
信用卡申請預測案例
信用卡業(yè)務,是各大銀行的核心業(yè)務之一。銀行收到大量信用卡申請,其中許多人因為各種原因而被拒絕,比如高的個人信用貸款余額,低的收入水平或者過高的個人征信報告查詢次數(shù)等。
銀行工作人員手動調(diào)研和分析這些個人申請資料很普遍,但是,容易出錯,而且也很耗時(時間就是金錢,效率就是生命)。幸運的是,這項任務可以通過機器學習實現(xiàn)自動化,在風險可控的前提下,極大地提升了工作的效率和產(chǎn)能。
在本案例中,將使用機器學習技術(shù)構(gòu)建一個自動信用卡申請預測模型,并利用模型去判斷那些人信用卡申請可以批準,就像真正銀行做的那樣。
學習和實踐本案例,你可以得到:
信用卡申請是個什么問題?
數(shù)據(jù)集如何整理?
模型如何構(gòu)建?
模型如何應用?
一、業(yè)務理解,
問題定義
面對大量的信用卡申請資料,如何根據(jù)這些資料的信息和關(guān)聯(lián)的其它信息,高效地對信用卡申請做出是否批準的判斷,并兼顧產(chǎn)能和風險的平衡,即在風控原則約束的前提下,提升效能。
二、數(shù)據(jù)理解,
數(shù)據(jù)畫像
本案例的數(shù)據(jù)集來自UCI平臺提供的一份公開信用卡申請數(shù)據(jù)集。數(shù)據(jù)集的下載和數(shù)據(jù)集結(jié)構(gòu)以及元數(shù)據(jù)(數(shù)據(jù)的數(shù)據(jù))描述請訪問如下鏈接:
http://archive.ics.uci.edu/ml/datasets/credit+approval
因為數(shù)據(jù)集涉及到個人敏感信息,所以數(shù)據(jù)集的貢獻者對特征名做了匿名化處理以實現(xiàn)數(shù)據(jù)保密。數(shù)據(jù)集的結(jié)構(gòu),可以在后面的代碼里了解。
1、導入Python庫
import?numpy?as?np
import?pandas?as?pd?
import?matplotlib.pyplot?as?plt
from?sklearn.preprocessing?import?LabelEncoder
from?sklearn.preprocessing?import?MinMaxScaler
from?sklearn.model_selection?import?train_test_split
from?sklearn.linear_model?import?LogisticRegression
from?sklearn.metrics?import?confusion_matrix
import?warnings
warnings.filterwarnings('ignore')
%matplotlib?inline
2、數(shù)據(jù)畫像
cc_apps?=?pd.read_csv("datasets/cc_approvals.data",?header=None)
print(cc_apps.shape)
print(cc_apps.head())
print(cc_apps.dtypes)
print(cc_apps.describe().T)
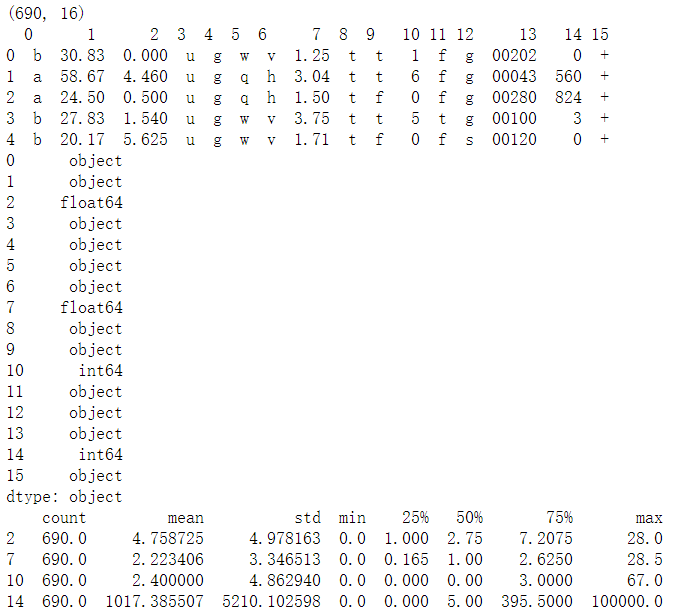
數(shù)據(jù)集包括690個觀察,16個特征,特征集都做了匿名化處理。這里有篇博客(詳見參考資料)對數(shù)據(jù)集的特征含義做了可能性的描述,依次是性別、年齡、債務、婚姻、銀行客戶、教育層次、種族、工作年限、先前違約、職業(yè)、信用評分、駕駛證、公民、郵政編碼、收入和申請狀態(tài)。通過數(shù)據(jù)畫像的結(jié)果,可以發(fā)現(xiàn)數(shù)據(jù)集包括數(shù)值型和非數(shù)值型特征,這個問題我們在數(shù)據(jù)準備階段會做相應處理。
三、數(shù)據(jù)準備,
數(shù)據(jù)整理
數(shù)據(jù)集包括數(shù)值型和非數(shù)值型特征,數(shù)據(jù)集跨度范圍不一致,數(shù)據(jù)集包括一些用?符號表示數(shù)據(jù)缺失的情況。這些問題,我們都要解決。
首先,做缺失值的檢測和處理。為什么要做這個事情?一方面,可以提升模型的性能,通常情況不建議直接粗暴地刪除含有缺失值的變量或者樣本,因為這樣容易丟失信息;另一方面,有很多算法,不支持數(shù)據(jù)的缺失的情況。如何處理缺失值。本案例中,數(shù)值型變量采用均值插補法;非數(shù)值型變量采用眾數(shù)插補法。
3、數(shù)據(jù)缺失值標記,發(fā)現(xiàn)和處理
cc_apps?=?cc_apps.replace("?",np.NaN)
cc_apps?=?cc_apps.fillna(cc_apps.mean())
print(cc_apps.info())
for?col?in?cc_apps.columns:
????if?cc_apps[col].dtypes?==?'object':
