
ElasticSearch 干貨 | ElasticSearch 索引生命周期管理 ILM 實戰(zhàn)指南
1、什么是索引生命周期?
關(guān)于人生,有人這么說:“人,生來一個人,死去一個人,所以,人生就是一個人生老病死的簡稱。”
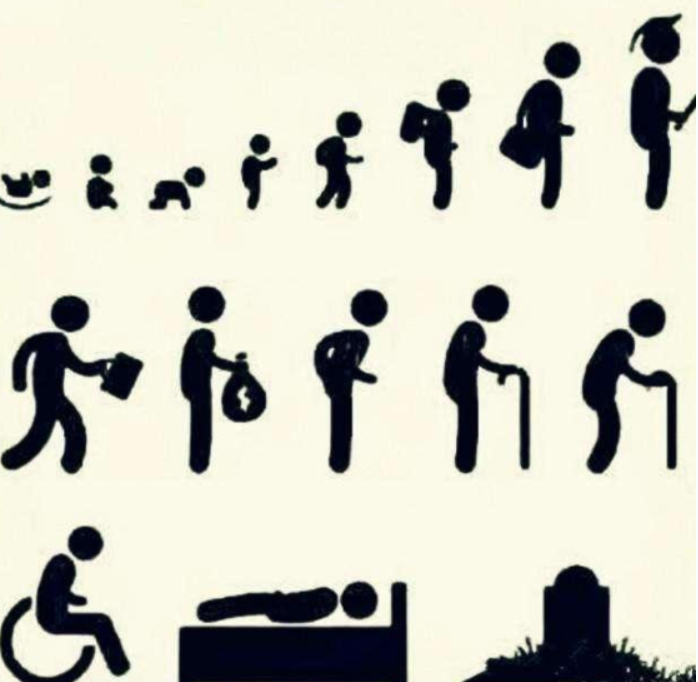
在基于日志、指標、實時時間序列的大型系統(tǒng)中,集群的索引也具備類似上圖中相通的屬性,一個索引自創(chuàng)建之后,不可能無限期的存在下去, 從索引產(chǎn)生到索引“消亡”,也會經(jīng)歷:“生、老、病、死”的階段。
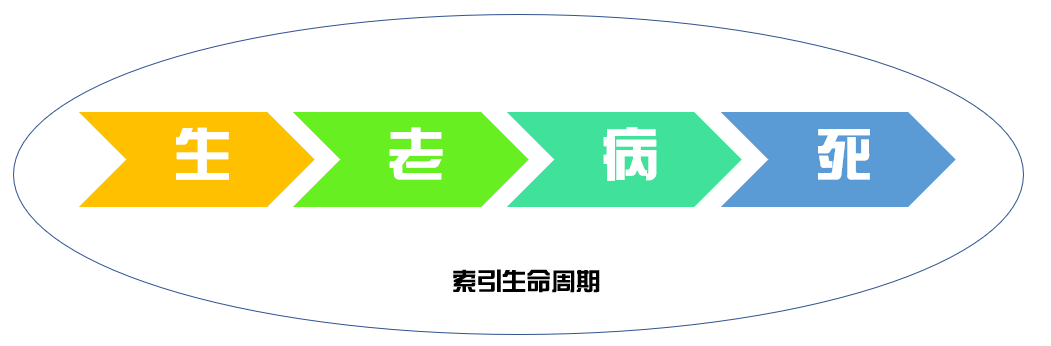
我們把索引的“生、老、病、死”的全過程類比稱為索引的生命周期。
2、什么是索引生命周期管理?
