
MongoDB + Spark: 完整的大數(shù)據(jù)解決方案
點(diǎn)擊上方藍(lán)色字體,選擇“設(shè)為星標(biāo)”




Spark介紹
按照官方的定義,Spark 是一個(gè)通用,快速,適用于大規(guī)模數(shù)據(jù)的處理引擎。
通用性:我們可以使用Spark SQL來(lái)執(zhí)行常規(guī)分析, Spark Streaming 來(lái)流數(shù)據(jù)處理, 以及用Mlib來(lái)執(zhí)行機(jī)器學(xué)習(xí)等。Java,python,scala及R語(yǔ)言的支持也是其通用性的表現(xiàn)之一。
快速:這個(gè)可能是Spark成功的最初原因之一,主要?dú)w功于其基于內(nèi)存的運(yùn)算方式。當(dāng)需要處理的數(shù)據(jù)需要反復(fù)迭代時(shí),Spark可以直接在內(nèi)存中暫存數(shù)據(jù),而無(wú)需像Map Reduce一樣需要把數(shù)據(jù)寫(xiě)回磁盤(pán)。官方的數(shù)據(jù)表明:它可以比傳統(tǒng)的Map Reduce快上100倍。
大規(guī)模:原生支持HDFS,并且其計(jì)算節(jié)點(diǎn)支持彈性擴(kuò)展,利用大量廉價(jià)計(jì)算資源并發(fā)的特點(diǎn)來(lái)支持大規(guī)模數(shù)據(jù)處理。
我們能用它做什么
那我們能用Spark來(lái)做什么呢?場(chǎng)景數(shù)不勝數(shù)。
最簡(jiǎn)單的可以只是統(tǒng)計(jì)一下某一個(gè)頁(yè)面多少點(diǎn)擊量,復(fù)雜的可以通過(guò)機(jī)器學(xué)習(xí)來(lái)預(yù)測(cè)。
個(gè)性化?是一個(gè)常見(jiàn)的案例,比如說(shuō),Yahoo的網(wǎng)站首頁(yè)使用Spark來(lái)實(shí)現(xiàn)快速的用戶(hù)興趣分析。應(yīng)該在首頁(yè)顯示什么新聞?原始的做法是讓用戶(hù)選擇分類(lèi);聰明的做法就是在用戶(hù)交互的過(guò)程中揣摩用戶(hù)可能喜歡的文章。另一方面就是要在新聞進(jìn)來(lái)時(shí)候進(jìn)行分析并確定什么樣的用戶(hù)是可能的受眾。新聞的時(shí)效性非常高,按照常規(guī)的MapReduce做法,對(duì)于Yahoo幾億用戶(hù)及海量的文章,可能需要計(jì)算一天才能得出結(jié)果。Spark的高效運(yùn)算可以在這里得到充分的運(yùn)用,來(lái)保證新聞推薦在數(shù)十分鐘或更短時(shí)間內(nèi)完成。另外,如美國(guó)最大的有線(xiàn)電視商Comcast用它來(lái)做節(jié)目推薦,最近剛和滴滴聯(lián)姻的uber用它實(shí)時(shí)訂單分析,優(yōu)酷則在Spark上實(shí)現(xiàn)了商業(yè)智能的升級(jí)版。
Spark生態(tài)系統(tǒng)
在我們開(kāi)始談MongoDB 和Spark 之前,我們首先來(lái)了解一下Spark的生態(tài)系統(tǒng)。Spark 作為一個(gè)大型分布式計(jì)算框架,需要和其他組件一起協(xié)同工作。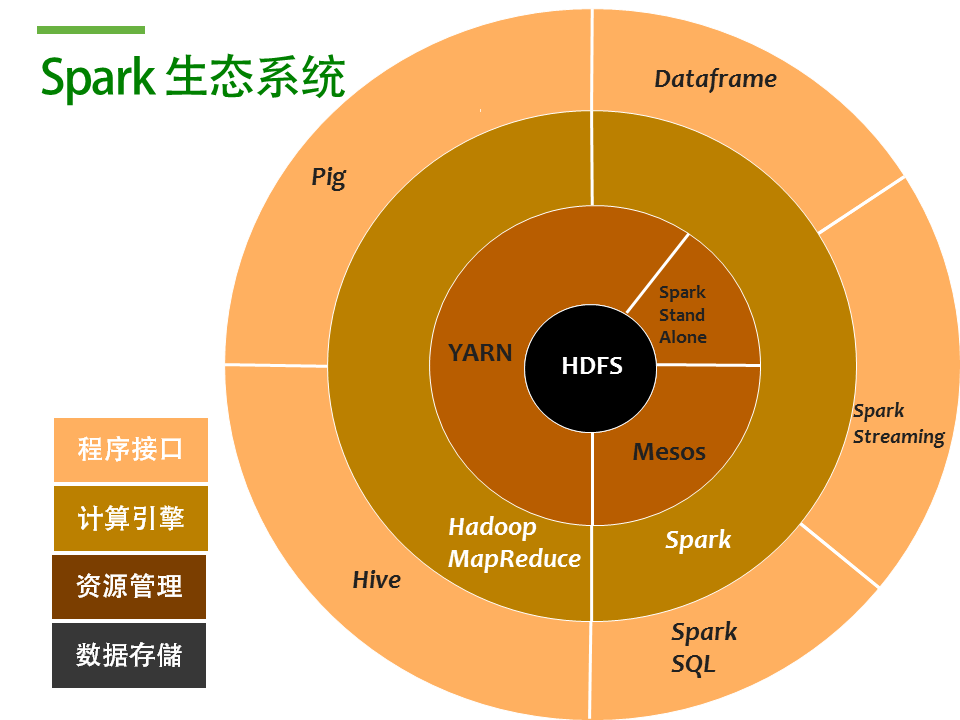
在Hdaoop里面,HDFS是其核心,作為一個(gè)數(shù)據(jù)層。
Spark是Hadoop生態(tài)系統(tǒng)的一顆新星,原生就支持HDFS。大家知道HDFS是用來(lái)管理大規(guī)模非結(jié)構(gòu)化數(shù)據(jù)的存儲(chǔ)系統(tǒng),具有高可用和巨大的橫向擴(kuò)展能力。
