
MySQL批量插入數(shù)據(jù)的四種方案(性能測試對比)
來源:blog.csdn.net/a18505947362/article/details/123667215
本文記錄個人使用MySQL插入大數(shù)據(jù)總結較實用的方案,通過對常用插入大數(shù)據(jù)的4種方式進行測試,即for循環(huán)單條、拼接SQL、批量插入saveBatch()、循環(huán) + 開啟批處理模式,得出比較實用的方案心得。
一、前言
最近趁空閑之余,在對MySQL數(shù)據(jù)庫進行插入數(shù)據(jù)測試,對于如何快速插入數(shù)據(jù)的操作無從下手,在僅1W數(shù)據(jù)量的情況下,竟花費接近47s,實在不忍直視!在不斷摸索之后,整理出一些較實用的方案。
二、準備工作
測試環(huán)境:SpringBoot項目、MyBatis-Plus框架、MySQL8.0.24、JDK13
前提:SpringBoot項目集成MyBatis-Plus上述文章有配置過程,同時實現(xiàn)IService接口用于進行批量插入數(shù)據(jù)操作saveBatch()方法
1、Maven項目中pom.xml文件引入的相關依賴如下
<dependencies>
<!-- SpringBoot Web模塊依賴 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- MyBatis-Plus 依賴 -->
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.3.1</version>
</dependency>
<!-- 數(shù)據(jù)庫連接驅動 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
<!-- 使用注解,簡化代碼-->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
</dependencies>
2、application.yml配置屬性文件內(nèi)容(重點:開啟批處理模式)
server:
# 端口號
port: 8080
# MySQL連接配置信息(以下僅簡單配置,更多設置可自行查看)
spring:
datasource:
# 連接地址(解決UTF-8中文亂碼問題 + 時區(qū)校正)
# (rewriteBatchedStatements=true 開啟批處理模式)
url: jdbc:mysql://127.0.0.1:3306/bjpowernode?useUnicode=true&characterEncoding=UTF-8&serverTimezone=Asia/Shanghai&rewriteBatchedStatements=true
# 用戶名
username: root
# 密碼
password: xxx
# 連接驅動名稱
driver-class-name: com.mysql.cj.jdbc.Driver
3、Entity實體類(測試)
/**
* Student 測試實體類
*
* @Data注解:引入Lombok依賴,可省略Setter、Getter方法
* @author LBF
* @date 2022/3/18 16:06
*/
@Data
@TableName(value = "student")
public class Student {
/** 主鍵 type:自增 */
@TableId(type = IdType.AUTO)
private int id;
/** 名字 */
private String name;
/** 年齡 */
private int age;
/** 地址 */
private String addr;
/** 地址號 @TableField:與表字段映射 */
@TableField(value = "addr_num")
private String addrNum;
public Student(String name, int age, String addr, String addrNum) {
this.name = name;
this.age = age;
this.addr = addr;
this.addrNum = addrNum;
}
}
4、數(shù)據(jù)庫student表結構(注意:無索引)
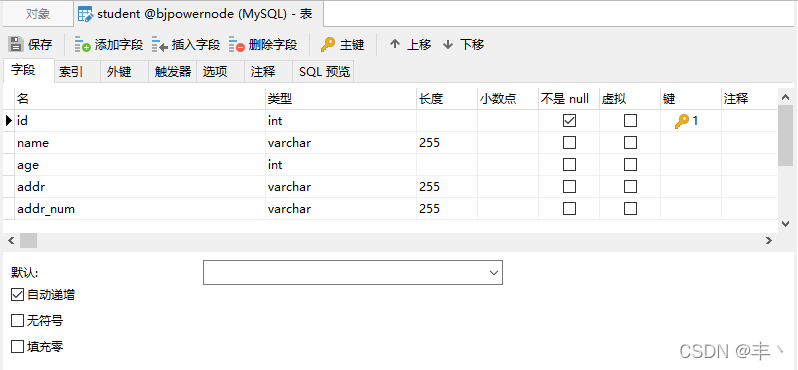
三、測試工作
簡明:完成準備工作后,即對for循環(huán)、拼接SQL語句、批量插入saveBatch()、循環(huán)插入+開啟批處理模式,該4種插入數(shù)據(jù)的方式進行測試性能。
注意:測試數(shù)據(jù)量為5W、單次測試完清空數(shù)據(jù)表(確保不受舊數(shù)據(jù)影響)
以下測試內(nèi)容可能受測試配置環(huán)境、測試規(guī)范和數(shù)據(jù)量等諸多因素影響,讀者可自行結合參考進行測試
