
Redis學(xué)習(xí)筆記
什么是Redis
Redis是一個使用C語言編寫的,開源的(BSD許可)高性能非關(guān)系型(NoSQL)的鍵值對數(shù)據(jù)庫Redis可以存儲鍵和五種不同類型的值之間的映射。鍵的類型只能為字符串,值支持五種類型:字符串、列表、集合、散列表、有序集合
與傳統(tǒng)數(shù)據(jù)庫不同的是Redis的數(shù)據(jù)是存在內(nèi)存中的,所以讀寫速度非常快,因此Redis被廣泛應(yīng)用于緩存方向,每秒可處理10萬次讀寫操作
Redis也可以用來做分布式鎖
Redis支持事務(wù)、持久化、LUA腳本、LRU驅(qū)動事件、多種集群方案
Redis的優(yōu)缺點
優(yōu)點
讀寫性能優(yōu)異
支持數(shù)據(jù)持久化
支持事務(wù)
數(shù)據(jù)結(jié)構(gòu)豐富
支持主從復(fù)制
缺點
數(shù)據(jù)庫容量收到物理內(nèi)存的限制,不能用作海量數(shù)據(jù)的高性能讀寫,因此Redis適合場景主要局限于較小數(shù)據(jù)量的高性能操作和運算
Redis不具備自動容錯和恢復(fù)功能,主機從機的宕機都會導(dǎo)致前端部分讀寫請求失敗,需要等待機器重啟或者手動切換前端的IP才能恢復(fù)
主機宕機,宕機前有部分數(shù)據(jù)未能及時同步到從機,切換IP后還會引入數(shù)據(jù)不一致的問題,降低了系統(tǒng)的可用性
Redis較難支持在線擴容,在集群容量達到上限時在線擴容會變得很復(fù)雜,為避免這一問題,運維人員在系統(tǒng)上線時必須確保有足夠的空間,這對資源造成了很大的浪費
除了Redis,還有哪些緩存實現(xiàn)方式
緩存可以分為分布式緩存和本地緩存
Redis可以作為分布式緩存,當分布式部署時各個服務(wù)器之間可以保持緩存數(shù)據(jù)的一致性,但是需要保證其可用性,Redis可使用哨兵模式來保證其可用性
Map可以用來做本地緩存,使用Map的key-value鍵值對來保存數(shù)據(jù),速度更快,其生命周期是和JVM一致的,當JVM銷毀時,本地緩存也隨之消失。當部署分布式時,每臺服務(wù)器上的緩存數(shù)據(jù)都是獨立存在的,不能保證相互之間的一致性
Redis為什么這么快
1、完全基于內(nèi)存,純內(nèi)存操作,非常快速。
2、數(shù)據(jù)結(jié)構(gòu)簡單,數(shù)據(jù)操作也很簡單
3、采用單線程,避免了不必要的上下文切換和競爭條件
4、使用多路I/O復(fù)用模型,非阻塞IO
5、Redis構(gòu)建了自己的VM機制,省去了部分不必要的移動和請求時間
Redis的數(shù)據(jù)類型
| 數(shù)據(jù)類型 | 可以存儲的值 | 操作 | 應(yīng)用場景 |
|---|---|---|---|
| STRING | 字符串、整數(shù)或者浮點數(shù) | 對整個字符串或者字符串的其中一部分執(zhí)行操作;對整數(shù)和浮點數(shù)執(zhí)行自增或者自減操作 | 做簡單的鍵值對緩存;短信驗證碼、配置信息 |
| LIST | 列表 | 從兩端壓入或者彈出元素對單個或者多個元素進行修剪,只保留一個范圍內(nèi)的元素 | 存儲一些列表型的數(shù)據(jù)結(jié)構(gòu),類似粉絲列表、文章的評論列表之類的數(shù)據(jù);省市區(qū)表、字典表、最新的...、消息隊列 |
| SET | 無序集合 | 添加、獲取、移除單個元素;檢查一個元素是否存在于集合中 | 交集、并集、差集的操作,比如交集,可以把兩個人的粉絲列表整一個交集;查找兩個人共同的好友 |
| HASH | 包含鍵值對的無序散列表 | 添加、獲取、移除、單個鍵值對;獲取所有鍵值對;檢查某個鍵是否存在 | 結(jié)構(gòu)化的數(shù)據(jù),比如一個對象;商品詳情、個人信息詳情、新聞詳情 |