由于自然規(guī)律,人會“不可逆轉(zhuǎn)”的由小長到大,由大長到老,且理論上年齡一般不會超過 150 歲(吉尼斯世界紀錄:122歲零164天)。
索引不是人,理論上:一旦創(chuàng)建了索引,它可以一直存活下去(假定硬件條件允許,壽命是無限的)。
索引創(chuàng)建后,它自身是相對靜態(tài)的,沒有“自然規(guī)律”牽引它變化,若放任其成長,它只會變成一個數(shù)據(jù)量極大的臃腫的“大胖子”。
這里可能就會引申出來問題:若是時序數(shù)據(jù)的索引,隨著時間的推移,業(yè)務(wù)索引的數(shù)據(jù)量會越來越大。但,基于如下的因素:
集群的單個分片最大文檔數(shù)上限:2 的 32 次冪減去 1(20億左右)。 索引最佳實踐官方建議:分片大小控制在30GB-50GB,若索引數(shù)據(jù)量無限增大,肯定會超過這個值。 索引大到一定程度,當索引出現(xiàn)健康問題,會導(dǎo)致真?zhèn)€集群核心業(yè)務(wù)不可用。 大索引恢復(fù)的時間要遠比小索引恢復(fù)慢的多得多。 索引大之后,檢索會很慢,寫入和更新也會受到不同程度的影響。 某些業(yè)務(wù)場景,用戶更關(guān)心最近3天、最近7天的業(yè)務(wù)數(shù)據(jù),大索引會將全部歷史數(shù)據(jù)匯集在一起,不利于這種場景的查詢。
非常有必要對索引進行管理起來,不再放任其“野蠻長成體弱多病、潛在風(fēng)險極大的大胖子”,而是限制其分階段、有目標的、有規(guī)律的生長。
這種分階段、有目標的操作和實現(xiàn),我們稱為索引生命周期管理。
3、索引生命周期管理的歷史演變
索引生命周期管理 (ILM) 是在 Elasticsearch 6.6(公測版)首次引入,在 6.7 版本正式推出的一項功能。
ILM 是 Elasticsearch 的一部分,主要用來幫助用戶管理索引。
沒有 ILM 之前索引生命周期管理基于:rollover + curator 實現(xiàn)。
ILM 是早些年呼聲非常高的功能之一,我印象中 2017 年南京的 meetup 中,就有公司說實現(xiàn)了類似的功能。
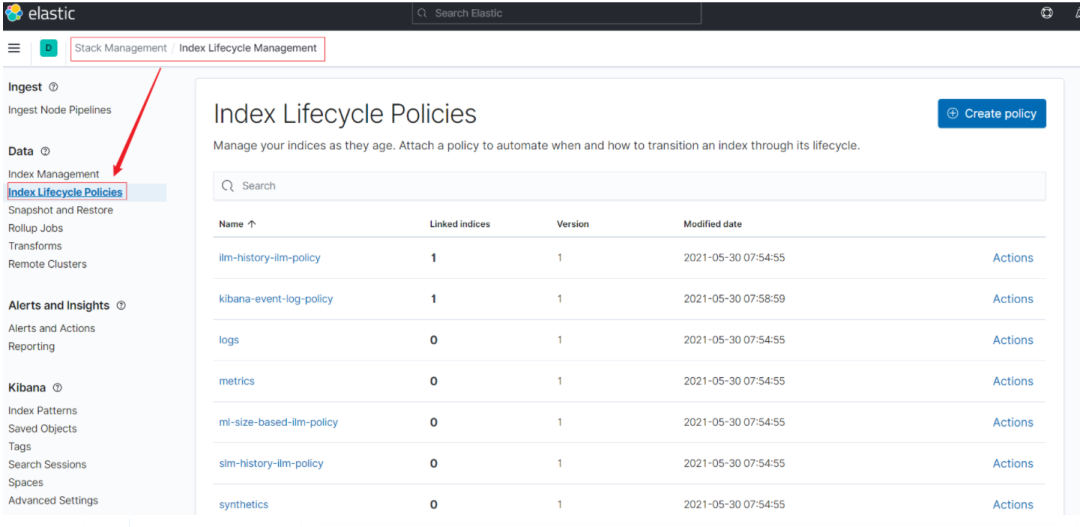
Kibana 7.12.0 索引生命周期管理配置界面如下圖所示:
4、索引生命周期管理的前提
本文演示試用版本:Elasticesarch:7.12.0,Kibana:7.12.0。
集群規(guī)模:3節(jié)點,屬性(node_roles)設(shè)置分別如下:
節(jié)點 node-022:主節(jié)點+數(shù)據(jù)節(jié)點+熱節(jié)點(Hot)。
節(jié)點 node-023:主節(jié)點+數(shù)據(jù)節(jié)點+溫節(jié)點(Warm)。
節(jié)點 node-024:主節(jié)點+數(shù)據(jù)節(jié)點+冷節(jié)點(Cold)。
4.1 冷熱集群架構(gòu)
冷熱架構(gòu)也叫熱暖架構(gòu),是“Hot-Warm” Architecture的中文翻譯。
