
實戰(zhàn)!我用“大白鯊”讓你看見 TCP

前言
“哈?啥是大白鯊?”
咳咳,主要是因為網(wǎng)絡(luò)分析工具 Wireshark 的圖標特別像大白鯊頂部的角。
不信你看:

“為什么拖了怎么久才發(fā)文?”
為了讓大家更容易「看得見」 TCP,我搭建不少測試環(huán)境,并且數(shù)據(jù)包抓很多次,花費了不少時間,才抓到比較容易分析的數(shù)據(jù)包。
接下來丟包、亂序、超時重傳、快速重傳、選擇性確認、流量控制等等 TCP 的特性,都能「一覽無云」。
沒錯,我把 TCP 的"衣服扒光"了,就為了給大家看的清楚,嘻嘻。

提綱
正文
顯形“不可見”的網(wǎng)絡(luò)包
網(wǎng)絡(luò)世界中的數(shù)據(jù)包交互我們?nèi)庋凼强床灰姷模鼈兙秃孟耠[形了一樣,我們對著課本學習計算機網(wǎng)絡(luò)的時候就會覺得非常的抽象,加大了學習的難度。
還別說,我自己在大學的時候,也是如此。
直到工作后,認識了兩大分析網(wǎng)絡(luò)的利器:tcpdump 和 Wireshark,這兩大利器把我們“看不見”的數(shù)據(jù)包,呈現(xiàn)在我們眼前,一目了然。
唉,當初大學學習計網(wǎng)的時候,要是能知道這兩個工具,就不會學的一臉懵逼。
tcpdump 和 Wireshark 有什么區(qū)別?
tcpdump 和 Wireshark 就是最常用的網(wǎng)絡(luò)抓包和分析工具,更是分析網(wǎng)絡(luò)性能必不可少的利器。
tcpdump 僅支持命令行格式使用,常用在 Linux 服務(wù)器中抓取和分析網(wǎng)絡(luò)包。
Wireshark 除了可以抓包外,還提供了可視化分析網(wǎng)絡(luò)包的圖形頁面。
所以,這兩者實際上是搭配使用的,先用 tcpdump 命令在 Linux 服務(wù)器上抓包,接著把抓包的文件拖出到 Windows 電腦后,用 Wireshark 可視化分析。
當然,如果你是在 Windows 上抓包,只需要用 Wireshark 工具就可以。
tcpdump 在 Linux 下如何抓包?
tcpdump 提供了大量的選項以及各式各樣的過濾表達式,來幫助你抓取指定的數(shù)據(jù)包,不過不要擔心,只需要掌握一些常用選項和過濾表達式,就可以滿足大部分場景的需要了。
假設(shè)我們要抓取下面的 ping 的數(shù)據(jù)包:
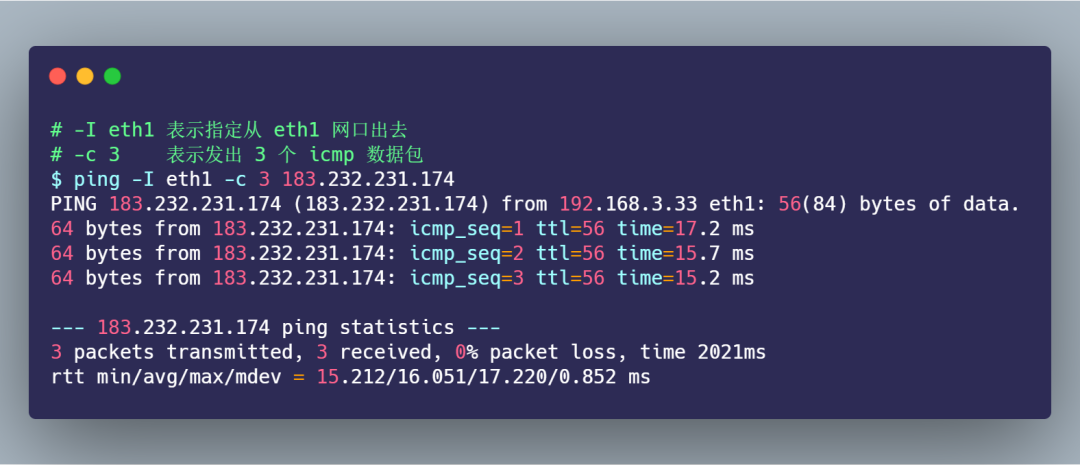
要抓取上面的 ping 命令數(shù)據(jù)包,首先我們要知道 ping 的數(shù)據(jù)包是 icmp 協(xié)議,接著在使用 tcpdump 抓包的時候,就可以指定只抓 icmp 協(xié)議的數(shù)據(jù)包:

那么當 tcpdump 抓取到 icmp 數(shù)據(jù)包后, 輸出格式如下:

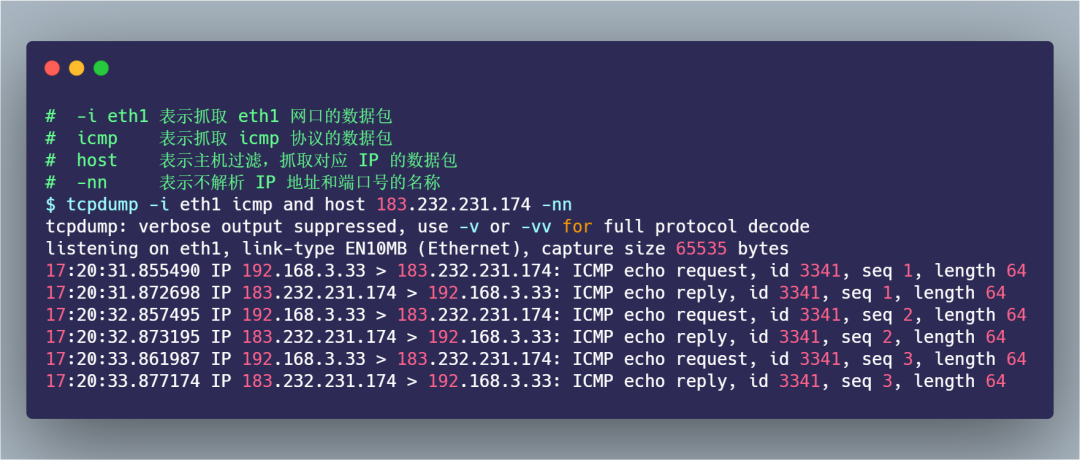
從 tcpdump 抓取的 icmp 數(shù)據(jù)包,我們很清楚的看到 icmp echo 的交互過程了,首先發(fā)送方發(fā)起了 ICMP echo request 請求報文,接收方收到后回了一個 ICMP echo reply 響應(yīng)報文,之后 seq 是遞增的。
我在這里也幫你整理了一些最常見的用法,并且繪制成了表格,你可以參考使用。
首先,先來看看常用的選項類,在上面的 ping 例子中,我們用過 -i 選項指定網(wǎng)口,用過 -nn 選項不對 IP 地址和端口名稱解析。其他常用的選項,如下表格:

接下來,我們再來看看常用的過濾表用法,在上面的 ping 例子中,我們用過的是 icmp and host 183.232.231.174,表示抓取 icmp 協(xié)議的數(shù)據(jù)包,以及源地址或目標地址為 183.232.231.174 的包。其他常用的過濾選項,我也整理成了下面這個表格。

說了這么多,你應(yīng)該也發(fā)現(xiàn)了,tcpdump 雖然功能強大,但是輸出的格式并不直觀。
所以,在工作中 tcpdump 只是用來抓取數(shù)據(jù)包,不用來分析數(shù)據(jù)包,而是把 tcpdump 抓取的數(shù)據(jù)包保存成 pcap 后綴的文件,接著用 Wireshark 工具進行數(shù)據(jù)包分析。
Wireshark 工具如何分析數(shù)據(jù)包?
Wireshark 除了可以抓包外,還提供了可視化分析網(wǎng)絡(luò)包的圖形頁面,同時,還內(nèi)置了一系列的匯總分析工具。
比如,拿上面的 ping 例子來說,我們可以使用下面的命令,把抓取的數(shù)據(jù)包保存到 ping.pcap 文件
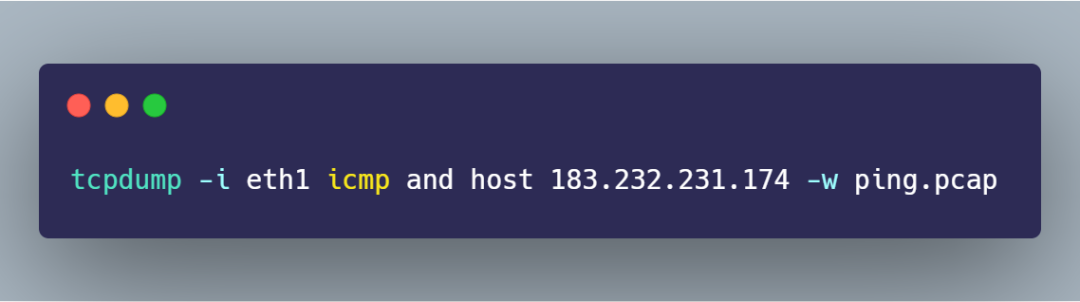
接著把 ping.pcap 文件拖到電腦,再用 Wireshark 打開它。打開后,你就可以看到下面這個界面:

是吧?在 Wireshark 的頁面里,可以更加直觀的分析數(shù)據(jù)包,不僅展示各個網(wǎng)絡(luò)包的頭部信息,還會用不同的顏色來區(qū)分不同的協(xié)議,由于這次抓包只有 ICMP 協(xié)議,所以只有紫色的條目。
接著,在網(wǎng)絡(luò)包列表中選擇某一個網(wǎng)絡(luò)包后,在其下面的網(wǎng)絡(luò)包詳情中,可以更清楚的看到,這個網(wǎng)絡(luò)包在協(xié)議棧各層的詳細信息。比如,以編號 1 的網(wǎng)絡(luò)包為例子:
絡(luò)包")
可以在數(shù)據(jù)鏈路層,看到 MAC 包頭信息,如源 MAC 地址和目標 MAC 地址等字段;
可以在 IP 層,看到 IP 包頭信息,如源 IP 地址和目標 IP 地址、TTL、IP 包長度、協(xié)議等 IP 協(xié)議各個字段的數(shù)值和含義;
可以在 ICMP 層,看到 ICMP 包頭信息,比如 Type、Code 等 ICMP 協(xié)議各個字段的數(shù)值和含義;
Wireshark 用了分層的方式,展示了各個層的包頭信息,把“不可見”的數(shù)據(jù)包,清清楚楚的展示了給我們,還有理由學不好計算機網(wǎng)絡(luò)嗎?是不是相見恨晚?
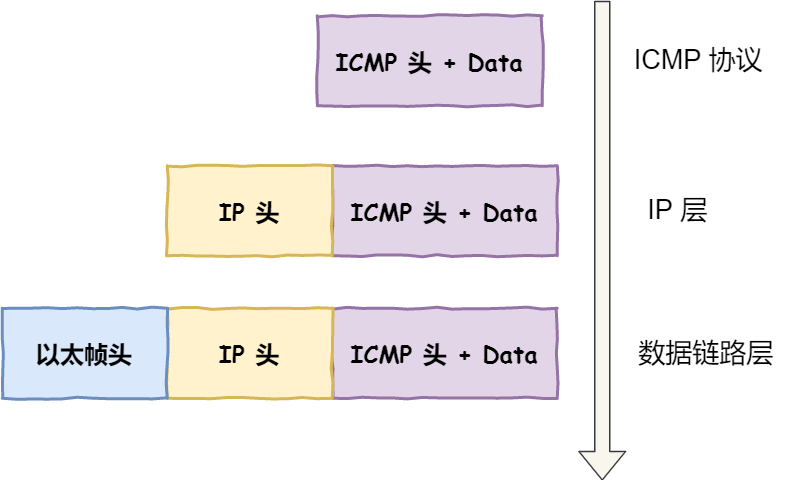
從 ping 的例子中,我們可以看到網(wǎng)絡(luò)分層就像有序的分工,每一層都有自己的責任范圍和信息,上層協(xié)議完成工作后就交給下一層,最終形成一個完整的網(wǎng)絡(luò)包。
解密 TCP 三次握手和四次揮手
既然學會了 tcpdump 和 Wireshark 兩大網(wǎng)絡(luò)分析利器,那我們快馬加鞭,接下用它倆抓取和分析 HTTP 協(xié)議網(wǎng)絡(luò)包,并理解 TCP 三次握手和四次揮手的工作原理。
本次例子,我們將要訪問的 http://192.168.3.200 服務(wù)端。在終端一用 tcpdump 命令抓取數(shù)據(jù)包:
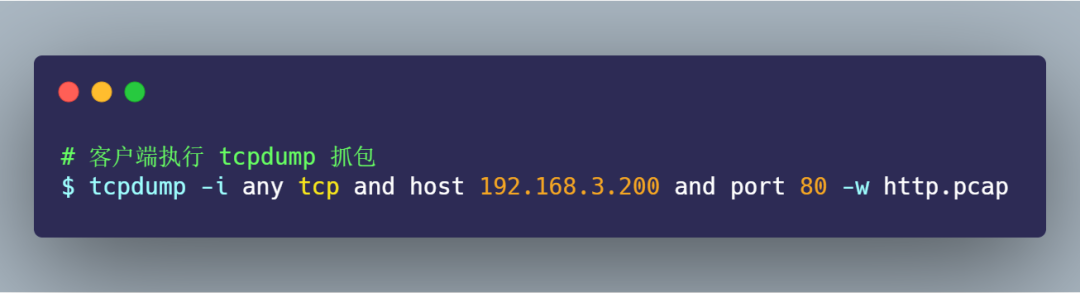
接著,在終端二執(zhí)行下面的 curl 命令:
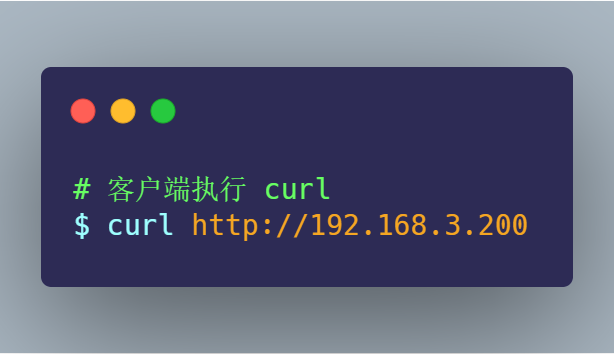
最后,回到終端一,按下 Ctrl+C 停止 tcpdump,并把得到的 http.pcap 取出到電腦。
使用 Wireshark 打開 http.pcap 后,你就可以在 Wireshark 中,看到如下的界面:
絡(luò)包")
我們都知道 HTTP 是基于 TCP 協(xié)議進行傳輸?shù)模敲矗?/p>
最開始的 3 個包就是 TCP 三次握手建立連接的包
中間是 HTTP 請求和響應(yīng)的包
而最后的 3 個包則是 TCP 斷開連接的揮手包
Wireshark 可以用時序圖的方式顯示數(shù)據(jù)包交互的過程,從菜單欄中,點擊 統(tǒng)計 (Statistics) -> 流量圖 (Flow Graph),然后,在彈出的界面中的「流量類型」選擇 「TCP Flows」,你可以更清晰的看到,整個過程中 TCP 流的執(zhí)行過程:

你可能會好奇,為什么三次握手連接過程的 Seq 是 0 ?
實際上是因為 Wireshark 工具幫我們做了優(yōu)化,它默認顯示的是序列號 seq 是相對值,而不是真實值。
如果你想看到實際的序列號的值,可以右鍵菜單, 然后找到「協(xié)議首選項」,接著找到「Relative Seq」后,把它給取消,操作如下:

取消后,Seq 顯示的就是真實值了:
可見,客戶端和服務(wù)端的序列號實際上是不同的,序列號是一個隨機值。
這其實跟我們書上看到的 TCP 三次握手和四次揮手很類似,作為對比,你通常看到的 TCP 三次握手和四次揮手的流程,基本是這樣的:

為什么抓到的 TCP 揮手是三次,而不是書上說的四次?
因為服務(wù)器端收到客戶端的 FIN 后,服務(wù)器端同時也要關(guān)閉連接,這樣就可以把 ACK 和 FIN 合并到一起發(fā)送,節(jié)省了一個包,變成了“三次揮手”。
而通常情況下,服務(wù)器端收到客戶端的 FIN 后,很可能還沒發(fā)送完數(shù)據(jù),所以就會先回復(fù)客戶端一個 ACK 包,稍等一會兒,完成所有數(shù)據(jù)包的發(fā)送后,才會發(fā)送 FIN 包,這也就是四次揮手了。
如下圖,就是四次揮手的過程:
TCP 三次握手異常情況實戰(zhàn)分析
TCP 三次握手的過程相信大家都背的滾瓜爛熟,那么你有沒有想過這三個異常情況:
TCP 第一次握手的 SYN 丟包了,會發(fā)生了什么?
TCP 第二次握手的 SYN、ACK 丟包了,會發(fā)生什么?
TCP 第三次握手的 ACK 包丟了,會發(fā)生什么?
有的小伙伴可能說:“很簡單呀,包丟了就會重傳嘛。”
那我在繼續(xù)問你:
那會重傳幾次?
超時重傳的時間 RTO 會如何變化?
在 Linux 下如何設(shè)置重傳次數(shù)?
….
是不是啞口無言,無法回答?
不知道沒關(guān)系,接下里我用三個實驗案例,帶大家一起探究探究這三種異常。
實驗場景
本次實驗用了兩臺虛擬機,一臺作為服務(wù)端,一臺作為客戶端,它們的關(guān)系如下:
境")
客戶端和服務(wù)端都是 CentOs 6.5 Linux,Linux 內(nèi)核版本 2.6.32
服務(wù)端 192.168.12.36,apache web 服務(wù)
客戶端 192.168.12.37
實驗一:TCP 第一次握手 SYN 丟包
為了模擬 TCP 第一次握手 SYN 丟包的情況,我是在拔掉服務(wù)器的網(wǎng)線后,立刻在客戶端執(zhí)行 curl 命令:
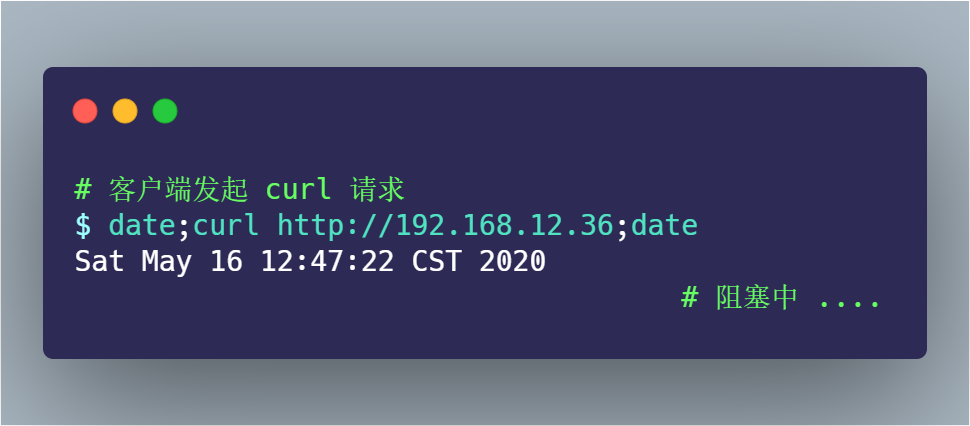
其間 tcpdump 抓包的命令如下:
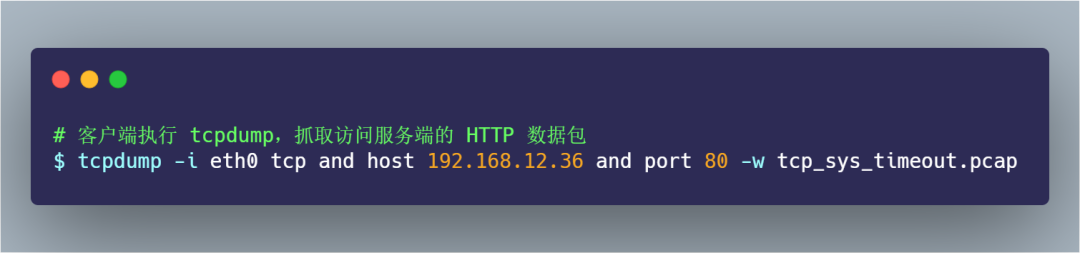
過了一會, curl 返回了超時連接的錯誤:
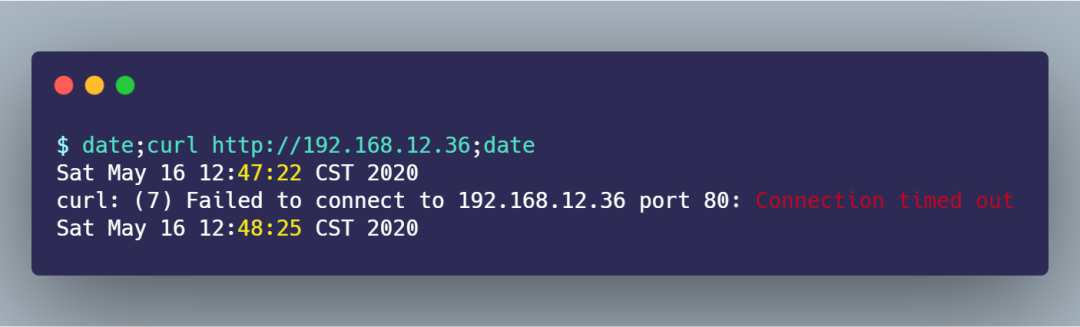
從 date 返回的時間,可以發(fā)現(xiàn)在超時接近 1 分鐘的時間后,curl 返回了錯誤。
接著,把 tcp_sys_timeout.pcap 文件用 Wireshark 打開分析,顯示如下圖:

從上圖可以發(fā)現(xiàn), 客戶端發(fā)起了 SYN 包后,一直沒有收到服務(wù)端的 ACK ,所以一直超時重傳了 5 次,并且每次 RTO 超時時間是不同的:
第一次是在 1 秒超時重傳
第二次是在 3 秒超時重傳
第三次是在 7 秒超時重傳
第四次是在 15 秒超時重傳
第五次是在 31 秒超時重傳
可以發(fā)現(xiàn),每次超時時間 RTO 是指數(shù)(翻倍)上漲的,當超過最大重傳次數(shù)后,客戶端不再發(fā)送 SYN 包。
在 Linux 中,第一次握手的 SYN 超時重傳次數(shù),是如下內(nèi)核參數(shù)指定的:
$ cat /proc/sys/net/ipv4/tcp_syn_retries
5
tcp_syn_retries 默認值為 5,也就是 SYN 最大重傳次數(shù)是 5 次。
接下來,我們繼續(xù)做實驗,把 tcp_syn_retries 設(shè)置為 2 次:
$ echo 2 > /proc/sys/net/ipv4/tcp_syn_retries
重傳抓包后,用 Wireshark 打開分析,顯示如下圖:

實驗一的實驗小結(jié)
通過實驗一的實驗結(jié)果,我們可以得知,當客戶端發(fā)起的 TCP 第一次握手 SYN 包,在超時時間內(nèi)沒收到服務(wù)端的 ACK,就會在超時重傳 SYN 數(shù)據(jù)包,每次超時重傳的 RTO 是翻倍上漲的,直到 SYN 包的重傳次數(shù)到達 tcp_syn_retries 值后,客戶端不再發(fā)送 SYN 包。

實驗二:TCP 第二次握手 SYN、ACK 丟包
為了模擬客戶端收不到服務(wù)端第二次握手 SYN、ACK 包,我的做法是在客戶端加上防火墻限制,直接粗暴的把來自服務(wù)端的數(shù)據(jù)都丟棄,防火墻的配置如下:

接著,在客戶端執(zhí)行 curl 命令:
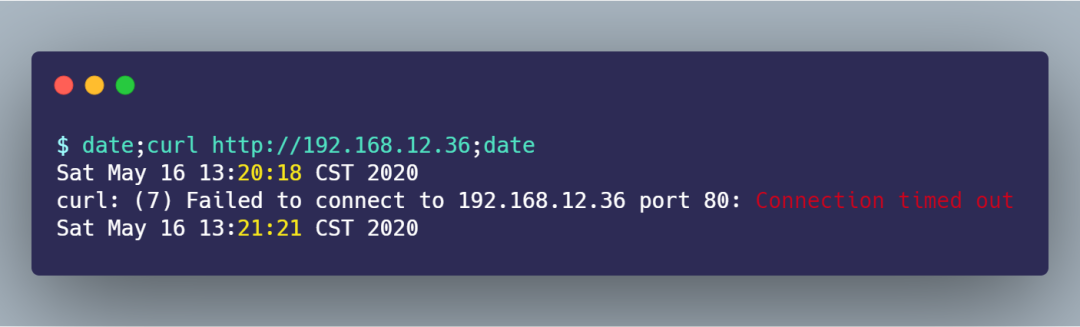
從 date 返回的時間前后,可以算出大概 1 分鐘后,curl 報錯退出了。
客戶端在這其間抓取的數(shù)據(jù)包,用 Wireshark 打開分析,顯示的時序圖如下:
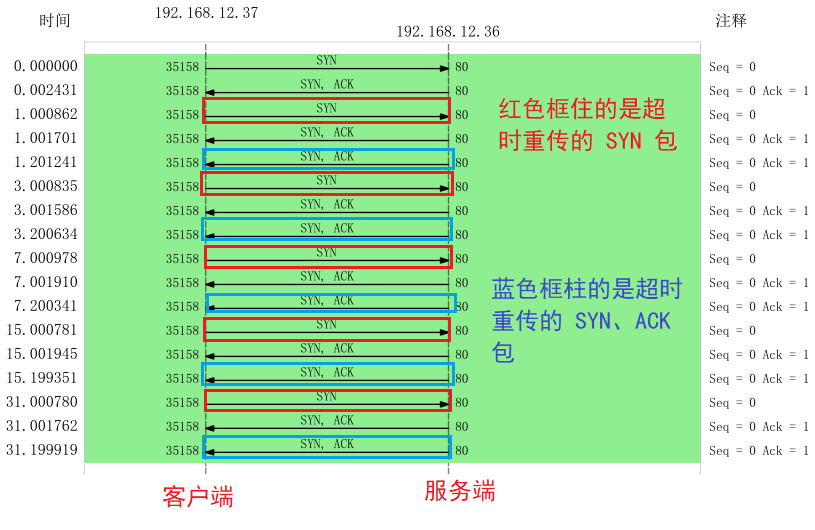
從圖中可以發(fā)現(xiàn):
客戶端發(fā)起 SYN 后,由于防火墻屏蔽了服務(wù)端的所有數(shù)據(jù)包,所以 curl 是無法收到服務(wù)端的 SYN、ACK 包,當發(fā)生超時后,就會重傳 SYN 包
服務(wù)端收到客戶的 SYN 包后,就會回 SYN、ACK 包,但是客戶端一直沒有回 ACK,服務(wù)端在超時后,重傳了 SYN、ACK 包,接著一會,客戶端超時重傳的 SYN 包又抵達了服務(wù)端,服務(wù)端收到后,超時定時器就重新計時,然后回了 SYN、ACK 包,所以相當于服務(wù)端的超時定時器只觸發(fā)了一次,又被重置了。
最后,客戶端 SYN 超時重傳次數(shù)達到了 5 次(tcp_syn_retries 默認值 5 次),就不再繼續(xù)發(fā)送 SYN 包了。
所以,我們可以發(fā)現(xiàn),當?shù)诙挝帐值?SYN、ACK 丟包時,客戶端會超時重發(fā) SYN 包,服務(wù)端也會超時重傳 SYN、ACK 包。
咦?客戶端設(shè)置了防火墻,屏蔽了服務(wù)端的網(wǎng)絡(luò)包,為什么 tcpdump 還能抓到服務(wù)端的網(wǎng)絡(luò)包?
添加 iptables 限制后, tcpdump 是否能抓到包 ,這要看添加的 iptables 限制條件:
如果添加的是
INPUT規(guī)則,則可以抓得到包如果添加的是
OUTPUT規(guī)則,則抓不到包
網(wǎng)絡(luò)包進入主機后的順序如下:
進來的順序 Wire -> NIC -> tcpdump -> netfilter/iptables
出去的順序 iptables -> tcpdump -> NIC -> Wire
tcp_syn_retries 是限制 SYN 重傳次數(shù),那第二次握手 SYN、ACK 限制最大重傳次數(shù)是多少?
TCP 第二次握手 SYN、ACK 包的最大重傳次數(shù)是通過 tcp_synack_retries 內(nèi)核參數(shù)限制的,其默認值如下:
$ cat /proc/sys/net/ipv4/tcp_synack_retries
5
是的,TCP 第二次握手 SYN、ACK 包的最大重傳次數(shù)默認值是 5 次。
為了驗證 SYN、ACK 包最大重傳次數(shù)是 5 次,我們繼續(xù)做下實驗,我們先把客戶端的 tcp_syn_retries 設(shè)置為 1,表示客戶端 SYN 最大超時次數(shù)是 1 次,目的是為了防止多次重傳 SYN,把服務(wù)端 SYN、ACK 超時定時器重置。
接著,還是如上面的步驟:
客戶端配置防火墻屏蔽服務(wù)端的數(shù)據(jù)包
客戶端 tcpdump 抓取 curl 執(zhí)行時的數(shù)據(jù)包
把抓取的數(shù)據(jù)包,用 Wireshark 打開分析,顯示的時序圖如下:

從上圖,我們可以分析出:
客戶端的 SYN 只超時重傳了 1 次,因為
tcp_syn_retries值為 1服務(wù)端應(yīng)答了客戶端超時重傳的 SYN 包后,由于一直收不到客戶端的 ACK 包,所以服務(wù)端一直在超時重傳 SYN、ACK 包,每次的 RTO 也是指數(shù)上漲的,一共超時重傳了 5 次,因為
tcp_synack_retries值為 5
接著,我把 tcp_synack_retries 設(shè)置為 2,tcp_syn_retries 依然設(shè)置為 1:
$ echo 2 > /proc/sys/net/ipv4/tcp_synack_retries
$ echo 1 > /proc/sys/net/ipv4/tcp_syn_retries
依然保持一樣的實驗步驟進行操作,接著把抓取的數(shù)據(jù)包,用 Wireshark 打開分析,顯示的時序圖如下:
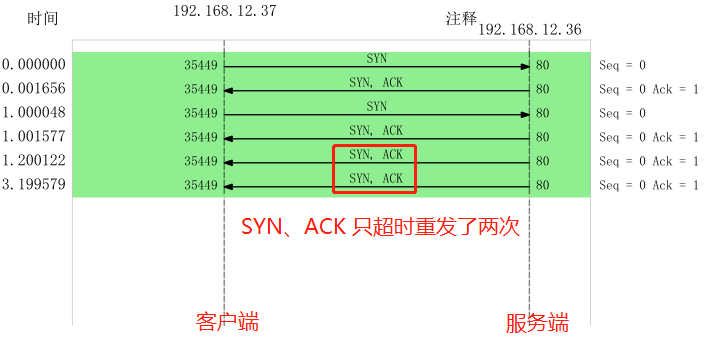
可見:
客戶端的 SYN 包只超時重傳了 1 次,符合 tcp_syn_retries 設(shè)置的值;
服務(wù)端的 SYN、ACK 超時重傳了 2 次,符合 tcp_synack_retries 設(shè)置的值
實驗二的實驗小結(jié)
通過實驗二的實驗結(jié)果,我們可以得知,當 TCP 第二次握手 SYN、ACK 包丟了后,客戶端 SYN 包會發(fā)生超時重傳,服務(wù)端 SYN、ACK 也會發(fā)生超時重傳。
客戶端 SYN 包超時重傳的最大次數(shù),是由 tcp_syn_retries 決定的,默認值是 5 次;服務(wù)端 SYN、ACK 包時重傳的最大次數(shù),是由 tcp_synack_retries 決定的,默認值是 5 次。
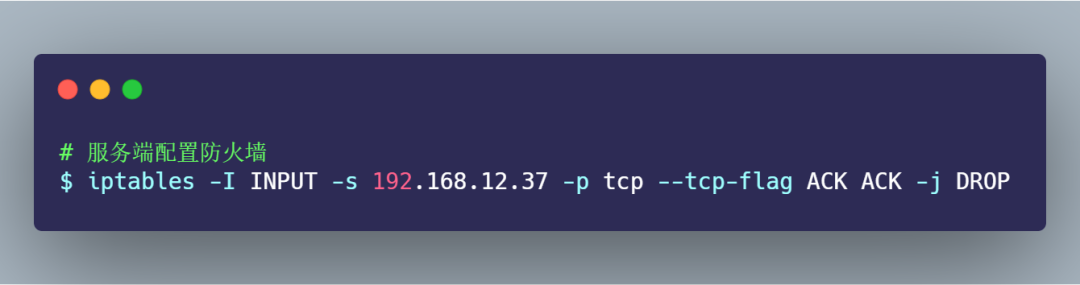
實驗三:TCP 第三次握手 ACK 丟包
為了模擬 TCP 第三次握手 ACK 包丟,我的實驗方法是在服務(wù)端配置防火墻,屏蔽客戶端 TCP 報文中標志位是 ACK 的包,也就是當服務(wù)端收到客戶端的 TCP ACK 的報文時就會丟棄,iptables 配置命令如下:
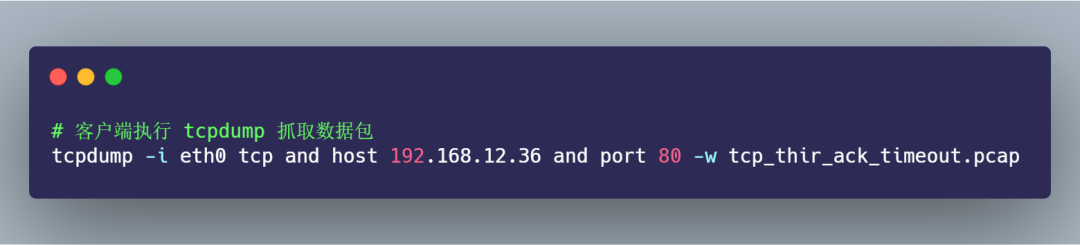
接著,在客戶端執(zhí)行如下 tcpdump 命令:
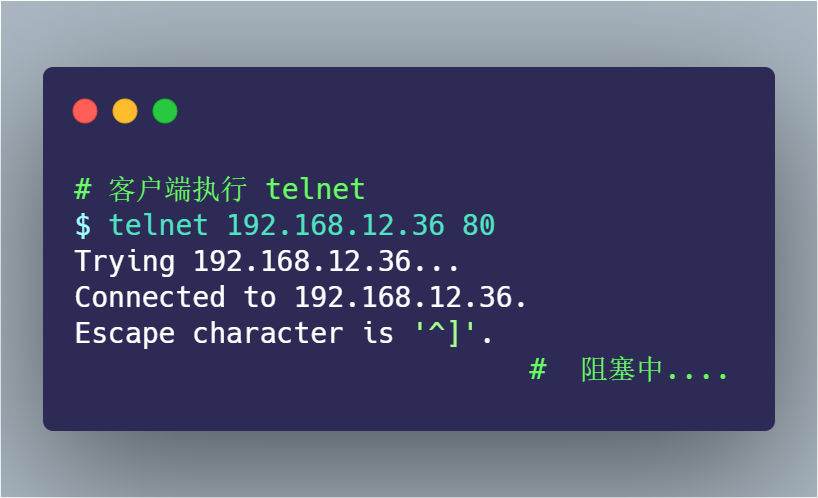
然后,客戶端向服務(wù)端發(fā)起 telnet,因為 telnet 命令是會發(fā)起 TCP 連接,所以用此命令做測試:
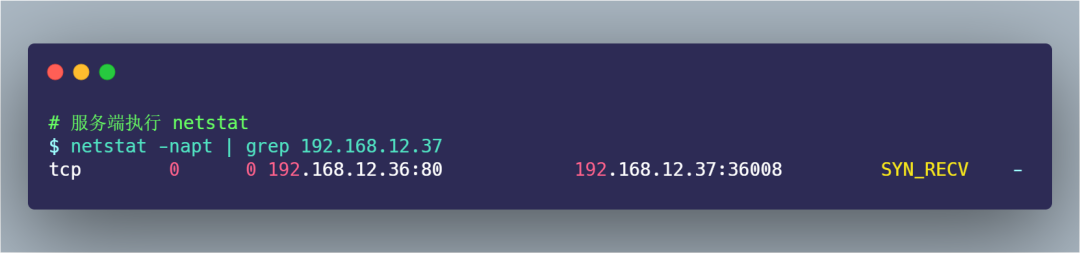
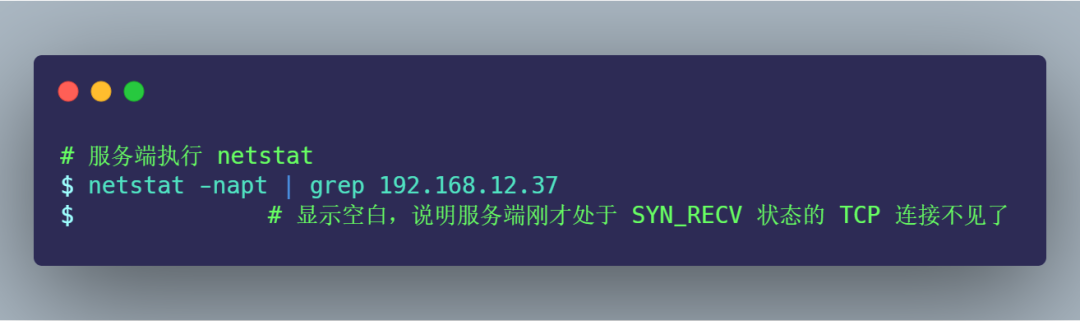
此時,由于服務(wù)端收不到第三次握手的 ACK 包,所以一直處于 SYN_RECV 狀態(tài):
而客戶端是已完成 TCP 連接建立,處于 ESTABLISHED 狀態(tài):
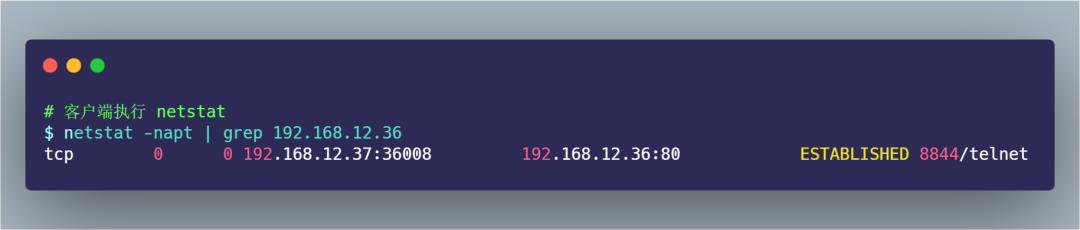
過了 1 分鐘后,觀察發(fā)現(xiàn)服務(wù)端的 TCP 連接不見了:
過了 30 分別,客戶端依然還是處于 ESTABLISHED 狀態(tài):
接著,在剛才客戶端建立的 telnet 會話,輸入 123456 字符,進行發(fā)送:
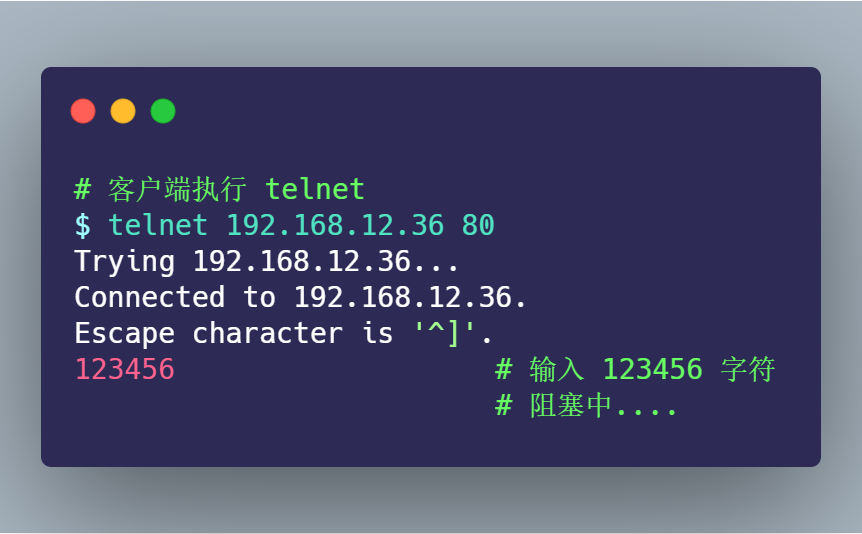
持續(xù)「好長」一段時間,客戶端的 telnet 才斷開連接:
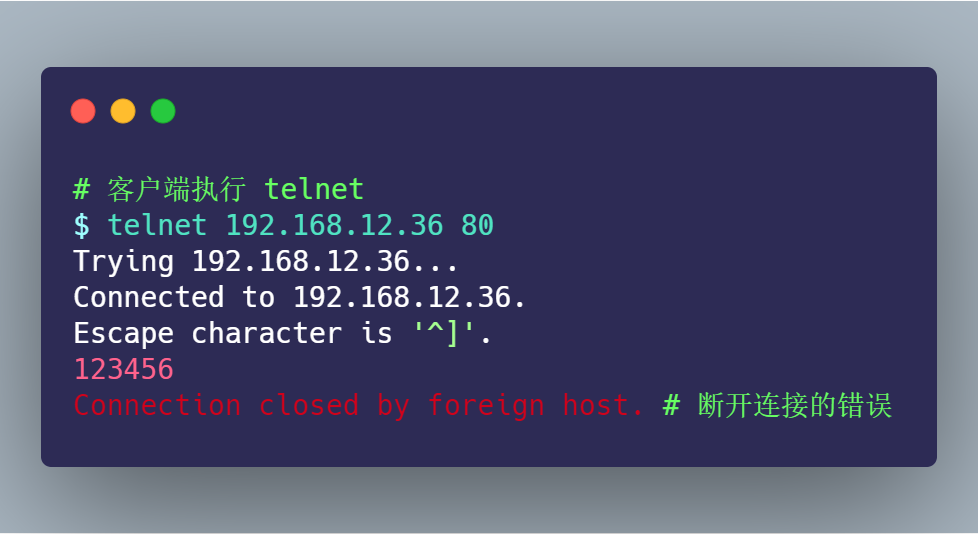
以上就是本次的實現(xiàn)三的現(xiàn)象,這里存在兩個疑點:
為什么服務(wù)端原本處于
SYN_RECV狀態(tài)的連接,過 1 分鐘后就消失了?為什么客戶端 telnet 輸入 123456 字符后,過了好長一段時間,telnet 才斷開連接?
不著急,我們把剛抓的數(shù)據(jù)包,用 Wireshark 打開分析,顯示的時序圖如下:

上圖的流程:
客戶端發(fā)送 SYN 包給服務(wù)端,服務(wù)端收到后,回了個 SYN、ACK 包給客戶端,此時服務(wù)端的 TCP 連接處于
SYN_RECV狀態(tài);客戶端收到服務(wù)端的 SYN、ACK 包后,給服務(wù)端回了個 ACK 包,此時客戶端的 TCP 連接處于
ESTABLISHED狀態(tài);由于服務(wù)端配置了防火墻,屏蔽了客戶端的 ACK 包,所以服務(wù)端一直處于
SYN_RECV狀態(tài),沒有進入ESTABLISHED狀態(tài),tcpdump 之所以能抓到客戶端的 ACK 包,是因為數(shù)據(jù)包進入系統(tǒng)的順序是先進入 tcpudmp,后經(jīng)過 iptables;接著,服務(wù)端超時重傳了 SYN、ACK 包,重傳了 5 次后,也就是超過 tcp_synack_retries 的值(默認值是 5),然后就沒有繼續(xù)重傳了,此時服務(wù)端的 TCP 連接主動中止了,所以剛才處于 SYN_RECV 狀態(tài)的 TCP 連接斷開了,而客戶端依然處于
ESTABLISHED狀態(tài);雖然服務(wù)端 TCP 斷開了,但過了一段時間,發(fā)現(xiàn)客戶端依然處于
ESTABLISHED狀態(tài),于是就在客戶端的 telnet 會話輸入了 123456 字符;此時由于服務(wù)端已經(jīng)斷開連接,客戶端發(fā)送的數(shù)據(jù)報文,一直在超時重傳,每一次重傳,RTO 的值是指數(shù)增長的,所以持續(xù)了好長一段時間,客戶端的 telnet 才報錯退出了,此時共重傳了 15 次。
通過這一波分析,剛才的兩個疑點已經(jīng)解除了:
服務(wù)端在重傳 SYN、ACK 包時,超過了最大重傳次數(shù)
tcp_synack_retries,于是服務(wù)端的 TCP 連接主動斷開了。客戶端向服務(wù)端發(fā)送數(shù)據(jù)包時,由于服務(wù)端的 TCP 連接已經(jīng)退出了,所以數(shù)據(jù)包一直在超時重傳,共重傳了 15 次, telnet 就 斷開了連接。
TCP 第一次握手的 SYN 包超時重傳最大次數(shù)是由 tcp_syn_retries 指定,TCP 第二次握手的 SYN、ACK 包超時重傳最大次數(shù)是由 tcp_synack_retries 指定,那 TCP 建立連接后的數(shù)據(jù)包最大超時重傳次數(shù)是由什么參數(shù)指定呢?
TCP 建立連接后的數(shù)據(jù)包傳輸,最大超時重傳次數(shù)是由 tcp_retries2 指定,默認值是 15 次,如下:
$ cat /proc/sys/net/ipv4/tcp_retries2
15
如果 15 次重傳都做完了,TCP 就會告訴應(yīng)用層說:“搞不定了,包怎么都傳不過去!”
那如果客戶端不發(fā)送數(shù)據(jù),什么時候才會斷開處于 ESTABLISHED 狀態(tài)的連接?
這里就需要提到 TCP 的 保活機制。這個機制的原理是這樣的:
定義一個時間段,在這個時間段內(nèi),如果沒有任何連接相關(guān)的活動,TCP 保活機制會開始作用,每隔一個時間間隔,發(fā)送一個「探測報文」,該探測報文包含的數(shù)據(jù)非常少,如果連續(xù)幾個探測報文都沒有得到響應(yīng),則認為當前的 TCP 連接已經(jīng)死亡,系統(tǒng)內(nèi)核將錯誤信息通知給上層應(yīng)用程序。
在 Linux 內(nèi)核可以有對應(yīng)的參數(shù)可以設(shè)置保活時間、保活探測的次數(shù)、保活探測的時間間隔,以下都為默認值:
net.ipv4.tcp_keepalive_time=7200
net.ipv4.tcp_keepalive_intvl=75
net.ipv4.tcp_keepalive_probes=9
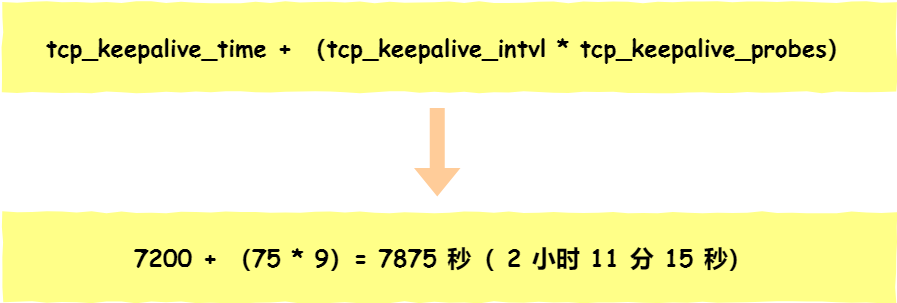
tcp_keepalive_time=7200:表示保活時間是 7200 秒(2小時),也就 2 小時內(nèi)如果沒有任何連接相關(guān)的活動,則會啟動保活機制
tcp_keepalive_intvl=75:表示每次檢測間隔 75 秒;
tcp_keepalive_probes=9:表示檢測 9 次無響應(yīng),認為對方是不可達的,從而中斷本次的連接。
也就是說在 Linux 系統(tǒng)中,最少需要經(jīng)過 2 小時 11 分 15 秒才可以發(fā)現(xiàn)一個「死亡」連接。
這個時間是有點長的,所以如果我抓包足夠久,或許能抓到探測報文。
實驗三的實驗小結(jié)
在建立 TCP 連接時,如果第三次握手的 ACK,服務(wù)端無法收到,則服務(wù)端就會短暫處于 SYN_RECV 狀態(tài),而客戶端會處于 ESTABLISHED 狀態(tài)。
由于服務(wù)端一直收不到 TCP 第三次握手的 ACK,則會一直重傳 SYN、ACK 包,直到重傳次數(shù)超過 tcp_synack_retries 值(默認值 5 次)后,服務(wù)端就會斷開 TCP 連接。
而客戶端則會有兩種情況:
如果客戶端沒發(fā)送數(shù)據(jù)包,一直處于
ESTABLISHED狀態(tài),然后經(jīng)過 2 小時 11 分 15 秒才可以發(fā)現(xiàn)一個「死亡」連接,于是客戶端連接就會斷開連接。如果客戶端發(fā)送了數(shù)據(jù)包,一直沒有收到服務(wù)端對該數(shù)據(jù)包的確認報文,則會一直重傳該數(shù)據(jù)包,直到重傳次數(shù)超過
tcp_retries2值(默認值 15 次)后,客戶端就會斷開 TCP 連接。
TCP 快速建立連接
客戶端在向服務(wù)端發(fā)起 HTTP GET 請求時,一個完整的交互過程,需要 2.5 個 RTT 的時延。
由于第三次握手是可以攜帶數(shù)據(jù)的,這時如果在第三次握手發(fā)起 HTTP GET 請求,需要 2 個 RTT 的時延。
但是在下一次(不是同個 TCP 連接的下一次)發(fā)起 HTTP GET 請求時,經(jīng)歷的 RTT 也是一樣,如下圖:
 HTTP 請求")
在 Linux 3.7 內(nèi)核版本中,提供了 TCP Fast Open 功能,這個功能可以減少 TCP 連接建立的時延。
 HTTP 請求 與 Fast Open HTTP 請求")
在第一次建立連接的時候,服務(wù)端在第二次握手產(chǎn)生一個
Cookie(已加密)并通過 SYN、ACK 包一起發(fā)給客戶端,于是客戶端就會緩存這個Cookie,所以第一次發(fā)起 HTTP Get 請求的時候,還是需要 2 個 RTT 的時延;在下次請求的時候,客戶端在 SYN 包帶上
Cookie發(fā)給服務(wù)端,就提前可以跳過三次握手的過程,因為Cookie中維護了一些信息,服務(wù)端可以從Cookie獲取 TCP 相關(guān)的信息,這時發(fā)起的 HTTP GET 請求就只需要 1 個 RTT 的時延;
注:客戶端在請求并存儲了 Fast Open Cookie 之后,可以不斷重復(fù) TCP Fast Open 直至服務(wù)器認為 Cookie 無效(通常為過期)
在 Linux 上如何打開 Fast Open 功能?
可以通過設(shè)置 net.ipv4.tcp_fastopn 內(nèi)核參數(shù),來打開 Fast Open 功能。
net.ipv4.tcp_fastopn 各個值的意義:
0 關(guān)閉
1 作為客戶端使用 Fast Open 功能
2 作為服務(wù)端使用 Fast Open 功能
3 無論作為客戶端還是服務(wù)器,都可以使用 Fast Open 功能
TCP Fast Open 抓包分析
在下圖,數(shù)據(jù)包 7 號,客戶端發(fā)起了第二次 TCP 連接時,SYN 包會攜帶 Cooike,并且有長度為 5 的數(shù)據(jù)。
服務(wù)端收到后,校驗 Cooike 合法,于是就回了 SYN、ACK 包,并且確認應(yīng)答收到了客戶端的數(shù)據(jù)包,ACK = 5 + 1 = 6

