
Java協(xié)程實踐指南(一)

一. 協(xié)程產生的背景
說起協(xié)程,大多數(shù)人的第一印象可能就是GoLang,這也是Go語言非常吸引人的地方之一,它內建的并發(fā)支持。Go語言并發(fā)體系的理論是C.A.R Hoare在1978年提出的CSP(Communicating Sequential Process,通訊順序進程)。CSP有著精確的數(shù)學模型,并實際應用在了Hoare參與設計的T9000通用計算機上。從NewSqueak、Alef、Limbo到現(xiàn)在的Go語言,對于對CSP有著20多年實戰(zhàn)經驗的Rob Pike來說,他更關注的是將CSP應用在通用編程語言上產生的潛力。作為Go并發(fā)編程核心的CSP理論的核心概念只有一個:同步通信。
首先要明確一個概念:并發(fā)不是并行。并發(fā)更關注的是程序的設計層面,并發(fā)的程序完全是可以順序執(zhí)行的,只有在真正的多核CPU上才可能真正地同時運行。并行更關注的是程序的運行層面,并行一般是簡單的大量重復,例如GPU中對圖像處理都會有大量的并行運算。為更好的編寫并發(fā)程序,從設計之初Go語言就注重如何在編程語言層級上設計一個簡潔安全高效的抽象模型,讓程序員專注于分解問題和組合方案,而且不用被線程管理和信號互斥這些繁瑣的操作分散精力。
在并發(fā)編程中,對共享資源的正確訪問需要精確的控制,在目前的絕大多數(shù)語言中,都是通過加鎖等線程同步方案來解決這一困難問題,而Go語言卻另辟蹊徑,它將共享的值通過Channel傳遞(實際上多個獨立執(zhí)行的線程很少主動共享資源)。在任意給定的時刻,最好只有一個Goroutine能夠擁有該資源。數(shù)據競爭從設計層面上就被杜絕了。為了提倡這種思考方式,Go語言將其并發(fā)編程哲學化為一句口號:

Do not communicate by sharing memory; instead, share memory by communicating.
不要通過共享內存來通信,而應通過通信來共享內存。
這是更高層次的并發(fā)編程哲學(通過管道來傳值是Go語言推薦的做法)。雖然像引用計數(shù)這類簡單的并發(fā)問題通過原子操作或互斥鎖就能很好地實現(xiàn),但是通過Channel來控制訪問能夠讓你寫出更簡潔正確的程序。
在《七周七并發(fā)模型》中描述的七種并發(fā)編程模型。
參考:?https://www.cnblogs.com/barrywxx/p/10406978.html
線程與鎖:線程與鎖模型有很多眾所周知的不足,但仍是其他模型的技術基礎,也是很多并發(fā)軟件開發(fā)的首選。
函數(shù)式編程:函數(shù)式編程日漸重要的原因之一,是其對并發(fā)編程和并行編程提供了良好的支持。函數(shù)式編程消除了可變狀態(tài),所以從根本上是線程安全的,而且易于并行執(zhí)行。
Clojure之道——分離標識與狀態(tài):編程語言Clojure是一種指令式編程和函數(shù)式編程的混搭方案,在兩種編程方式上取得了微妙的平衡來發(fā)揮兩者的優(yōu)勢。
actor:actor模型是一種適用性很廣的并發(fā)編程模型,適用于共享內存模型和分布式內存模型,也適合解決地理分布型問題,能提供強大的容錯性。
通信順序進程(Communicating Sequential Processes,CSP):表面上看,CSP模型與actor模型很相似,兩者都基于消息傳遞。不過CSP模型側重于傳遞信息的通道,而actor模型側重于通道兩端的實體,使用CSP模型的代碼會帶有明顯不同的風格。
數(shù)據級并行:每個筆記本電腦里都藏著一臺超級計算機——GPU。GPU利用了數(shù)據級并行,不僅可以快速進行圖像處理,也可以用于更廣闊的領域。如果要進行有限元分析、流體力學計算或其他的大量數(shù)字計算,GPU的性能將是不二選擇。