而作為一個(gè)橫向擴(kuò)展的分布式集群,資源管理是其核心必備的能力,Spark 可以通過(guò)YARN或者M(jìn)ESOS來(lái)負(fù)責(zé)資源(CPU)分配和任務(wù)調(diào)度。如果你不需要管理節(jié)點(diǎn)的高可用需求,你也可以直接使用Spark standalone。
在有了數(shù)據(jù)層和資源管理層后, 接下來(lái)就是我們真正的計(jì)算引擎。
Hadoop技術(shù)的兩大基石之一的MapReduce就是用來(lái)實(shí)現(xiàn)集群大規(guī)模并行計(jì)算。而現(xiàn)在就多了一個(gè)選項(xiàng):Spark。Map Reduce的特點(diǎn)是,用4個(gè)字來(lái)概括,簡(jiǎn)單粗暴。采用divide & conquer戰(zhàn)術(shù),我們可以用Map Reduce來(lái)處理PB級(jí)的數(shù)據(jù)。而Spark 作為打了雞血的Map Reduce增強(qiáng)版,利用了內(nèi)存價(jià)格大量下降的時(shí)代因素,充分把計(jì)算所用變量和中間結(jié)果放到內(nèi)存里,并且提供了一整套機(jī)器學(xué)習(xí)的分析算法,在加上很多語(yǔ)言的支持,使之成為一個(gè)較之于Map Reduce更加優(yōu)秀的選擇。
由于MapReduce 是一個(gè)相對(duì)并不直觀(guān)的程序接口,所以為了方便使用,一系列的高層接口如Hive或者Pig應(yīng)運(yùn)而生。Hive可以讓我們使用非常熟悉的SQL語(yǔ)句的方式來(lái)做一些常見(jiàn)的統(tǒng)計(jì)分析工作。同理,在Spark 引擎層也有類(lèi)似的封裝,如Spark SQL、RDD以及2.0版本新推出的Dataframe等。
所以一個(gè)完整的大數(shù)據(jù)解決方案,包含了存儲(chǔ),資源管理,計(jì)算引擎及接口層。那么問(wèn)題來(lái)了:我們畫(huà)了這么大這么圓的大餅,MongoDB可以吃哪一塊呢?
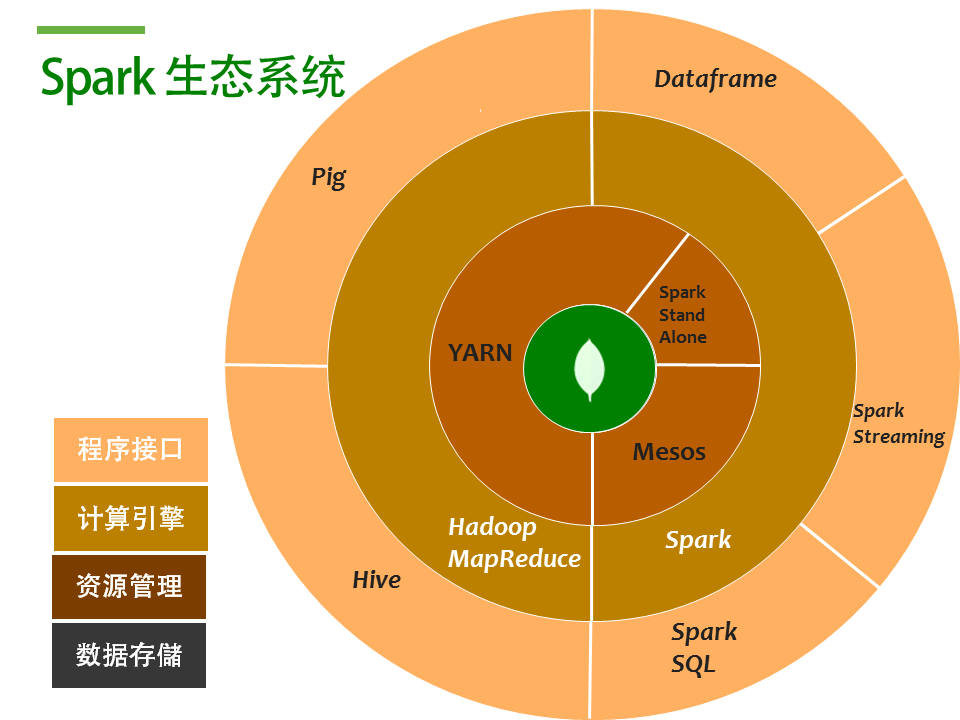
MongoDB是個(gè)什么?是個(gè)database。所以自然而然,MongoDB可以擔(dān)任的角色,就是數(shù)據(jù)存儲(chǔ)的這一部分。在和 Spark一起使用的時(shí)候,MongoDB就可以扮演HDFS的角色來(lái)為Spark提供計(jì)算的原始數(shù)據(jù),以及用來(lái)持久化分析計(jì)算的結(jié)果。
HDFS vs. MongoDB
既然我們說(shuō)MongoDB可以用在HDFS的地方,那我們來(lái)詳細(xì)看看兩者之間的差異性。
在說(shuō)區(qū)別之前,其實(shí)我們可以先來(lái)注意一下兩者的共同點(diǎn)。HDFS和MongoDB都是基于廉價(jià)x86服務(wù)器的橫向擴(kuò)展架構(gòu),都能支持到TB到PB級(jí)的數(shù)據(jù)量。數(shù)據(jù)會(huì)在多節(jié)點(diǎn)自動(dòng)備份,來(lái)保證數(shù)據(jù)的高可用和冗余。兩者都支持非結(jié)構(gòu)化數(shù)據(jù)的存儲(chǔ),等等。
但是,HDFS和MongoDB更多的是差異點(diǎn):
如在存儲(chǔ)方式上 HDFS的存儲(chǔ)是以文件為單位,每個(gè)文件64MB到128MB不等。而MongoDB則是細(xì)顆粒化的、以文檔為單位的存儲(chǔ)。
