
一個(gè)簡單的Python案例帶你了解SVM
本文轉(zhuǎn)載自公眾號(hào)CAD數(shù)據(jù)分析師。
掌握機(jī)器學(xué)習(xí)算法并不是一個(gè)不可能完成的事情。大多數(shù)的初學(xué)者都是從學(xué)習(xí)回歸開始的。是因?yàn)榛貧w易于學(xué)習(xí)和使用,但這能夠解決我們?nèi)康膯栴}嗎?當(dāng)然不行!因?yàn)椋阋獙W(xué)習(xí)的機(jī)器學(xué)習(xí)算法不僅僅只有回歸!
把機(jī)器學(xué)習(xí)算法想象成一個(gè)裝有斧頭,劍,刀,弓箭,匕首等等武器的軍械庫。你有各種各樣的工具,但你應(yīng)該學(xué)會(huì)在正確的時(shí)間和場合使用它們。作為一個(gè)類比,我們可以將“回歸”想象成一把能夠有效切割數(shù)據(jù)的劍,但它無法處理高度復(fù)雜的數(shù)據(jù)。相反,“支持向量機(jī)”就像一把鋒利的刀—它適用于較小的數(shù)據(jù)集,但它可以再這些小的數(shù)據(jù)集上面構(gòu)建更加強(qiáng)大的模型。
現(xiàn)在,我希望你現(xiàn)在已經(jīng)掌握了隨機(jī)森林,樸素貝葉斯算法和模型融合的算法基礎(chǔ)。如果沒有,我希望你先抽出一部分時(shí)間來了解一下他們,因?yàn)樵诒疚闹校覍⒅笇?dǎo)你了解認(rèn)識(shí)機(jī)器學(xué)習(xí)算法中關(guān)鍵的高級(jí)算法,也就是支持向量機(jī)的基礎(chǔ)知識(shí)。
如果你是初學(xué)者,并且希望開始你的數(shù)據(jù)科學(xué)之旅,那么我希望你先去了解一些基礎(chǔ)的機(jī)器學(xué)習(xí)算法, 支持向量機(jī)相對(duì)來說對(duì)于數(shù)據(jù)科學(xué)的初學(xué)者來講的確有一點(diǎn)難了。
0.什么是分類分析
讓我們用一個(gè)例子來理解這個(gè)概念。假如我們的人口是按照50%-50%分布的男性和女性。那么使用這個(gè)群體的樣本,就需要?jiǎng)?chuàng)建一些規(guī)則,這些規(guī)則將指導(dǎo)我們將其他人的性別進(jìn)行分類。如果使用這種算法,我們打算建立一個(gè)機(jī)器人,可以識(shí)別一個(gè)人是男性還是女性。這是分類分析的樣本問題。我們將嘗試使用一些規(guī)則來劃分性別之間的不同。為簡單起見,我們假設(shè)使用的兩個(gè)區(qū)別因素是:個(gè)體的身高和頭發(fā)長度。以下是樣本的散點(diǎn)圖。
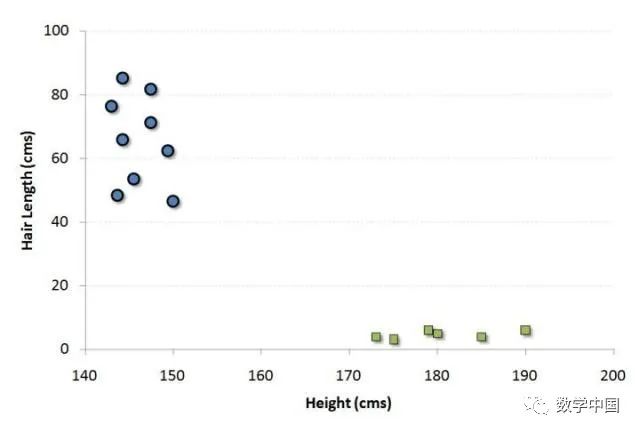
圖中的藍(lán)色圓圈表示女性,綠色方塊表示男性。圖中的一些預(yù)期見解是:
我們?nèi)丝谥械哪行缘钠骄砀咻^高。
我們?nèi)丝谥械呐缘念^發(fā)較長。
如果我們看到一個(gè)身高180厘米,頭發(fā)長度為4厘米的人,我們最好的分類是將這個(gè)人歸類為男性。這就是我們進(jìn)行分類分析的方法。
1.什么是支持向量機(jī)
“支持向量機(jī)”(SVM)是一種有監(jiān)督的機(jī)器學(xué)習(xí)算法,可用于分類任務(wù)或回歸任務(wù)。但是,它主要適用于分類問題。在這個(gè)算法中,我們將每個(gè)數(shù)據(jù)項(xiàng)繪制為n維空間中的一個(gè)點(diǎn)(其中n是你擁有的是特征的數(shù)量),每個(gè)特征的值是特定坐標(biāo)的值。然后,我們通過找到很好地區(qū)分這兩個(gè)類的超平面來執(zhí)行分類的任務(wù)(請(qǐng)看下面的演示圖片)。
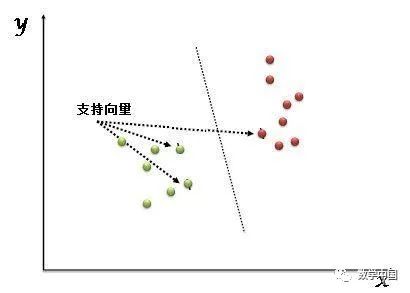
支持向量只是個(gè)體觀測的坐標(biāo)。支持向量機(jī)是一個(gè)最好地隔離兩個(gè)類(超平面或者說分類線)的前沿算法。
在我第一次聽到“支持向量機(jī)”這個(gè)名字,我覺得這個(gè)名字聽起來好復(fù)雜,如果連名字都這么復(fù)雜的話,那么這個(gè)名字的概念將超出我的理解。幸運(yùn)的是,在我看了一些大學(xué)的講座視頻,才意識(shí)到這個(gè)算法其實(shí)也沒有那么復(fù)雜。接下來,我們將討論支持向量機(jī)如何工作。我們將詳細(xì)探討該技術(shù),并分析這些技術(shù)為什么比其他技術(shù)更強(qiáng)。
2.它是如何工作的?
上面,我們已經(jīng)習(xí)慣了用超平面來隔離兩種類別的過程,但是現(xiàn)在最迫切的問題是“我們?nèi)绾巫R(shí)別正確的超平面?”。關(guān)于這個(gè)問題不用急躁,因?yàn)樗⒉幌衲阆胂蟮哪敲措y!
讓我們一個(gè)個(gè)的來理解如何識(shí)別正確的超平面:
選擇正確的超平面(場景1):這里,我們有三個(gè)超平面(A、B、C)。現(xiàn)在,讓我們用正確的超平面對(duì)星形和圓形進(jìn)行分類。
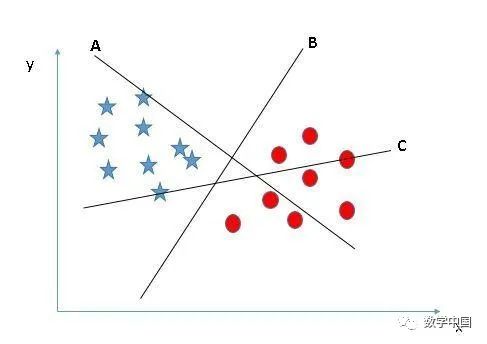
你需要記住一個(gè)經(jīng)驗(yàn)的法則來識(shí)別正確的超平面:“選擇更好的可以隔離兩個(gè)類別的超平面”。在這種情況下,超平面“B”就非常完美的完成了這項(xiàng)工作。
選擇正確的超平面(場景2):在這里,我們有三個(gè)超平面(A,B,C),并且所有這些超平面都很好地隔離了類。現(xiàn)在,我們?nèi)绾芜x擇正確的超平面?