????????cc_apps[col]?=?cc_apps[col].fillna(cc_apps[col].value_counts().index[0])
???????
print(cc_apps.isnull().values.sum())

4、非數(shù)值型特征處理--標簽編碼
接下來,做非數(shù)值型特征處理。為什么要對非數(shù)值型特征做處理和轉(zhuǎn)換?一方面,可以提升計算的速度;另一方面,則是很多算法必須要要求數(shù)據(jù)集為數(shù)值型格式,比方說xgboost算法。如何做非數(shù)值型特征處理?本案例,采用標簽編碼的方法。
le?=?LabelEncoder()
for?col?in?cc_apps.columns:
????if?cc_apps[col].dtype=='object':
????????cc_apps[col]=le.fit_transform(cc_apps[col])
5、特征篩選和縮放
第三,做特征篩選和縮放。根據(jù)特征的含義和所要解決問題,基于領域知識刪除不需要特征,例如駕駛證和郵政編碼,同時,把特征縮放到一致范圍。
#?刪除不需要的變量
#?同時對特征做縮放處理
cc_apps?=?cc_apps.drop([cc_apps.columns[10],cc_apps.columns[13]],?axis=1)
cc_apps?=?cc_apps.values
X,y?=?cc_apps[:,0:13],?cc_apps[:,13]
scaler?=?MinMaxScaler(feature_range=(0,1))
rescaledX?=?scaler.fit_transform(X)四、模型架構(gòu),
模型創(chuàng)建
把數(shù)據(jù)集整理好后,接下來我們做模型創(chuàng)建的事情,首先,把數(shù)據(jù)集劃分為訓練集和測試集,然后利用訓練集來構(gòu)建模型,利用測試集來評價模型的性能。因為本案例的問題是一個典型的二元分類問題,我們假設數(shù)據(jù)集里面特征與目標變量有一定的關(guān)系,我們選擇簡單常用和可解釋的邏輯回歸模型來創(chuàng)建模型。
6、數(shù)據(jù)集劃分
X_train,?X_test,?y_train,?y_test?=?train_test_split(rescaledX,
????????????????????????????????????????????????????y,
????????????????????????????????????????????????????test_size=0.33,
????????????????????????????????????????????????????random_state=42)
6、模型創(chuàng)建
#?模型創(chuàng)建
logreg?=?LogisticRegression()
logreg.fit(X_train,y_train)
五、模型評價,
性能分析
把創(chuàng)建好的模型,在測試數(shù)據(jù)集上做模型的性能分析。我們采用模型的準確率和混淆矩陣來評價模型的性能。
y_pred?=?logreg.predict(X_test)
print("模型的準確率:?%.3f"?%?logreg.score(X_test,?y_test))
#?混淆矩陣
confusion_matrix(y_test,?y_pred)

六、模型應用,
指導行動
針對新的的數(shù)據(jù)集,按著模型構(gòu)建前的數(shù)據(jù)加工邏輯(缺失值處理+標簽編碼+數(shù)據(jù)縮放),做好數(shù)據(jù)處理后,然后利用構(gòu)建好的模型對新數(shù)據(jù)集做預測,對預測的結(jié)果做應用,以指導信用卡申請的審批工作。
總結(jié)
本案例對信用卡申請是否批準的問題,利用機器學習的方法做了解答,以實現(xiàn)從人工審批過度到自動化審批的操作流程,從而提升審批的效率和客觀一致性。
本案例還有很多地方值得進一步深入思考和挖掘。比方說,文章的標準化是對所有數(shù)據(jù)集進行處理,這樣是否存在信息泄露問題,有待進一步驗證;邏輯回歸模型的超參數(shù)使用了默認值的設定,根據(jù)實際問題,是否存有最佳的超參數(shù),也需要做相關(guān)的測試工作;模型預測的輸出結(jié)果是一個介于0~1的值,然后根據(jù)臨界點做比較來標記是否批準,而銀行的實際應用中,需要把這種概率映射為一種分數(shù),利用這種分數(shù)來更好地指導業(yè)務的行動等。
關(guān)于本案例,你有什么見解或者疑問,請留言或者加入Python群做討論。
附錄:案例完整代碼(需要數(shù)據(jù)集的朋友可以添加我的個人微信獲取或者從Kaggle平臺下載獲取)
import?numpy?as?np
import?pandas?as?pd?
