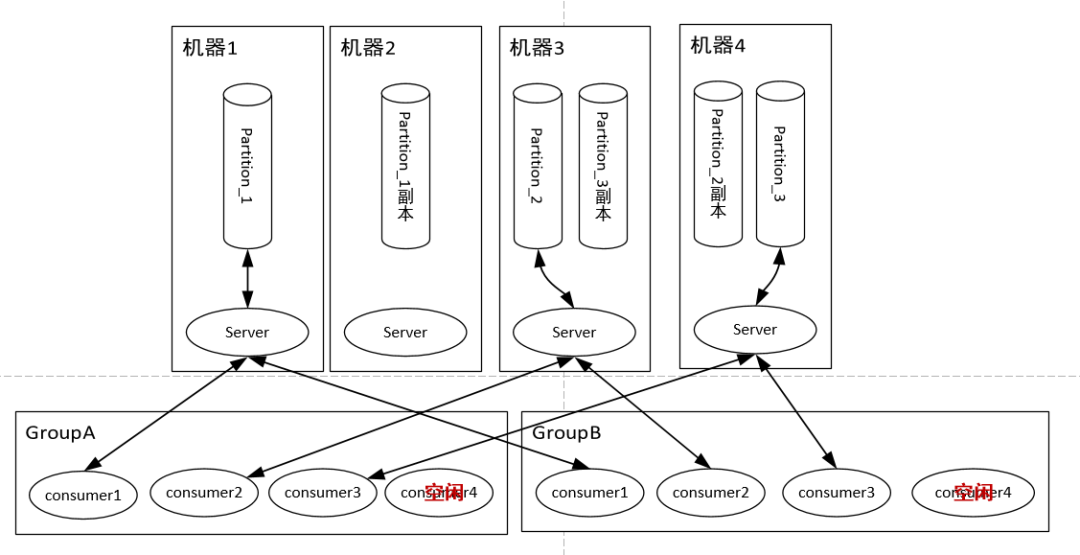
隊列讀同樣是讀主分片,并且為了優(yōu)化性能,消費者與主分片有一一的對應關系,如果消費者數(shù)目大于分片數(shù),則存在某些消費者得不到消息。
由此可見,Kafka絕對是為了高吞吐量設計的,比如設置分片數(shù)為100,那么就有100臺機器去扛一個Topic的流量,當然比RabbitMQ的單機性能好。
總結
本文只做了Kafka和RabbitMQ的對比,但是開源隊列豈止這兩個,ZeroMQ,RocketMQ,JMQ等等,時間有限也就沒有細看,故不在本文比較范圍之內(nèi)。
所以,別再被這些五花八門的隊列迷惑了,從架構上找出關鍵差別,并結合自己的實際需求(比如本文就只單單從吞吐量一個需求來考察)輕輕松松搞定選型。最后總結如下:
吞吐量較低:Kafka和RabbitMQ都可以。 吞吐量高:Kafka。
本文內(nèi)容參考自RabbitMQ和KafKa官方文檔,所以真要搞懂一個中間件的原理最好去看官方文檔,文檔里面有詳細的設計方案,我們可以自己進行設計方案的對比,從而找出符合自己實際情況的中間件。