| ZSET | 有序集合 | 添加、獲取、刪除元素;根據(jù)分值范圍或者成員來獲取元素;計算一個鍵的排名 | 去重但可以排序,如獲取排名前幾的用戶;top 10 |
Redis持久化
持久化就是把內(nèi)存的數(shù)據(jù)寫到磁盤中,防止服務(wù)宕機了內(nèi)存數(shù)據(jù)丟失
Redis提供兩種持久化機制RDB(默認)和AOF機制
RDB:是Redis DataBase縮寫快照
RDB是Redis默認的持久化方式。按照一定的時間將內(nèi)存的數(shù)據(jù)以快照的方式保存到硬盤中,對應(yīng)產(chǎn)生的數(shù)據(jù)文件為dump.rdb。通過配置文件中的save參數(shù)來定義快照的周期
優(yōu)點
只有一個文件dump.rdb,方便持久化
容災(zāi)性好,一個文件可以保存到安全的磁盤
性能最大化,fork子進程來完成寫操作,讓主進程繼續(xù)處理命令,所以是IO最大化。主進程不進行任何IO操作,保證了redis的高性能
相對于數(shù)據(jù)集大時,比AOF的啟動效率更高
缺點
數(shù)據(jù)安全性低。RDB是隔一段時間進行持久化,如果持久化之間redis發(fā)生故障,會發(fā)生數(shù)據(jù)丟失。所以這種方式更適合數(shù)據(jù)要求不嚴謹?shù)臅r候
AOF:持久化
AOF(Append-Only file)是指所有的命令行記錄以redis命令請求協(xié)議的格式完全持久化存儲,保存為aof文件。當重啟Redis會重新從持久化的日志中恢復(fù)數(shù)據(jù)
當兩種方式同時開啟時,數(shù)據(jù)恢復(fù)Redis時會優(yōu)先選擇AOF恢復(fù)
優(yōu)點
數(shù)據(jù)安全,aof持久化可以配置appendfsync屬性,有always,每進行一次命令操作就記錄到aof文件中一次
通過append模式寫文件,即使中途服務(wù)器宕機,可以通過redis-check-aof工具解決數(shù)據(jù)一致性問題
AOF的rewrite模式。AOF文件沒被rewritr之前(文件過大時會對命令進行合并重寫),可以刪除其中的某些命令
缺點
AOF文件比RDB文件大,且恢復(fù)速度慢
數(shù)據(jù)集大得時候,比rdb啟動效率低
AOF文件比RDB更新頻率高,優(yōu)先使用AOF還原數(shù)據(jù)
AOF比RDB更安全也更大
RDB性能比AOF好
如果兩個都配了。優(yōu)先加載AOF
Redis持久化數(shù)據(jù)和緩存怎么做擴容?
如果Redis被當作緩存使用,使用一致性哈希實現(xiàn)動態(tài)擴容縮容
如果Redis被當作一個持久化存儲使用,必須使用固定的keys-to-nodes映射關(guān)系,結(jié)點的數(shù)量一旦確定不能變化
過期鍵的刪除策略
Redis的過期鍵的刪除策略
過期策略通常有以下三種
定時過期:每個設(shè)置過期時間的key都需要創(chuàng)建一個定時器,到過期時間就會立即清除。該策略可以立即清除過期的數(shù)據(jù),對內(nèi)存很友好,但會占用大量的CPU資源去處理過期的數(shù)據(jù),從而影響緩存的響應(yīng)時間和吞吐量
惰性過期:只有當訪問一個key時,才會判斷key是否過期,過期則清楚。該策略可以最大化地節(jié)省CPU資源,卻對內(nèi)存不太友好。極端情況下可能出現(xiàn)大量的過期key沒有再次被訪問,從而不會被清除,占用大量內(nèi)存
定期過期:每隔一定的時間,會掃描一定數(shù)量地數(shù)據(jù)庫地expires字典中一定數(shù)量地key,并清除其中已過期地key,該策略是前兩者地一個折中方案,通過調(diào)整定時掃描地時間間隔和每次掃描地限定耗時,可以在不同情況下是的CPU和內(nèi)存資源達到最優(yōu)的平衡
Redis中同時使用了惰性過期和定期過期兩種過期策略
Redis key的過期時間和永久有效分別怎么設(shè)置?