TCP 重復(fù)確認和快速重傳
當接收方收到亂序數(shù)據(jù)包時,會發(fā)送重復(fù)的 ACK,以使告知發(fā)送方要重發(fā)該數(shù)據(jù)包,當發(fā)送方收到 3 個重復(fù) ACK 時,就會觸發(fā)快速重傳,立該重發(fā)丟失數(shù)據(jù)包。

TCP 重復(fù)確認和快速重傳的一個案例,用 Wireshark 分析,顯示如下:
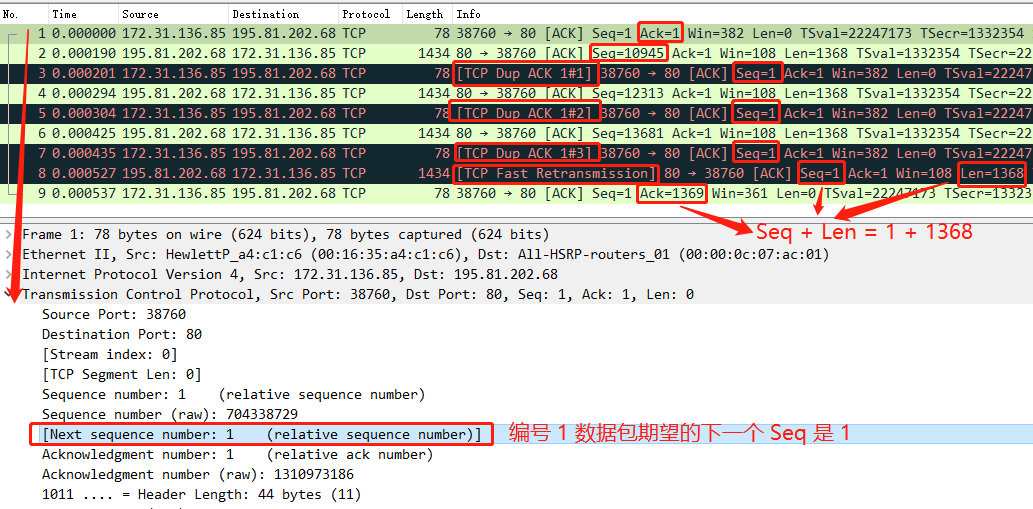
數(shù)據(jù)包 1 期望的下一個數(shù)據(jù)包 Seq 是 1,但是數(shù)據(jù)包 2 發(fā)送的 Seq 卻是 10945,說明收到的是亂序數(shù)據(jù)包,于是回了數(shù)據(jù)包 3 ,還是同樣的 Seq = 1,Ack = 1,這表明是重復(fù)的 ACK;
數(shù)據(jù)包 4 和 6 依然是亂序的數(shù)據(jù)包,于是依然回了重復(fù)的 ACK;
當對方收到三次重復(fù)的 ACK 后,于是就快速重傳了 Seq = 1 、Len = 1368 的數(shù)據(jù)包 8;
當收到重傳的數(shù)據(jù)包后,發(fā)現(xiàn) Seq = 1 是期望的數(shù)據(jù)包,于是就發(fā)送了確認報文 ACK;
注意:快速重傳和重復(fù) ACK 標記信息是 Wireshark 的功能,非數(shù)據(jù)包本身的信息。
以上案例在 TCP 三次握手時協(xié)商開啟了選擇性確認 SACK,因此一旦數(shù)據(jù)包丟失并收到重復(fù) ACK ,即使在丟失數(shù)據(jù)包之后還成功接收了其他數(shù)據(jù)包,也只需要重傳丟失的數(shù)據(jù)包。如果不啟用 SACK,就必須重傳丟失包之后的每個數(shù)據(jù)包。
如果要支持 SACK,必須雙方都要支持。在 Linux 下,可以通過 net.ipv4.tcp_sack 參數(shù)打開這個功能(Linux 2.4 后默認打開)。
TCP 流量控制
TCP 為了防止發(fā)送方無腦的發(fā)送數(shù)據(jù),導致接收方緩沖區(qū)被填滿,所以就有了滑動窗口的機制,它可利用接收方的接收窗口來控制發(fā)送方要發(fā)送的數(shù)據(jù)量,也就是流量控制。
接收窗口是由接收方指定的值,存儲在 TCP 頭部中,它可以告訴發(fā)送方自己的 TCP 緩沖空間區(qū)大小,這個緩沖區(qū)是給應(yīng)用程序讀取數(shù)據(jù)的空間:
如果應(yīng)用程序讀取了緩沖區(qū)的數(shù)據(jù),那么緩沖空間區(qū)的就會把被讀取的數(shù)據(jù)移除
如果應(yīng)用程序沒有讀取數(shù)據(jù),則數(shù)據(jù)會一直滯留在緩沖區(qū)。
接收窗口的大小,是在 TCP 三次握手中協(xié)商好的,后續(xù)數(shù)據(jù)傳輸時,接收方發(fā)送確認應(yīng)答 ACK 報文時,會攜帶當前的接收窗口的大小,以此來告知發(fā)送方。
假設(shè)接收方接收到數(shù)據(jù)后,應(yīng)用層能很快的從緩沖區(qū)里讀取數(shù)據(jù),那么窗口大小會一直保持不變,過程如下:
下的窗口變化")
但是現(xiàn)實中服務(wù)器會出現(xiàn)繁忙的情況,當應(yīng)用程序讀取速度慢,那么緩存空間會慢慢被占滿,于是為了保證發(fā)送方發(fā)送的數(shù)據(jù)不會超過緩沖區(qū)大小,則服務(wù)器會調(diào)整窗口大小的值,接著通過 ACK 報文通知給對方,告知現(xiàn)在的接收窗口大小,從而控制發(fā)送方發(fā)送的數(shù)據(jù)大小。
端繁忙狀態(tài)下的窗口變化")
零窗口通知與窗口探測
假設(shè)接收方處理數(shù)據(jù)的速度跟不上接收數(shù)據(jù)的速度,緩存就會被占滿,從而導致接收窗口為 0,當發(fā)送方接收到零窗口通知時,就會停止發(fā)送數(shù)據(jù)。
如下圖,可以接收方的窗口大小在不斷的收縮至 0:

接著,發(fā)送方會定時發(fā)送窗口大小探測報文,以便及時知道接收方窗口大小的變化。
以下圖 Wireshark 分析圖作為例子說明:

發(fā)送方發(fā)送了數(shù)據(jù)包 1 給接收方,接收方收到后,由于緩沖區(qū)被占滿,回了個零窗口通知;
