
Video Matting:AI視頻摳圖
點擊上方“機器學習與生成對抗網(wǎng)絡(luò)”,關(guān)注星標
獲取有趣、好玩的前沿干貨!
魚羊 明敏 發(fā)自 凹非寺 量子位 報道 | 公眾號 QbitAI
看這一頭蓬松的秀發(fā),加上帥氣的動作,你以為是在綠幕前拍大片?

No、No、No
這其實是AI拿來視頻實時摳圖后的效果。
沒想到吧,實時視頻摳圖,現(xiàn)在能精細到每一根發(fā)絲。

換到alpha通道再看一眼,不用多說,德芙打錢吧(手動狗頭)。

這就是來自字節(jié)跳動實習生小哥的最新研究:實時高分辨率視頻摳圖大法。
無需任何輔助輸入,把視頻丟給這個名為RVM的AI,它分分鐘就能幫你把人像高精度摳出,將背景替換成可以任意二次加工的綠幕。

不信有這么絲滑?我們用線上Demo親自嘗試了一波。

相比之下,現(xiàn)在在線會議軟件里的摳圖,一旦頭發(fā)遮住臉,人就會消失……

頭發(fā)絲更是明顯糊了。

難怪看得網(wǎng)友直言:
不敢想象你們把這只AI塞進手機里的樣子。

目前,這篇論文已經(jīng)入選WACV 2022。
你也可以上手一試
目前,RVM已經(jīng)在GitHub上開源,并給出了兩種試玩途徑:
于是我們也趕緊上手試了試。
先來看看效果:

首先來點難度低的。
對于這種人物在畫面中基本不移動的情況,RVM可以說是表現(xiàn)的非常好,和人工摳圖幾乎無差別。
現(xiàn)在,王冰冰進入動森都毫不違和了。