HDFS不支持索引的概念,對(duì)數(shù)據(jù)的操作局限于掃描性質(zhì)的讀,MongoDB則支持基于二級(jí)索引的快速檢索。
MongoDB可以支持常見(jiàn)的增刪改查場(chǎng)景,而HDFS一般只是一次寫(xiě)入后就很難進(jìn)行修改。
從響應(yīng)時(shí)間上來(lái)說(shuō),HDFS一般是分鐘級(jí)別而MongoDB對(duì)手請(qǐng)求的響應(yīng)時(shí)間通常以毫秒作為單位。
一個(gè)日志的例子
如果說(shuō)剛才的比較有些抽象,我們可以結(jié)合一個(gè)實(shí)際一點(diǎn)的例子來(lái)理解。
比如說(shuō),一個(gè)比較經(jīng)典的案例可能是日志記錄管理。在HDFS里面你可能會(huì)用日期范圍來(lái)命名文件,如7月1日,7月2日等等,每個(gè)文件是個(gè)日志文本文件,可能會(huì)有幾萬(wàn)到幾十萬(wàn)行日志。
而在MongoDB里面,我們可以采用一個(gè)JSON的格式,每一條日志就是一個(gè)JSON document。我們可以對(duì)某幾個(gè)關(guān)心的字段建索引,如時(shí)間戳,錯(cuò)誤類(lèi)型等。
我們來(lái)考慮一些場(chǎng)景,加入我們相對(duì)7月份所有日志做一些全量的統(tǒng)計(jì),比如每個(gè)頁(yè)面的所有點(diǎn)擊量,那么這個(gè)HDFS和MongoDB都可以正常處理。
如果有一天你的經(jīng)理告訴你:他想知道網(wǎng)站上每天有多少404錯(cuò)誤在發(fā)生,這個(gè)時(shí)候如果你用HDFS,就還是需要通過(guò)全量掃描所有行,而MongoDB則可以通過(guò)索引,很快地找到所有的404日志,可能花數(shù)秒鐘就可以解答你經(jīng)理的問(wèn)題。
又比如說(shuō),如果你希望對(duì)每個(gè)日志項(xiàng)加一個(gè)自定義的屬性,在進(jìn)行一些預(yù)處理后,MongoDB就會(huì)比較容易地支持到。而一般來(lái)說(shuō),HDFS是不支持更新類(lèi)型操作的。
好的,我們了解了MongoDB為什么可以替換HDFS并且為什么有這個(gè)必要來(lái)做這個(gè)事情,下面我們就來(lái)看看Spark和MongoDB怎么玩!
Spark + MongoDB
Spark的工作流程可以概括為三部曲:創(chuàng)建并發(fā)任務(wù),對(duì)數(shù)據(jù)進(jìn)行transformation操作,如map, filter,union,intersect等,然后執(zhí)行運(yùn)算,如reduce,count,或者簡(jiǎn)單地收集結(jié)果。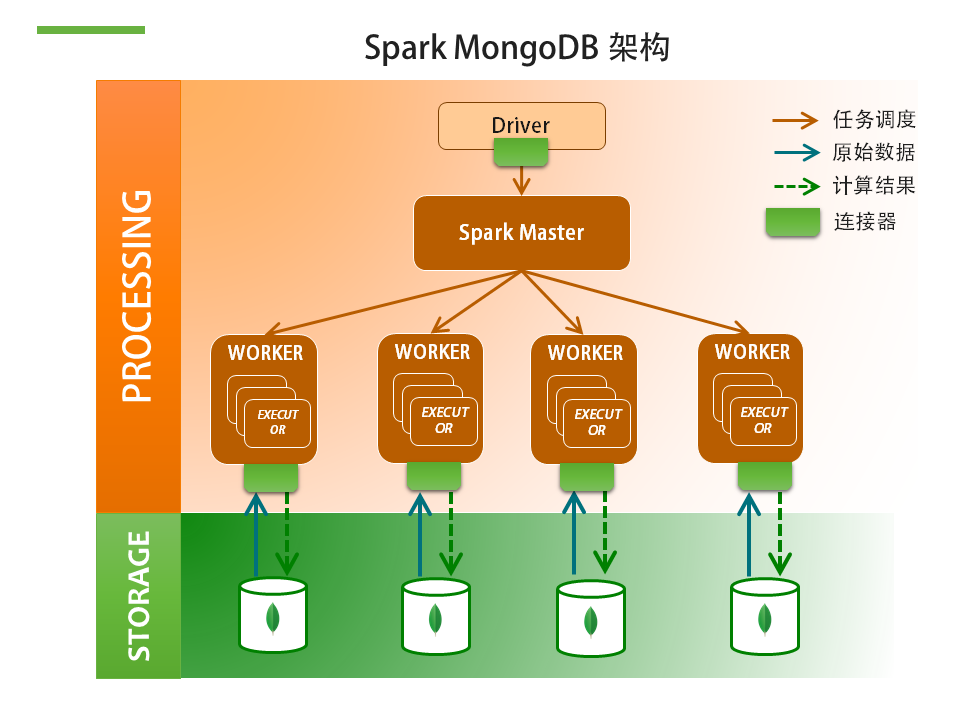
這里是Spark和MongoDB部署的一個(gè)典型架構(gòu)。
Spark任務(wù)一般由Spark的driver節(jié)點(diǎn)發(fā)起,經(jīng)過(guò)Spark Master進(jìn)行資源調(diào)度分發(fā)。比如這里我們有4個(gè)Spark worker節(jié)點(diǎn),這些節(jié)點(diǎn)上的幾個(gè)executor 計(jì)算進(jìn)程就會(huì)同時(shí)開(kāi)始工作。一般一個(gè)core就對(duì)應(yīng)一個(gè)executor。
每個(gè)executor會(huì)獨(dú)立的去MongoDB取來(lái)原始數(shù)據(jù),直接套用Spark提供的分析算法或者使用自定義流程來(lái)處理數(shù)據(jù),計(jì)算完后把相應(yīng)結(jié)果寫(xiě)回到MongoDB。
我們需要提到的是:在這里,所有和MongoDB的交互都是通過(guò)一個(gè)叫做Mongo-Spark的連接器來(lái)完成的。
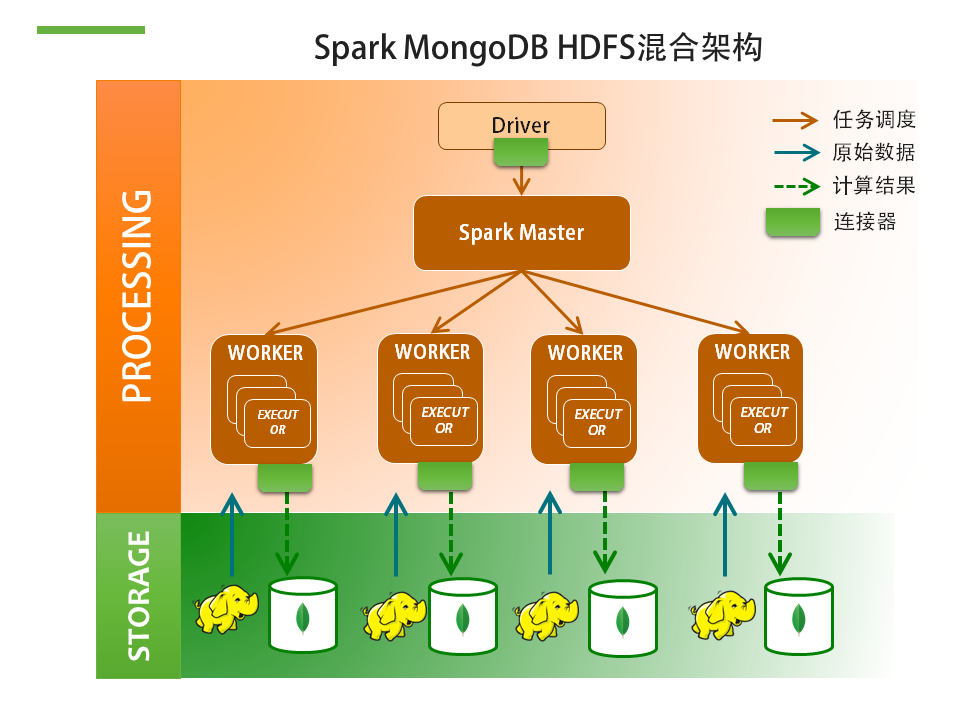
另一種常見(jiàn)的架構(gòu)是結(jié)合MongoDB和HDFS的。Hadoop在非結(jié)構(gòu)化數(shù)據(jù)處理的場(chǎng)景下要比MongoDB的普及率高。所以我們可以看到不少用戶(hù)會(huì)已經(jīng)將數(shù)據(jù)存放在HDFS上。這個(gè)時(shí)候你可以直接在HDFS上面架Spark來(lái)跑,Spark從HDFS取來(lái)原始數(shù)據(jù)進(jìn)行計(jì)算,而MongoDB在這個(gè)場(chǎng)景下是用來(lái)保存處理結(jié)果。為什么要這么麻煩?幾個(gè)原因:
Spark處理結(jié)果數(shù)量可能會(huì)很大,比如說(shuō),個(gè)性化推薦可能會(huì)產(chǎn)生數(shù)百萬(wàn)至數(shù)千萬(wàn)條記錄,需要一個(gè)能夠支持每秒萬(wàn)級(jí)寫(xiě)入能力的數(shù)據(jù)庫(kù)
處理結(jié)果可以直接用來(lái)驅(qū)動(dòng)前臺(tái)APP,如用戶(hù)打開(kāi)頁(yè)面時(shí)獲取后臺(tái)已經(jīng)為他準(zhǔn)備好的推薦列表。
Mongo Spark Connector 連接器
在這里我們?cè)诮榻B下MongoDB官方提供的Mongo Spark連接器?。目前有3個(gè)連接器可用,包括社區(qū)第三方開(kāi)發(fā)的和之前Mongo Hadoop連接器等,這個(gè)Mongo-Spark是最新的,也是我們推薦的連接方案。
這個(gè)連接器是專(zhuān)門(mén)為Spark打造的,支持雙向數(shù)據(jù),讀出和寫(xiě)入。但是最關(guān)鍵的是條件下推,也就是說(shuō):如果你在Spark端指定了查詢(xún)或者限制條件的情況下,這個(gè)條件會(huì)被下推到MongoDB去執(zhí)行,這樣可以保證從MongoDB取出來(lái)、經(jīng)過(guò)網(wǎng)絡(luò)傳輸?shù)絊park計(jì)算節(jié)點(diǎn)的數(shù)據(jù)確實(shí)都是用得著的。沒(méi)有下推支持的話(huà),每次操作很可能需要從MongoDB讀取全量的數(shù)據(jù),性能體驗(yàn)將會(huì)很糟糕。拿剛才的日志例子來(lái)說(shuō),如果我們只想對(duì)404錯(cuò)誤日志進(jìn)行分析,看那些錯(cuò)誤都是哪些頁(yè)面,以及每天錯(cuò)誤頁(yè)面數(shù)量的變化,如果有條件下推,那么我們可以給MongoDB一個(gè)限定條件:錯(cuò)誤代碼=404, 這個(gè)條件會(huì)在MongoDB服務(wù)器端執(zhí)行,這樣我們只需要通過(guò)網(wǎng)絡(luò)傳輸可能只是全部日志的0.1%的數(shù)據(jù),而不是沒(méi)有條件下推情況下的全部數(shù)據(jù)。
另外,這個(gè)最新的連接器還支持和Spark計(jì)算節(jié)點(diǎn)Co-Lo 部署。就是說(shuō)在同一個(gè)節(jié)點(diǎn)上同時(shí)部署Spark實(shí)例和MongoDB實(shí)例。這樣做可以減少數(shù)據(jù)在網(wǎng)絡(luò)上的傳輸帶來(lái)的資源消耗及時(shí)延。當(dāng)然,這種部署方式需要注意內(nèi)存資源和CPU資源的隔離。隔離的方式可以通過(guò)Linux的cgroups。
Spark + MongoDB 成功案例
目前已經(jīng)有很多案例在不同的應(yīng)用場(chǎng)景中使用Spark+MongoDB。
法國(guó)航空是法國(guó)最大的航空公司,為了提高客戶(hù)體驗(yàn),在最近施行的360度客戶(hù)視圖中,使用Spark對(duì)已經(jīng)收集在MongoDB里面的客戶(hù)數(shù)據(jù)進(jìn)行分類(lèi)及行為分析,并把結(jié)果(如客戶(hù)的類(lèi)別、標(biāo)簽等信息)寫(xiě)回到MongoDB內(nèi)每一個(gè)客戶(hù)的文檔結(jié)構(gòu)里。
Stratio是美國(guó)硅谷一家著名的金融大數(shù)據(jù)公司。他們最近在一家在31個(gè)國(guó)家有分支機(jī)構(gòu)的跨國(guó)銀行實(shí)施了一個(gè)實(shí)時(shí)監(jiān)控平臺(tái)。該銀行希望通過(guò)對(duì)日志的監(jiān)控和分析來(lái)保證客戶(hù)服務(wù)的響應(yīng)時(shí)間以及實(shí)時(shí)監(jiān)測(cè)一些可能的違規(guī)或者金融欺詐行為。在這個(gè)應(yīng)用內(nèi), 他們使用了:
Stratio是美國(guó)硅谷一家著名的金融大數(shù)據(jù)公司。他們最近在一家在31個(gè)國(guó)家有分支機(jī)構(gòu)的跨國(guó)銀行實(shí)施了一個(gè)實(shí)時(shí)監(jiān)控平臺(tái)。該銀行希望通過(guò)對(duì)日志的監(jiān)控和分析來(lái)保證客戶(hù)服務(wù)的響應(yīng)時(shí)間以及實(shí)時(shí)監(jiān)測(cè)一些可能的違規(guī)或者金融欺詐行為。在這個(gè)應(yīng)用內(nèi), 他們使用了:
Apache Flume 來(lái)收集log
Spark來(lái)處理實(shí)時(shí)的log
MongoDB來(lái)存儲(chǔ)收集的log以及Spark分析的結(jié)果,如Key Performance Indicators等
東方航空最近剛完成一個(gè)Spark運(yùn)價(jià)的POC測(cè)試。
東方航空的挑戰(zhàn)
東方航空作為國(guó)內(nèi)的3大行之一,每天有1000多個(gè)航班,服務(wù)26萬(wàn)多乘客。過(guò)去,顧客在網(wǎng)站上訂購(gòu)機(jī)票,平均資料庫(kù)查詢(xún)200次就會(huì)下單訂購(gòu)機(jī)票,但是現(xiàn)在平均要查詢(xún)1.2萬(wàn)次才會(huì)發(fā)生一次訂購(gòu)行為,同樣的訂單量,查詢(xún)量卻成長(zhǎng)百倍。按照50%直銷(xiāo)率這個(gè)目標(biāo)計(jì)算,東航的運(yùn)價(jià)系統(tǒng)要支持每天16億的運(yùn)價(jià)請(qǐng)求。
思路:空間換時(shí)間
當(dāng)前的運(yùn)價(jià)是通過(guò)實(shí)時(shí)計(jì)算的,按照現(xiàn)在的計(jì)算能力,需要對(duì)已有系統(tǒng)進(jìn)行100多倍的擴(kuò)容。另一個(gè)常用的思路,就是采用空間換時(shí)間的方式。與其對(duì)每一次的運(yùn)價(jià)請(qǐng)求進(jìn)行耗時(shí)300ms的運(yùn)算,不如事先把所有可能的票價(jià)查詢(xún)組合窮舉出來(lái)并進(jìn)行批量計(jì)算,然后把結(jié)果存入MongoDB里面。當(dāng)需要查詢(xún)運(yùn)價(jià)時(shí),直接按照 出發(fā)+目的地+日期的方式做一個(gè)快速的DB查詢(xún),響應(yīng)時(shí)間應(yīng)該可以做到幾十毫秒。