發(fā)送方收到零窗口通知后,就不再發(fā)送數(shù)據(jù)了,直到過了
3.4秒后,發(fā)送了一個 TCP Keep-Alive 報文,也就是窗口大小探測報文;當接收方收到窗口探測報文后,就立馬回一個窗口通知,但是窗口大小還是 0;
發(fā)送方發(fā)現(xiàn)窗口還是 0,于是繼續(xù)等待了
6.8(翻倍) 秒后,又發(fā)送了窗口探測報文,接收方依然還是回了窗口為 0 的通知;發(fā)送方發(fā)現(xiàn)窗口還是 0,于是繼續(xù)等待了
13.5(翻倍) 秒后,又發(fā)送了窗口探測報文,接收方依然還是回了窗口為 0 的通知;
可以發(fā)現(xiàn),這些窗口探測報文以 3.4s、6.5s、13.5s 的間隔出現(xiàn),說明超時時間會翻倍遞增。
這連接暫停了 25s,想象一下你在打王者的時候,25s 的延遲你還能上王者嗎?
發(fā)送窗口的分析
在 Wireshark 看到的 Windows size 也就是 " win = ",這個值表示發(fā)送窗口嗎?
這不是發(fā)送窗口,而是在向?qū)Ψ铰暶髯约旱慕邮沾翱凇?/p>
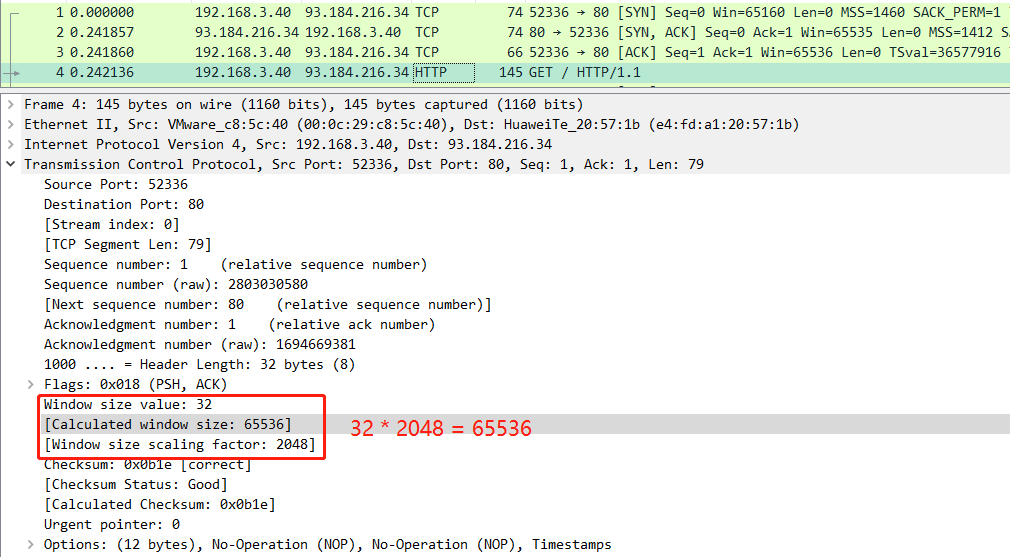
你可能會好奇,抓包文件里有「Window size scaling factor」,它其實是算出實際窗口大小的乘法因子,「Windos size value」實際上并不是真實的窗口大小,真實窗口大小的計算公式如下:
「Windos size value」 * 「Window size scaling factor」 = 「Caculated window size 」
對應(yīng)的下圖案例,也就是 32 * 2048 = 65536。
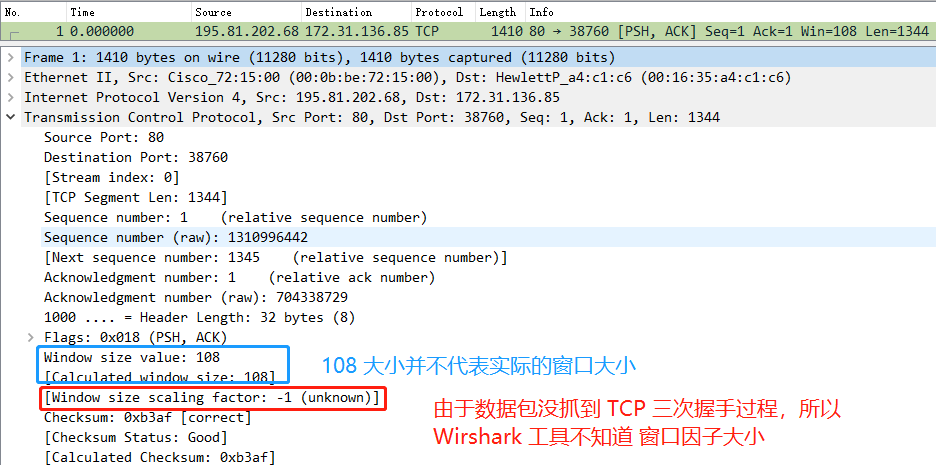
實際上是 Caculated window size 的值是 Wireshark 工具幫我們算好的,Window size scaling factor 和 Windos size value 的值是在 TCP 頭部中,其中 Window size scaling factor 是在三次握手過程中確定的,如果你抓包的數(shù)據(jù)沒有 TCP 三次握手,那可能就無法算出真實的窗口大小的值,如下圖:
如何在包里看出發(fā)送窗口的大小?
很遺憾,沒有簡單的辦法,發(fā)送窗口雖然是由接收窗口決定,但是它又可以被網(wǎng)絡(luò)因素影響,也就是擁塞窗口,實際上發(fā)送窗口是值是 min(擁塞窗口,接收窗口)。
發(fā)送窗口和 MSS 有什么關(guān)系?
發(fā)送窗口決定了一口氣能發(fā)多少字節(jié),而 MSS 決定了這些字節(jié)要分多少包才能發(fā)完。
舉個例子,如果發(fā)送窗口為 16000 字節(jié)的情況下,如果 MSS 是 1000 字節(jié),那就需要發(fā)送 1600/1000 = 16 個包。
發(fā)送方在一個窗口發(fā)出 n 個包,是不是需要 n 個 ACK 確認報文?
不一定,因為 TCP 有累計確認機制,所以當收到多個數(shù)據(jù)包時,只需要應(yīng)答最后一個數(shù)據(jù)包的 ACK 報文就可以了。
TCP 延遲確認與 Nagle 算法
當我們 TCP 報文的承載的數(shù)據(jù)非常小的時候,例如幾個字節(jié),那么整個網(wǎng)絡(luò)的效率是很低的,因為每個 TCP 報文中都有會 20 個字節(jié)的 TCP 頭部,也會有 20 個字節(jié)的 IP 頭部,而數(shù)據(jù)只有幾個字節(jié),所以在整個報文中有效數(shù)據(jù)占有的比重就會非常低。
這就好像快遞員開著大貨車送一個小包裹一樣浪費。
那么就出現(xiàn)了常見的兩種策略,來減少小報文的傳輸,分別是:
Nagle 算法
延遲確認
Nagle 算法是如何避免大量 TCP 小數(shù)據(jù)報文的傳輸?
Nagle 算法做了一些策略來避免過多的小數(shù)據(jù)報文發(fā)送,這可提高傳輸效率。
Nagle 算法的策略:
沒有已發(fā)送未確認報文時,立刻發(fā)送數(shù)據(jù)。
存在未確認報文時,直到「沒有已發(fā)送未確認報文」或「數(shù)據(jù)長度達到 MSS 大小」時,再發(fā)送數(shù)據(jù)。
只要沒滿足上面條件中的一條,發(fā)送方一直在囤積數(shù)據(jù),直到滿足上面的發(fā)送條件。