冷熱架構(gòu)本質(zhì)是給節(jié)點設(shè)置不同的屬性,讓每個節(jié)點具備了不同的屬性。
為演示 ILM,需要首先配置冷熱架構(gòu),三個節(jié)點在 elasticsearch.yml 分別設(shè)置的屬性如下:
- node.attr.box_type: hot
- node.attr.box_type: warm
- node.attr.box_type: cold
拿輿情數(shù)據(jù)舉例,通俗解讀如下:
熱節(jié)點(Hot):存放用戶最關(guān)心的熱數(shù)據(jù)。
比如:最近3天的數(shù)據(jù)——近期大火的“曹縣牛皮666,我的寶貝”。
溫節(jié)點(Warm):存放前一段時間沉淀的熱數(shù)據(jù),現(xiàn)在不再熱了。
比如:3-7天的熱點事件——“特斯拉車頂事件”。
冷節(jié)點(Cold):存放用戶不太關(guān)心或者關(guān)心優(yōu)先級低的冷數(shù)據(jù),很久之前的熱點事件。
比如:7天前或者很久前的熱點事件——去年火熱的“后浪視頻“、”馬老師不講武德”等。
如果磁盤數(shù)量不足,冷數(shù)據(jù)是待刪除優(yōu)先級最高的。
如果硬件資源不足,熱節(jié)點優(yōu)先配置為 SSD 固態(tài)盤。
檢索優(yōu)先級最高的是熱節(jié)點的數(shù)據(jù),基于熱節(jié)點檢索數(shù)據(jù)自然比基于全量數(shù)據(jù)響應(yīng)時間要快。
更多冷熱架構(gòu)推薦:干貨 | Elasticsearch 冷熱集群架構(gòu)實戰(zhàn)。
4.2 rollover 滾動索引
實際Elasticsearch 5.X 之后的版本已經(jīng)推出:Rollover API。Rollover API解決的是以日期作為索引名稱的索引大小不均衡的問題。
Rollover API對于日志類的數(shù)據(jù)非常有用,一般我們按天來對索引進行分割(數(shù)據(jù)量更大還能進一步拆分),沒有Rollover之前,需要在程序里設(shè)置一個自動生成索引的模板。
推薦閱讀:干貨 | Elasticsearch索引生命周期管理探索
rollover 滾動索引實踐一把:
# 1、創(chuàng)建基于日期的索引
PUT %3Cmy-index-%7Bnow%2Fd%7D-000001%3E
{
"aliases": {
"my-alias": {
"is_write_index": true
}
}
}
# 2、批量導(dǎo)入數(shù)據(jù)
PUT my-alias/_bulk
{"index":{"_id":1}}
{"title":"testing 01"}
{"index":{"_id":2}}
{"title":"testing 02"}
{"index":{"_id":3}}
{"title":"testing 03"}
{"index":{"_id":4}}
{"title":"testing 04"}
{"index":{"_id":5}}
{"title":"testing 05"}