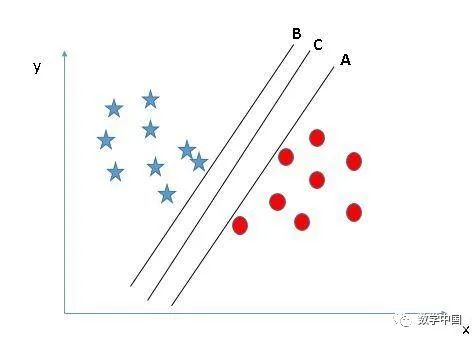
在這里,在這里,將最近的數(shù)據(jù)點(diǎn)(任一類)和超平面之間的距離最大化將有助于我們選擇正確的超平面。該距離稱為邊距。讓我們看一下下面的圖片:
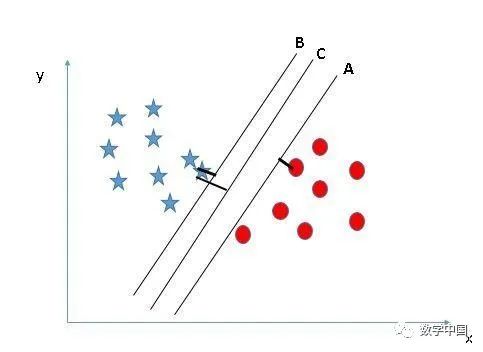
上面,你可以看到超平面C的邊距與A和B相比都很高。因此,我們將正確的超平面選擇為C。選擇邊距較高的超平面的另一個(gè)決定性因素是穩(wěn)健性。如果我們選擇一個(gè)低邊距的超平面,那么很有可能進(jìn)行錯(cuò)誤分類。
選擇正確的超平面(場景3):提示:使用我們前面討論的規(guī)則來選擇正確的超平面
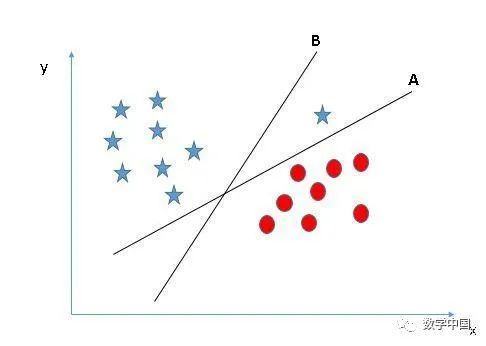
你們中的一些人可能選擇了超平面B,因?yàn)樗cA相比具有更高的邊距。但是SVM選擇超平面是需要在最大化邊距之前準(zhǔn)確地對(duì)類別進(jìn)行分類。這里,超平面B有一個(gè)分類的錯(cuò)誤,而且A進(jìn)行了正確的分類。因此,正確的超平面應(yīng)該是A.
我們可以對(duì)這個(gè)兩個(gè)類進(jìn)行分類嗎?(場景4):下面這張圖片中,我們無法使用直線來分隔這兩個(gè)類,因?yàn)槠渲幸粋€(gè)星星位于圓形類別的區(qū)域中作為一個(gè)異常值。
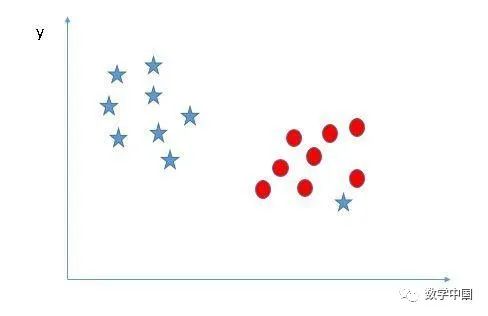
正如我剛剛已經(jīng)提到的,另一端的那一顆星星就像是一個(gè)異常值。SVM具有忽略異常值并找到具有最大邊距的超平面的功能。因此,我們可以說,SVM對(duì)異常值有很強(qiáng)的穩(wěn)健性
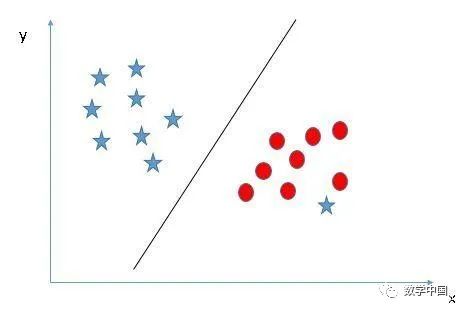
找到一個(gè)超平面用來隔離兩個(gè)類別(場景5):在下面的場景中,我們不能在兩個(gè)類之間有線性的超平面,那么SVM如何對(duì)這兩個(gè)類進(jìn)行分類?到目前為止,我們只研究過線性超平面。
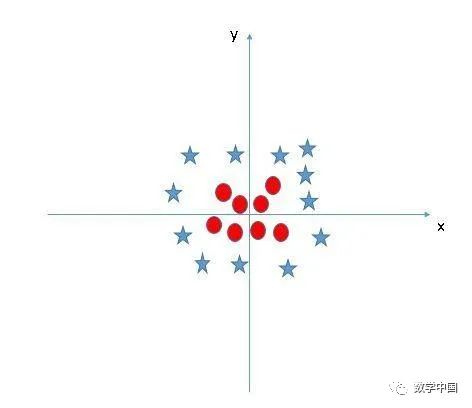
SVM可以解決這個(gè)問題。并且是輕松就可以做到!它通過引入額外的特征來解決這個(gè)問題。在這里,我們將添加一個(gè)新特征
現(xiàn)在,讓我們繪制軸x和z上的數(shù)據(jù)點(diǎn):
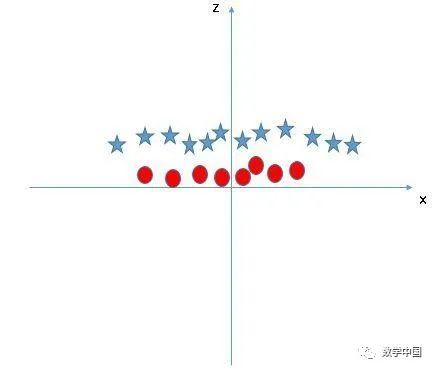
在上圖中,要考慮的問題是:
z的所有值都是正的,因?yàn)閦是x和y的平方和在原圖中,紅色圓圈出現(xiàn)在靠近x和y軸原點(diǎn)的位置,導(dǎo)致z值比較低。星形相對(duì)遠(yuǎn)離原點(diǎn),導(dǎo)致z值較高。在SVM中,很容易就可以在這兩個(gè)類之間建立線性超平面。但是,另一個(gè)需要解決的問題是,我們是否需要手動(dòng)添加一個(gè)特征以獲得超平面。不,并不需要這么做,SVM有一種稱為核技巧的技術(shù)。這些函數(shù)把低維度的輸入空間轉(zhuǎn)換為更高維度的空間,也就是它將不可分離的問題轉(zhuǎn)換為可分離的問題,這些函數(shù)稱為內(nèi)核函數(shù)。它主要用于非線性的分離問題。簡而言之,它執(zhí)行一些非常復(fù)雜的數(shù)據(jù)轉(zhuǎn)換,然后根據(jù)你定義的標(biāo)簽或輸出找出分離數(shù)據(jù)的過程。
當(dāng)SVM找到一條合適的超平面之后,我們在原始輸入空間中查看超平面時(shí),它看起來像一個(gè)圓圈:
現(xiàn)在,讓我們看看在數(shù)據(jù)科學(xué)中應(yīng)用SVM算法的方法。
3.如何在Python中實(shí)現(xiàn)SVM?
在Python中,scikit-learn是一個(gè)廣泛使用的用于實(shí)現(xiàn)機(jī)器學(xué)習(xí)算法的庫,SVM也可在scikit-learn庫中使用并且遵循相同的結(jié)構(gòu)(導(dǎo)入庫,創(chuàng)建對(duì)象,擬合模型和預(yù)測)。我們來看下面的代碼:
#導(dǎo)入庫from sklearn import svm#假設(shè)您有用于訓(xùn)練數(shù)據(jù)集的X(特征數(shù)據(jù))和Y(目標(biāo)),以及測試數(shù)據(jù)的x_test(特征數(shù)據(jù))#創(chuàng)建SVM分類對(duì)象model = svm.svc(kernel='linear', c=1, gamma=1)#與之相關(guān)的選項(xiàng)有很多,比如更改kernel值(內(nèi)核)、gamma值和C值。下一節(jié)將對(duì)此進(jìn)行更多討論。使用訓(xùn)練集訓(xùn)練模型,并檢查成績model.fit(X, y)model.score(X, y)#預(yù)測輸出predicted= model.predict(x_test)
4.如何調(diào)整SVM的參數(shù)?
