
圖解 Kafka 中的基本概念
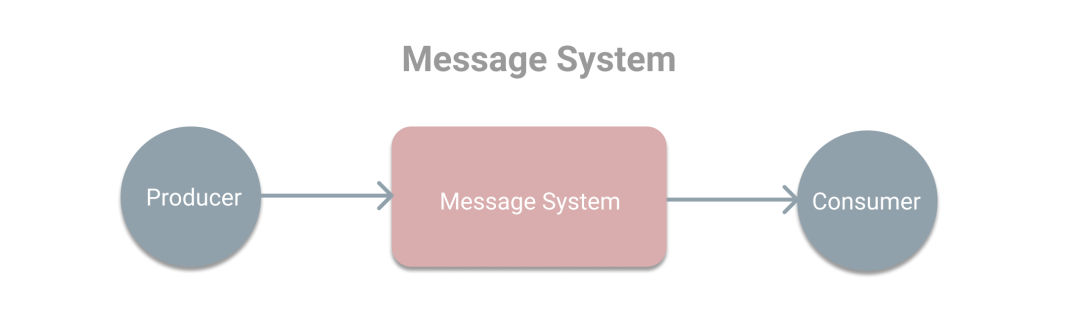
在上篇文章《消息系統(tǒng)概述》中對消息系統(tǒng)進行了介紹,本次將學習Kafka中的基本概念。首先我們回顧下在消息系統(tǒng)的使用場景中有三種角色分別是生產(chǎn)者、消息系統(tǒng)和消費者,其中生產(chǎn)者負責產(chǎn)生消息和發(fā)送消息到消息系統(tǒng),而消息系統(tǒng)將為消費者提供消息用于處理,如下圖。
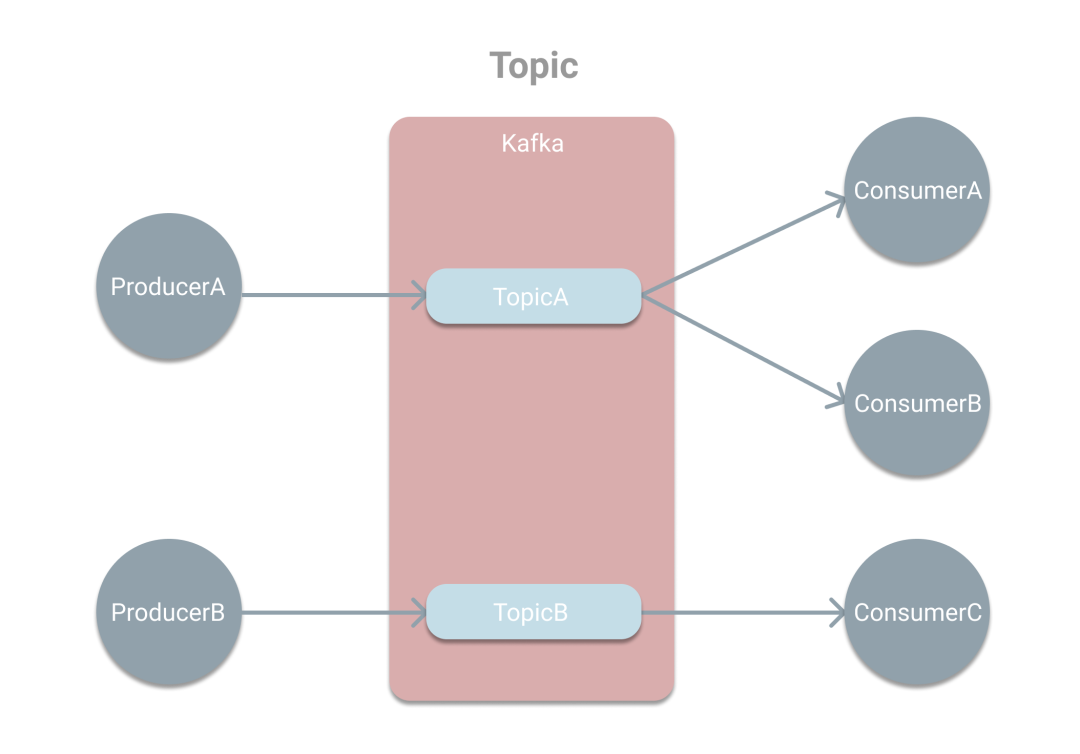
Kafka是基于發(fā)布/訂閱模式的消息系統(tǒng),如下圖。生產(chǎn)者會將消息推送到Kafka中的某個Topic上。引入Topic的目的則是為了對消息進行分類,這樣消費者就可以根據(jù)需要訂閱相應的Topic獲取消息。
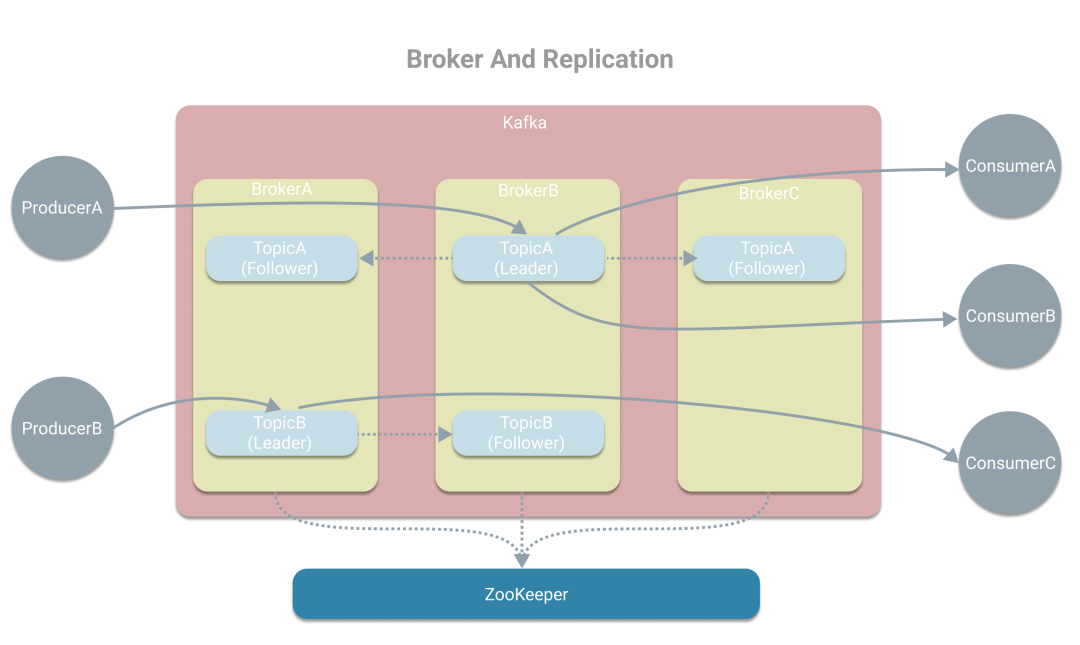
雖然Kafka這樣已經(jīng)能開始工作了,但緊接著又面臨單點問題。而為了解決單點問題,Kafka引入了Broker的概念。一個Broker是一個Kafka實例,而一臺機器上可運行多個Broker,這里我們認為一臺機器上只有一個Kafka實例。多個Broker將形成一個Kafka集群,而Topic也可指定副本數(shù)量,作為多個副本位于多臺機器上。Kafka使用ZooKeeper在多個副本中選舉出一個Leader,其他副本將作為Follower。Leaer主要負責讀寫消息,也就是和生產(chǎn)者、消費者打交道,同時將消息同步寫到其他副本中。當有Broker失效時,如果Topic沒有了Leader,則會重新選舉出新的Leader,從而解決單點問題。
引入Broker和副本后解決了單點問題,接著面對的是性能問題,對于單個Topic來說,只有Leader所在的Broker與生產(chǎn)者、消費者進行通信,這樣吞吐量將受到Broker所在的機器限制。那么如何提高吞吐量。Kafka將Topic拆分成多個分區(qū),也就是將消息進行劃分,類似數(shù)據(jù)庫的分庫,這樣起到了負載均衡的作用,可不受單機的限制。如下圖,生產(chǎn)者A分別往TopicA的分區(qū)0和分區(qū)1寫消息,而消費者A、B則也從分區(qū)0、1獲取消息。這里注意下,在不同分區(qū)存儲的消息也是不同的,和副本的概念要分清楚。
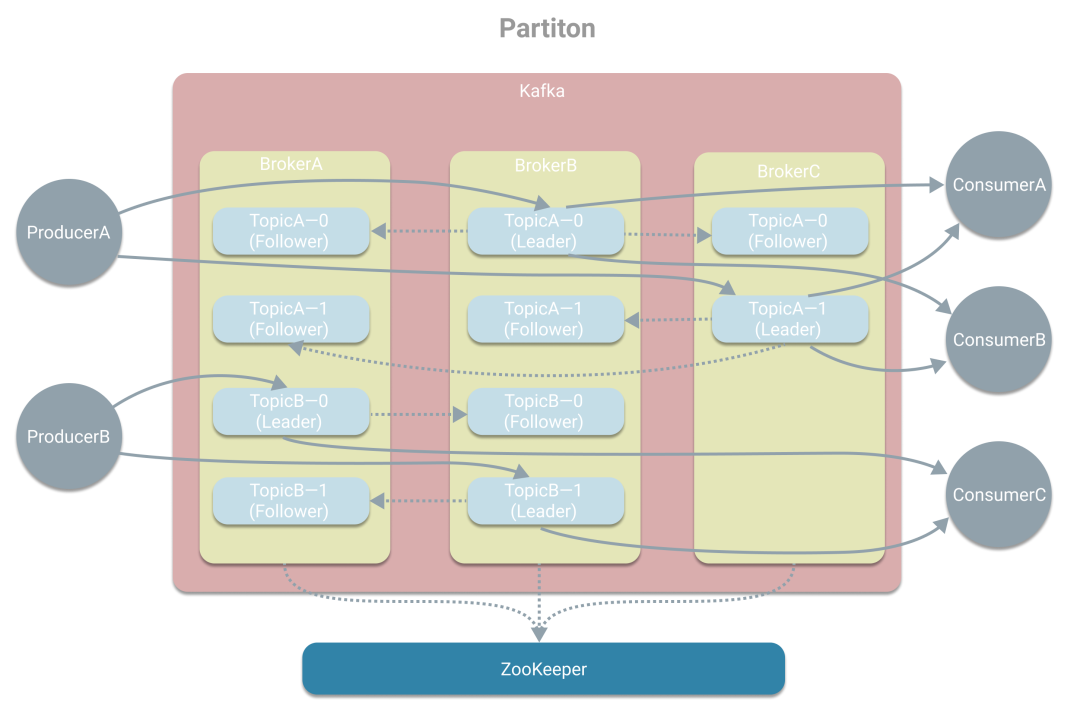
從上圖中我們可看到消費者A在消費TopicA時分別從分區(qū)0、分區(qū)1中獲取消息,為了進一步提高吞吐量,Kafka引入了消費組的概念,將消費者A拆分成多個消費者,從而形成一個消費組。我們可以這樣理解,消費者A是一個應用A實例,為了提高消費的吞吐量,我們多部署了幾個消費者A實例,這樣就有多個消費者形成一個消費組,但干的都是應用A做的事,需要與消費者B(不同的應用)區(qū)分開。一般設置消費組的消費者數(shù)與分區(qū)數(shù)一致,這是為了一個消費者能負責一個分區(qū),提高效率。如果消費組的消費者數(shù)量小于分區(qū)數(shù),則會出現(xiàn)一個消費者負責多個分區(qū)。而如果消費組的消費者數(shù)量大于分區(qū)數(shù),則會出現(xiàn)有消費者分不到分區(qū),造成浪費。所以一般保持一致。為了簡潔,且消費組B和消費組A類似,所以下圖未將消費組B畫出。