# 3、rollover 滾動索引
POST my-alias/_rollover
{
"conditions": {
"max_age": "7d",
"max_docs": 5,
"max_primary_shard_size": "50gb"
}
}
GET my-alias/_count
# 4、在滿足滾動條件的前提下滾動索引
PUT my-alias/_bulk
{"index":{"_id":6}}
{"title":"testing 06"}
# 5、檢索數(shù)據(jù),驗證滾動是否生效
GET my-alias/_search
如上的驗證結(jié)論是:
{
"_index" : "my-index-2021.05.30-000001",
"_type" : "_doc",
"_id" : "5",
"_score" : 1.0,
"_source" : {
"title" : "testing 05"
}
},
{
"_index" : "my-index-2021.05.30-000002",
"_type" : "_doc",
"_id" : "6",
"_score" : 1.0,
"_source" : {
"title" : "testing 06"
}
}
_id 為 6 的數(shù)據(jù)索引名稱變成了:my-index-2021.05.30-000002,實現(xiàn)了 后綴 id 自增。
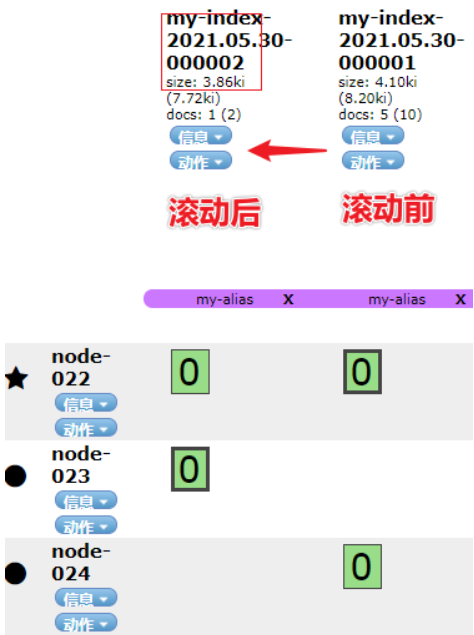
這里要強調(diào)下,索引滾動變化的三個核心條件:
"max_age": "7d", 最長期限 7d,超過7天,索引會實現(xiàn)滾動。 "max_docs": 5, 最大文檔數(shù) 5,超過 5個文檔,索引會實現(xiàn)滾動(測試需要,設(shè)置的很小)。 "max_primary_shard_size": "50gb",主分片最大存儲容量 50GB,超過50GB,索引就會滾動。
注意,三個條件是或的關(guān)系,滿足其中一個,索引就會滾動。
4.3 shrink 壓縮索引
壓縮索引的本質(zhì):在索引只讀等三個條件的前提下,減少索引的主分片數(shù)。
# 設(shè)置待壓縮的索引,分片設(shè)置為5個。
PUT kibana_sample_data_logs_ext
{
"settings": {
"number_of_shards":5
}
}
# 準備索引數(shù)據(jù)
POST _reindex
{
"source":{
"index":"kibana_sample_data_logs"
},
"dest":{
"index":"kibana_sample_data_logs_ext"
}
}
# shrink 壓縮之前的三個必要條件
PUT kibana_sample_data_logs_ext/_settings
{
"settings": {
"index.number_of_replicas": 0,
"index.routing.allocation.require._name": "node-024",
"index.blocks.write": true