Lambda架構:大數(shù)據時代的到來離不開并行——現(xiàn)在我們只需要增加計算資源,就能具有處理TB級數(shù)據的能力。Lambda架構綜合了MapReduce和流式處理的特點,是一種可以處理多種大數(shù)據問題的架構。
通常語言的并發(fā)模型有以下幾種。
線程模型
操作系統(tǒng)抽象,開發(fā)效率高,IO密集、高并發(fā)下切換開銷大。
異步模型
編程框架抽象,執(zhí)行效率高,破壞結構化編程,開發(fā)門檻高。
協(xié)程模型
語言運行時抽象,輕量級線程,兼顧開發(fā)效率和執(zhí)行效率。
二. Java協(xié)程發(fā)展歷程
Java本身有著豐富的異步編程框架,比如說CompletableFuture,在一定程度上緩解了Java使用協(xié)程的緊迫性。
在2010年,JKU大學發(fā)表了一篇論文《高效的協(xié)程》,向OpenJdk社區(qū)提了一個協(xié)程框架的Patch,在2013年Quasar和Coroutine,這兩種協(xié)程框架不需要修改Runtime,在協(xié)程切換時本來是要保存調用棧的,但是它們不保存這個調用棧,而是在切換時回溯調用鏈,生成一個狀態(tài)機,將狀態(tài)機保存起來。

Quasar和Coroutine并不是OpenJdk社區(qū)原生的協(xié)程解決方案,直到2018年1月,官方提出了Project Loom,到了2019年,Loom的首個EA版本問世,此時Java的協(xié)程類叫做Fiber,但社區(qū)覺得這引入了一個新的概念,于是在2019年10月將Fiber重新實現(xiàn)為了Thread的子類VirtualThread,兼容Thread的所有操作。
這時Project Loom的基本雛形已經完成了,在它的概念中,協(xié)程就是一個特殊的線程,是線程的一個子類,從Project Loom已經可以看到Open Jdk社區(qū)未來協(xié)程發(fā)展的方向, 但Loom還有很多的工作需要完成,并沒有完全開發(fā)完。
三. Project Loom的目標與挑戰(zhàn)
目標
易于理解的Java協(xié)程系統(tǒng)解決方案,協(xié)程即線程。
Virtual threads are just threads that are scheduled by the Java virtual machine rather than the operating system.
挑戰(zhàn)
兼容龐大而復雜的標準類庫、JVM特性,同時支持協(xié)程和線程。
四. Loom實現(xiàn)架構
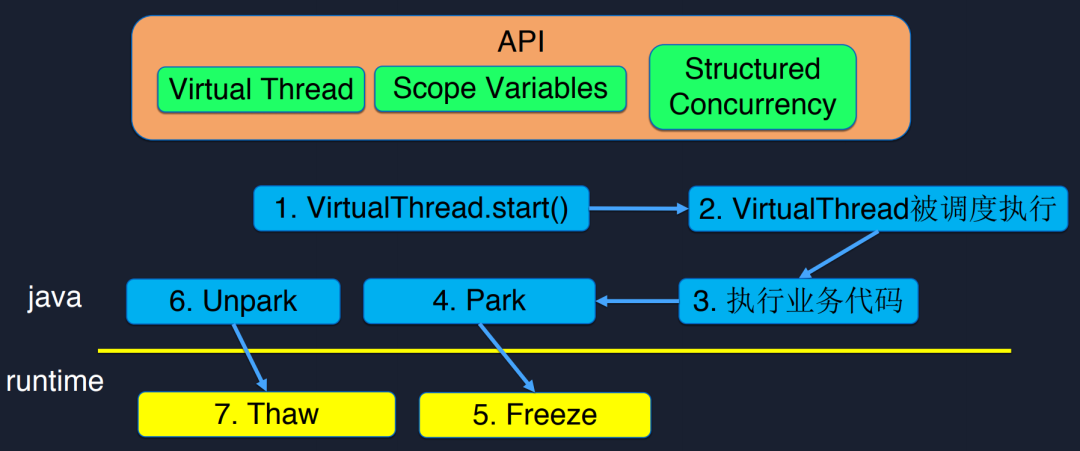
在API層面Loom引入最重要的概念就是Virtual Thread,對于使用者來說可以當做Thread來理解。
下面是協(xié)程生命周期的描述,與線程相同需要一個start函數(shù)開始執(zhí)行,接下來VirtualThread就會被調度執(zhí)行,與線程不同的是,協(xié)程的上層需要一個調度器來調度它,而不是被操作系統(tǒng)直接調度,被調度執(zhí)行后就是執(zhí)行業(yè)務代碼,此時我們業(yè)務代碼可能會遇到一個數(shù)據庫訪問或者IO操作,這時當前協(xié)程就會被Park起來,與線程相同,此時我們的協(xié)程需要在切換前保存上下文,這步操作是由Runtime的Freeze來執(zhí)行,等到IO操作完成,協(xié)程被喚醒繼續(xù)執(zhí)行,這時就要恢復上下文,這一步叫做Thaw。
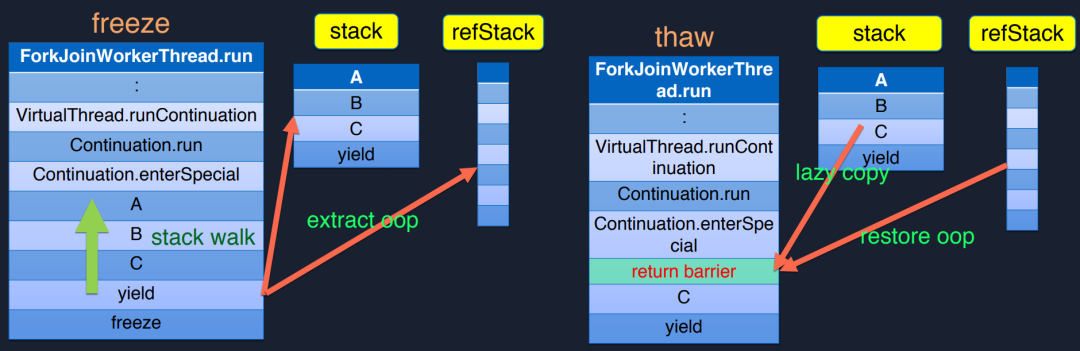
1. Freeze操作