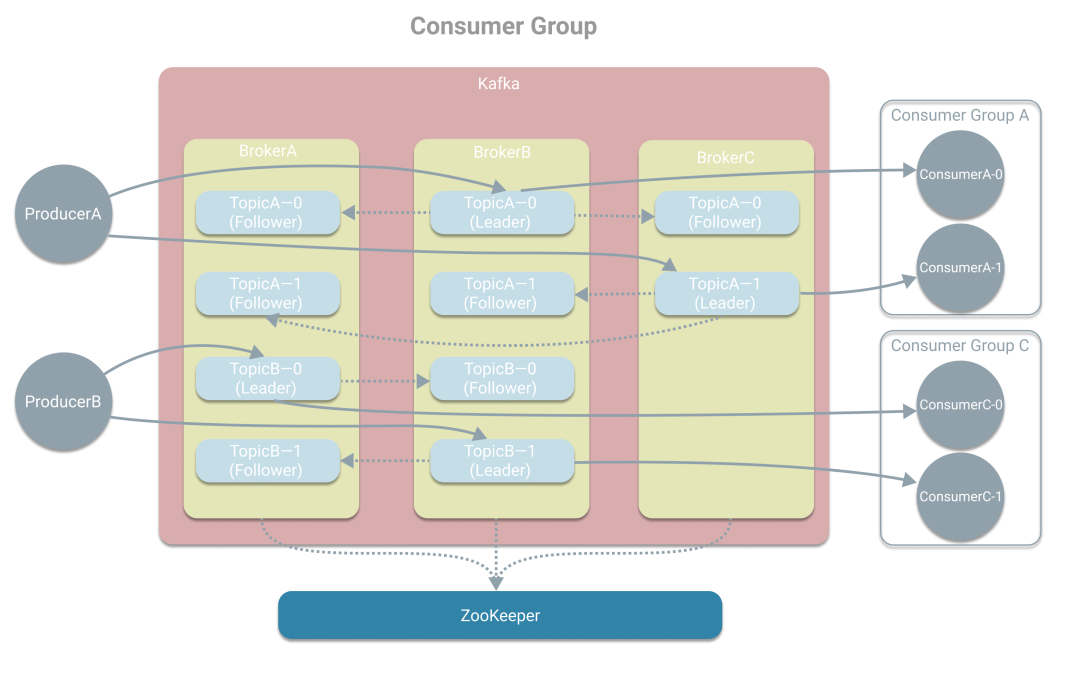
Kafka中的基本概念就是以上這些:生產(chǎn)者、消費者、Topic、Broker、副本、分區(qū)和消息組。最后為了大家更好的理解分區(qū)的概念,再畫一張細節(jié)圖。
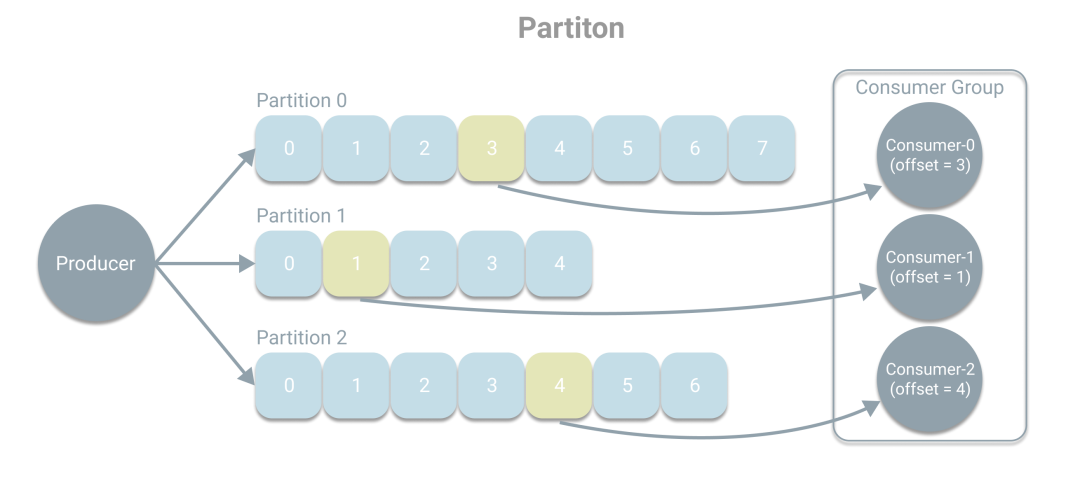
一個分區(qū)可以看做是一個單獨的隊列,生產(chǎn)者根據(jù)策略將消息寫入對于的分區(qū),策略有三種:一、直接指定分區(qū);二、如果未指定分區(qū),則根據(jù)消息的key,通過哈希函數(shù)指定分區(qū);三、如果沒有key,則輪詢分區(qū)。這里想強調(diào)的是分區(qū)中的數(shù)據(jù)是不同的,一條消息只會進入一個分區(qū)。而消費組中的消費者則會根據(jù)偏移量去分區(qū)中取得相應的消息進行消費處理。
完
? ? ? ?
 ???
???覺得不錯,點個在看~