}
}
# 實施壓縮
POST kibana_sample_data_logs_ext/_shrink/kibana_sample_data_logs_shrink
{
"settings": {
"index.number_of_replicas": 0,
"index.number_of_shards": 1,
"index.codec": "best_compression"
},
"aliases": {
"kibana_sample_data_logs_alias": {}
}
}
有圖有真相:
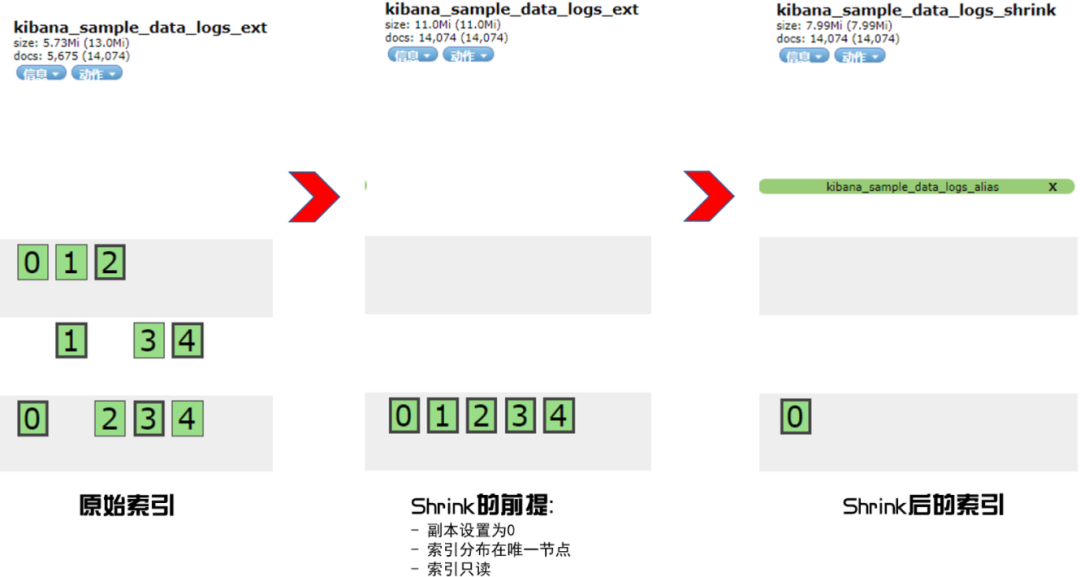
強調(diào)一下三個壓縮前的條件,缺一不可:
"index.number_of_replicas": 0 副本設(shè)置為 0。 "index.routing.allocation.require._name": "node-024" 分片數(shù)據(jù)要求都集中到一個獨立的節(jié)點。 "index.blocks.write": true 索引數(shù)據(jù)只讀。
4.4 Frozen 冷凍索引
為高效檢索,核心業(yè)務(wù)索引都會保持在內(nèi)存中,意味著內(nèi)存使用率會變得很高。
對于一些非業(yè)務(wù)必須、非密集訪問的某些索引,可以考慮釋放內(nèi)存,僅磁盤存儲,必要的時候再還原檢索。
這時候,就會用到 Frozen 冷凍索引。除了在內(nèi)存中維護其元數(shù)據(jù),凍結(jié)索引在集群上幾乎沒有開銷,并且冷凍索引是只讀的。
具體使用如下:
# 冷凍索引
POST kibana_sample_data_logs_shrink/_freeze
# 冷凍后,不能寫入
POST kibana_sample_data_logs_shrink/_doc/1
{
"test":"12111"
}
# 冷凍后,能檢索,但不返回具體數(shù)據(jù),只返回0。
POST kibana_sample_data_logs_shrink/_search
# 解除冷凍
POST kibana_sample_data_logs_shrink/_unfreeze
# 解除冷凍后,可以檢索和寫入了
POST kibana_sample_data_logs_shrink/_search
綜合上述拆解分析可知:
有了:冷熱集群架構(gòu),集群的不同節(jié)點有了明確的角色之分,冷熱數(shù)據(jù)得以物理隔離,SSD 固態(tài)盤使用效率會更高。
有了:rollover 滾動索引,索引可以基于文檔個數(shù)、時間、占用磁盤容量滾動升級,實現(xiàn)了索引的動態(tài)變化。
有了:Shrink 壓縮索引、Frozen 冷凍索引,索引可以物理層面壓縮、冷凍,分別釋放了磁盤空間和內(nèi)存空間,提高了集群的可用性。
除此之外,還有:Force merge 段合并、Delete 索引數(shù)據(jù)刪除等操作,索引的“生、老、病、死”的全生命周期的更迭,已然有了助推器。
如上指令單個操作,非常麻煩和繁瑣,有沒有更為快捷的方法呢?
有的!