EXPIRE和PERSIST命令
內(nèi)存相關(guān)
Mysql里有2000W數(shù)據(jù),redis中只存20W的數(shù)據(jù),如何保證redis中的數(shù)據(jù)都是熱點數(shù)據(jù)
redis內(nèi)存數(shù)據(jù)集大小上升到一定大小的時候,就會施行數(shù)據(jù)淘汰策略
Redis的內(nèi)存淘汰策略
Redis的內(nèi)存淘汰策略是指在Redis的用于緩存的內(nèi)存不足時,怎么處理需要新寫入且需要申請額外的數(shù)據(jù)
全局的鍵空間選擇性移除
noeviction:當內(nèi)存不足以容納新寫入數(shù)據(jù)時,新寫入數(shù)據(jù)會報錯
allkeys-lru:當內(nèi)存不足以容納新寫入數(shù)據(jù)時,在鍵空間中,移除最近最少使用的key(這個是最常使用的)
allkeys-random:當內(nèi)存不足以容納新寫入數(shù)據(jù)時,在鍵空間中,隨機移除某個key
設(shè)置過期時間的鍵空間選擇性移除
volatile-lru:當內(nèi)存不足以容納新寫入數(shù)據(jù)時,在設(shè)置了過期時間的鍵空間中,移除最近最少使用的key
volatile-random:當內(nèi)存不足以容納新寫入數(shù)據(jù)時,在設(shè)置了過期時間的鍵空間中,隨機移除某個key
volatile-ttl:當內(nèi)存不足以容納新寫入數(shù)據(jù)時,在設(shè)置了過期時間的鍵空間中,有更早過期時間的key優(yōu)先移除
Redis主要消耗什么物理資源
內(nèi)存
Redis的內(nèi)存用完了會發(fā)生什么?
如果達到設(shè)置的上限,Redis的寫命令會返回錯誤信息(但是讀命令還可以正常返回)或者你可以配置內(nèi)存淘汰機制,當Redis達到內(nèi)存上限時會沖刷掉舊的內(nèi)容
Redis如何做內(nèi)存優(yōu)化?
散列表
盡可能使用散列表(hash),散列表使用的內(nèi)存非常小縮減鍵值對象
key長度:設(shè)計鍵規(guī)則時,在完整完整描述業(yè)務(wù)情況下,鍵值越短越好
value長度:值對象縮減常見的方式就是將業(yè)務(wù)數(shù)據(jù)對象序列化二進制數(shù)組,序列化需要注意兩點
(1)精簡對象信息,避免無用信息的存儲
(2)序列化工具的選擇,選擇更為高效的序列化工具可以有效降低字節(jié)數(shù)組的大小
共享對象池
共享對象池指的是Redis內(nèi)部維護這[0-9999]的整數(shù)對象池。創(chuàng)建大量的整數(shù)類型redis對象存在內(nèi)存開銷,每個redis對象內(nèi)部結(jié)構(gòu)至少占16字節(jié),甚至超過了整數(shù)自身空間消耗。所以redis內(nèi)部維護了一個[0-9999]的整數(shù)對象池,用于節(jié)省內(nèi)存設(shè)置內(nèi)存上限
使用maxmemory參數(shù)限制最大可用內(nèi)存,當超出內(nèi)存上限時使用LRU等刪除策略釋放空間以及防止所用內(nèi)存超過服務(wù)器物理內(nèi)存配置內(nèi)存回收策略
Redis所用內(nèi)存達到maxmemory上限時會觸發(fā)相應(yīng)的溢出控制策略。具體策略受maxmemory-policy參數(shù)控制,Redis支持6種策略
(1)noeviction:默認策略,不會刪除任何數(shù)據(jù),拒絕所有寫入操作并返回客戶端錯誤信息OOM,command not allowed when used memory,此時Redis只響應(yīng)讀操作
(2)volatile-lru:根據(jù)LRU算法刪除設(shè)置了超時屬性(expire)的鍵,直到騰出足夠空間為止。如果沒有可刪除的鍵對象,回退到noeviction策略。
(3)allkeys-lru:根據(jù)LRU算法刪除鍵,不管數(shù)據(jù)有沒有設(shè)置超時屬性,直到騰出足夠空間為止
(4)allkeys-random:隨機刪除所有鍵,直到騰出足夠空間為止
(5)volatile-random:隨即刪除過期鍵,直到騰出足夠空間為止
(6)volatile-ttl:根據(jù)鍵值對象的ttl屬性,刪除最近將要過期數(shù)據(jù)。如果沒有,回退到noeviction策略
字符串優(yōu)化