于是開腦洞,也變得簡單了許多……

咳咳,言歸正傳。人物動作幅度加大會怎樣呢?
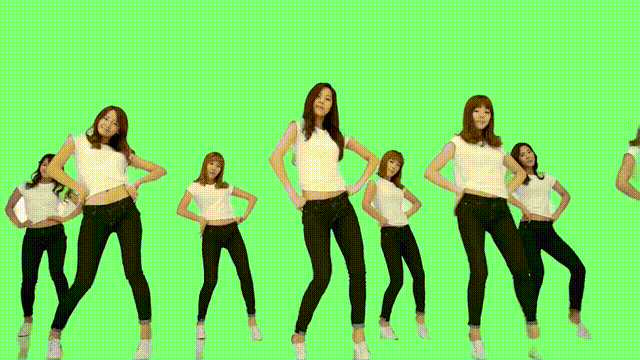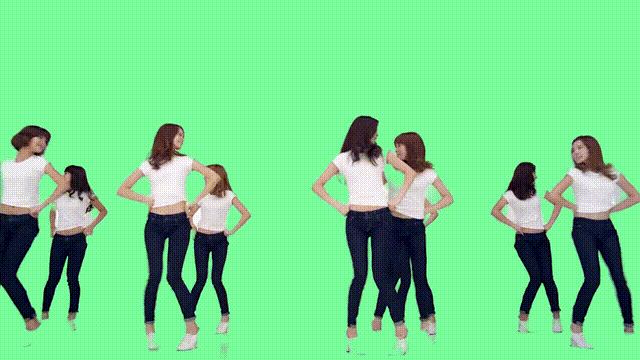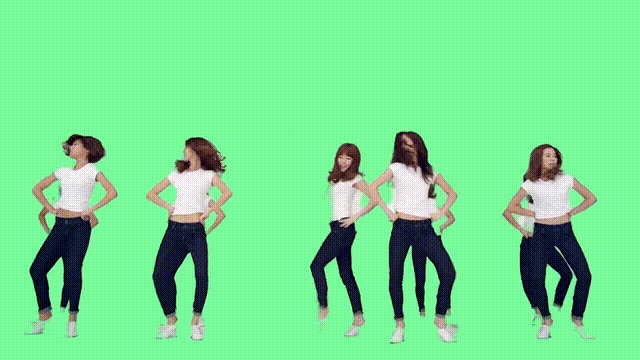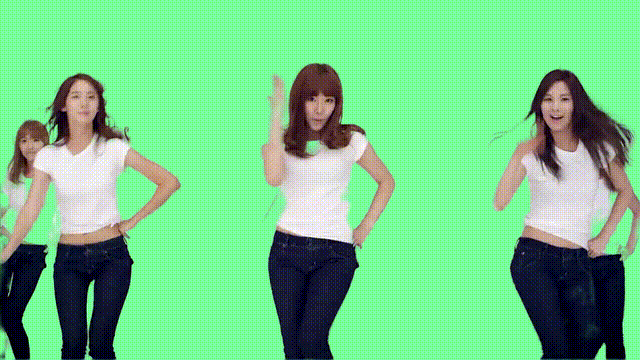
對于多人舞蹈視頻而言,RVM的表現(xiàn)也很nice。
即便動來動去、頭發(fā)亂甩,也沒有影響它的摳圖效果。
只有在人物出現(xiàn)遮擋的情況下,才會出現(xiàn)瑕疵。
對比前輩方法MODNet,確實有不小的進步。
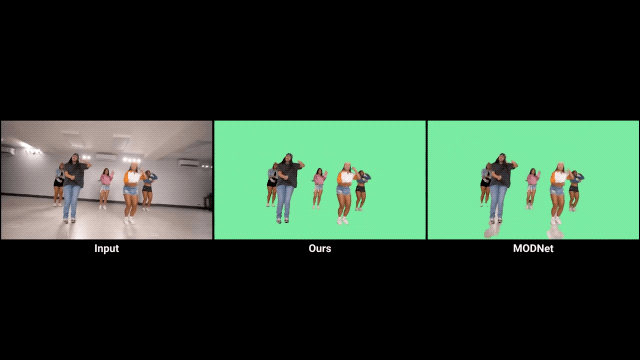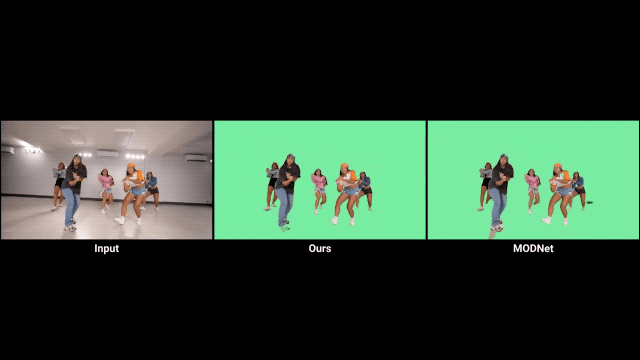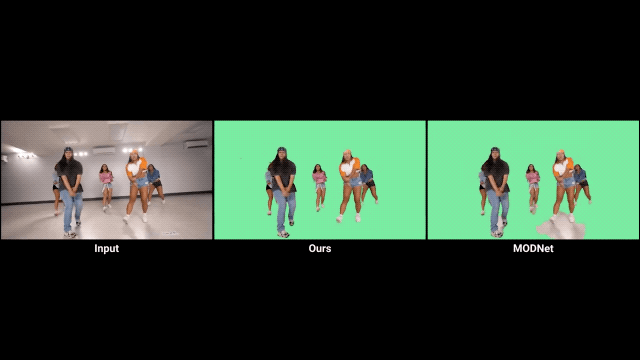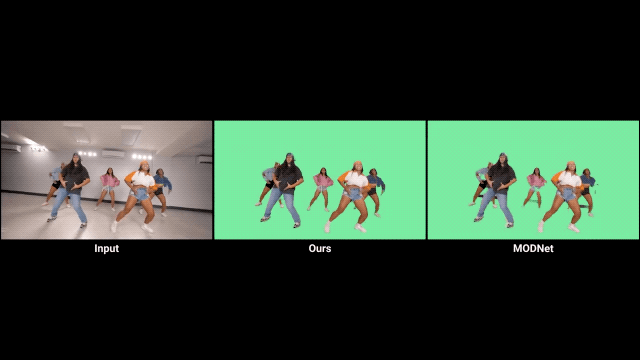
不過我們也發(fā)現(xiàn),如果視頻的背景較暗,就會影響RVM的發(fā)揮。
比如在這種背景光線昏暗的情況下,摳圖的效果就非常不盡人意了。