1、for循環(huán)插入(單條)(總耗時:177秒)
總結:測試平均時間約是177秒,實在是不忍直視(捂臉),因為利用for循環(huán)進行單條插入時,每次都是在獲取連接(Connection)、釋放連接和資源關閉等操作上,(如果數(shù)據(jù)量大的情況下)極其消耗資源,導致時間長。
@GetMapping("/for")
public void forSingle(){
// 開始時間
long startTime = System.currentTimeMillis();
for (int i = 0; i < 50000; i++){
Student student = new Student("李毅" + i,24,"張家界市" + i,i + "號");
studentMapper.insert(student);
}
// 結束時間
long endTime = System.currentTimeMillis();
System.out.println("插入數(shù)據(jù)消耗時間:" + (endTime - startTime));
}
(1)第一次測試結果:190155 約等于 190秒
(2)第二次測試結果:175926 約等于 176秒(服務未重啟)
(3)第三次測試結果:174726 約等于 174秒(服務重啟)
2、拼接SQL語句(總耗時:2.9秒)
簡明:拼接格式:insert into student(xxxx) value(xxxx),(xxxx),(xxxxx).......
總結:拼接結果就是將所有的數(shù)據(jù)集成在一條SQL語句的value值上,其由于提交到服務器上的insert語句少了,網(wǎng)絡負載少了,性能也就提上去。
但是當數(shù)據(jù)量上去后,可能會出現(xiàn)內(nèi)存溢出、解析SQL語句耗時等情況,但與第一點相比,提高了極大的性能。
@GetMapping("/sql")
public void sql(){
ArrayList<Student> arrayList = new ArrayList<>();
long startTime = System.currentTimeMillis();
for (int i = 0; i < 50000; i++){
Student student = new Student("李毅" + i,24,"張家界市" + i,i + "號");
arrayList.add(student);
}
studentMapper.insertSplice(arrayList);
long endTime = System.currentTimeMillis();
System.out.println("插入數(shù)據(jù)消耗時間:" + (endTime - startTime));
}
// 使用@Insert注解插入:此處為簡便,不寫Mapper.xml文件
@Insert("<script>" +
"insert into student (name,age,addr,addr_num) values " +
"<foreach collection='studentList' item='item' separator=','> " +
"(#{item.name}, #{item.age}, #{item.addr}, #{item.addrNum}) " +
"</foreach> " +
"</script>")
int insertSplice(@Param("studentList") List<Student> studentList);
(1)第一次測試結果:3218 約等于 3.2秒
(2)第二次測試結果:2592 約等于 2.6秒(服務未重啟)
(3)第三次測試結果:3082 約等于 3.1秒(服務重啟)
3、批量插入saveBatch(總耗時:2.7秒)
簡明:使用MyBatis-Plus實現(xiàn)IService接口中批處理saveBatch()方法,對底層源碼進行查看時,可發(fā)現(xiàn)其實是for循環(huán)插入,但是與第一點相比,為什么性能上提高了呢?因為利用分片處理(batchSize = 1000) + 分批提交事務的操作,從而提高性能,并非在Connection上消耗性能。
@GetMapping("/saveBatch1")
public void saveBatch1(){
ArrayList<Student> arrayList = new ArrayList<>();
long startTime = System.currentTimeMillis();
// 模擬數(shù)據(jù)
for (int i = 0; i < 50000; i++){
Student student = new Student("李毅" + i,24,"張家界市" + i,i + "號");
arrayList.add(student);
}
// 批量插入