那為什么要用MongoDB?因?yàn)槲覀円幚淼臄?shù)據(jù)量龐大無(wú)比。按照1000多個(gè)航班,365天,26個(gè)倉(cāng)位,100多渠道以及數(shù)個(gè)不同的航程類(lèi)型,我們要實(shí)時(shí)存取的運(yùn)價(jià)記錄有數(shù)十億條之多。這個(gè)已經(jīng)遠(yuǎn)遠(yuǎn)超出常規(guī)RDBMS可以承受的范圍。
MongoDB基于內(nèi)存緩存的數(shù)據(jù)管理方式?jīng)Q定了對(duì)并發(fā)讀寫(xiě)的響應(yīng)可以做到很低延遲,水平擴(kuò)展的方式可以通過(guò)多臺(tái)節(jié)點(diǎn)同時(shí)并發(fā)處理海量請(qǐng)求。
事實(shí)上,全球最大的航空分銷(xiāo)商,管理者全世界95%航空庫(kù)存的Amadeus也正是使用MongoDB作為其1000多億運(yùn)價(jià)緩存的存儲(chǔ)方案。
Spark + MongoDB 方案
我們知道MongoDB可以用來(lái)做我們海量運(yùn)價(jià)數(shù)據(jù)的存儲(chǔ)方案,在大規(guī)模并行計(jì)算方案上,就可以用到嶄新的Spark技術(shù)。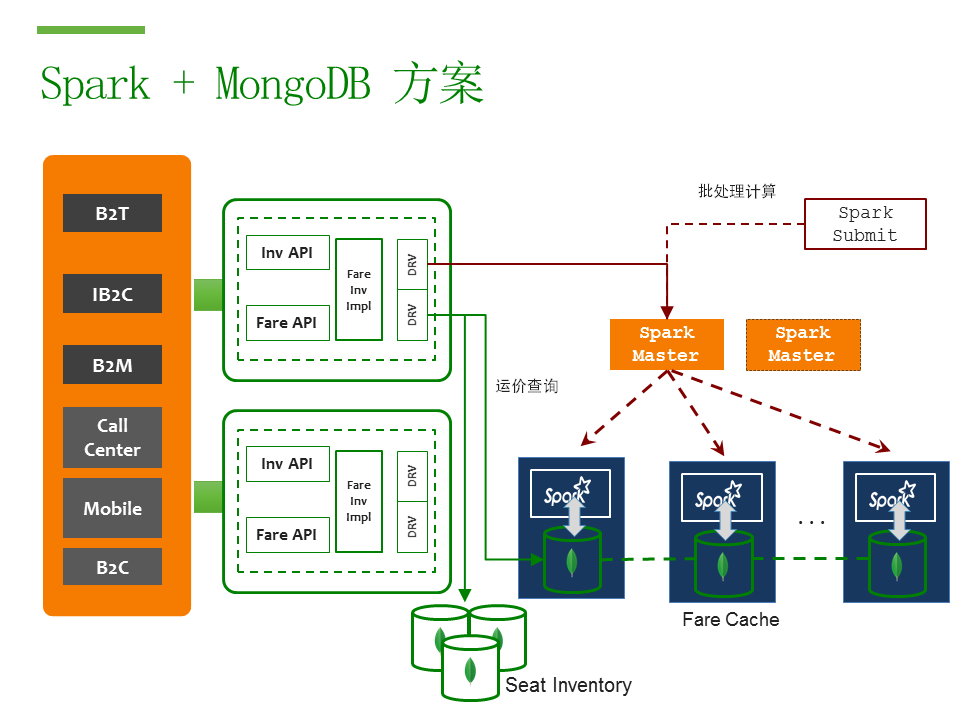
這里是一個(gè)運(yùn)價(jià)系統(tǒng)的架構(gòu)圖。左邊是發(fā)起航班查詢(xún)請(qǐng)求的客戶(hù)端,首先會(huì)有API服務(wù)器進(jìn)行預(yù)處理。一般航班請(qǐng)求會(huì)分為庫(kù)存查詢(xún)和運(yùn)價(jià)查詢(xún)。庫(kù)存查詢(xún)會(huì)直接到東航已有的庫(kù)存系統(tǒng)(Seat Inventory),同樣是實(shí)現(xiàn)在MongoDB上面的。在確定庫(kù)存后根據(jù)庫(kù)存結(jié)果再?gòu)腇are Cache系統(tǒng)內(nèi)查詢(xún)相應(yīng)的運(yùn)價(jià)。
Spark集群則是另外一套計(jì)算集群,通過(guò)Spark MongoDB連接套件和MongoDB Fare Cache集群連接。Spark 計(jì)算任務(wù)會(huì)定期觸發(fā)(如每天一次或者每4小時(shí)一次),這個(gè)任務(wù)會(huì)對(duì)所有的可能的運(yùn)價(jià)組合進(jìn)行全量計(jì)算,然后存入MongoDB,以供查詢(xún)使用。右半邊則把原來(lái)實(shí)時(shí)運(yùn)算的集群換成了Spark+MongoDB。Spark負(fù)責(zé)批量計(jì)算一年內(nèi)所有航班所有倉(cāng)位的所有價(jià)格,并以高并發(fā)的形式存儲(chǔ)到MongoDB里面。每秒鐘處理的運(yùn)價(jià)可以達(dá)到數(shù)萬(wàn)條。
當(dāng)來(lái)自客戶(hù)端的運(yùn)價(jià)查詢(xún)達(dá)到服務(wù)端以后,服務(wù)端直接就向MongoDB發(fā)出按照日期,出發(fā)到達(dá)機(jī)場(chǎng)為條件的mongo查詢(xún)。
批處理計(jì)算流程
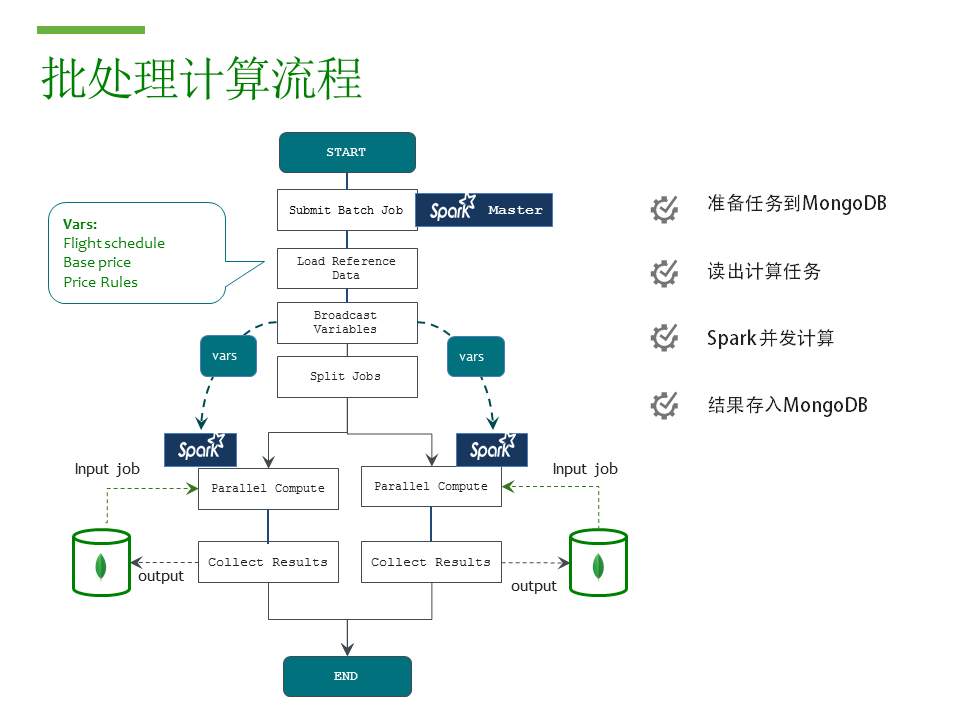
這里是Spark計(jì)算任務(wù)的流程圖。需要計(jì)算的任務(wù),也就是所有日期航班倉(cāng)位的組合,事先已經(jīng)存放到MongoDB里面。
任務(wù)遞交到master,然后預(yù)先加載所需參考數(shù)據(jù),broadcast就是把這些在內(nèi)存里的數(shù)據(jù)復(fù)制到每一個(gè)Spark計(jì)算節(jié)點(diǎn)的JVM,然后所有計(jì)算節(jié)點(diǎn)多線(xiàn)程并發(fā)執(zhí)行,從Mongodb里取出需要計(jì)算的倉(cāng)位,調(diào)用東航自己的運(yùn)價(jià)邏輯,得出結(jié)果以后,并保存回MongoDB。
Spark 任務(wù)入口程序
Spark和MongoDB的連接使用非常簡(jiǎn)單,下面就是一個(gè)代碼示例:
// initialization dependencies including base prices, pricing rules and some reference dataMap dependencies = MyDependencyManager.loadDependencies();// broadcasting dependencies
javaSparkContext.broadcast(dependencies);// create job rdd
cabinsRDD = MongoSpark.load(javaSparkContext).withPipeline(pipeline)// for each cabin, date, airport pair, calculate the price
cabinsRDD.map(function calc_price);// collect the result, which will cause the data to be stored into MongoDB
cabinsRDD.collect()
cabinsRDD.saveToMongo()處理能力和響應(yīng)時(shí)間比較
這里是一個(gè)在東航POC的簡(jiǎn)單測(cè)試結(jié)果。從吞吐量的角度,新的API服務(wù)器單節(jié)點(diǎn)就可以處理3400個(gè)并發(fā)的運(yùn)價(jià)請(qǐng)求。在顯著提高了并發(fā)的同時(shí),響應(yīng)延遲則降低了10幾倍,平均10ms就可以返回運(yùn)價(jià)結(jié)果。按照這個(gè)性能,6臺(tái) API服務(wù)器就可以應(yīng)付將來(lái)每天16億的運(yùn)價(jià)查詢(xún)。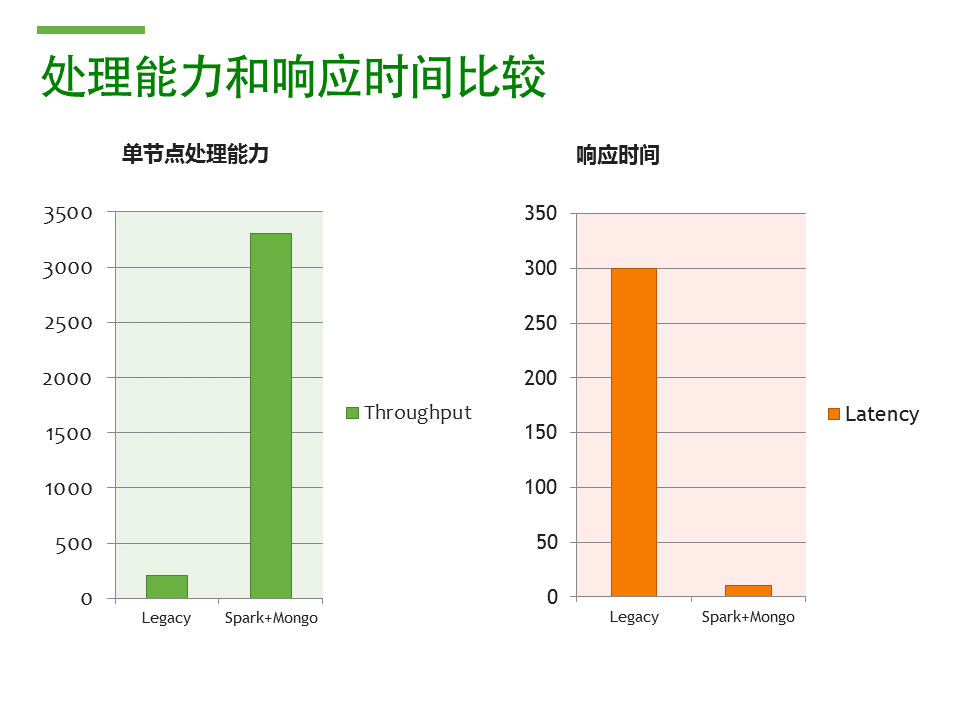
Spark + MongoDB演示
接下來(lái)是一個(gè)簡(jiǎn)單的Spark+MongoDB演示。
安裝 Spark
# curl -OL http://d3kbcqa49mib13.cloudfront.net/spark-1.6.0-bin-hadoop2.6.tgz# mkdir -p ~/spark# tar -xvf spark-1.6.0-bin-hadoop2.6.tgz -C ~/spark --strip-components=1測(cè)試連接器
# cd ~/spark# ./bin/spark-shell \--conf "spark.mongodb.input.uri=mongodb://127.0.0.1/flights.av" \
--conf "spark.mongodb.output.uri=mongodb://127.0.0.1/flights.output" \
