
【82期】面試中被問到SQL優(yōu)化,看這篇就對(duì)了!

閱讀本文大概需要 7 分鐘。
來自:juejin.im/post/59b11ba151882538cb1ecbd0
前言
https://www.jianshu.com/p/098a870d83e4
1 基本概念簡述
1.1 邏輯架構(gòu)
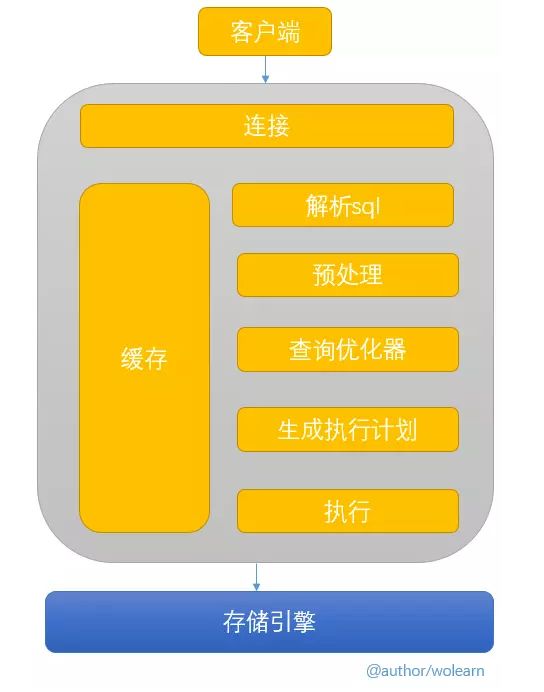
第一層:客戶端通過連接服務(wù),將要執(zhí)行的sql指令傳輸過來
第二層:服務(wù)器解析并優(yōu)化sql,生成最終的執(zhí)行計(jì)劃并執(zhí)行
第三層:存儲(chǔ)引擎,負(fù)責(zé)數(shù)據(jù)的儲(chǔ)存和提取
1.2 鎖
樂觀鎖,通常用于數(shù)據(jù)競爭不激烈的場景,多讀少寫,通過版本號(hào)和時(shí)間戳實(shí)現(xiàn)。
悲觀鎖,通常用于數(shù)據(jù)競爭激烈的場景,每次操作都會(huì)鎖定數(shù)據(jù)。
表鎖,鎖定整張表,開銷最小,但是會(huì)加劇鎖競爭。
行鎖,鎖定行級(jí)別,開銷最大,但是可以最大程度的支持并發(fā)。
1.3 事務(wù)
未提交讀(Read UnCommitted),事務(wù)中的修改,即使沒提交對(duì)其他事務(wù)也是可見的。事務(wù)可能讀取未提交的數(shù)據(jù),造成臟讀。
提交讀(Read Committed),一個(gè)事務(wù)開始時(shí),只能看見已提交的事務(wù)所做的修改。事務(wù)未提交之前,所做的修改對(duì)其他事務(wù)是不可見的。也叫不可重復(fù)讀,同一個(gè)事務(wù)多次讀取同樣記錄可能不同。
可重復(fù)讀(RepeatTable Read),同一個(gè)事務(wù)中多次讀取同樣的記錄結(jié)果時(shí)結(jié)果相同。
可串行化(Serializable),最高隔離級(jí)別,強(qiáng)制事務(wù)串行執(zhí)行。
1.4 存儲(chǔ)引擎
2 創(chuàng)建時(shí)優(yōu)化
2.1 Schema和數(shù)據(jù)類型優(yōu)化
Float,Double , 支持近似的浮點(diǎn)運(yùn)算。
Decimal,用于存儲(chǔ)精確的小數(shù)。
VarChar,存儲(chǔ)變長的字符串。需要1或2個(gè)額外的字節(jié)記錄字符串的長度。
Char,定長,適合存儲(chǔ)固定長度的字符串,如MD5值。
Blob,Text 為了存儲(chǔ)很大的數(shù)據(jù)而設(shè)計(jì)的。分別采用二進(jìn)制和字符的方式。
DateTime,保存大范圍的值,占8個(gè)字節(jié)。
TimeStamp,推薦,與UNIX時(shí)間戳相同,占4個(gè)字節(jié)。
盡量使用對(duì)應(yīng)的數(shù)據(jù)類型。比如,不要用字符串類型保存時(shí)間,用整型保存IP。
選擇更小的數(shù)據(jù)類型。能用TinyInt不用Int。
標(biāo)識(shí)列(identifier column),建議使用整型,不推薦字符串類型,占用更多空間,而且計(jì)算速度比整型慢。
不推薦ORM系統(tǒng)自動(dòng)生成的Schema,通常具有不注重?cái)?shù)據(jù)類型,使用很大的VarChar類型,索引利用不合理等問題。
真實(shí)場景混用范式和反范式。冗余高查詢效率高,插入更新效率低;冗余低插入更新效率高,查詢效率低。
創(chuàng)建完全的獨(dú)立的匯總表\緩存表,定時(shí)生成數(shù)據(jù),用于用戶耗時(shí)時(shí)間長的操作。對(duì)于精確度要求高的匯總操作,可以采用 歷史結(jié)果+最新記錄的結(jié)果 來達(dá)到快速查詢的目的。
數(shù)據(jù)遷移,表升級(jí)的過程中可以使用影子表的方式,通過修改原表的表名,達(dá)到保存歷史數(shù)據(jù),同時(shí)不影響新表使用的目的。
2.2 索引
減少查詢掃描的數(shù)據(jù)量
避免排序和零時(shí)表
將隨機(jī)IO變?yōu)轫樞騃O (順序IO的效率高于隨機(jī)IO)
如果不是按照索引的最左列開始查詢,則無法使用索引。
不能跳過索引中的列。如果使用第一列和第三列索引,則只能使用第一列索引。
如果查詢中有個(gè)范圍查詢,則其右邊的所有列都無法使用索引優(yōu)化查詢。
無法用于排序
不支持部分匹配
只支持等值查詢?nèi)?,IN(),不支持 < >
注意每種索引的適用范圍和適用限制。
索引的列如果是表達(dá)式的一部分或者是函數(shù)的參數(shù),則失效。
針對(duì)特別長的字符串,可以使用前綴索引,根據(jù)索引的選擇性選擇合適的前綴長度。
使用多列索引的時(shí)候,可以通過 AND 和 OR 語法連接。
重復(fù)索引沒必要,如(A,B)和(A)重復(fù)。
索引在where條件查詢和group by語法查詢的時(shí)候特別有效。