字符串對象是Redis內(nèi)部最常用的數(shù)據(jù)類型。所有的鍵都是字符串類 型,值對象數(shù)據(jù)除了整數(shù)之外都使用字符串存儲。在使用過程中應(yīng)當盡量優(yōu)先使用整數(shù),比字符串類型更節(jié)省空間。并且要優(yōu)化字符串使用,避免預(yù)分配造成的內(nèi)存浪費。使用ziplist壓縮編碼優(yōu)化hash、list等結(jié)構(gòu),注重效率和空間的平衡,使用intset編碼優(yōu)化整數(shù)集合。使用ziplist編碼的hash結(jié)構(gòu)降低小對象鏈規(guī)模。編碼優(yōu)化
Redis對外提供了多種數(shù)據(jù)類型,但是Redis內(nèi)部對于不同類型的數(shù)據(jù)使用的內(nèi)部編碼不一樣。內(nèi)部編碼不同將直接影響數(shù)據(jù)的內(nèi)存占用和讀寫效率。控制鍵的數(shù)量
當Redis存儲的數(shù)據(jù)越來越多,必然會存在大量的鍵,過多的鍵同樣會消耗大量的內(nèi)存Redis線程模型
Redis基于Reactor模式開發(fā)了網(wǎng)絡(luò)事件處理器,這個處理器被稱為文件事件處理器(file event handler)。它的組成結(jié)構(gòu)分為4部分:多個套接字、IO多路復(fù)用器、文件事件分派器、事件處理器。因為文件事件分派器隊列的消費是單線程的,所以Redis才叫單線程模型
文件事件處理器使用I/O多路復(fù)用程序來同時監(jiān)聽多個套接字,并根據(jù)套接字目前執(zhí)行的任務(wù)來為套接字關(guān)聯(lián)不同的事件處理器
當被監(jiān)聽的套接字準備好執(zhí)行連接應(yīng)答(accept)、讀取(read)、寫入(write)、關(guān)閉(close)等操作時,與操作對應(yīng)的文件事件就會產(chǎn)生,這是文件事件處理器就會調(diào)用套接字之前關(guān)聯(lián)好的事件處理器來處理這些事件
為啥 redis 單線程模型也能效率這么高?
純內(nèi)存操作
核心是基于非阻塞的 IO 多路復(fù)用機制
單線程反而避免了多線程的頻繁上下文切換問題
事務(wù)
什么是事務(wù)?
事務(wù)是一個單獨的隔離操作:事務(wù)中的所有命令都會序列化、按順序地執(zhí)行。事務(wù)在執(zhí)行的過程中,不會被其他客戶端發(fā)送來的命令請求打斷
事務(wù)是一個原子操作:事務(wù)中的命令要么全部被執(zhí)行,要么全部都不執(zhí)行
Redis事務(wù)的概念
Redis事務(wù)的本質(zhì)是通過MULTI、EXEC、WATCH等一組命令的集合。事務(wù)支持一次執(zhí)行多個命令,一個事務(wù)中所有命令都會被序列化。在事務(wù)執(zhí)行過程,會按照串行化執(zhí)行隊列中的命令,其他客戶端提交的命令請求不會插入到事務(wù)執(zhí)行命令序列中
Redis事務(wù)的三個階段
事務(wù)開始MULTI
命令入隊
事務(wù)執(zhí)行EXEC
事務(wù)執(zhí)行過程中,如果服務(wù)端收到EXEC、DISCARD、WATCH、MULTI之外的請求,將會把請求放入隊列中排隊
Redis事務(wù)相關(guān)命令
Redis事務(wù)功能是通過MULTI、EXEC、DISCARD和WATCH四個原語實現(xiàn)的
Redis會將一個事務(wù)中的所有命令序列化,然后按順序執(zhí)行
redis不支持回滾,“Redis在事務(wù)失敗時不進行回滾,而是繼續(xù)執(zhí)行余下的命令”,所以Redis的內(nèi)部可以保持簡單且快速
如果在一個事務(wù)中的命令出現(xiàn)錯誤,那么所有的命令都不會執(zhí)行
如果在一個事務(wù)中出現(xiàn)運行錯誤,那么正確的命令會被執(zhí)行
WATCH命令是一個樂觀鎖,可以為Redis事務(wù)提供check-and-set(CAS)行為,可以監(jiān)控一個或多個鍵,一旦其中有一個鍵被修改(或刪除),之后的事務(wù)就不會被執(zhí)行,監(jiān)控一直持續(xù)到EXEC命令
MULTI命令用于開啟一個事務(wù),它總是返回OK。MULTI執(zhí)行后,客戶端可以繼續(xù)向服務(wù)器發(fā)送多條命令,這些命令不會被立即執(zhí)行,而是放到一個隊列里,當EXEC命令執(zhí)行時,所有隊列中的命令才會被執(zhí)行
EXEC:執(zhí)行所有事務(wù)塊內(nèi)的命令,返回事務(wù)塊內(nèi)所有命令的返回值,按命令執(zhí)行的先后順序排列。當操作被打斷時,返回值null