對(duì)機(jī)器學(xué)習(xí)算法進(jìn)行調(diào)整參數(shù)值可以有效地提高模型的性能。讓我們看一下SVM可用的參數(shù)列表。
sklearn.svm.SVC(C=1.0, kernel='rbf', degree=3, gamma=0.0, coef0=0.0, shrinking=True, probability=False,tol=0.001, cache_size=200, class_weight=None, verbose=False, max_iter=-1, random_state=None)
下面將討論一些對(duì)模型性能影響較大的重要參數(shù),如“kernel”,“gamma”和“C”。
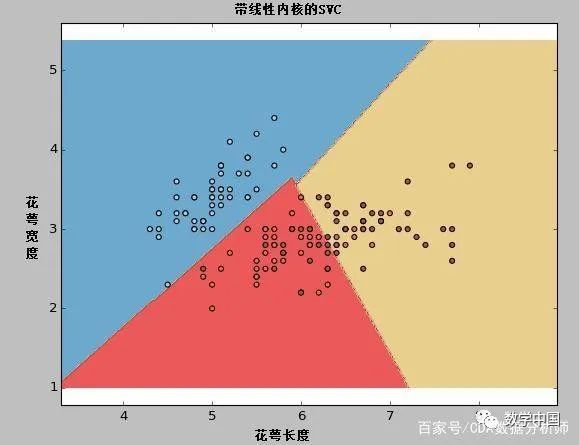
kernel:我們之間已經(jīng)簡單的討論過了。在算法參數(shù)中,我們可以為kernel值提供各種內(nèi)核選項(xiàng),如“l(fā)inear”,“rbf”,“poly”等(默認(rèn)值為“rbf”)。其中“rbf”和“poly”對(duì)于找到非線性超平面是很有用的。讓我們看一下這個(gè)例子,我們使用線性內(nèi)核函數(shù)對(duì)iris數(shù)據(jù)集中的兩個(gè)特性進(jìn)行分類。
示例:使用linear的內(nèi)核
import numpy as npimport matplotlib.pyplot as pltfrom sklearn import svm, datasets#導(dǎo)入數(shù)據(jù)iris = datasets.load_iris()X = iris.data[:, :2]#我們可以只考慮前兩個(gè)特征#我們可以使用雙數(shù)據(jù)集來避免丑陋的切片y = iris.target#我們創(chuàng)建了一個(gè)SVM實(shí)例并對(duì)數(shù)據(jù)進(jìn)行擬合。不進(jìn)行縮放#是因?yàn)槲覀兿胍嫵鲋С窒蛄?/span>C = 1.0#SVM正則化參數(shù)svc = svm.SVC(kernel='linear', C=1,gamma=0).fit(X, y)#創(chuàng)建一個(gè)網(wǎng)格來進(jìn)行可視化x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1h = (x_max / x_min)/100xx, yy = np.meshgrid(np.arange(x_min, x_max, h),np.arange(y_min, y_max, h))plt.subplot(1, 1, 1)Z = svc.predict(np.c_[xx.ravel(), yy.ravel()])Z = Z.reshape(xx.shape)plt.contourf(xx, yy, Z, cmap=plt.cm.Paired, alpha=0.8)plt.scatter(X[:, 0], X[:, 1], c=y, cmap=plt.cm.Paired)plt.xlabel('Sepal length')plt.ylabel('Sepal width')plt.xlim(xx.min(), xx.max())plt.title('SVC with linear kernel')plt.show()
示例:使用RBF內(nèi)核
將內(nèi)核類型更改為下面的代碼行中的rbf并查看影響。
svc = svm.SVC(kernel ='rbf',C = 1,gamma = 0).fit(X,y)