可以看到,博主老哥的頭發(fā)完全糊了。
而且身體的邊界線也不夠清晰。

所以,如果你想自己拍視頻試玩,就一定要選擇光線充足的場景。
利用時間信息
那么這樣的“魔法”,具體又是如何實現(xiàn)的?
照例,我們先來扒一扒論文~
實際上,有關(guān)視頻摳圖的算法如今已不鮮見,其中大多數(shù)采用的是將視頻中的每一幀作為獨立圖像來實現(xiàn)摳圖的方法。
不同與此,在這篇論文中,研究人員構(gòu)建了一個循環(huán)架構(gòu),利用上了視頻的時間信息,在時間一致性和摳圖質(zhì)量上取得了明顯改進。
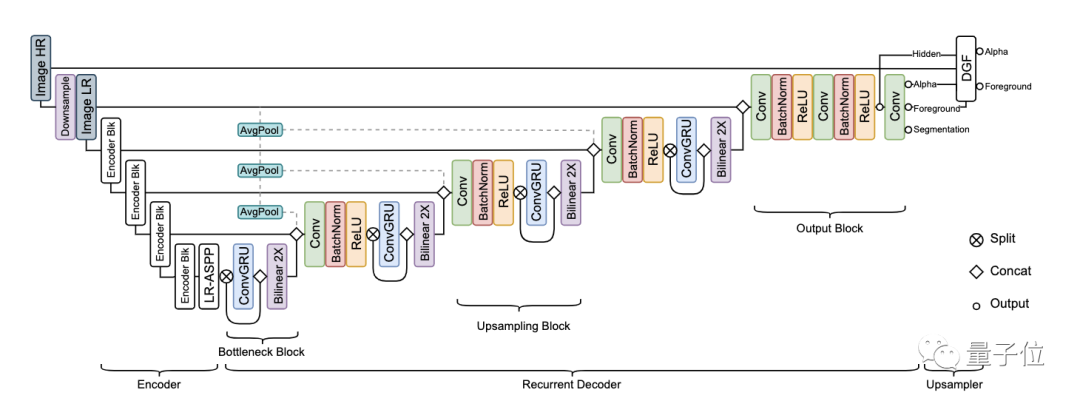
從上圖中可以看出,RVM的網(wǎng)絡(luò)架構(gòu)包括3個部分:
特征提取編碼器,用來提取單幀特征;
循環(huán)解碼器,用于匯總時間信息;
深度引導濾波(DGF)模塊,用于高分辨率上采樣。
其中,循環(huán)機制的引入使得AI能夠在連續(xù)的視頻流中自我學習,從而了解到哪些信息需要保留,哪些信息可以遺忘掉。
具體而言,循環(huán)解碼器采用了多尺度ConvGRU來聚合時間信息。其定義如下:
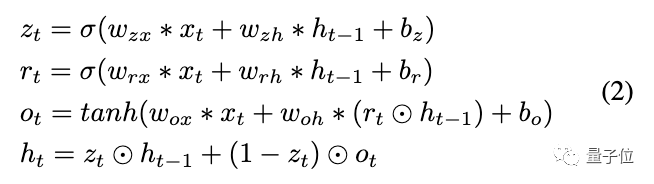
在這個編碼器-解碼器網(wǎng)絡(luò)中,AI會完成對高分辨率視頻的下采樣,然后再使用DGF對結(jié)果進行上采樣。
除此之外,研究人員還提出了一種新的訓練策略:同時使用摳圖和語義分割目標數(shù)據(jù)集來訓練網(wǎng)絡(luò)。
這樣做到好處在于:
首先,人像摳圖與人像分割任務(wù)密切相關(guān),AI必須學會從語義上理解場景,才能在定位人物主體方面具備魯棒性。
其次,現(xiàn)有的大部分摳圖數(shù)據(jù)集只提供真實的alpha通道和前景信息,所以必須對背景圖像進行合成。但前景和背景的光照往往不同,這就影響了合成的效果。語義分割數(shù)據(jù)集的引入可以有效防止過擬合。
最后,語義分割數(shù)據(jù)集擁有更為豐富的訓練數(shù)據(jù)。
經(jīng)過這一番調(diào)教之后,RVM和前輩們比起來,有怎樣的改進?
從效果對比中就可以明顯感受到了:

另外,與MODNet相比,RVM更輕更快。
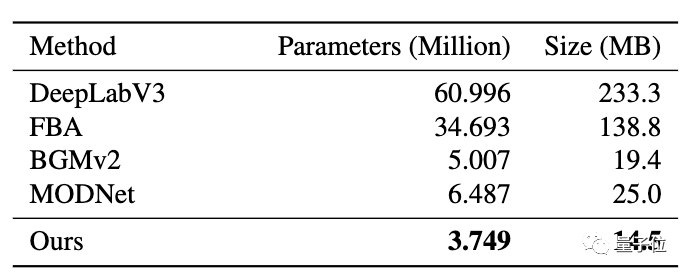
從下面這張表格中可以看出,在1080p視頻上RVM的處理速度是最快的,在512×288上比BGMv2略慢,在4K視頻上則比帶FGF的MODNet慢一點。研究人員分析,這是因為RVM除了alpha通道外還預(yù)判了前景。
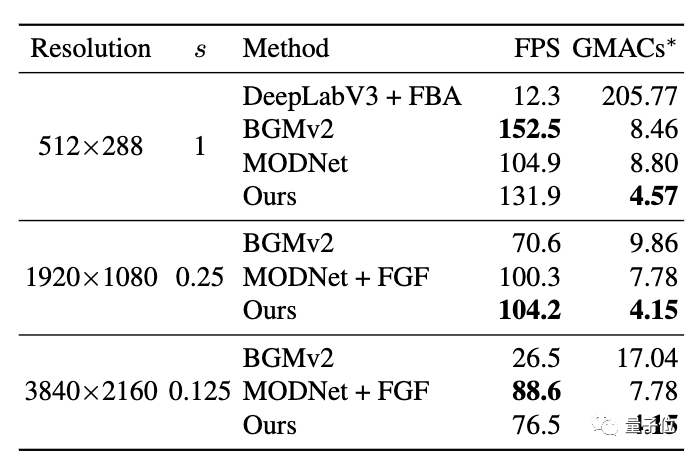
更直觀的數(shù)據(jù)是,在英偉達GTX 1080Ti上,RVM能以76FPS的速度處理4K視頻,以104FPS的速度處理HD視頻。
一作字節(jié)跳動實習生
這篇論文是一作林山川在字節(jié)跳動實習期間完成的。