通過執(zhí)行DISCARD,客戶端可以清空事務(wù)隊列。并放棄執(zhí)行事務(wù),并且客戶端會從事務(wù)狀態(tài)中退出
UNWATCH命令可以取消watch對所有key的監(jiān)控
事務(wù)管理(ACID)概述
原子性、一致性、隔離性、持久性
Redis的事務(wù)總是具有ACID中的一致性和隔離性,其他特性是不支持的,當服務(wù)器運行在AOF持久化模式下,并且appendfsync選項的值未always時,事物也具有耐久性
Redis事務(wù)支持隔離性嗎
Redis是單進程程序,并且它保證在執(zhí)行事務(wù)時,不會對事務(wù)進行中斷,事務(wù)可以運行直到執(zhí)行完所有事務(wù)隊列中的命令為止。因此,Redis的事務(wù)總是帶有隔離性的
Redis事務(wù)保證原子性嗎,支持回滾嗎
Redis中,單條命令是原子性執(zhí)行的,但事務(wù)不保證原子性,且沒有回滾。事務(wù)中任意命令失敗,其余的命令仍會被執(zhí)行
集群方案
主從復(fù)制
主機數(shù)據(jù)更新后根據(jù)配置和策略,自動同步到master/slave機制,Master以寫為主,Slave以讀為主
主少從多、主寫從讀、讀寫分離、主寫同步復(fù)制到從
一主二從
搭建過程靜等后續(xù)吧
哨兵模式
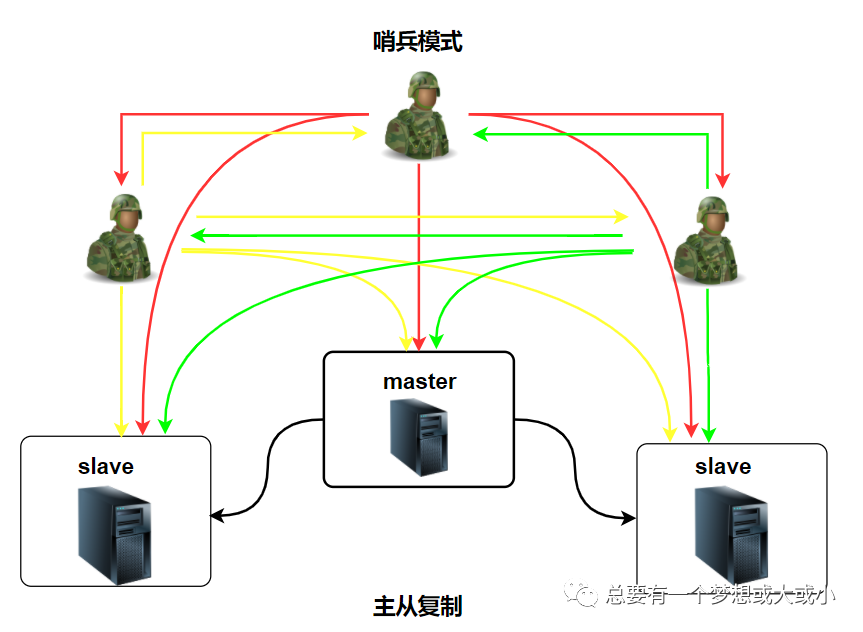
哨兵的介紹
sentinel,中文名是哨兵。哨兵是redis集群架構(gòu)中非常重要的一個組件,主要有以下功能
集群監(jiān)控:負責(zé)監(jiān)控redis master和slave進程是否正常工作
消息通知:如果某個redis實例有故障,那么哨兵負責(zé)發(fā)送消息作為報警通知給管理員
故障轉(zhuǎn)移:如果master node掛掉了,會自動轉(zhuǎn)移到slave node上
配置中心:如果故障轉(zhuǎn)移發(fā)生了,通知client客戶端新的master地址
哨兵用于實現(xiàn)redis集群的高可用,本身也是分布式的,作為一個哨兵集群去運行,互相協(xié)同去工作
故障轉(zhuǎn)移時,判斷一個master node是否宕機了,需要大部分的哨兵都同意才行,涉及到了分布式選舉的問題
即使部分哨兵節(jié)點掛掉了,哨兵集群還是能正常工作的,因為如果一個作為高可用機制重要組成部分的故障轉(zhuǎn)移系統(tǒng)本身是單節(jié)點的,就很扯淡
哨兵的核心知識
哨兵至少需要3個實例,來保證自己的健壯性
哨兵+redis主從的部署架構(gòu),是不保證數(shù)據(jù)零丟失的,只能保證redis集群的高可用性
對于哨兵+redis主從這種復(fù)雜的部署架構(gòu),盡量在測試環(huán)境和生產(chǎn)環(huán)境,都進行充足的測試和演練
操作命令
數(shù)據(jù)庫操作
127.0.0.1:6379> select 3 #切換到3號數(shù)據(jù)庫,默認0號數(shù)據(jù)庫
127.0.0.1:6379> dbsize #查看數(shù)據(jù)庫大小
127.0.0.1:6379> keys * #查看所有的key
127.0.0.1:6379> flushdb #清空當前數(shù)據(jù)庫
127.0.0.1:6379> flushall #清空所有數(shù)據(jù)庫內(nèi)容
127.0.0.1:6379> exists 'key' #判斷某個key是否存在
127.0.0.1:6379> move 'key' 1 #移除某個key,后面的1代表數(shù)據(jù)庫
127.0.0.1:6379> expire 'key' 10 #設(shè)置某個key過期時間,10表示10秒
127.0.0.1:6379> ttl 'key' #查看某個key剩余時效
127.0.0.1:6379> set 'key' 'value' #set一個key
127.0.0.1:6379> type 'key' #查看當前key的類型
數(shù)據(jù)類型及對應(yīng)操作
String
127.0.0.1:6379> append 'key' 'value' #在key對應(yīng)的value上追加字符串
127.0.0.1:6379> strlen 'key' #獲取字符串長度
127.0.0.1:6379> incr 'key' #當前key加1
127.0.0.1:6379> decr 'key' #當前key減1
