
為什么不建議使用 Java 自帶的序列化?


作者:rickiyang
出處:www.cnblogs.com/rickiyang/p/11074232.html
談到序列化我們自然想到 Java 提供的 Serializable 接口,在 Java 中我們?nèi)绻枰蛄谢恍枰^承該接口就可以通過輸入輸出流進(jìn)行序列化和反序列化。
但是在提供很用戶簡單的調(diào)用的同時他也存在很多問題:
1、無法跨語言
當(dāng)我們進(jìn)行跨應(yīng)用之間的服務(wù)調(diào)用的時候如果另外一個應(yīng)用使用c語言來開發(fā),這個時候我們發(fā)送過去的序列化對象,別人是無法進(jìn)行反序列化的因為其內(nèi)部實現(xiàn)對于別人來說完全就是黑盒。
2、序列化之后的碼流太大
這個我們可以做一個實驗還是上一節(jié)中的Message類,我們分別用java的序列化和使用二進(jìn)制編碼來做一個對比,下面我寫了一個測試類:
@Test
public void testSerializable(){
String str = "哈哈,我是一條消息";
Message msg = new Message((byte)0xAD,35,str);
ByteArrayOutputStream out = new ByteArrayOutputStream();
try {
ObjectOutputStream os = new ObjectOutputStream(out);
os.writeObject(msg);
os.flush();
byte[] b = out.toByteArray();
System.out.println("jdk序列化后的長度: "+b.length);
os.close();
out.close();
ByteBuffer buffer = ByteBuffer.allocate(1024);
byte[] bt = msg.getMsgBody().getBytes();
buffer.put(msg.getType());
buffer.putInt(msg.getLength());
buffer.put(bt);
buffer.flip();
byte[] result = new byte[buffer.remaining()];
buffer.get(result);
System.out.println("使用二進(jìn)制序列化的長度:"+result.length);
} catch (IOException e) {
e.printStackTrace();
}
}
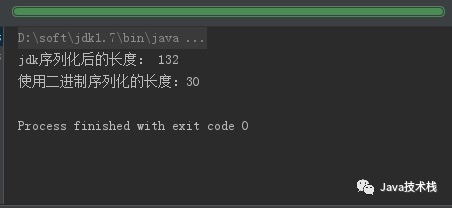
我們可以看到差距是挺大的,目前的主流編解碼框架序列化之后的碼流也都比java序列化要小太多。
3、序列化效率
這個我們也可以做一個對比,還是上面寫的測試代碼我們循環(huán)跑100000次對比一下時間:
@Test
public void testSerializable(){
String str = "哈哈,我是一條消息";
Message msg = new Message((byte)0xAD,35,str);
ByteArrayOutputStream out = new ByteArrayOutputStream();
try {
long startTime = System.currentTimeMillis();
for(int i = 0;i < 100000;i++){
ObjectOutputStream os = new ObjectOutputStream(out);
os.writeObject(msg);
os.flush();
byte[] b = out.toByteArray();
/*System.out.println("jdk序列化后的長度: "+b.length);*/
os.close();
out.close();
}
long endTime = System.currentTimeMillis();
System.out.println("jdk序列化100000次耗時:" +(endTime - startTime));
long startTime1 = System.currentTimeMillis();
for(int i = 0;i < 100000;i++){
ByteBuffer buffer = ByteBuffer.allocate(1024);
byte[] bt = msg.getMsgBody().getBytes();
buffer.put(msg.getType());
buffer.putInt(msg.getLength());
buffer.put(bt);
buffer.flip();
byte[] result = new byte[buffer.remaining()];
buffer.get(result);
/*System.out.println("使用二進(jìn)制序列化的長度:"+result.length);*/
}
long endTime1 = System.currentTimeMillis();
System.out.println("使用二進(jìn)制序列化100000次耗時:" +(endTime1 - startTime1));
} catch (IOException e) {
e.printStackTrace();
}
}
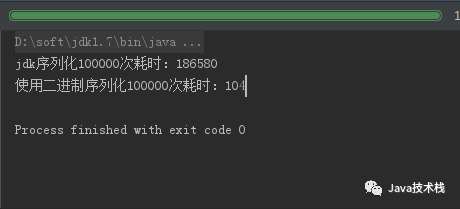
結(jié)果為毫秒數(shù),這個差距也是不小的。
結(jié)合以上我們看到:
目前的序列化過程中使用 Java 本身的肯定是不行,使用二進(jìn)制編碼的話又的我們自己去手寫,所以為了讓我們少搬磚前輩們早已經(jīng)寫好了工具讓我們調(diào)用,目前社區(qū)比較活躍的有 google 的 Protobuf 和 Apache 的 Thrift。
往 期 推 薦 1、Intellij IDEA這樣 配置注釋模板,讓你瞬間高出一個逼格! 2、吊炸天的 Docker 圖形化工具 Portainer,必須推薦給你! 3、最牛逼的 Java 日志框架,性能無敵,橫掃所有對手! 4、把Redis當(dāng)作隊列來用,真的合適嗎? 5、驚呆了,Spring Boot居然這么耗內(nèi)存!你知道嗎? 6、全網(wǎng)最全 Java 日志框架適配方案!還有誰不會? 7、Spring中毒太深,離開Spring我居然連最基本的接口都不會寫了 點分享
點收藏
點點贊
點在看





評論
圖片
表情