import?matplotlib.pyplot?as?plt
from?sklearn.preprocessing?import?LabelEncoder
from?sklearn.preprocessing?import?MinMaxScaler
from?sklearn.model_selection?import?train_test_split
from?sklearn.linear_model?import?LogisticRegression
from?sklearn.metrics?import?confusion_matrix
import?warnings
warnings.filterwarnings('ignore')
%matplotlib?inline
cc_apps?=?pd.read_csv("datasets/cc_approvals.data",?header=None)
print(cc_apps.shape)
print(cc_apps.head())
print(cc_apps.dtypes)
print(cc_apps.describe().T)
cc_apps?=?cc_apps.replace("?",np.NaN)
cc_apps?=?cc_apps.fillna(cc_apps.mean())
print(cc_apps.info())
for?col?in?cc_apps.columns:
????if?cc_apps[col].dtypes?==?'object':
????????cc_apps[col]?=?cc_apps[col].fillna(cc_apps[col].value_counts().index[0])
???????
print(cc_apps.isnull().values.sum())
le?=?LabelEncoder()
for?col?in?cc_apps.columns:
????if?cc_apps[col].dtype=='object':
????????cc_apps[col]=le.fit_transform(cc_apps[col])
????????
????????
cc_apps?=?cc_apps.drop([cc_apps.columns[10],cc_apps.columns[13]],?axis=1)
cc_apps?=?cc_apps.values
X,y?=?cc_apps[:,0:13],?cc_apps[:,13]
scaler?=?MinMaxScaler(feature_range=(0,1))
rescaledX?=?scaler.fit_transform(X)
X_train,?X_test,?y_train,?y_test?=?train_test_split(rescaledX,
????????????????????????????????????????????????????y,
????????????????????????????????????????????????????test_size=0.33,
????????????????????????????????????????????????????random_state=42)
????????????????????????????????????????????????????
????????????????????????????????????????????????????
#?模型創(chuàng)建
logreg?=?LogisticRegression()
logreg.fit(X_train,y_train)
y_pred?=?logreg.predict(X_test)
print("模型的準確率:?%.3f"?%?logreg.score(X_test,?y_test))
#?混淆矩陣
confusion_matrix(y_test,?y_pred)
參考資料
1、案例的數(shù)據(jù)集的結(jié)構(gòu)描述
http://rstudio-pubs-static.s3.amazonaws.com/73039_9946de135c0a49daa7a0a9eda4a67a72.html
2、LabelEncoder和OneHotEncoder
https://blog.csdn.net/quintind/article/details/79850455
3、邏輯回歸算法
https://ml-cheatsheet.readthedocs.io/en/latest/logistic_regression.html
4、混淆矩陣
https://www.dataschool.io/simple-guide-to-confusion-matrix-terminology/
5、如何處理缺失值
https://machinelearningmastery.com/handle-missing-data-python/
公眾號推薦
數(shù)據(jù)思踐
數(shù)據(jù)思踐公眾號記錄和分享數(shù)據(jù)人思考和踐行的內(nèi)容與故事。
Python語言群
誠邀您加入
《數(shù)據(jù)科學與人工智能》公眾號推薦朋友們學習和使用Python語言,需要加入Python語言群的,請掃碼加我個人微信,備注【姓名-Python群】,我誠邀你入群,大家學習和分享。