他本科、碩士均畢業(yè)于華盛頓大學,曾先后在Adobe、Facebook等大廠實習。
2021年3月-6月,林山川在字節(jié)跳動實習。8月剛剛?cè)肼毼④洝?/p>
事實上,林山川此前就曾憑借AI摳圖大法拿下CVPR 2021最佳學生論文榮譽獎。
他以一作身份發(fā)表論文《Real-Time High-Resolution Background Matting》,提出了Background Matting V2方法。
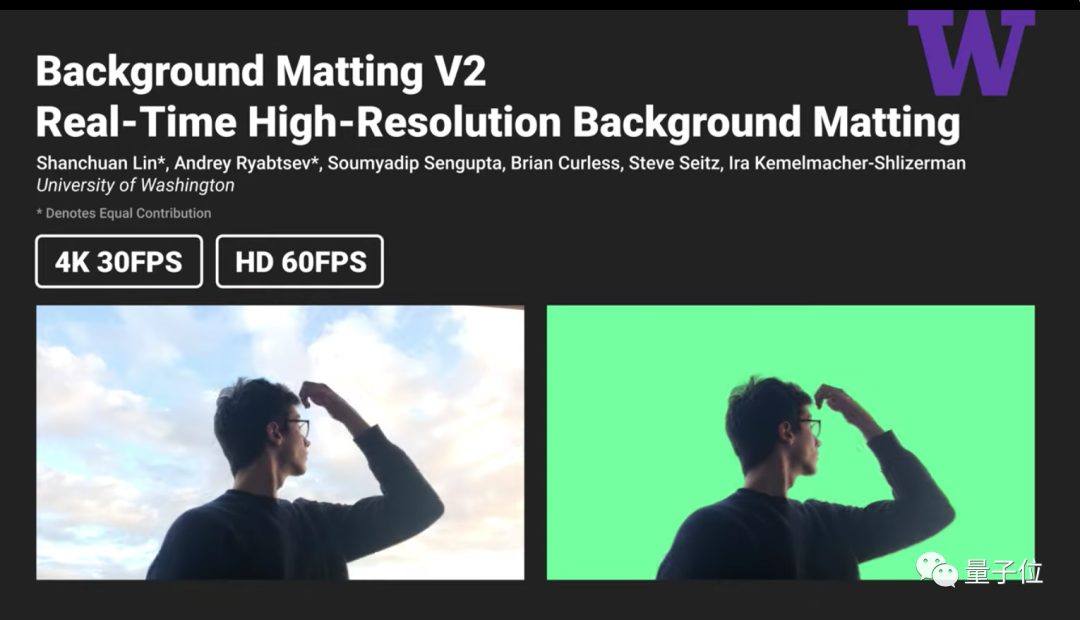
這一方法能夠以30FPS的速度處理4K視頻,以60FPS的速度處理HD視頻。
值得一提的是,Background Matting這一系列方法不止一次中了CVPR。此前,第一代Background Matting就被CVPR 2020收錄。

兩次論文的通訊作者都是華盛頓大學副教授Ira Kemelmacher-Shlizerman,她的研究方向為計算機視覺、計算機圖形、AR/VR等。

此外,本次論文的二作為Linjie Yang,他是字節(jié)跳動的研究科學家。本科畢業(yè)于清華大學,在香港中文大學獲得博士學位。

對了,除了能在Colab上試用之外,你也可以在網(wǎng)頁版上實時感受一下這只AI的效果,地址拿好:
https://peterl1n.github.io/RobustVideoMatting/#/demo
GitHub地址:
https://github.com/PeterL1n/RobustVideoMatting
論文地址:
https://arxiv.org/abs/2108.11515
參考鏈接:
https://www.reddit.com/r/MachineLearning/comments/pdbpmg/r_robust_highresolution_video_matting_with/
— 完 —
猜您喜歡:
等你著陸!【GAN生成對抗網(wǎng)絡(luò)】知識星球!
CVPR 2021 | GAN的說話人驅(qū)動、3D人臉論文匯總
CVPR 2021 | 圖像轉(zhuǎn)換 今如何?幾篇GAN論文
CVPR 2021生成對抗網(wǎng)絡(luò)GAN部分論文匯總
最新最全20篇!基于 StyleGAN 改進或應(yīng)用相關(guān)論文
附下載 | 經(jīng)典《Think Python》中文版
附下載 |《TensorFlow 2.0 深度學習算法實戰(zhàn)》