將范圍查詢放在條件查詢的最后,防止范圍查詢導(dǎo)致的右邊索引失效的問題。
索引最好不要選擇過長的字符串,而且索引列也不宜為null。
3 查詢時(shí)優(yōu)化
3.1 查詢質(zhì)量的三個(gè)重要指標(biāo)
響應(yīng)時(shí)間 (服務(wù)時(shí)間,排隊(duì)時(shí)間)
掃描的行
返回的行
3.2 查詢優(yōu)化點(diǎn)
避免查詢無關(guān)的列,如使用Select * 返回所有的列。
避免查詢無關(guān)的行
切分查詢。將一個(gè)對(duì)服務(wù)器壓力較大的任務(wù),分解到一個(gè)較長的時(shí)間中,并分多次執(zhí)行。如要?jiǎng)h除一萬條數(shù)據(jù),可以分10次執(zhí)行,每次執(zhí)行完成后暫停一段時(shí)間,再繼續(xù)執(zhí)行。過程中可以釋放服務(wù)器資源給其他任務(wù)。
分解關(guān)聯(lián)查詢。將多表關(guān)聯(lián)查詢的一次查詢,分解成對(duì)單表的多次查詢。可以減少鎖競爭,查詢本身的查詢效率也比較高。因?yàn)镸ySql的連接和斷開都是輕量級(jí)的操作,不會(huì)由于查詢拆分為多次,造成效率問題。
注意count的操作只能統(tǒng)計(jì)不為null的列,所以統(tǒng)計(jì)總的行數(shù)使用count(*)。
group by 按照標(biāo)識(shí)列分組效率高,分組結(jié)果不宜出行分組列之外的列。
關(guān)聯(lián)查詢延遲關(guān)聯(lián),可以根據(jù)查詢條件先縮小各自要查詢的范圍,再關(guān)聯(lián)。
Limit分頁優(yōu)化。可以根據(jù)索引覆蓋掃描,再根據(jù)索引列關(guān)聯(lián)自身查詢其他列。如
SELECT
?id,
?NAME,
?age
WHERE
?student?s1
INNER?JOIN?(
?SELECT
?????id
?FROM
?????student
?ORDER?BY
?????age
?LIMIT?50,5
)?AS?s2?ON?s1.id?=?s2.id
Union查詢默認(rèn)去重,如果不是業(yè)務(wù)必須,建議使用效率更高的Union All
補(bǔ)充內(nèi)容
來自大神-小寶
CREATE?TABLE?triangle?(sidea?DOUBLE,?sideb?DOUBLE,?area?DOUBLE?AS?(sidea?*?sideb?/?2));
insert?into?triangle(sidea,?sideb)?values(3,?4);
select?*?from?triangle;
+-------+-------+------+
|?sidea?|?sideb?|?area?|
+-------+-------+------+
|???3??????|???4??????|??6?????|
+-------+-------+------+
CREATE?TABLE?json_test?(name?JSON);
INSERT?INTO?json_test?VALUES('{"name1":?"value1",?"name2":?"value2"}');
SELECT?*?FROM?json_test?WHERE?JSON_CONTAINS(name,?'$.name1');
來自JVM專家-達(dá)
EXPLAIN?SELECT?settleId?FROM?Settle?WHERE?settleId?=?"3679"

select_type,有幾種值:simple(表示簡單的select,沒有union和子查詢),primary(有子查詢,最外面的select查詢就是primary),union(union中的第二個(gè)或隨后的select查詢,不依賴外部查詢結(jié)果),dependent union(union中的第二個(gè)或隨后的select查詢,依賴外部查詢結(jié)果)
type,有幾種值:system(表僅有一行(=系統(tǒng)表),這是const連接類型的一個(gè)特例),const(常量查詢), ref(非唯一索引訪問,只有普通索引),eq_ref(使用唯一索引或組件查詢),all(全表查詢),index(根據(jù)索引查詢?nèi)恚瑀ange(范圍查詢)
possible_keys: 表中可能幫助查詢的索引
key,選擇使用的索引
key_len,使用的索引長度
rows,掃描的行數(shù),越大越不好
extra,有幾種值:Only index(信息從索引中檢索出,比掃描表快),where used(使用where限制),Using filesort (可能在內(nèi)存或磁盤排序),Using temporary(對(duì)查詢結(jié)果排序時(shí)使用臨時(shí)表)
推薦閱讀:
網(wǎng)絡(luò)故障排除工具 | 快速定位網(wǎng)絡(luò)故障
微信掃描二維碼,關(guān)注我的公眾號(hào)
朕已閱?