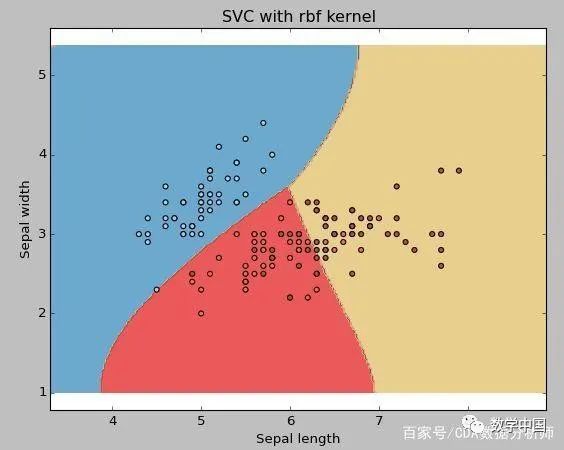
如果你有大量的特征數(shù)據(jù)(> 1000),那么我建議你去使用線性內(nèi)核,因?yàn)閿?shù)據(jù)在高維空間中更可能是線性可分的。此外,你也可以使用RBF,但不要忘記交叉驗(yàn)證其參數(shù),以避免過度擬合。
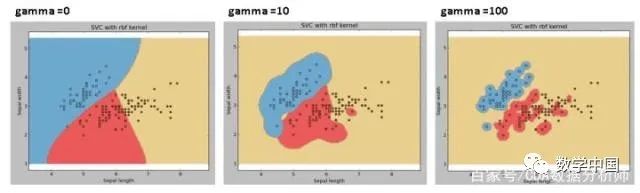
gamma:'rbf','poly'和'sigmoid'的內(nèi)核系數(shù)。伽馬值越高,則會(huì)根據(jù)訓(xùn)練數(shù)據(jù)集進(jìn)行精確擬合,也就是泛化誤差從而導(dǎo)致過擬合問題。
示例:如果我們使用不同的伽瑪值,如0,10或100,讓我們來查看一下不同的區(qū)別。
svc = svm.SVC(kernel ='rbf',C = 1,gamma = 0).fit(X,y)
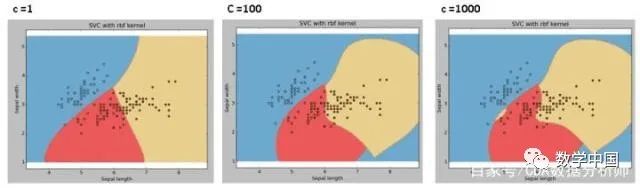
C:誤差項(xiàng)的懲罰參數(shù)C. 它還控制了平滑決策邊界與正確分類訓(xùn)練點(diǎn)之間的權(quán)衡。
我們應(yīng)該始終關(guān)注交叉驗(yàn)證的分?jǐn)?shù),以便更有效地組合這些參數(shù)并避免過度擬合。
5.SVM的優(yōu)缺點(diǎn)
優(yōu)點(diǎn):它工作的效果很明顯,有很好的分類作用
它在高維空間中同樣是有效的。
它在尺寸數(shù)量大于樣本數(shù)量的情況下,也是有效的。
它在決策函數(shù)(稱為支持向量)中使用訓(xùn)練點(diǎn)的子集,因此它的內(nèi)存也是有效的
缺點(diǎn):當(dāng)我們擁有大量的數(shù)據(jù)集時(shí),
它表現(xiàn)并不好,因?yàn)樗枰挠?xùn)練時(shí)間更長當(dāng)數(shù)據(jù)集具有很多噪聲,也就是目標(biāo)類重疊時(shí),
它的表現(xiàn)性能也不是很好SVM不直接提供概率估計(jì),這些是使用昂貴的五重交叉驗(yàn)證來計(jì)算的。它是Python scikit-learn庫的相關(guān)SVC方法。
實(shí)踐問題
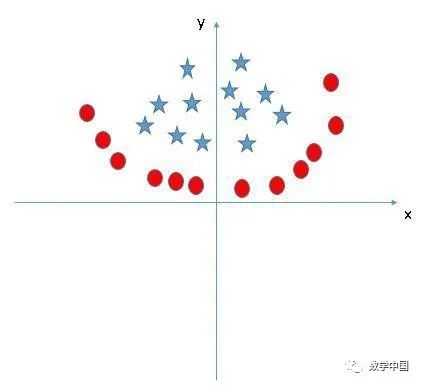
找到一個(gè)正確的超平面用來將下面圖片中的兩個(gè)類別進(jìn)行分類
結(jié)語
在本文中,我們詳細(xì)介紹了機(jī)器學(xué)習(xí)算法中的高階算法,支持向量機(jī)(SVM)。我們討論了它的工作原理,python中的實(shí)現(xiàn)過程,通過調(diào)整模型的參數(shù)來提高模型效率的技巧,討論了SVM的優(yōu)缺點(diǎn),以及最后留下的一個(gè)要你們自己解決的問題。我建議你使用SVM并通過調(diào)整參數(shù)來分析此模型的能力。
支持向量機(jī)是一種非常強(qiáng)大的分類算法。當(dāng)與隨機(jī)森林和其他機(jī)器學(xué)習(xí)工具結(jié)合使用時(shí),它們?yōu)榧夏P吞峁┝朔浅2煌木S度。因此,在需要非常高的預(yù)測能力的情況下,他們就顯得非常重要。由于公式的復(fù)雜性,這些算法可能稍微有些難以可視化。
謝謝大家觀看,如有幫助,來個(gè)喜歡或者關(guān)注吧!
本文僅供學(xué)習(xí)參考,有任何疑問及建議,掃描以下公眾號(hào)二維碼添加交流:
更多學(xué)習(xí)內(nèi)容,僅在知識(shí)星球發(fā)布: