作者 | Robin
翻譯 | 周凱波
來源 | Flink中文社區(qū)
Contentsquare 公司的 Robin 總結(jié)了他們將 Spark 任務(wù)遷移到 Flink 遇到的 10 個『陷阱』。對于第一次將 Flink 用于生產(chǎn)環(huán)境的用戶來說,這些經(jīng)驗(yàn)非常有參考意義。
采用新的框架總是會帶來很多驚喜。當(dāng)你花了幾天時(shí)間去排查為什么服務(wù)運(yùn)行異常,結(jié)果發(fā)現(xiàn)只是因?yàn)槟硞€功能的用法不對或者缺少一些簡單的配置。
在 Contentsquare[1],我們需要不斷升級數(shù)據(jù)處理任務(wù),以滿足越來越多的數(shù)據(jù)上的苛刻需求。這也是為什么我們決定將用于會話[2]處理的小時(shí)級 Spark 任務(wù)遷移到 Flink[3] 流服務(wù)。這樣我們就可以利用 Flink 更為健壯的處理能力,提供更實(shí)時(shí)的數(shù)據(jù)給用戶,并能提供歷史數(shù)據(jù)。不過這并不輕松,我們的團(tuán)隊(duì)在上面工作了有一年時(shí)間。同時(shí),我們也遇到了一些令人驚訝的問題,本文將嘗試幫助你避免這些陷阱。
1. 并行度設(shè)置導(dǎo)致的負(fù)載傾斜
我們從一個簡單的問題開始:在 Flink UI 中調(diào)查某個作業(yè)的子任務(wù)時(shí),關(guān)于每個子任務(wù)處理的數(shù)據(jù)量,你可能會遇到如下這種奇怪的情況。

每個子任務(wù)的工作負(fù)載并不均衡
這表明每個子任務(wù)的算子沒有收到相同數(shù)量的 Key Groups,它代表所有可能的 key 的一部分。如果一個算子收到了 1 個 Key Group,而另外一個算子收到了 2 個,則第二個子任務(wù)很可能需要完成兩倍的工作。查看 Flink 的代碼,我們可以找到以下函數(shù):
public static int computeOperatorIndexForKeyGroup( int maxParallelism, int parallelism, int keyGroupId) { return keyGroupId * parallelism / maxParallelism; }
其目的是將所有 Key Groups 分發(fā)給實(shí)際的算子。Key Groups 的總數(shù)由 maxParallelism 參數(shù)決定,而算子的數(shù)量和 parallelism 相同。這里最大的問題是 maxParallelism 的默認(rèn)值,它默認(rèn)等于 operatorParallelism + (operatorParallelism / 2) [4]。假如我們設(shè)置 parallelism 為10,那么 maxParallelism 為 15 (實(shí)際最大并發(fā)度值的下限是 128 ,上限是 32768,這里只是為了方便舉例)。這樣,根據(jù)上面的函數(shù),我們可以計(jì)算出哪些算子會分配給哪些 Key Group。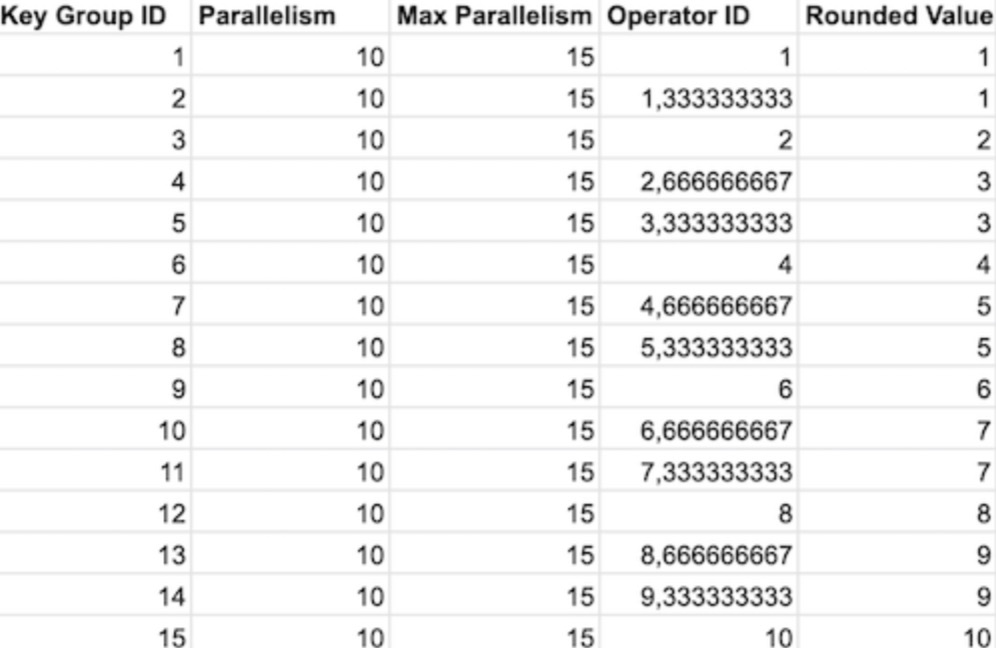
在默認(rèn)配置下,部分算子分配了兩個 Key Group,解決這個問題非常容易:設(shè)置并發(fā)度的時(shí)候,還要為 maxParallelism 設(shè)置一個值,且該值為 parallelism 的倍數(shù)。這將讓負(fù)載更加均衡,同時(shí)方便以后擴(kuò)展。
2. 注意 mapWithState & TTL 的重要性
在處理包含無限多鍵的數(shù)據(jù)時(shí),要考慮到 keyed 狀態(tài)保留策略(通過 TTL 定時(shí)器來在給定的時(shí)間之后清理未使用的數(shù)據(jù))是很重要的。術(shù)語『無限』在這里有點(diǎn)誤導(dǎo),因?yàn)槿绻阋幚淼?key 以 128 位編碼,則 key 的最大數(shù)量將會有個限制(等于 2 的 128 次方)。但這是一個巨大的數(shù)字!你可能無法在狀態(tài)中存儲那么多值,所以最好考慮你的鍵空間是無界的,同時(shí)新鍵會隨著時(shí)間不斷出現(xiàn)。
如果你的 keyed 狀態(tài)包含在某個 Flink 的默認(rèn)窗口中,則將是安全的:即使未使用 TTL,在處理窗口的元素時(shí)也會注冊一個清除計(jì)時(shí)器,該計(jì)時(shí)器將調(diào)用 clearAllState 函數(shù),并刪除與該窗口關(guān)聯(lián)的狀態(tài)及其元數(shù)據(jù)。如果要使用 Keyed State Descriptor [5]來管理狀態(tài),可以很方便地添加 TTL 配置,以確保在狀態(tài)中的鍵數(shù)量不會無限制地增加。但是,你可能會想使用更簡便的 mapWithState 方法,該方法可讓你訪問 valueState 并隱藏操作的復(fù)雜性。雖然這對于測試和少量鍵的數(shù)據(jù)來說是很好的選擇,但如果在生產(chǎn)環(huán)境中遇到無限多鍵值時(shí),會引發(fā)問題。由于狀態(tài)是對你隱藏的,因此你無法設(shè)置 TTL,并且默認(rèn)情況下未配置任何 TTL。這就是為什么值得考慮做一些額外工作的原因,如聲明諸如 RichMapFunction 之類的東西,這將使你能更好的控制狀態(tài)的生命周期。
在使用大狀態(tài)時(shí),有必要使用增量檢查點(diǎn)(incremental checkpointing)。在我們的案例中,任務(wù)的完整狀態(tài)約為 8TB,我們將檢查點(diǎn)配置為每 15 分鐘做一次。由于檢查點(diǎn)是增量式的,因此我們只能設(shè)法每 15 分鐘將大約 100GB 的數(shù)據(jù)發(fā)送到對象存儲,這是一種更快的方式并且網(wǎng)絡(luò)占用較少。這對于容錯效果很好,但是在更新任務(wù)時(shí)我們也需要檢索狀態(tài)。常用的方法是為正在運(yùn)行的作業(yè)創(chuàng)建一個保存點(diǎn)(savepoint),以可移植的格式包含整個狀態(tài)。但是,在我們的情況下,保存點(diǎn)可能需要幾個小時(shí)才能完成,這使得每次發(fā)布版本都是一個漫長而麻煩的過程。相反,我們決定使用保留檢查點(diǎn)(Retained Checkpoints[6])。設(shè)置此參數(shù)后,我們可以通過從上一個作業(yè)的檢查點(diǎn)恢復(fù)狀態(tài)來加快發(fā)布速度,而不必觸發(fā)冗長的保存點(diǎn)!此外,盡管保存點(diǎn)比檢查點(diǎn)具有更高的可移植性,但您仍然可以使用保留的檢查點(diǎn)來更改作業(yè)的分區(qū)(它可能不適用于所有類型的作業(yè),所以最好對其進(jìn)行測試)。這與從保存點(diǎn)重新分區(qū)完全一樣,但是不需要經(jīng)歷 Flink 在 TaskManager 之間重新分配數(shù)據(jù)的漫長過程。當(dāng)我們嘗試這樣做時(shí),大約花了 8 個小時(shí)才完成,這是不可持續(xù)的。幸運(yùn)的是,由于我們使用的是 RocksDB 狀態(tài)后端,因此我們可以在這步中增加更多線程以提高其速度。這是通過將以下兩個參數(shù)從 1 增加到 8 來完成的:state.backend.rocksdb.checkpoint.transfer.thread.num:8state.backend.rocksdb.thread.num:8
使用保留的檢查點(diǎn),并增加分配給 RocksDB 傳輸?shù)木€程數(shù),能將發(fā)布和重新分區(qū)時(shí)間減少 10 倍!
這一點(diǎn)可能看起來很明顯,但也很容易忘記。開發(fā)作業(yè)時(shí),請記住它將運(yùn)行很長時(shí)間,并且可能會處理意外的數(shù)據(jù)。發(fā)生這種情況時(shí),你將需要盡可能多的信息來調(diào)查發(fā)生了什么,而不必通過再次回溯相同的數(shù)據(jù)來重現(xiàn)問題。我們的任務(wù)是將事件匯總在一起,并根據(jù)特定規(guī)則進(jìn)行合并。這些規(guī)則中的某些規(guī)則在大多數(shù)情況下性能還可以,但是當(dāng)有數(shù)據(jù)傾斜時(shí)卻要花費(fèi)很長時(shí)間。當(dāng)我們發(fā)現(xiàn)任務(wù)卡住了 3 個小時(shí),卻不知道它在做什么。似乎只有一個 TaskManager 的 CPU 可以正常工作,因此我們懷疑是特定數(shù)據(jù)導(dǎo)致我們的算法性能下降。最終處理完數(shù)據(jù)后,一切恢復(fù)正常,但是我們不知道從哪開始檢查!這就是為什么我們?yōu)檫@些情況添加了一些預(yù)防性日志的原因:在處理窗口時(shí),我們會測量花費(fèi)的時(shí)間。只要計(jì)算窗口所需的時(shí)間超過 1 分鐘,我們就會記錄下所有可能的數(shù)據(jù)。這對于準(zhǔn)確了解導(dǎo)致性能下降的傾斜是非常有幫助的,并且當(dāng)再次發(fā)生這種情況時(shí),我們能夠定位到合并過程處理慢的部分原因。假如收到的是重復(fù)的數(shù)據(jù),則可能確實(shí)需要幾個小時(shí)。當(dāng)然,重要的是不要過多地記錄信息,因?yàn)檫@會降低性能。因此,請嘗試找到僅在異常情況下才顯示信息的閾值。
5. 如何找出卡住的作業(yè)實(shí)際上在做什么
對上述問題的調(diào)查也使我們意識到,我們需要找到一種簡單的方法,來定位作業(yè)疑似卡住時(shí)當(dāng)前正在運(yùn)行的代碼段。幸運(yùn)的是,有一個簡單的方法可以做到這一點(diǎn)!首先,您將需要配置 TaskManagers 的 JMX 以接受遠(yuǎn)程監(jiān)視。在 Kubernetes 部署中,我們可以通過三個步驟連接到 JMX:
- 首先,將此屬性添加到我們的 flink-conf.yaml 中
env.java.opts: "-Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.local.only=false -Dcom.sun.management.jmxremote.port=1099 -Dcom.sun.management.jmxremote.rmi.port=1099 -Djava.rmi.server.hostname=127.0.0.1"
- 然后,將本地端口 1099 轉(zhuǎn)發(fā)到 TaskManager 的 pod 中的端口
kubectl port-forward flink-taskmanager-4 1099
這使您可以輕松地在 JVM 上查看目標(biāo) TaskManager 的信息。對于卡住的作業(yè),我們以正在運(yùn)行的唯一一個 TaskManager 為目標(biāo),分析了正在運(yùn)行的線程:
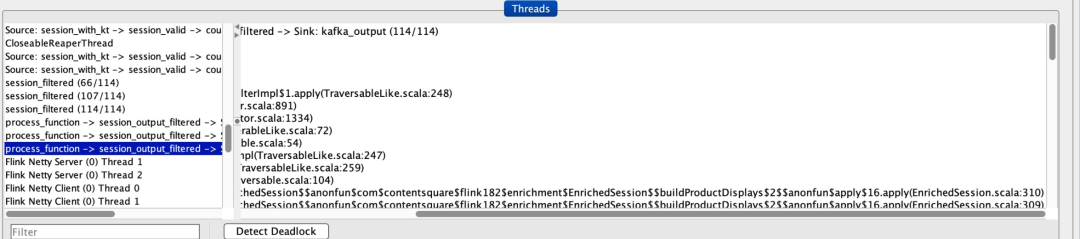
JConsole 向我們展示了每個線程當(dāng)前正在做什么深入研究,我們可以看到所有線程都在等待,除了其中一個(在上面的屏幕截圖中已突出顯示)。這使得我們能夠快速發(fā)現(xiàn)作業(yè)是卡在哪個方法調(diào)用里面的,并輕松修復(fù)!
6. 將數(shù)據(jù)從一種狀態(tài)
遷移到另一種狀態(tài)的風(fēng)險(xiǎn)
根據(jù)你的實(shí)際情況,可能需要保留兩個具有不同語義的不同狀態(tài)描述符。例如,我們通過 WindowContent 狀態(tài)為進(jìn)行中的會話累積事件,接著將處理后的會話移動到稱為 HistoricalSessions 的 ValueState 中。第二個狀態(tài)為了防止后面需要用到會保留幾天,直到 TTL 過期丟棄它為止。我們做的第一個測試運(yùn)行良好:我們可以發(fā)送額外的數(shù)據(jù)到已處理的會話,這將為相同的鍵創(chuàng)建一個新窗口。在窗口的處理過程中,我們會從 HistoricalSessions 狀態(tài)中獲取數(shù)據(jù),以將新數(shù)據(jù)與舊會話合并,并且結(jié)果會話是歷史會話的增強(qiáng)版本,這也正是我們所期望的。在執(zhí)行此操作時(shí),我們遇到過幾次內(nèi)存問題。經(jīng)過幾次測試后,我們了解到 OOM 僅在將舊數(shù)據(jù)發(fā)送到 Flink 時(shí)才發(fā)生(即,發(fā)送數(shù)據(jù)的時(shí)間戳早于其當(dāng)前水印)。這使得我們發(fā)現(xiàn)了當(dāng)前處理方式中的一個大問題:當(dāng)接收到舊數(shù)據(jù)時(shí),F(xiàn)link 將其與舊窗口合并,而舊窗口的數(shù)據(jù)仍在 WindowContent 狀態(tài)內(nèi)(這可以通過設(shè)置 AllowedLateness 實(shí)現(xiàn))。然后結(jié)果窗口會與 HistoricalSessions 內(nèi)容合并,該內(nèi)容還包含舊的數(shù)據(jù)。最終我們得到的是重復(fù)的事件,在同一會話中收到一些事件后,每個事件都將有數(shù)千條重復(fù),從而導(dǎo)致了 OOM。這個問題的解法非常簡單:我們希望 WindowContent 在將其內(nèi)容移至第二個狀態(tài)之前自動清除。我們使用了 Flink 的 PurgingTrigger 來達(dá)到這個目的,當(dāng)窗口觸發(fā)時(shí),該消息會發(fā)送一條清除狀態(tài)內(nèi)容的消息。具體代碼如下所示:// Purging the window's content allows us to receive late events without merging them twice with the old session val sessionWindows = keyedStream .window(EventTimeSessionWindows.withGap(Time.minutes(30))) .allowedLateness(Time.days(7)) .trigger(PurgingTrigger.of(EventTimeTrigger.create()))
如上所述,我們對 Flink 的使用依賴于累積給定鍵的數(shù)據(jù),并將所有這些數(shù)據(jù)合并在一起。這可以通過兩種方式完成:- 將數(shù)據(jù)存儲在 ListState 容器中,等待會話結(jié)束,并在會話結(jié)束時(shí)將所有數(shù)據(jù)合并在一起
- 使用 ReducingState 在每個新事件到達(dá)時(shí),將其與之前的事件合并
使用第一種還是第二種狀態(tài)取決于你在 WindowedStream 上運(yùn)行的功能:使用 ProcessWindowFunction 的 process 調(diào)用將使用 ListState,而使用 ReduceFunction 的 reduce 調(diào)用則將使用 ReducingState。ReducingState 的優(yōu)點(diǎn)非常明顯:不存儲窗口處理之前的所有數(shù)據(jù),而是在單個記錄中不斷地對其進(jìn)行聚合。這通常會導(dǎo)致狀態(tài)更小,取決于在 reduce 操作期間會丟棄多少數(shù)據(jù)。對我們來說,它在存儲方面幾乎沒有改善,因?yàn)榕c我們?yōu)闅v史會話存儲的 7 天數(shù)據(jù)相比,該狀態(tài)的大小可以忽略不計(jì)。相反,我們注意到通過使用 ListState 可以提高性能!原因是:每次新事件到來時(shí),連續(xù)的 reduce 操作都需要對數(shù)據(jù)進(jìn)行反序列化和序列化。這可以在 RocksDBReducingState[7] 的 add 函數(shù)中看到,該函數(shù)會調(diào)用 getInternal[8],從而導(dǎo)致數(shù)據(jù)反序列化。但是,當(dāng)使用 RocksDB 更新 ListState 中的值,我們可以看到?jīng)]有序列化發(fā)生[9]。這要?dú)w功于 RocksDB 的合并操作能讓 Flink 可以將數(shù)據(jù)進(jìn)行追加而無需反序列化。最后,我們選擇了 ListState 方法,因?yàn)樾阅芴嵘兄跍p少延遲,而存儲的影響卻很小。
永遠(yuǎn)不要假設(shè)你的輸入會像你期望的那樣。可能會出現(xiàn)各種未知的情況,比如你的任務(wù)接收到了傾斜的數(shù)據(jù)、重復(fù)的數(shù)據(jù)、意外的峰值、無效的記錄……總是往最壞的方面想,保護(hù)你的作業(yè)免受這些影響。
讓我們快速定義幾個關(guān)鍵術(shù)語,供后面使用:- “網(wǎng)頁瀏覽(PV)事件”是我們接收到的主要信息。當(dāng)訪問者在客戶端加載 URL 以及 userId、sessionNumber 和 pageNumber 等信息時(shí),就會觸發(fā)它
- “會話”代表用戶在不離開網(wǎng)站的情況下進(jìn)行的所有互動的總和。它們是由 Flink 通過匯總 PV 事件和其他信息計(jì)算得出的
為了保護(hù)我們的任務(wù),我們已盡可能的增加前置過濾。我們必須遵守的規(guī)則是,盡可能早地在流中過濾掉無效數(shù)據(jù),以避免在中后期造成不必要的昂貴操作。例如,我們有一個規(guī)則,對于給定的會話,最多只能發(fā)送 300 個 PV 事件。每個 PV 事件都用一個遞增的頁碼標(biāo)記,以指示其在會話中的位置。當(dāng)我們在一個會話中接收到超過 300 個 PV 事件時(shí),我們可以通過以下方法來過濾它們:- 計(jì)算一個給定窗口過期時(shí)的 PV 事件的數(shù)量
第一個方案似乎更可靠,因?yàn)樗灰蕾囉陧摯a的值,但是我們要在狀態(tài)中累積 300 多個 PV 事件,然后才能排除它們。最終我們選擇了第二個方案,該方案在錯誤數(shù)據(jù)進(jìn)入 Flink 時(shí)就進(jìn)行了排除。除了這些無狀態(tài)過濾器之外,我們還需要根據(jù)與每個鍵相關(guān)的指標(biāo)排除數(shù)據(jù)。例如,每個會話的最大大小(以字節(jié)為單位)設(shè)置為 4MB。選擇此數(shù)字是出于業(yè)務(wù)原因,也是為了幫助解決 Flink 中 RocksDB 狀態(tài)的一個限制。事實(shí)上,如果 Flink 使用的 RocksDB API 的值超過 2 ^ 31 字節(jié)[10],那么它就會失敗。因此,如果你像上面解釋的那樣使用一個 ListState,則需要確保你永遠(yuǎn)不要累積太多的數(shù)據(jù)。
當(dāng)你只有關(guān)于新消費(fèi)的事件的信息時(shí),就不可能知道會話的當(dāng)前大小,這意味著我們不能使用與處理頁碼相同的技巧。我們所做的只是將 RocksDB 中的每個鍵(即每個會話)的元數(shù)據(jù)存儲在一個單獨(dú)的 ValueState 中。此元數(shù)據(jù)在 keyBy 算子之后,但在開窗之前使用和更新。這意味著我們可以保護(hù) RocksDB 避免在其 ListState 中積累太多數(shù)據(jù),因?yàn)榛诖嗽獢?shù)據(jù),我們知道何時(shí)停止接受給定鍵的值!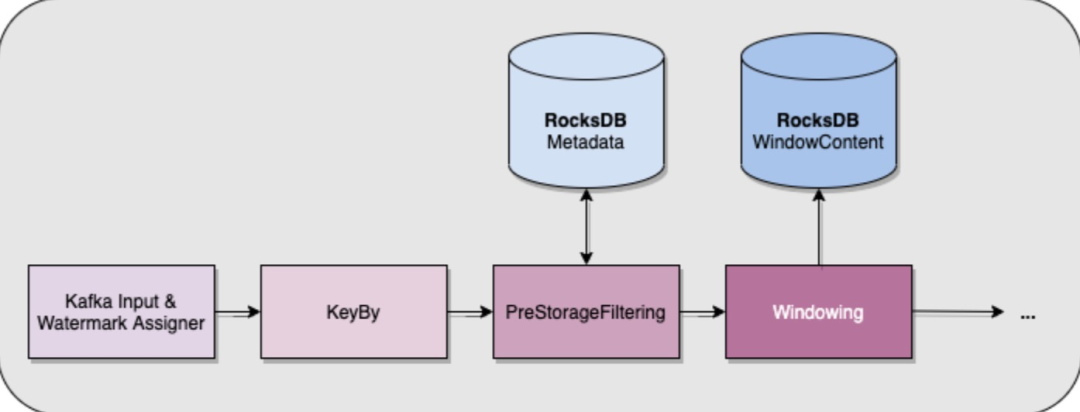
事件時(shí)間處理在大多數(shù)情況下都很出色,但你必須牢記:如果你處理晚到數(shù)據(jù)的方法很費(fèi)時(shí),可能會有一些糟糕的后果。這個問題并不是直接與 Flink 有關(guān),當(dāng)某個外部組件往 Kafka topic 在寫數(shù)據(jù),而同時(shí)Flink正在消費(fèi)這個 topic 的數(shù)據(jù),如果這個外部組件出現(xiàn)問題,就會發(fā)生數(shù)據(jù)晚到的現(xiàn)象。具體來說,當(dāng)這個組件消費(fèi)某些分區(qū)的速度比其他組件慢時(shí)。
這個組件(稱為 Asimov)是一個簡單的 Akka 流程序,該程序讀取 Kafka topic,解析 JSON 數(shù)據(jù),將其轉(zhuǎn)換為 protobuf,然后將其推送到另一個 Kafka topic,這樣Flink就可以處理這個 protobuf。Asimov 的輸入在每個分區(qū)中應(yīng)該是有序的,但是由于分區(qū)不是與輸出 topic 一對一映射,因此當(dāng)Flink最終處理消息時(shí),可能會出現(xiàn)一些亂序。這樣也沒啥問題,因?yàn)?Flink 能通過延遲水印來支持亂序。問題是,當(dāng) Asimov 讀取一個分區(qū)的速度比其他分區(qū)慢時(shí):這意味著 Flink 的水印將隨著最快的 Asimov 輸入分區(qū)(而不是 Flink 的輸入,因?yàn)樗蟹謪^(qū)都正常前進(jìn))前進(jìn),而慢的分區(qū)將發(fā)出具有更舊時(shí)間戳的記錄。這最終會導(dǎo)致 Flink 將這些記錄視為遲來的記錄! 這可能沒問題,但是在我們的作業(yè)中,我們使用特定的邏輯來處理晚到的記錄,需要從 RocksDB 獲取數(shù)據(jù)并生成額外的消息來執(zhí)行下游的更新。這意味著,每當(dāng) Asimov 因?yàn)槟撤N原因在幾個分區(qū)上落后時(shí),F(xiàn)link 就需要做更多的工作。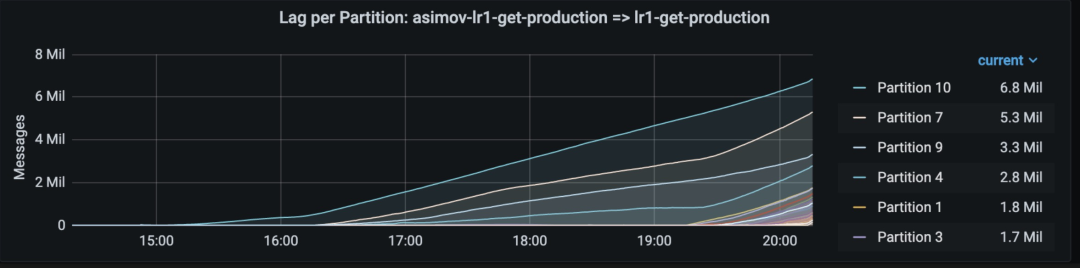
在有 128 個分區(qū)的 topic 中,只有 8 個分區(qū)累積延遲,從而導(dǎo)致 Flink 中的數(shù)據(jù)晚到我們發(fā)現(xiàn)了兩種解決此問題的方法:- 我們可以按照與它的輸出 topic 相同的方式(通過 userId)對 Asimov 的輸 入 topic 進(jìn)行分區(qū)。這意味著,當(dāng) Asimov 滯后幾個分區(qū),F(xiàn)link輸入中的相應(yīng)分區(qū)也滯后,從而導(dǎo)致水印前進(jìn)得更慢:
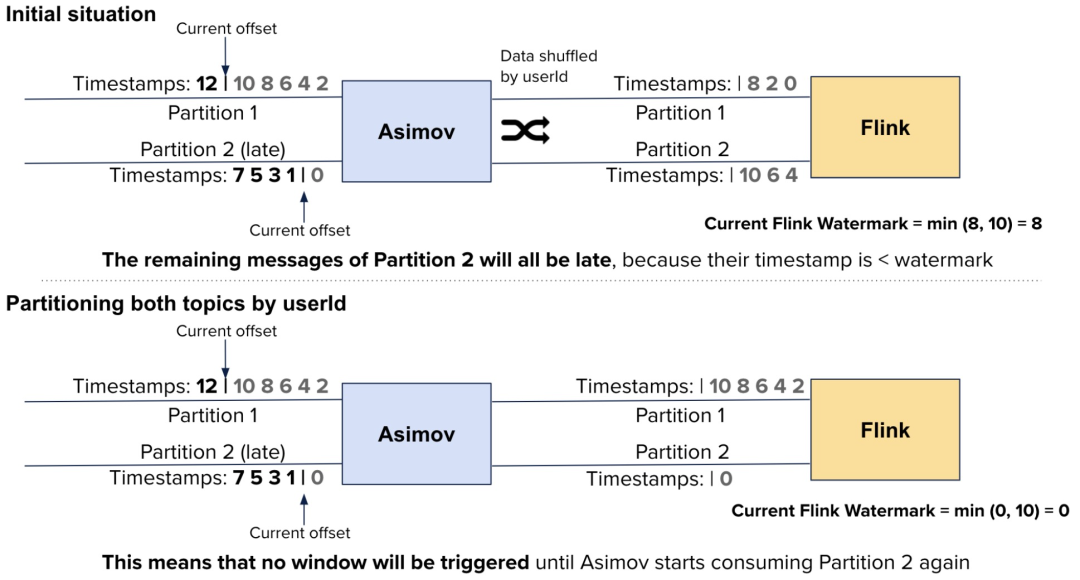
我們決定不這樣做,因?yàn)槿绻覀冊?Asimov 之前就有晚到的數(shù)據(jù),這個問題仍然會存在,這迫使我們得以相同的方式來給每個 topic 劃分分區(qū)。但這在很多情況下是不能做的。- 另一個解決方案依賴于攢批處理晚到的事件:如果我們可以推遲對晚到事件的處理,我們可以確保每個會話最多產(chǎn)生一個更新,而不是每個事件產(chǎn)生一個更新。
我們可以通過使用自定義觸發(fā)器,以避免出現(xiàn)晚到事件到達(dá)時(shí)就觸發(fā)窗口,從而實(shí)現(xiàn)第二種解決方案。正如你在默認(rèn)的 EventTimeTrigger 實(shí)現(xiàn)中所看到的,晚到事件在特定情況下不會注冊計(jì)時(shí)器。在我們的方案中,無論如何我們都會注冊一個計(jì)時(shí)器,并且不會立即觸發(fā)窗口。因?yàn)槲覀兊臉I(yè)務(wù)需求允許以這種方式進(jìn)行批量更新,所以我們可以確保當(dāng)上游出現(xiàn)延遲時(shí),我們不會生成數(shù)百個昂貴的更新。
10. 避免將所有內(nèi)容存儲在 Flink 中
讓我們以一些普遍的觀點(diǎn)來結(jié)束我們的討論:如果你的數(shù)據(jù)很大,并且不需要經(jīng)常訪問,那么最好將其存儲在 Flink 之外。在設(shè)計(jì)作業(yè)時(shí),你希望所有需要的數(shù)據(jù)都直接在 Flink 節(jié)點(diǎn)上(在 RocksDB 或內(nèi)存中)可用。當(dāng)然,這使得使用這種數(shù)據(jù)的方式更快,但當(dāng)數(shù)據(jù)很大時(shí),它會給你的作業(yè)增加很多成本。這是因?yàn)?Flink 的狀態(tài)沒有被復(fù)制,所以丟失一個節(jié)點(diǎn)需要從檢查點(diǎn)完全恢復(fù)。如果你經(jīng)常需要向檢查點(diǎn)存儲寫入數(shù)百 GB 數(shù)據(jù),則檢查點(diǎn)機(jī)制本身也很昂貴。
如果對狀態(tài)的訪問是性能需求中的關(guān)鍵部分,那么將它存儲在Flink中絕對是值得的。但是,如果你可以忍受額外的延遲,那么將它存儲在具有復(fù)制功能和支持對給定記錄快速訪問的外部數(shù)據(jù)庫中,這將為你節(jié)省很多麻煩。對于我們的用例,我們選擇將 WindowContent 狀態(tài)保留在 RocksDB 中,但我們將 HistoricalSessions 數(shù)據(jù)移入了 Aerospike[11]中。由于狀態(tài)較小,這使得我們的 Flink 作業(yè)更快,更容易維護(hù)。我們甚至還受益于這樣一個事實(shí):存儲在 Flink 中的剩余數(shù)據(jù)足夠小,可以都放入內(nèi)存,這讓我們無需使用 RocksDB 和本地 SSD。總而言之,使用 Flink 是一次很棒的經(jīng)歷:盡管有時(shí)我們無法理解框架的行為,但最終它總是有道理的。我強(qiáng)烈推薦訂閱 Flink 用戶郵件列表[12],從這個非常有用和友好的社區(qū)獲得額外的提示!https://engineering.contentsquare.com/2021/ten-flink-gotchas/