studentService.saveBatch(arrayList);
long endTime = System.currentTimeMillis();
System.out.println("插入數(shù)據(jù)消耗時間:" + (endTime - startTime));
}
(1)第一次測試結果:2864 約等于 2.9秒
(2)第二次測試結果:2302 約等于 2.3秒(服務未重啟)
(3)第三次測試結果:2893 約等于 2.9秒(服務重啟)
重點注意:MySQL JDBC驅動默認情況下忽略saveBatch()方法中的executeBatch()語句,將需要批量處理的一組SQL語句進行拆散,執(zhí)行時一條一條給MySQL數(shù)據(jù)庫,造成實際上是分片插入,即與單條插入方式相比,有提高,但是性能未能得到實質性的提高。
測試:數(shù)據(jù)庫連接URL地址缺少 rewriteBatchedStatements = true 參數(shù)情況
# MySQL連接配置信息
spring:
datasource:
# 連接地址(未開啟批處理模式)
url: jdbc:mysql://127.0.0.1:3306/bjpowernode?useUnicode=true&characterEncoding=UTF-8&serverTimezone=Asia/Shanghai
# 用戶名
username: root
# 密碼
password: xxx
# 連接驅動名稱
driver-class-name: com.mysql.cj.jdbc.Driver
測試結果:10541 約等于 10.5秒(未開啟批處理模式)
4、循環(huán)插入 + 開啟批處理模式(總耗時:1.7秒)(重點:一次性提交)
簡明:開啟批處理,關閉自動提交事務,共用同一個SqlSession之后,for循環(huán)單條插入的性能得到實質性的提高;由于同一個SqlSession省去對資源相關操作的耗能、減少對事務處理的時間等,從而極大程度上提高執(zhí)行效率。(目前個人覺得最優(yōu)方案)
@GetMapping("/forSaveBatch")
public void forSaveBatch(){
// 開啟批量處理模式 BATCH 、關閉自動提交事務 false
SqlSession sqlSession = sqlSessionFactory.openSession(ExecutorType.BATCH,false);
// 反射獲取,獲取Mapper
StudentMapper studentMapper = sqlSession.getMapper(StudentMapper.class);
long startTime = System.currentTimeMillis();
for (int i = 0 ; i < 50000 ; i++){
Student student = new Student("李毅" + i,24,"張家界市" + i,i + "號");
studentMapper.insertStudent(student);
}
// 一次性提交事務
sqlSession.commit();
// 關閉資源
sqlSession.close();
long endTime = System.currentTimeMillis();
System.out.println("總耗時: " + (endTime - startTime));
}
(1)第一次測試結果:1831 約等于 1.8秒
![]()
(2)第二次測試結果:1382 約等于 1.4秒(服務未重啟)
(3)第三次測試結果:1883 約等于 1.9秒(服務重啟)
四、總結
本文記錄個人學習MySQL插入大數(shù)據(jù)一些方案心得,可得知主要是在獲取連接、關閉連接、釋放資源和提交事務等方面較耗能,其中最需要注意是開啟批處理模式,即URL地址的參數(shù):rewriteBatchedStatements = true,否則也無法發(fā)揮作用。
對于測試方案的設定、對考慮不周、理解和編寫錯誤的地方等情況,請多指出,共同學習!
推薦閱讀
1024 程序員節(jié):共迎算力新時代,開源新未來! Git 2.38 發(fā)布,引入巨型倉庫管理工具"Scalar" 七萬獎金,字節(jié)Offer,iPhone 14 Pro 等驚喜獎品
你好,我是程序猿DD,10年開發(fā)老司機、阿里云MVP、騰訊云TVP、出過書創(chuàng)過業(yè)、國企4年互聯(lián)網(wǎng)6年。從普通開發(fā)到架構師、再到合伙人。一路過來,給我最深的感受就是一定要不斷學習并關注前沿。只要你能堅持下來,多思考、少抱怨、勤動手,就很容易實現(xiàn)彎道超車!所以,不要問我現(xiàn)在干什么是否來得及。如果你看好一個事情,一定是堅持了才能看到希望,而不是看到希望才去堅持。相信我,只要堅持下來,你一定比現(xiàn)在更好!如果你還沒什么方向,可以先關注我,這里會經(jīng)常分享一些前沿資訊,幫你積累彎道超車的資本。