127.0.0.1:6379> incrby 'key' 10 #當前key增加10
127.0.0.1:6379> decrby 'key' 10 #當前key減少10
127.0.0.1:6379> getrange 'key' 0 3 #截取當前字符串
127.0.0.1:6379> getrange 'key' 0 -1 #獲取全部的字符串 和 get key是一樣的
127.0.0.1:6379> setrange 'key' 1 xxx #替換指定位置開始的字符串
127.0.0.1:6379> setnx 'key' 30 xxx #設(shè)置當前key的過期時間
127.0.0.1:6379> setnx 'key' xxx #不存在再設(shè)置(在分布式鎖中常使用)
127.0.0.1:6379> mset k1 v1 k2 v2 k3 v3 #同時設(shè)置多個值
127.0.0.1:6379> mget k1 k2 k3 #同時獲取多個值
127.0.0.1:6379> msetnx k1 v2 k4 v4 #msetnx 是一個原子性操作,要么一起成功,要么一起失敗
List
127.0.0.1:6379> lpush list one #將一個值或者多個值,插入到列表的頭部(左)
127.0.0.1:6379> rpush list one #將一個值或者多個值,插入到列表的尾部(右)
127.0.0.1:6379> lrange list 0 -1 #獲取list中的值
127.0.0.1:6379> lrange list 0 1 #通過區(qū)間獲取list中具體的值
127.0.0.1:6379> lpop list #移除當前l(fā)ist中的第一個值
127.0.0.1:6379> rpop list #移除當前l(fā)ist中的最后一個值
127.0.0.1:6379> lindex list 1 #通過下標獲取list的某一個值
127.0.0.1:6379> llen list #返回列表的長度
127.0.0.1:6379> lrem list 1 one #移除list集合中指定個數(shù)的value,精確匹配;移除列表中的1個one
127.0.0.1:6379> lrem list 2 one #移除list集合中指定個數(shù)的value,精確匹配;移除列表中的2個one
127.0.0.1:6379> ltrim list 1 2 #通過下標截取指定的長度 改變list,list只剩下截取的元素
127.0.0.1:6379> rpoplpush list targetlist #移除列表的最后一個元素并將其移動到另一個列表中
127.0.0.1:6379> lset list 0 item #將列表中指定下標的值替換為另一個值
127.0.0.1:6379> linsert list before "world" "other" #將某個具體的值插入列表中某個元素的前面
127.0.0.1:6379> linsert list after "world" "other" #將某個具體的值插入列表中某個元素的后面
Set
127.0.0.1:6379> sadd myset "world" #set集合中添加元素
127.0.0.1:6379> smembers myset #查看set集合中的元素
127.0.0.1:6379> sismembers myset hello #查看set集合是否包含某個元素
127.0.0.1:6379> scard myset #獲取set集合中的內(nèi)容元素個數(shù)
127.0.0.1:6379> srem myset hello #移除set集合中的某個元素
127.0.0.1:6379> srandmember myset #隨機抽選出一個元素
127.0.0.1:6379> srandmember myset 2 #隨機抽選出指定個數(shù)的元素
127.0.0.1:6379> spop myset #隨機移除元素
127.0.0.1:6379> smove myset targetset #移動指定的元素到指定的集合
127.0.0.1:6379> sdiff set1 set2 #獲取兩個集合的差集
127.0.0.1:6379> sinter set1 set2 #獲取兩個集合的交集 共同好友可以這樣實現(xiàn)
127.0.0.1:6379> sunion set1 set2 #獲取兩個集合的并集
Hash
127.0.0.1:6379> hset myhash key value #set一個具體的key-value
127.0.0.1:6379> hget myhash key #獲取一個key對應(yīng)的value
127.0.0.1:6379> hmset myhash key value key1 value1 #set多個具體的key-value
127.0.0.1:6379> hmget myhash key key1 #s獲取多個value
127.0.0.1:6379> hgetall myhash #獲取所有的key-value
127.0.0.1:6379> hdel myhash key #刪除hash指定的key,對應(yīng)的value也不見了
127.0.0.1:6379> hlen myhash #獲取hash的長度
127.0.0.1:6379> hexists myhash key #判斷hash中指定字段是否存在
127.0.0.1:6379> hkeys myhash #獲取所有的key
127.0.0.1:6379> hvals myhash #獲取所有的value
127.0.0.1:6379> hincrby myhash key 1 #hash中指定key自增1
127.0.0.1:6379> hdecrby myhash key 1 #hash中指定key自減1
127.0.0.1:6379> hsetnx myhash key value #如果存在則可以設(shè)置
#hash變更的數(shù)據(jù),hash更適合存儲對象Zset(有序集合)
127.0.0.1:6379> zset myzset 1 one #添加一個值到zset
127.0.0.1:6379> zset myzset 2 two 3 three #添加多個值到zset
127.0.0.1:6379> zrange myzset 0 -1 #獲取zset的所有值
127.0.0.1:6379> zrangebyscore myzset -inf +inf #獲取zset的所有值,從小到大排序
127.0.0.1:6379> zrevrange myzset 0 -1 #獲取zset的所有值,從大到小
127.0.0.1:6379> zrem myzset zzz #移除有序集合中的指定元素
127.0.0.1:6379> zcard myzset #獲取有序集合中的個數(shù)
127.0.0.1:6379> zcount myzset targer 1 3 #獲取指定區(qū)間的成員數(shù)量
#消息設(shè)置權(quán)重 普通消息;重要消息;緊急消息
Hyperloglog
PFadd mykey a b c d e f g h i j #創(chuàng)建第一組元素
PFcount mykey #統(tǒng)計mykey的元素的基數(shù)數(shù)量
PFadd mykey2 i j z y x c v b #創(chuàng)建第二組元素
PFcount mykey2 #統(tǒng)計第二組元素
PFMERGE mykey3 mykey mykey2 #合并兩組 mykey mykey2 => mykey3 并集
PFCOUNT mykey3 #看并集的數(shù)量
#如果允許容錯,那么一定可以使用Hyperloglog,如果不允許容錯,就使用set事務(wù)
事務(wù)的原則:ACID:原子性、一致性、隔離性、持久性
Redis單條命令保存原子性,但是事務(wù)不保證原子性
Redis事務(wù)的本質(zhì):一組命令的事務(wù)
開啟事務(wù) multi
命令入隊
執(zhí)行事務(wù) exec
127.0.0.1:6379> multi #開啟事務(wù)
OK
127.0.0.1:6379> set k1 v1
QUEUED
127.0.0.1:6379> set k2 v2
QUEUED
127.0.0.1:6379> exec #執(zhí)行事務(wù)
1) OK
2) OK
127.0.0.1:6379>
#放棄事務(wù) 事務(wù)中的命令都不會被執(zhí)行
127.0.0.1:6379> discard
#異常
##編譯型異常 命令有錯,事務(wù)中所有命令都不會執(zhí)行
##運行時異常 如果事務(wù)隊列中存在語法性,那么執(zhí)行命令時,其他命令是可以正常執(zhí)行的,錯誤命令會拋出異常
Redis事務(wù)沒有隔離級別的概念
所有的命令在事務(wù)中,并沒有直接被執(zhí)行,只有發(fā)起執(zhí)行命令的時候才會執(zhí)行
!!!!!Redis的watch可以實現(xiàn)樂觀鎖的操作
watch money #監(jiān)視money
multi #開啟事務(wù)
incrby money #命令入隊 money+1
decrby money #命令入隊 money-1
exec #比對監(jiān)視的值是否發(fā)生了變化,如果沒有變化,那么可以執(zhí)行成功,如果有變化就執(zhí)行失敗Redis.conf詳解
1、配置文件unit單位第一大小寫不敏感
2、includes可以包含多個配置文件的信息
3、network
bind 127.0.0.1 #綁定的ip
protected-mode yes #保護模式
port 6379 #端口設(shè)置
4、daemonize yes #以守護進程的方式運行,默認是no,我們需要自己開啟為yes
5、pidfile /var/run/redis_6379.pid #如果以后臺的方式運行,我們就需要指定一個pid文件
6、loglevel notice #日志級別
7、log file“” #日志的文件路徑
8、databases 16 # 數(shù)據(jù)庫的數(shù)量,默認是16個數(shù)據(jù)庫
9、always-show-logo yes #是否總是顯示logo
10、持久化,在規(guī)定的時間內(nèi),執(zhí)行多少次操作則會持久化到 .rdb .aof
redis是內(nèi)存數(shù)據(jù)庫,如果沒有持久化,那么數(shù)據(jù)斷電即失
save 900 1 # 如果 900s 內(nèi),至少有 1 個 可以進行了修改,我們就進行持久化操作
save 300 10 # 如果 300s 內(nèi),至少有 10 個 可以進行了修改,我們就進行持久化操作
save 60 1000 # 如果 60s 內(nèi),至少有 1000 個 可以進行了修改,我們就進行持久化操作
11、stop-writes-on-bgsave-error yes #如果持久化出錯,redis是否正常工作
12、rdbcompression yes #是否壓縮rdb文件,需要消耗一些cpu資源
13、rdbchecksun yes #保存rdb文件時,進行錯誤的校驗
14、dir ./ #rdb 文件保存的目錄#
########限制CLIENTS#########
15、maxclients 1000 # 設(shè)置能連接上redis的最大客戶端的數(shù)量
16、maxmemory <bytes> # redis 配置最大的內(nèi)存容量
17、maxmemory-policy noeviction # 內(nèi)存到達上之后的處理策略
TODO 需要補充策略
########APPEND ONLY 模式 AOF配置#########
18、appendonly no #默認是不開啟aof模式的,默認是使用rdb方式持久化的,在大部分的情況下,rdb完全夠用
19、appendfilename "appendonly.aof" #持久化文件的名字
20、 appendfsync always #每次修改都會sync , 消耗性能
appendfsync everysec #每秒執(zhí)行一次sync,可能會丟失這1s的數(shù)據(jù)
appendfsync no #不執(zhí)行sync,這個時候操作系統(tǒng)自己同步數(shù)據(jù),速度最快
觸發(fā)持久化機制(RDB)
1、save的規(guī)則滿足的情況下,會自動觸發(fā)rdb規(guī)則
2、執(zhí)行flushall命令,也會觸發(fā)我們的rdb規(guī)則
3、退出redis,也會產(chǎn)生rdb文件
####如果要恢復(fù)rdb文件,只需要將rdb文件放在redis啟動目錄就可以,redis啟動的時候會自動檢查dump.rdb,恢復(fù)其中的數(shù)據(jù)
####優(yōu)點:1、適合大規(guī)模的數(shù)據(jù)恢復(fù)
#### 2、對數(shù)據(jù)的完整性要求不高
####缺點:1、需要一定的時間間隔進程操作,如果redis意外宕機,這個最后一次的操作將會丟失
AOF(Append Only File)(默認不開啟,需手動開啟,重啟redis生效)
將我們所有的命令都記錄下來,history,恢復(fù)的時候就把這個文件全部再執(zhí)行一遍
1、AOF在大數(shù)據(jù)的情況下效率很低
2、AOF被破壞的話,redis將不能啟動;可以使用 redis-check-aof --fix 進行修復(fù)本文為學(xué)習(xí)筆記,參考多篇文章及教學(xué)視頻,如有侵權(quán),請后臺聯(lián)系