--packages org.mongodb.spark:mongo-spark-connector_2.10:1.0.0import com.mongodb.spark._
import org.bson.DocumentMongoSpark.load(sc).take(10).foreach(println)簡(jiǎn)單分組統(tǒng)計(jì)
數(shù)據(jù):365天,所有航班庫(kù)存信息,500萬(wàn)文檔
任務(wù):按航班統(tǒng)計(jì)一年內(nèi)所有余票量
MongoSpark.load(sc)
.map(doc=>(doc.getString("flight") ,doc.getLong("seats")))
.reduceByKey((x,y)=>(x+y))
.take(10)
.foreach(println)簡(jiǎn)單分組統(tǒng)計(jì)加條件過(guò)濾
數(shù)據(jù):365天,所有航班庫(kù)存信息,500萬(wàn)文檔
任務(wù):按航班統(tǒng)計(jì)一年內(nèi)所有庫(kù)存,但是只處理昆明出發(fā)的航班
import org.bson.DocumentMongoSpark.load(sc)
.withPipeline(Seq(Document.parse("{ $match: { orig : 'KMG' } }")))
.map(doc=>(doc.getString("flight") ,doc.getLong("seats")))
.reduceByKey((x,y)=>(x+y))
.take(10)
.foreach(println)性能優(yōu)化事項(xiàng)
使用合適的chunksize (MB)
Total data size / chunksize = chunks = RDD partitions = spark tasks不要將所有CPU核分配給Spark
預(yù)留1-2個(gè)core給操作系統(tǒng)及其他管理進(jìn)程同機(jī)部署
適當(dāng)情況可以同機(jī)部署Spark+MongoDB,利用本地IO提高性能
總結(jié)
上面只是一些簡(jiǎn)單的演示,實(shí)際上Spark + MongoDB的使用可以通過(guò)Spark的很多種形式來(lái)使用。我們來(lái)總結(jié)一下Spark + Mongo的應(yīng)用場(chǎng)景。在座的同學(xué)可能很多人已經(jīng)使用了MongoDB,也有些人已經(jīng)使用了Hadoop。我們可以從兩個(gè)角度來(lái)考慮這個(gè)事情:
對(duì)那些已經(jīng)使用MongoDB的用戶(hù),如果你希望在你的MongoDB驅(qū)動(dòng)的應(yīng)用上提供個(gè)性化功能,比如說(shuō)像Yahoo一樣為你找感興趣的新聞,能夠在你的MongoDB數(shù)據(jù)上利用到Spark強(qiáng)大的機(jī)器學(xué)習(xí)或者流處理,你就可以考慮在MongoDB集群上部署Spark來(lái)實(shí)現(xiàn)這些功能。
如果你已經(jīng)使用Hadoop而且數(shù)據(jù)已經(jīng)在HDFS里面,你可以考慮使用Spark來(lái)實(shí)現(xiàn)更加實(shí)時(shí)更加快速的分析型需求,并且如果你的分析結(jié)果有數(shù)據(jù)量大、格式多變以及這些結(jié)果數(shù)據(jù)要及時(shí)提供給前臺(tái)APP使用的需求,那么MongoDB可以用來(lái)作為你分析結(jié)果的一個(gè)存儲(chǔ)方案。


版權(quán)聲明:
文章不錯(cuò)?點(diǎn)個(gè)【在看】吧!??