上圖右側(cè)啟用了 Nagle 算法,它的發(fā)送數(shù)據(jù)的過程:
一開始由于沒有已發(fā)送未確認的報文,所以就立刻發(fā)了 H 字符;
接著,在還沒收到對 H 字符的確認報文時,發(fā)送方就一直在囤積數(shù)據(jù),直到收到了確認報文后,此時就沒有已發(fā)送未確認的報文,于是就把囤積后的 ELL 字符一起發(fā)給了接收方;
待收到對 ELL 字符的確認報文后,于是把最后一個 O 字符發(fā)送出去
可以看出,Nagle 算法一定會有一個小報文,也就是在最開始的時候。
另外,Nagle 算法默認是打開的,如果對于一些需要小數(shù)據(jù)包交互的場景的程序,比如,telnet 或 ssh 這樣的交互性比較強的程序,則需要關(guān)閉 Nagle 算法。
可以在 Socket 設(shè)置 TCP_NODELAY 選項來關(guān)閉這個算法(關(guān)閉 Nagle 算法沒有全局參數(shù),需要根據(jù)每個應(yīng)用自己的特點來關(guān)閉)。
閉 Nagle 算法")
那延遲確認又是什么?
事實上當沒有攜帶數(shù)據(jù)的 ACK,他的網(wǎng)絡(luò)效率也是很低的,因為它也有 40 個字節(jié)的 IP 頭 和 TCP 頭,但沒有攜帶數(shù)據(jù)。
為了解決 ACK 傳輸效率低問題,所以就衍生出了 TCP 延遲確認。
TCP 延遲確認的策略:
當有響應(yīng)數(shù)據(jù)要發(fā)送時,ACK 會隨著響應(yīng)數(shù)據(jù)一起立刻發(fā)送給對方
當沒有響應(yīng)數(shù)據(jù)要發(fā)送時,ACK 將會延遲一段時間,以等待是否有響應(yīng)數(shù)據(jù)可以一起發(fā)送
如果在延遲等待發(fā)送 ACK 期間,對方的第二個數(shù)據(jù)報文又到達了,這時就會立刻發(fā)送 ACK

延遲等待的時間是在 Linux 內(nèi)核中的定義的,如下圖:
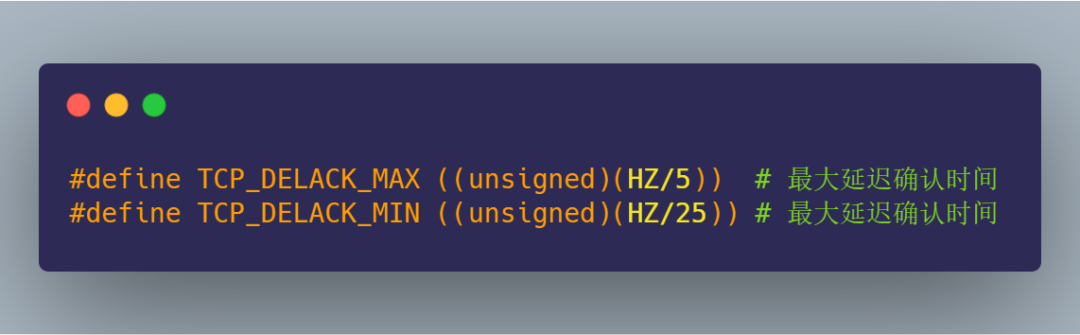
關(guān)鍵就需要 HZ 這個數(shù)值大小,HZ 是跟系統(tǒng)的時鐘頻率有關(guān),每個操作系統(tǒng)都不一樣,在我的 Linux 系統(tǒng)中 HZ 大小是 1000,如下圖:
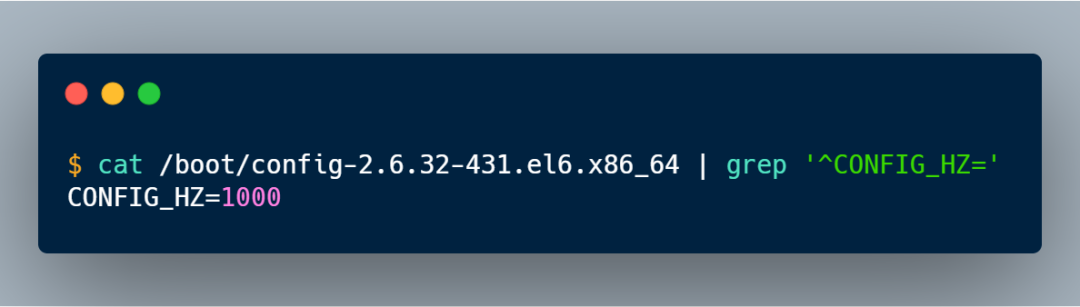
知道了 HZ 的大小,那么就可以算出:
最大延遲確認時間是
200ms (1000/5)最短延遲確認時間是
40ms (1000/25)
TCP 延遲確認可以在 Socket 設(shè)置 TCP_QUICKACK 選項來關(guān)閉這個算法。
閉 TCP 延遲確認")
延遲確認 和 Nagle 算法混合使用時,會產(chǎn)生新的問題
當 TCP 延遲確認 和 Nagle 算法混合使用時,會導致時耗增長,如下圖:

發(fā)送方使用了 Nagle 算法,接收方使用了 TCP 延遲確認會發(fā)生如下的過程:
發(fā)送方先發(fā)出一個小報文,接收方收到后,由于延遲確認機制,自己又沒有要發(fā)送的數(shù)據(jù),只能干等著發(fā)送方的下一個報文到達;
而發(fā)送方由于 Nagle 算法機制,在未收到第一個報文的確認前,是不會發(fā)送后續(xù)的數(shù)據(jù);
所以接收方只能等待最大時間 200 ms 后,才回 ACK 報文,發(fā)送方收到第一個報文的確認報文后,也才可以發(fā)送后續(xù)的數(shù)據(jù)。
很明顯,這兩個同時使用會造成額外的時延,這就會使得網(wǎng)絡(luò)"很慢"的感覺。
要解決這個問題,只有兩個辦法:
要么發(fā)送方關(guān)閉 Nagle 算法
要么接收方關(guān)閉 TCP 延遲確認
巨人的肩膀
[1] Wireshark網(wǎng)絡(luò)分析的藝術(shù).林沛滿.人民郵電出版社.
[2] Wireshark網(wǎng)絡(luò)分析就這么簡單.林沛滿.人民郵電出版社.
[3] Wireshark數(shù)據(jù)包分析實戰(zhàn).Chris Sanders .人民郵電出版社
推薦閱讀:
完全整理 | 365篇高質(zhì)技術(shù)文章目錄整理
專注服務(wù)器后臺技術(shù)棧知識總結(jié)分享
歡迎關(guān)注交流共同進步