上圖左側是對Freeze的介紹,首先一個協(xié)程要被執(zhí)行需要一個調度器,在Java生態(tài)本身就有一個非常不錯的調度器ForkJoinPool,Loom也默認使用ForkJoinPool來作為調度器。
圖中ForkJoinWorkerThread調用棧前半部分直到enterSpecial都是類庫的調用棧,用戶不需要考慮,A可以理解為用戶自己的實現(xiàn),從函數(shù)A調用到函數(shù)B,函數(shù)B調用函數(shù)C,函數(shù)C此時有一個數(shù)據訪問,就會將當前協(xié)程掛起,yield操作會去保存當前協(xié)程的執(zhí)行上下文,調用freeze,freeze會做一個stack walk,從當前調用棧的最后一層(yield)回溯到用戶調用(函數(shù)A),將這些內容拷貝到一個stack。這也是協(xié)程棧大小不固定的原因,我們可以動態(tài)擴縮協(xié)程需要的空間,而線程棧大小默認1M,不管用沒用到。而協(xié)程按需使用的特點,可以創(chuàng)建的數(shù)量非常多。extract_pop是Loom非常好的一個優(yōu)化,它將ABC調用棧中的Java對象單獨拷貝到一個refStack,在GC root時,如果把協(xié)程棧也當做root,幾百萬個協(xié)程會導致掃描停頓很久,Loom將所有對象都提到一個refStack里面,只需要處理這個stack即可,避免過多的協(xié)程棧增加GC時間。
2. Thaw操作
Thaw用于恢復執(zhí)行,如果將stack里面ABC、yield全部拷貝回執(zhí)行棧里面可能是很耗時的,因為執(zhí)行棧可能非常深了,Loom社區(qū)成員在調研后發(fā)現(xiàn),函數(shù)C可能不止一個數(shù)據訪問操作,在恢復執(zhí)行棧之后,可能因為C的IO操作又會再次切換上下文,所以Loom用了一種lazy copy的方式,每次只拷貝一部分,執(zhí)行完成之后遇到return barrier則繼續(xù)去stack中拷貝。這樣除了第一次切換開銷比較大,其他所有的切換開銷都會很小。
另一方面refStack里面保存的OOP要restore回來,因為很多的GC可能在執(zhí)行時將OOP地址改了,如果不restore之后訪問可能會出現(xiàn)問題。
五. Loom使用
Virtual Thread創(chuàng)建
通過Thread.builder創(chuàng)建VirtualThread
通過Thread.builder創(chuàng)建VirtualThread工廠
默認ForkJoinPool調度器(負載均衡、自動擴展),支持定制調度器
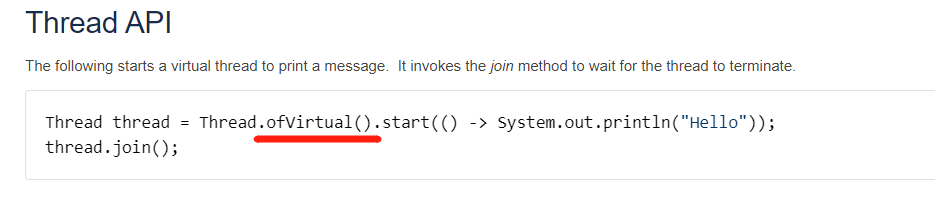
定制調度器
static ExecutorService SCHEDULER_1 = Executors.newFixedThreadPool(1);Thread thread = Thread.ofVirtual().scheduler(SCHEDULER_1).start(() -> System.out.println("Hello"));thread.join();
創(chuàng)建協(xié)程池
ThreadFactory factory;if (usrFiber == false) {factory = Thread.builder().factory();else {factory = Thread.builder().ofVirtual().factory();}ExecutorService e = Executors.newFixThreadPool(threadCount, factory);for (int i=0; i < requestCount; i++) {e.execute(r);}