
深度學(xué)習(xí)在圖像處理中的應(yīng)用一覽
點(diǎn)擊上方“小白學(xué)視覺”,選擇加"星標(biāo)"或“置頂”
重磅干貨,第一時(shí)間送達(dá)

本文轉(zhuǎn)自:人工智能與算法學(xué)習(xí)
計(jì)算機(jī)視覺的底層,圖像處理,根本上講是基于一定假設(shè)條件下的信號(hào)重建。這個(gè)重建不是3-D結(jié)構(gòu)重建,是指恢復(fù)信號(hào)的原始信息,比如去噪聲。這本身是一個(gè)逆問題,所以沒有約束或者假設(shè)條件是無解的,比如去噪最常見的假設(shè)就是高斯噪聲。
以前最成功的方法基本是信號(hào)處理,傳統(tǒng)機(jī)器學(xué)習(xí)也有過這方面的應(yīng)用,只是信號(hào)處理的約束條件變成了貝葉斯規(guī)則的先驗(yàn)知識(shí),比如稀疏編碼(sparse coding)/字典學(xué)習(xí)(dictionary learning),MRF/CRF之類。下面討論基于深度學(xué)習(xí)的方法。
以DnCNN和CBDNet為例介紹如何將深度學(xué)習(xí)用于去噪聲。
? DnCNN
最近,由于圖像去噪的鑒別模型學(xué)習(xí)性能引起了關(guān)注。去噪卷積神經(jīng)網(wǎng)絡(luò)(DnCNNs)將深度結(jié)構(gòu)、學(xué)習(xí)算法和正則化方法用于圖像去噪。
如圖是DnCNN架構(gòu)圖。給定深度為D的DnCNN,有三種層。(i)Conv + ReLU:第一層,64個(gè)大小為3×3×c的濾波器生成64個(gè)特征圖,然后是ReLU,這里c表示圖像通道數(shù),灰度圖像c = 1,彩色圖像c = 3。(ii)Conv + BN + ReLU:層2~(D-1),64個(gè)大小為3×3×64的濾波器,在卷積和ReLU之間添加BN。(iii)Conv:最后一層,c個(gè)尺寸3×3×64濾波器來重建輸出。
DnCNN采用殘差學(xué)習(xí)訓(xùn)練殘差映射R(y)≈v,然后得到x = y - R(y)。DnCNN模型有兩個(gè)主要特征:采用殘差學(xué)習(xí)來學(xué)習(xí)R(y),并結(jié)合BN來加速訓(xùn)練以及提高去噪性能。卷積與ReLU結(jié)合,DnCNN通過隱層逐漸將圖像結(jié)構(gòu)與噪聲干擾的觀測(cè)分開。這種機(jī)制類似于EPLL和WNNM等方法中采用的迭代噪聲消除策略,但DnCNN以端到端的方式進(jìn)行訓(xùn)練。
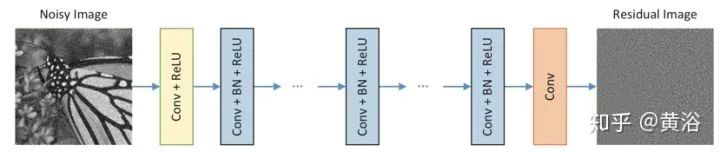
圖中的網(wǎng)絡(luò)可用于訓(xùn)練原始映射F(y)以預(yù)測(cè)x或殘差映射R(y)以預(yù)測(cè)v。當(dāng)原始映射更像是個(gè)體映射,殘差映射將更容易優(yōu)化。注意,噪聲觀察y更像是潛在干凈圖像x而不是殘差圖像v(特別是噪聲水平低)。因此,F(xiàn)(y)將比R(y)更接近于個(gè)體映射,并且殘差學(xué)習(xí)公式更適合于圖像去噪。
? CBD-Net
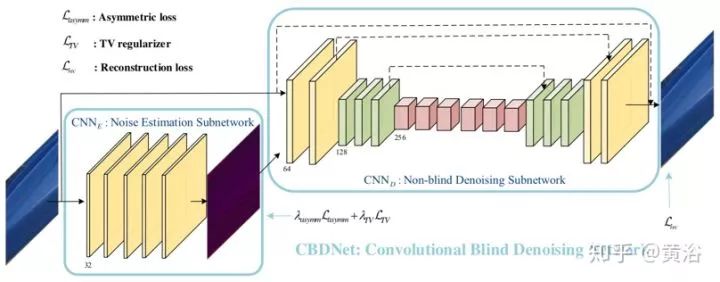
為了提高深度去噪模型的魯棒性和實(shí)用性,卷積盲去噪網(wǎng)絡(luò)(CBD-Net,convolutional blind denoising network)結(jié)合了網(wǎng)絡(luò)結(jié)構(gòu)、噪聲建模和非對(duì)稱學(xué)習(xí)幾個(gè)特點(diǎn)。CBD-Net由噪聲估計(jì)子網(wǎng)和去噪子網(wǎng)組成,使用更逼真的噪聲模型進(jìn)行訓(xùn)練,考慮到信號(hào)相關(guān)噪聲和攝像頭內(nèi)處理流水線。非盲去噪器(例如著名的BM3D)對(duì)噪聲估計(jì)誤差的不對(duì)稱靈敏度,可以使噪聲估計(jì)子網(wǎng)抑制低估的噪聲水平。為了使學(xué)習(xí)的模型適用于真實(shí)圖像,基于真實(shí)噪聲模型的合成圖像和幾乎無噪聲的真實(shí)噪聲圖像合并后訓(xùn)練CBDNet。
如圖是CBDNet盲去噪架構(gòu)圖。噪聲模型在基于CNN的去噪性能方面起著關(guān)鍵作用。給定一個(gè)干凈的圖像x,更真實(shí)的噪聲模型n(x)~N(0,σ(y))可以表示為,
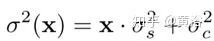
這里,n(x) = ns(x)+ nc由信號(hào)相關(guān)噪聲分量ns和靜止噪聲分量nc組成。并且nc被建模為具有噪聲方差σc2的AWGN,但是對(duì)于每個(gè)像素i,ns的噪聲方差與圖像強(qiáng)度相關(guān),即x(i)·σs2。
CBDNet包括噪聲估計(jì)子網(wǎng)CNNE和非盲去噪子網(wǎng)CNND。首先,噪聲估計(jì)子網(wǎng)CNNE采用噪聲觀測(cè)y來產(chǎn)生估計(jì)的噪聲水平圖σ?(y)= FE(y; WE),其中WE表示CNNE的網(wǎng)絡(luò)參數(shù)。CNNE的輸出為噪聲水平圖,因?yàn)樗c輸入y具有相同的大小,并通過全卷積網(wǎng)絡(luò)。然后,非盲去噪子網(wǎng)絡(luò)CNND將y和σ?(y)都作為輸入以獲得最終去噪結(jié)果x = FD(y,σ(y); WD),其中WD表示CNND的網(wǎng)絡(luò)參數(shù)。此外,CNNE允許估計(jì)的噪聲水平圖σ(y)放入非盲去噪子網(wǎng)絡(luò)CNND之前調(diào)整。一個(gè)簡(jiǎn)單的策略是讓?duì)?(y)=γσ?(y)以交互的方式做去噪計(jì)算。
噪聲估計(jì)子網(wǎng)CNNE是五層全卷積網(wǎng)絡(luò),沒有池化和批量歸一化(BN)操作。每個(gè)卷積層特征通道32,濾波器大小3×3。在每個(gè)卷積層之后有ReLU。與CNNE不同,非盲去噪子網(wǎng)絡(luò)CNND采用U-Net架構(gòu),以y和σ?(y)作為輸入,在無噪干凈圖像給出預(yù)測(cè)x。通過殘差學(xué)習(xí)學(xué)習(xí)殘差映射R(y,σ?(y); WD)然后預(yù)測(cè)x = y + R(y,σ?(y); WD)。CNNE的16層U-Net架構(gòu)引入對(duì)稱跳躍連接、跨步卷積和轉(zhuǎn)置卷積,來利用多尺度信息并擴(kuò)大感受野。所有濾波器大小均為3×3,除最后一個(gè),每個(gè)卷積層之后加ReLU。
將如下定義的不對(duì)稱損失引入噪聲估計(jì)子網(wǎng),并與重建損失結(jié)合一起,訓(xùn)練完整的CBDNet:
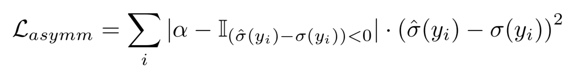
此外,引入一個(gè)全局變化(TV)正則化來約束σ?(y)的平滑度,
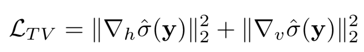
其中?h(?v)表示水平(垂直)方向的梯度算子。
重建損失為
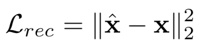
總損失函數(shù)
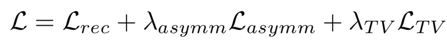
一些結(jié)果例子:

單圖像去霧是一個(gè)具有挑戰(zhàn)性的病態(tài)問題。現(xiàn)有方法使用各種約束/先驗(yàn)來獲得似乎合理的除霧解決方案。實(shí)現(xiàn)去霧的關(guān)鍵是估計(jì)輸入霧霾圖像的介質(zhì)傳輸圖(medium transmission map)。
? DehazeNet
DehazeNet是一個(gè)可訓(xùn)練的端到端系統(tǒng),用于介質(zhì)傳輸估計(jì)。DehazeNet將霧圖像輸入,輸出其介質(zhì)傳輸圖,隨后通過大氣散射模型(atmospheric scattering model)恢復(fù)無霧圖像。DehazeNet采用CNN的深層架構(gòu),設(shè)計(jì)能體現(xiàn)圖像去霧的假設(shè)/先驗(yàn)知識(shí)。具體而言,Maxout單元層用于特征提取,幾乎所有與霧相關(guān)的特征。還有一種新的非線性激活函數(shù),稱為雙邊整流線性單元(Bilateral Rectified Linear Unit,BReLU),提高圖像的無霧恢復(fù)質(zhì)量。
下圖是DehazeNet架構(gòu)圖。在概念上DehazeNet由四個(gè)順序操作(特征提取、多尺度映射、局部極值和非線性回歸)組成,它由3個(gè)卷積層、最大池化、Maxout單元和BReLU激活函數(shù)構(gòu)成。下面依次介紹四個(gè)操作細(xì)節(jié)。
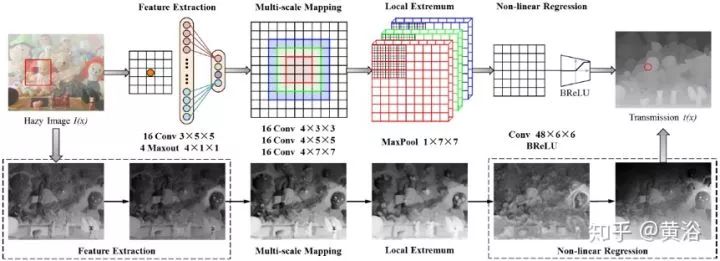
1) 特征提取:為了解決圖像去霧問題的病態(tài)性,現(xiàn)有方法提出了各種假設(shè),并且基于這些假設(shè),在圖像域密集地提取與霧度相關(guān)的特征,例如,著名的暗通道(dark channel),色調(diào)差和顏色衰減等;為此,選擇具有特別激活函數(shù)的Maxout單元作為降維非線性映射;通常Maxout用于多層感知器(MLP)或CNN的簡(jiǎn)單前饋非線性激活函數(shù);在CNN使用時(shí),對(duì)k仿射特征圖逐像素最大化操作生成新的特征圖;設(shè)計(jì)DehazeNet的第一層如下
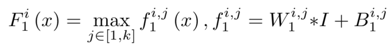
其中
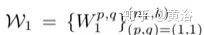
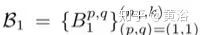
分別代表濾波器和偏差。
2) 多尺度映射:多尺度特征已經(jīng)被證明對(duì)于去除霧度是有效的;多尺度特征提取實(shí)現(xiàn)尺度不變性有效;選擇在DehazeNet的第二層使用并行卷積運(yùn)算,其中任何卷積濾波器的大小在3×3、5×5和7×7之間,那么第二層的輸出寫為
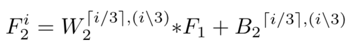
其中
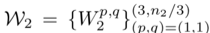
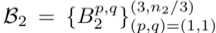
包含分為3組的n2對(duì)參數(shù), n2是第二層的輸出維度,i∈[1,n2]索引輸出特征圖,??向上取整數(shù),表示余數(shù)運(yùn)算。
3) 局部極值:根據(jù)CNN的經(jīng)典架構(gòu),在每個(gè)像素考慮鄰域最大值可克服局部靈敏度;另外,局部極值是根據(jù)介質(zhì)傳輸局部恒常的假設(shè),并且通常用于克服傳輸估計(jì)的噪聲;第三層使用局部極值運(yùn)算,即
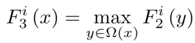
注:局部極值密集地應(yīng)用于特征圖,能夠保持圖像分辨率。
4) 非線性回歸:非線性激活函數(shù)的標(biāo)準(zhǔn)選擇包括Sigmoid和ReLU;前者容易受到梯度消失的影響,導(dǎo)致網(wǎng)絡(luò)訓(xùn)練收斂緩慢或局部最優(yōu);為此提出了ReLU ,一種稀疏表示方法;不過,ReLU僅在值小于零時(shí)才禁止輸出,這可能導(dǎo)致響應(yīng)溢出,尤其是在最后一層;所以采用一種BReLU激活功能,如圖所示;BReLU保持了雙邊約束(bilateral restraint)和局部線性;這樣,第四層特征圖定義為
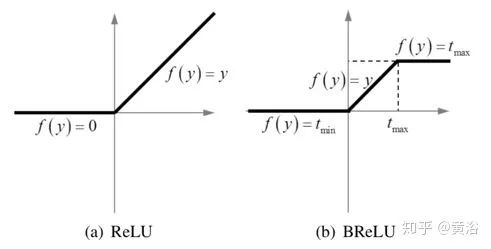
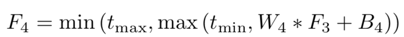
這里W4 = {W4}包含一個(gè)大小為n3×f4×f4的濾波器,B4 = {B4}包含一個(gè)偏差,tmin, max是BReLU的邊際值(tmin = 0和tmax = 1) 。根據(jù)上式,該激活函數(shù)的梯度可以表示為
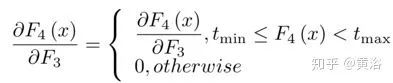
將上述四層級(jí)聯(lián)形成基于CNN的可訓(xùn)練端到端系統(tǒng),其中與卷積層相關(guān)聯(lián)的濾波器和偏置是要學(xué)習(xí)的網(wǎng)絡(luò)參數(shù)。
? EPDN
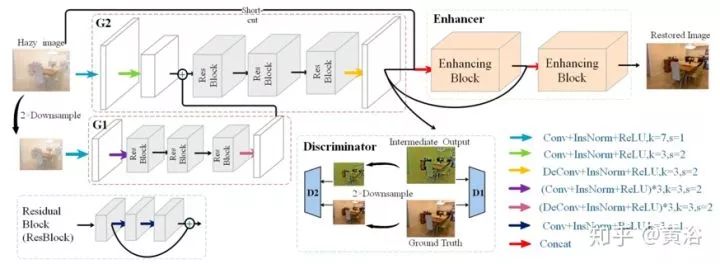
論文將圖像去霧問題簡(jiǎn)化為圖像到圖像的轉(zhuǎn)換問題,并提出增強(qiáng)的Pix2pix去霧網(wǎng)絡(luò)(EPDN),它可以生成無霧圖像,而不依賴于物理散射模型。EPDN由生成對(duì)抗網(wǎng)絡(luò)(GAN)嵌入,然后是增強(qiáng)器。一種理論認(rèn)為視覺感知是全局優(yōu)先的,那么鑒別器指導(dǎo)生成器在粗尺度上創(chuàng)建偽真實(shí)圖像,而生成器后面的增強(qiáng)器需要在精細(xì)尺度上產(chǎn)生逼真的去霧圖像。增強(qiáng)器包含兩個(gè)基于感受野模型的增強(qiáng)塊,增強(qiáng)顏色和細(xì)節(jié)的去霧效果。另外,嵌入式GAN與增強(qiáng)器是一起訓(xùn)練的。
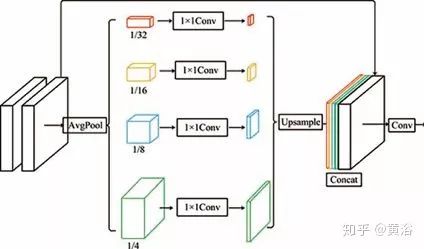
如圖是EPDN架構(gòu)的示意圖,由多分辨率生成器模塊,增強(qiáng)器模塊和多尺度鑒別器模塊組成。即使pix2pixHD使用粗到細(xì)特征,結(jié)果仍然缺乏細(xì)節(jié)并且顏色過度。一個(gè)可能的原因是現(xiàn)有的鑒別器在引導(dǎo)生成器創(chuàng)建真實(shí)細(xì)節(jié)方面受到限制。換句話說,鑒別者應(yīng)該只指導(dǎo)生成器恢復(fù)結(jié)構(gòu)而不是細(xì)節(jié)。為了有效地解決這個(gè)問題,采用金字塔池化模塊,以確保不同尺度的特征細(xì)節(jié)嵌入到最終結(jié)果中,即增強(qiáng)塊。從目標(biāo)識(shí)別的全局上下文信息中看出,在各種尺度需要特征的細(xì)節(jié)。因此,增強(qiáng)塊根據(jù)感受野模型設(shè)計(jì),可以提取不同尺度的信息。
如圖是增強(qiáng)塊的架構(gòu):有兩個(gè)3×3前端卷積層,前端卷積層的輸出縮減,因子分別是4×,8×,16×,32×,這樣構(gòu)建四尺度金字塔;不同尺度的特征圖提供了不同的感受域,有助于不同尺度的圖像重建;然后,1×1卷積降維,實(shí)際上1×1卷積實(shí)現(xiàn)了自適應(yīng)加權(quán)通道的注意機(jī)制;之后,將特征圖上采樣為原始大小,并與前端卷積層的輸出連接在一起;最后,3×3卷積在連接的特征圖上實(shí)現(xiàn)。
在EPDN中,增強(qiáng)器包括兩個(gè)增強(qiáng)塊。第一個(gè)增強(qiáng)塊輸入是原始圖像和生成器特征的連接,而這些特征圖也輸入到第二個(gè)增強(qiáng)塊。
? PMS-Net
補(bǔ)丁圖選擇網(wǎng)絡(luò)(Patch Map Selection Network,PMS-Net)是一個(gè)自適應(yīng)和自動(dòng)化補(bǔ)丁尺寸選擇模型,主要選擇每個(gè)像素對(duì)應(yīng)的補(bǔ)丁尺寸。該網(wǎng)絡(luò)基于CNN設(shè)計(jì),可以從輸入圖像生成補(bǔ)丁圖。其去霧算法的流程圖如圖所示。
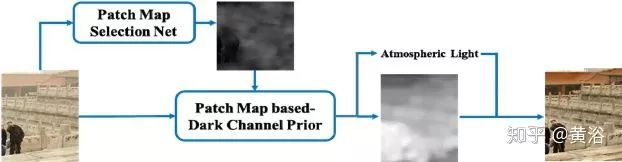
為了提高該網(wǎng)絡(luò)的性能,PMS-Net提出一種有金字塔風(fēng)格的多尺度U-模塊。基于補(bǔ)丁圖,可預(yù)測(cè)更精確的大氣光和透射圖。所提出的架構(gòu),可以避免傳統(tǒng)DCP的問題(例如,白色或明亮場(chǎng)景的錯(cuò)誤恢復(fù)),恢復(fù)圖像的質(zhì)量高于其他算法。其中,定義了一個(gè)名為補(bǔ)丁圖(patch map)的來解決暗通道先驗(yàn)(DCP)補(bǔ)丁大小固定的問題。
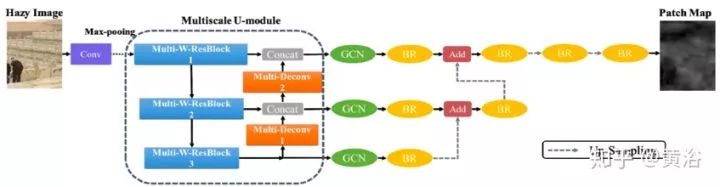
如圖是PMS-Net的架構(gòu),分為編碼器和解碼器。最初,輸入的霧圖像和16個(gè)3×3內(nèi)核的濾波器卷積投影到更高維空間。然后,多尺度-U模塊從更高維數(shù)據(jù)中提取特征。多尺度U-模塊的設(shè)計(jì)如圖左側(cè)所示。
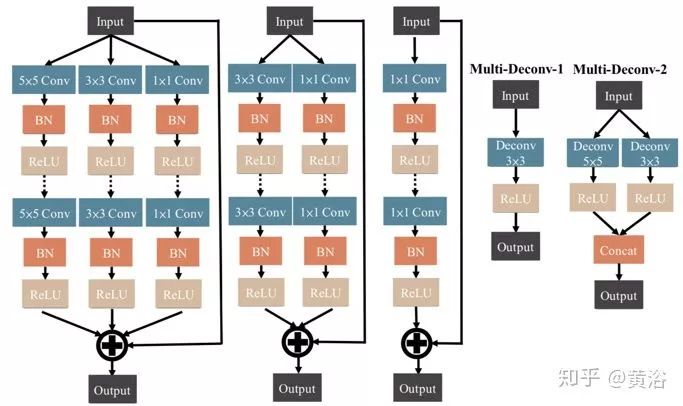
輸入將通過幾個(gè)Multiscale-W-ResBlocks(MSWR),如下圖左側(cè)所示。MSWR的設(shè)計(jì)想法類似Wide-ResNet(WRN),通過增加網(wǎng)絡(luò)寬度和減小深度來改進(jìn)ResNet。每塊中使用快捷方式執(zhí)行Conv-BN-ReLu-Dropout-Conv-BN-ReLu這一系列操作提取信息。MSWR中多尺度概念類似Inception-ResNet,采用多層技術(shù)來增強(qiáng)信息的多樣性,并提取詳細(xì)信息。
多尺度U-模塊中的其他部分,Multi-Deconv模塊將信息與MSWR而不是反卷積的輸出連接在一起,因?yàn)榉淳矸e層可以幫助網(wǎng)絡(luò)重建輸入數(shù)據(jù)的形狀信息。因此,通過多尺度反卷積組合,可以從網(wǎng)絡(luò)前層重建更精確的特征圖。此外,Multi-Deconv執(zhí)行金字塔風(fēng)格并提高尺度與MSWR連接。也就是說,不同層特征圖以不同的尺度運(yùn)行去卷積(參見多尺度U-模塊圖右側(cè))。
為保留高分辨率,MSWR和Multi-Deconv模塊的輸出直接連接。然后,特征圖饋送到網(wǎng)絡(luò)更高層的Multi-Deconv模塊和解碼器。解碼器采用全局卷積網(wǎng)絡(luò)模塊(global convolutional network modules,GCN)。邊界細(xì)化模塊(boundary refinement,BR)也用于邊緣信息保留。上采樣操作升級(jí)尺度層。此外,采用致密連接樣式合并高與低分辨率的信息。PMS-Net可以預(yù)測(cè)補(bǔ)丁圖。
下圖是一些實(shí)驗(yàn)結(jié)果的分析:白色和明亮場(chǎng)景中去霧結(jié)果的比較;第1欄:輸入圖像; 第2欄:通過固定尺寸補(bǔ)丁DCP的結(jié)果; 第3欄:PMS-Net方法的結(jié)果; 第4欄:第2欄和第3欄中白色或亮部的放大; 第5欄:補(bǔ)丁圖; 第6-7欄:分別由DCP和PMS-Net方法估計(jì)的介質(zhì)傳輸圖。

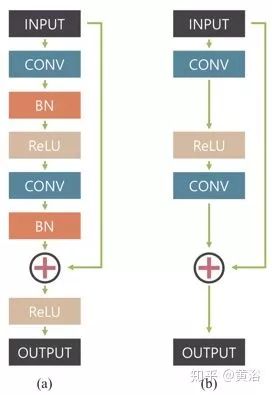
這是一種多尺度卷積神經(jīng)網(wǎng)絡(luò),以端到端的方式恢復(fù)清晰的圖像,其中模糊是由各種來源引起的,包括鏡頭運(yùn)動(dòng)、景物深度和物體運(yùn)動(dòng)。如圖是定義的網(wǎng)絡(luò)模型架構(gòu)圖,稱為ResBlocks:(a)原始?xì)堄嗑W(wǎng)絡(luò)構(gòu)建塊,(b)該網(wǎng)絡(luò)修正的模塊化構(gòu)建塊;沒有使用批量歸一化(BN)層,因?yàn)橛?xùn)練模型使用的小批量(mini-batch)大小為2,比BN通常要小;在輸出之前去除整流線性單元(ReLU)有利于提高經(jīng)驗(yàn)性能。
設(shè)計(jì)的去模糊多尺度網(wǎng)絡(luò)架構(gòu)見下圖所示:Bk,Lk,Sk分別表示模糊、潛在和GT清晰圖像。下標(biāo)k表示高斯金字塔第k個(gè)尺度層,下采樣到1 / 2k尺度。該模型將模糊的圖像金字塔作為輸入并輸出估計(jì)的潛在圖像金字塔。每個(gè)中間尺度的輸出都訓(xùn)練成清晰。在測(cè)試時(shí),選擇原始尺度的輸出圖像作為最終結(jié)果。
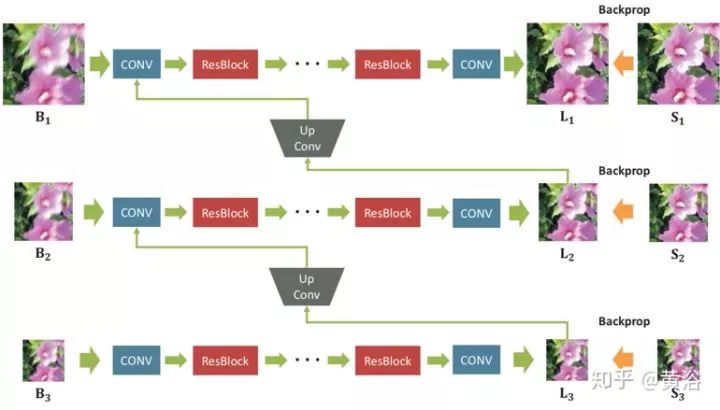
用ResBlocks堆疊足夠數(shù)量的卷積層,每個(gè)尺度的感受野得以擴(kuò)展。在訓(xùn)練時(shí),將輸入和輸出高斯金字塔補(bǔ)丁的分辨率設(shè)置為{256×256,128×128,64×64}。連續(xù)尺度之間的比例(scale ratio)是0.5。對(duì)所有卷積層,濾波器大小為5×5。因?yàn)槟P褪侨矸e,在測(cè)試時(shí)補(bǔ)丁大小可能變化。
定義一個(gè)多尺度損失函數(shù)模擬傳統(tǒng)的粗到精方法
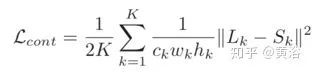
其中Lk,Sk分別表示在尺度層k的模型輸出圖像和GT圖像。而對(duì)抗損失函數(shù)定義為
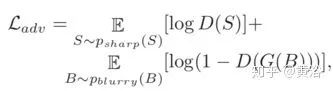
其中G和D分別是生成器和鑒別器。最終的損失函數(shù)是
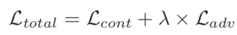
一些結(jié)果如圖所示,有幾個(gè)縮放的局部細(xì)節(jié)。

具有深度覺察和視角聚合(Depth Awareness and View Aggregation)的網(wǎng)絡(luò)DAVANet是一個(gè)立體圖像去模糊網(wǎng)絡(luò)。網(wǎng)絡(luò)中來自兩個(gè)視圖有深度和變化信息的3D場(chǎng)景線索合并在一起,動(dòng)態(tài)場(chǎng)景中有助于消除復(fù)雜空間變化的模糊。具體而言,通過這個(gè)融合網(wǎng)絡(luò),將雙向視差估計(jì)和去模糊整合到一個(gè)統(tǒng)一框架中。
下圖描述立體視覺帶來的模糊:(a)是與圖像平面平行的相對(duì)平移引起的深度變化模糊,(b)和(c)是沿深度方向的相對(duì)平移和旋轉(zhuǎn)引起的視角變化模糊。注意,所有復(fù)雜運(yùn)動(dòng)可以分解為這三個(gè)相對(duì)子運(yùn)動(dòng)模式。
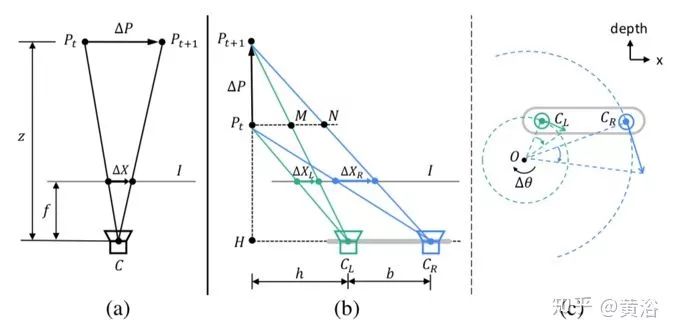
如圖(a)所示,我們可以得到:
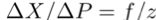
其中ΔX,ΔP,f和z分別表示模糊的大小、目標(biāo)點(diǎn)的運(yùn)動(dòng)、焦距和目標(biāo)點(diǎn)的深度。
如圖(b)所示,我們知道:
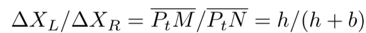
其中b是基線,h是左攝像頭CL和線段PtPt+1之間的距離。
如圖(c)所示,兩個(gè)鏡頭的速度vCL,vCR與相應(yīng)旋轉(zhuǎn)半徑CLO,CRO成正比,即
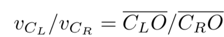
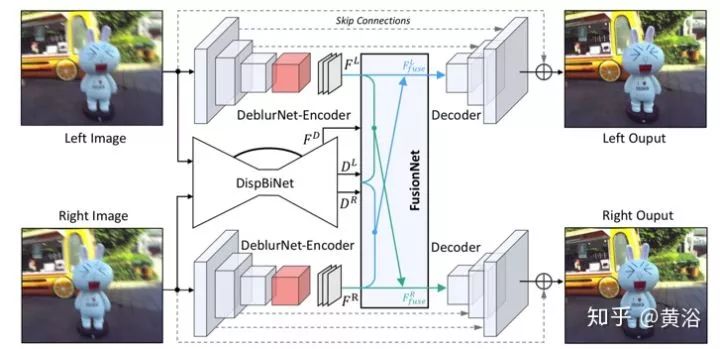
DAVANet總體流程圖如圖所示,由三個(gè)子網(wǎng)絡(luò)組成:用于單鏡頭去模糊的DeblurNet,用于雙向視差估計(jì)的DispBiNet,和以自適應(yīng)選擇方式融合深度和雙視角信息的FusionNet。這里采用小卷積濾波器(3×3)來構(gòu)造這三個(gè)子網(wǎng)絡(luò),因?yàn)榇笮蜑V波器并不能提高性能。
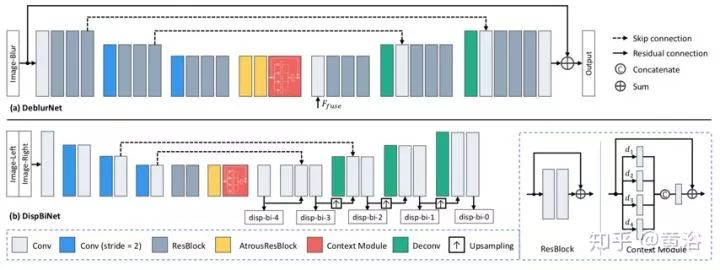
DeblurNet的結(jié)構(gòu)基于U-Net,如圖(a)所示。用基本殘差模塊作為構(gòu)建塊,編碼器輸出特征為輸入尺寸的1/4×1/4。之后,解碼器通過兩個(gè)上采樣殘差塊全分辨率重建清晰圖像。在編碼器和解碼器之間使用相應(yīng)特征圖之間的跳連接(skip-connections)。此外,還采用輸入和輸出之間的殘差連接。這使網(wǎng)絡(luò)很容易估計(jì)模糊-尖銳(blurry-sharp)圖像對(duì)之間的殘差并保持顏色一致性。還有,在編碼器和解碼器之間使用兩個(gè)空洞殘差(atrous residual)塊和一個(gè)Context模塊來獲得更豐富的特征。DeblurNet對(duì)兩個(gè)視圖使用共享權(quán)重。
受以前DispNet模型結(jié)構(gòu)的啟發(fā),采用一個(gè)小型DispBiNet,如圖(b)所示。與DispNet不同,DispBiNet可以預(yù)測(cè)一個(gè)前向過程的雙向視差。輸出是完整分辨率,網(wǎng)絡(luò)有三次下采樣和上采樣操作。此外,DispBiNet中還使用了殘差塊、空洞殘差塊和Context模塊。
為了嵌入多尺度特征,DeblurNet和DispBiNet采用Context模塊,它包含具有不同擴(kuò)張率(dilated rate)的并行擴(kuò)張卷積(dilated convolution),如圖所示。四個(gè)擴(kuò)張率是設(shè)置為1, 2, 3, 4。Context模塊融合更豐富的分級(jí)上下文信息,有利于消除模糊和視差估計(jì)。
為了利用深度和雙視角信息去模糊,引入融合網(wǎng)絡(luò)FusionNet來豐富具有視差和雙視角的特征。如圖所示,F(xiàn)usionNet采用原始立體圖像IL,IR,估計(jì)的左視圖DL視差,DispBiNet倒數(shù)第二層的特征FD和DeblurNet編碼器的特征FL,F(xiàn)R作為輸入,以生成融合特征FLfuse。
為雙視角聚合,估計(jì)的左目視差DL將DeblurNet的右目特征FR變形到左目,即為WL(FR)。不用直接連接WL(FR)和FL,而是子網(wǎng)GateNet生成從0到1的軟門圖(soft gate map)GL。門圖可以自適應(yīng)選擇方式用來融合特征FL和WL(FR),即選擇有用的特征,并從另一個(gè)視角拒絕不正確的特征。例如,在遮擋或錯(cuò)誤視差區(qū)域,門圖值往往為0,這表明只采用參考視角F L的特征。GateNet由五個(gè)卷積層組成,如圖所示,輸入是左圖像IL和變形的右圖像WL(IR)的絕對(duì)差,即| IL - WL(IR)|,輸出是單通道的門圖。所有特征通道共享相同的門圖以生成聚合特征:
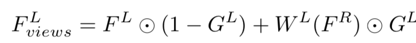
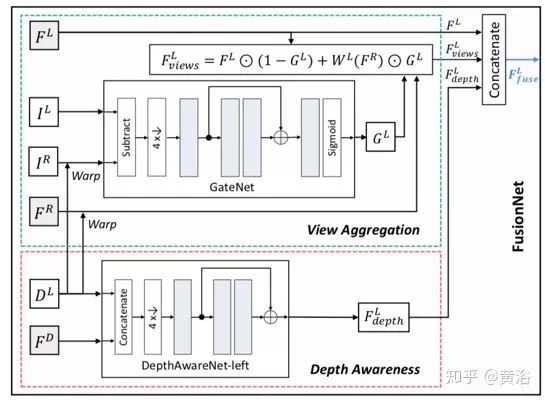
為深度覺察,使用三個(gè)卷積層的子網(wǎng)絡(luò)DepthAwareNet,而且兩個(gè)視角不共享該子網(wǎng)絡(luò)。給定視差DL和DispBiNet的倒數(shù)第二層特征FD,DepthAwareNet-left產(chǎn)生深度關(guān)聯(lián)的特征FL。事實(shí)上,DepthAwareNet隱式地學(xué)習(xí)深度覺察的先驗(yàn)知識(shí),這有助于動(dòng)態(tài)場(chǎng)景的去模糊。
最后,連接原始左圖特征FL,視角聚合特征FLviews和深度覺察特征FLdepth生成融合的左視角特征FLfuse。然后,將FLfuse供給DeblurNet的解碼器。同理,采用FusionNet一樣的架構(gòu)可以得到右視角的融合特征。
DeblurNet損失函數(shù)包括兩個(gè)部分:MSE損失和感知損失,即
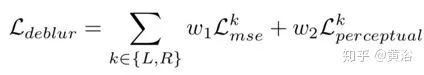
其中
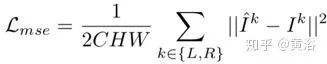
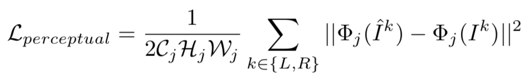
DispBiNet的視差損失函數(shù)如下:
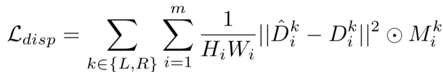
如圖顯示的是視差對(duì)去模糊的作用:(a)(f)(g)和(h)分別表示模糊圖像、清晰圖像、預(yù)測(cè)的視差和GT視差。(b)和(e)是單目去模糊網(wǎng)絡(luò)DeblurNet和雙目去模糊網(wǎng)絡(luò)DAVANet的結(jié)果。在(c),兩個(gè)左圖像輸入,DispBiNet不能為深度覺察和視角聚合提供任何深度信息或視差。在(d)中,為了消除視角聚合的影響,不會(huì)從FusionNet中其他視圖變形該特征。由于該網(wǎng)絡(luò)可以準(zhǔn)確估計(jì)和采用視差,因此其性能優(yōu)于其他方法

? Deep Bilateral Learning
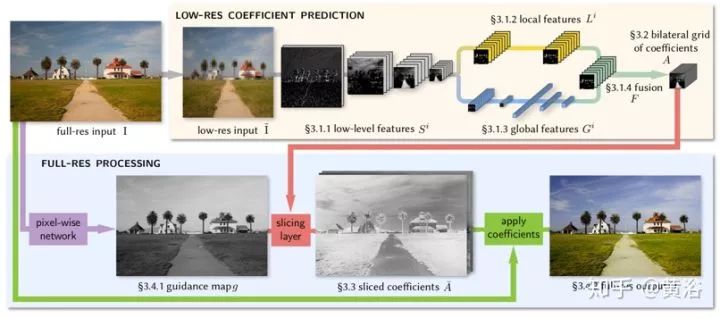
這是一種做圖像增強(qiáng)的神經(jīng)網(wǎng)絡(luò)架構(gòu),其靈感來自雙邊網(wǎng)格處理(bilateral grid processing)和局部仿射顏色變換。基于輸入/輸出圖像對(duì),訓(xùn)練卷積神經(jīng)網(wǎng)絡(luò)來預(yù)測(cè)雙邊空間(bilateral space)局部仿射模型的系數(shù)。網(wǎng)絡(luò)架構(gòu)目的是學(xué)習(xí)如何做出局部的、全局的和依賴于內(nèi)容的決策來近似所需的圖像變換。輸入神經(jīng)網(wǎng)絡(luò)是低分辨率圖像,在雙邊空間生成一組仿射變換,以邊緣保留方式切片(slicing)節(jié)點(diǎn)對(duì)這些變換進(jìn)行上采樣,然后變換到全分辨率圖像。該模型是從數(shù)據(jù)離線訓(xùn)練的,不需要在運(yùn)行時(shí)訪問原始操作。這樣模型可以學(xué)習(xí)復(fù)雜的、依賴于場(chǎng)景的變換。
如圖所示,對(duì)低分辨率的輸入I的低分辨率副本I~執(zhí)行大部分推斷(圖頂部),類似于雙邊網(wǎng)格(bilateral grid)方法,最終預(yù)測(cè)局部仿射變換。圖像增強(qiáng)通常不僅取決于局部圖像特征,還取決于全局圖像特征,如直方圖、平均強(qiáng)度甚至場(chǎng)景類別。因此,低分辨率流進(jìn)一步分為局部路徑和全局路徑。將這兩條路徑融合在一起,則生成代表仿射變換的系數(shù)。
而高分辨率流(圖底部)在全分辨率模式工作,執(zhí)行最少的計(jì)算,但有捕獲高頻效果和保留邊緣的作用。為此,引入了一個(gè)切片節(jié)點(diǎn)。該節(jié)點(diǎn)基于學(xué)習(xí)的導(dǎo)圖(guidance map)在約束系數(shù)的低分辨率格點(diǎn)做數(shù)據(jù)相關(guān)查找。基于全分辨率導(dǎo)圖,給定網(wǎng)格切片獲得的高分辨率仿射系數(shù),對(duì)每個(gè)像素做局部顏色變換,產(chǎn)生最終輸出O。在訓(xùn)練時(shí),在全分辨率下最小化損失函數(shù)。這意味著,僅處理大量下采樣數(shù)據(jù)的低分辨率流,仍然可以學(xué)習(xí)再現(xiàn)高頻效果的中間特征和仿射系數(shù)。
下面可以從一些例子看到各個(gè)改進(jìn)的效果。如圖所示,低級(jí)卷積層具備學(xué)習(xí)能力,可以提取語義信息。用標(biāo)準(zhǔn)雙邊網(wǎng)格的噴濺操作(splatting operation)替換這些層會(huì)導(dǎo)致網(wǎng)絡(luò)失去很大的表現(xiàn)力。

如圖所示,全局特征路徑允許模型推理完整圖像,(a)例如再現(xiàn)通過強(qiáng)度分布或場(chǎng)景類型的調(diào)整。(b)如果沒有全局路徑,模型可以做出空間不一致的局部決策。

如圖所示,新切片節(jié)點(diǎn)對(duì)架構(gòu)的表現(xiàn)力及其對(duì)高分辨率效果的處理至關(guān)重要。用反卷積濾波器組替換該節(jié)點(diǎn)會(huì)降低表現(xiàn)力(b),因?yàn)闆]有使用全分辨率數(shù)據(jù)來預(yù)測(cè)輸出像素。由于全分辨率導(dǎo)圖,切片層以更高的保真度(c)逼近。

如圖所示,(b)HDR的亮度畸變,特別是在前額和臉頰的高光區(qū)域出現(xiàn)的海報(bào)化畸變(posterization artifacts)。相反,切片節(jié)點(diǎn)的導(dǎo)圖使(c)正確地再現(xiàn)(d)基礎(chǔ)事實(shí)GT。

? Deep Photo Enhancer
它提出一種不成對(duì)學(xué)習(xí)(unpaired learning)的圖像增強(qiáng)方法。給定一組具有所需特征的照片,該方法學(xué)習(xí)一種照片增強(qiáng)器,將輸入圖像轉(zhuǎn)換為具有這些特征的增強(qiáng)圖像。在基于雙路(two-way)生成對(duì)抗網(wǎng)絡(luò)(GAN)框架基礎(chǔ)上,改進(jìn)如下:1)基于全局特征擴(kuò)充U-Net,而全局U-Net是GAN模型的生成器;2)用自適應(yīng)加權(quán)方案改進(jìn)Wasserstein GAN(WGAN),訓(xùn)練收斂更快更好,對(duì)參數(shù)敏感度低于WGAN-GP;3)在雙路GAN的生成器采用單獨(dú)BN層,有助于生成器更好地適應(yīng)自身輸入分布,提高GAN訓(xùn)練的穩(wěn)定性。
如圖介紹了雙路GAN的架構(gòu)。(a)是單向GAN的架構(gòu)。給定輸入x∈X,生成器GX將x變換為y'= GX(x)∈Y。鑒別器DY旨在區(qū)分目標(biāo)域{y}中的樣本和生成的樣本{y'= GX(x)}。為了實(shí)現(xiàn)循環(huán)一致性,雙路GAN被采用,例如CycleGAN 和DualGAN 。它們需要G'Y(GX(x))= x,其中生成器G'Y采用GX生成的樣本并將其映射回源域X。此外,雙路GAN通常包含前向映射(X →Y)和后向映射(Y→X)。(b)顯示了雙路GAN的體系結(jié)構(gòu)。在前向傳播時(shí),
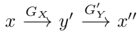
,檢查x''和x之間的一致性。在后向傳播時(shí),
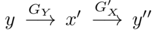
,檢查y和y''之間的一致性。

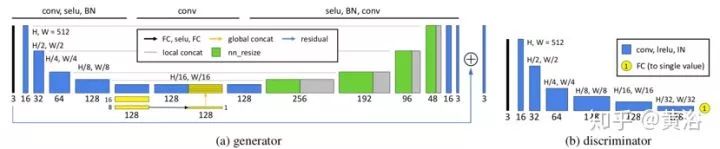
如圖是GAN的生成器和鑒別器架構(gòu)。生成器器基于U-Net,但添加全局特征。為了提高模型效率,全局特征的提取與U-Net的收縮部分共享前五層局部特征的提取。每個(gè)收縮步驟包括5×5濾波、步幅為2、SELU激活和BN。對(duì)全局特征來說,假定第五層是32×32×128特征圖,收縮后進(jìn)一步減小到16×16×128然后8×8×128。通過全連接層、SELU激活層和另一個(gè)全連接層,將8×8×128特征圖減少到1×1×128。然后將提取的1×1×128全局特征復(fù)制32×32個(gè)拷貝,并和低級(jí)特征32×32×128之后相連接,得到32×32×256特征圖,其同時(shí)融合了局部和全局特征。在融合的特征圖上執(zhí)行U-Net的擴(kuò)展路徑。最后,采用殘差學(xué)習(xí)的思想,也就是說,生成器只學(xué)習(xí)輸入圖像和標(biāo)注圖像之間的差異。
WGAN依賴于訓(xùn)練目標(biāo)的Lipschitz約束:當(dāng)且僅當(dāng)它梯度模最多是1時(shí),一個(gè)可微函數(shù)是1-Lipschtiz 。為了滿足約束條件,WGAN-GP通過添加以下梯度懲罰直接約束鑒別器相對(duì)于其輸入的輸出梯度模,
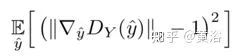
其中y?是沿目標(biāo)分布與生成器分布之間的直線的采樣點(diǎn)。
參數(shù)λ加權(quán)原鑒別器損失的懲罰。λ確定梯度趨進(jìn)1的趨勢(shì)。如果λ太小,無法保證Lipschitz約束。另一方面,如果λ太大,則收斂可能緩慢,因?yàn)閼土P可能過重加權(quán)鑒別器損失。λ的選擇很重要。相反,使用以下梯度懲罰,
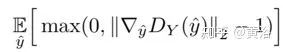
這更好地反映了要求梯度小于或等于1并且僅懲罰大于1部分的Lipschitz約束。更重要的是,可采用自適應(yīng)加權(quán)方案調(diào)整權(quán)重λ,選擇適當(dāng)?shù)臋?quán)重,即梯度位于所需的間隔內(nèi),比如[1.001, 1.05]。如果滑動(dòng)窗(大小= 50)內(nèi)的梯度移動(dòng)平均值(moving average of gradients)大于上限,則意味著當(dāng)前權(quán)重λ太小而且懲罰力不足以確保Lipschitz約束。因此,通過加倍權(quán)重來增加λ。另一方面,如果梯度移動(dòng)平均值小于下限,則將λ衰減一半,這樣就不會(huì)變得太大。這個(gè)改進(jìn),稱為A-GAN(自適應(yīng)GAN)。
前面圖(a)生成器作GX而圖(b)鑒別器用作DY,得到以前圖(a)單路GAN的架構(gòu)。同樣推廣A-GAN可以得到如以前圖(b)的雙路GAN架構(gòu)。
? Deep Illumination Estimation
這是一種基于神經(jīng)網(wǎng)絡(luò)增強(qiáng)曝光不足照片的方法,其中引入中間照明(intermediate illumination),將輸入與預(yù)期的增強(qiáng)結(jié)果相關(guān)聯(lián),也加強(qiáng)了網(wǎng)絡(luò)的能力,能夠從專家修改的輸入/輸出圖像對(duì)學(xué)習(xí)復(fù)雜的攝影修整過程。基于該模型,用照明的約束和先驗(yàn)定義一個(gè)損失函數(shù),并訓(xùn)練網(wǎng)絡(luò)有效地學(xué)習(xí)各種照明條件的修整過程。通過這些方式,網(wǎng)絡(luò)能夠恢復(fù)清晰的細(xì)節(jié),鮮明的對(duì)比度和自然色彩。
從根本上說,圖像增強(qiáng)任務(wù)可以被稱為尋找映射函數(shù)F,從輸入圖像I增強(qiáng),I ? = F(I)是期望的圖像。在Retinex的圖像增強(qiáng)方法中,F(xiàn)的倒數(shù)通常建模為照明圖S,其以像素方式與反射圖像I ?相乘產(chǎn)生觀察圖像I:I = S * I ?。
可以將反射分量I ?視為曝光良好的圖像,因此在模型中,I ?作為增強(qiáng)結(jié)果,I作為觀察到的未曝光圖像。一旦S已知,可以通過F(I)= S-1 * I獲得增強(qiáng)結(jié)果I ?. S被模型化為多通道(R,G,B)數(shù)據(jù)而不是單通道數(shù)據(jù),以增加其在顏色增強(qiáng)方面的能力,尤其是處理不同顏色通道的非線性特性。
如圖是網(wǎng)絡(luò)的流水線圖。增強(qiáng)曝光不足的照片需要調(diào)整局部(對(duì)比度,細(xì)節(jié)清晰度,陰影和高光)和全局特征(顏色分布,平均亮度和場(chǎng)景類別)。從編碼器網(wǎng)絡(luò)生成的特征考慮局部和全局上下文信息,見圖上部。為了驅(qū)動(dòng)網(wǎng)絡(luò)學(xué)習(xí)從輸入的曝光不足圖像(Ii)到相應(yīng)的專家修飾圖像(I ?)的照明映射,設(shè)計(jì)了一種損失函數(shù),具有照明平滑度先驗(yàn)知識(shí)以及增強(qiáng)的重建和顏色損失,見圖底部。這些策略有效地從(Ii,I ?i)學(xué)習(xí)S,通過各種各樣的照片調(diào)整來恢復(fù)增強(qiáng)的圖像。值得一提的是,該方法學(xué)習(xí)低分辨率下預(yù)測(cè)圖像-照明映射的局部和全局特征,同時(shí)基于雙邊網(wǎng)格的上采樣將低分辨率預(yù)測(cè)擴(kuò)展到全分辨率,系統(tǒng)實(shí)時(shí)性好。
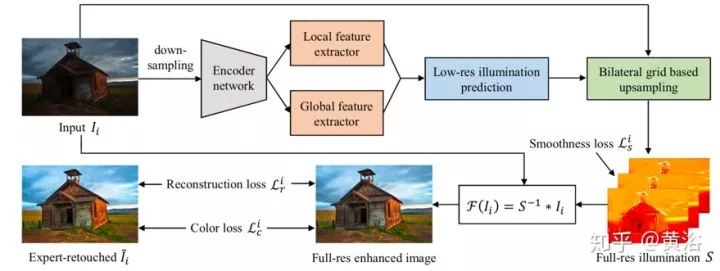
下圖展示了一些增強(qiáng)的結(jié)果例子(上:輸入,下:增強(qiáng))。

1. K Zhang et al., “Beyond a Gaussian denoiser: Residual learning of deep CNN for image denoising”,IEEE T-IP,2017
2. A Ignatov et al., “DSLR-Quality Photos on Mobile Devices with Deep Convolutional Networks“,arXiv 1704.02470, 2017
3. P. Svoboda et al., “Compression artifacts removal using convolutional neural networks”. arXiv 1605.00366, 2016.
4. B. Cai et al.,”Dehazenet: An end-to-end system for single image haze removal”. IEEE T-IP, 2016
5. X. Mao, C. Shen, Y.-B. Yang. “Image restoration using very deep convolutional encoder-decoder networks with symmetric skip connections”. Advances in Neural Information Processing Systems 29, 2016
6. Z. Yan et al., “Automatic photo adjustment using deep neural networks”. ACM Trans. Graph., 2016
7. M Gharbi et al.,“Deep Bilateral Learning for Real-Time Image Enhancement”, arXiv 1707.02880, 2017
8. S Nah, T Kim, K Lee,“Deep Multi-scale Convolutional Neural Network for Dynamic Scene Deblurring”, CVPR, 2017
9. Y Chen et al.,“Deep Photo Enhancer: Unpaired Learning for Image Enhancement from Photographs with GANs”, CVPR, 2018.
10. J Zhang et al., "Dynamic Scene Deblurring Using Spatially Variant Recurrent Neural Networks", CVPR 2018.
11. S Guo et al.,“Toward Convolutional Blind Denoising of Real Photographs”, CVPR, 2019
12. R Wang et al.,“Underexposed Photo Enhancement using Deep Illumination Estimation”, CVPR 2019.
13. Y Qu et al.,“Enhanced Pix2pix Dehazing Network”, CVPR, 2019
14. S Zhou et al.,“DAVANet: Stereo Deblurring with View Aggregation”, CVPR 2019.
15. W Chen, J Ding, S Kuo,“PMS-Net: Robust Haze Removal Based on Patch Map for Single Images”, CVPR, 2019
交流群
歡迎加入公眾號(hào)讀者群一起和同行交流,目前有SLAM、三維視覺、傳感器、自動(dòng)駕駛、計(jì)算攝影、檢測(cè)、分割、識(shí)別、醫(yī)學(xué)影像、GAN、算法競(jìng)賽等微信群(以后會(huì)逐漸細(xì)分),請(qǐng)掃描下面微信號(hào)加群,備注:”昵稱+學(xué)校/公司+研究方向“,例如:”張三 + 上海交大 + 視覺SLAM“。請(qǐng)按照格式備注,否則不予通過。添加成功后會(huì)根據(jù)研究方向邀請(qǐng)進(jìn)入相關(guān)微信群。請(qǐng)勿在群內(nèi)發(fā)送廣告,否則會(huì)請(qǐng)出群,謝謝理解~