第一:命令行可以 DSL 大綜合實現(xiàn)。
第二:可以借助 Kibana 圖形化界面實現(xiàn)。
下面兩小節(jié)會結(jié)合實例解讀。
5、Elasticsearch ILM 實戰(zhàn)
5.1 核心概念:不同階段(Phrase)的功能點(Acitons)

注意:僅在 Hot 階段可以設(shè)置:Rollover 滾動。
5.2 各生命周期 Actions 設(shè)定
后兩節(jié)演示要用。
5.2.1 Hot 階段
基于:max_age=3天、最大文檔數(shù)為5、最大size為:50gb rollover 滾動索引。
設(shè)置優(yōu)先級為:100(值越大,優(yōu)先級越高)。
5.2.2 Warm 階段
實現(xiàn)段合并,max_num_segments 設(shè)置為1. 副本設(shè)置為 0。 數(shù)據(jù)遷移到:warm 節(jié)點。 優(yōu)先級設(shè)置為:50。
5.2.3 Cold 階段
冷凍索引 數(shù)據(jù)遷移到冷節(jié)點
5.2.4 Delete 階段
刪除索引
關(guān)于觸發(fā)滾動的條件:
Hot 階段的觸發(fā)條件:手動創(chuàng)建第一個滿足模板要求的索引。
其余階段觸發(fā)條件:min_age,索引自創(chuàng)建后的時間。
時間類似:業(yè)務(wù)里面的 熱節(jié)點保留 3 天,溫節(jié)點保留 7 天,冷節(jié)點保留 30 天的概念。
5.3 DSL 實戰(zhàn)索引生命周期管理
# step1: 前提:演示刷新需要
PUT _cluster/settings
{
"persistent": {
"indices.lifecycle.poll_interval": "1s"
}
}
# step2:測試需要,值調(diào)的很小
PUT _ilm/policy/my_custom_policy_filter
{
"policy": {
"phases": {
"hot": {
"actions": {
"rollover": {
"max_age": "3d",
"max_docs": 5,
"max_size": "50gb"
},
"set_priority": {
"priority": 100
}
}
},
"warm": {
"min_age": "15s",
"actions": {
"forcemerge": {
"max_num_segments": 1
},
"allocate": {
"require": {
"box_type": "warm"
},
"number_of_replicas": 0
},
"set_priority": {
"priority": 50
}
}
},
"cold": {
"min_age": "30s",
"actions": {
"allocate": {
"require": {
"box_type": "cold"
}
},
"freeze": {}
}
},
"delete": {
"min_age": "45s",
"actions": {
"delete": {}
}
}
}
}
}
# step3:創(chuàng)建模板,關(guān)聯(lián)配置的ilm_policy
PUT _index_template/timeseries_template
{
"index_patterns": ["timeseries-*"],
"template": {
"settings": {
"number_of_shards": 1,
"number_of_replicas": 0,
"index.lifecycle.name": "my_custom_policy_filter",
"index.lifecycle.rollover_alias": "timeseries",
"index.routing.allocation.require.box_type": "hot"
}
}
}
# step4:創(chuàng)建起始索引(便于滾動)
PUT timeseries-000001
{
"aliases": {
"timeseries": {
"is_write_index": true
}
}
}
# step5:插入數(shù)據(jù)
PUT timeseries/_bulk
{"index":{"_id":1}}
{"title":"testing 01"}
{"index":{"_id":2}}
{"title":"testing 02"}
{"index":{"_id":3}}
{"title":"testing 03"}
{"index":{"_id":4}}
{"title":"testing 04"}
# step6:臨界值(會滾動)
PUT timeseries/_bulk
{"index":{"_id":5}}
{"title":"testing 05"}
# 下一個索引數(shù)據(jù)寫入
PUT timeseries/_bulk
{"index":{"_id":6}}
{"title":"testing 06"}
核心步驟總結(jié)如下:
第一步:創(chuàng)建生周期 policy。 第二步:創(chuàng)建索引模板,模板中關(guān)聯(lián) policy 和別名。 第三步:創(chuàng)建符合模板的起始索引,并插入數(shù)據(jù)。 第四步: 索引基于配置的 ilm 滾動。
實現(xiàn)效果如下GIF動畫(請耐心看完)
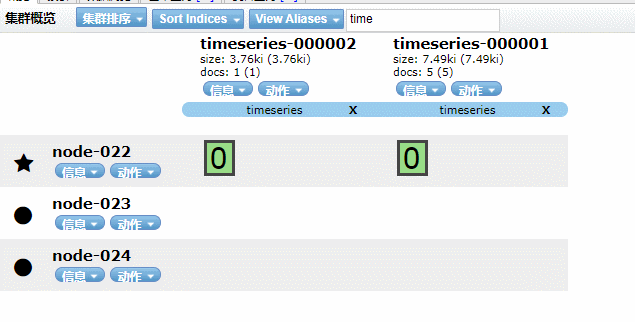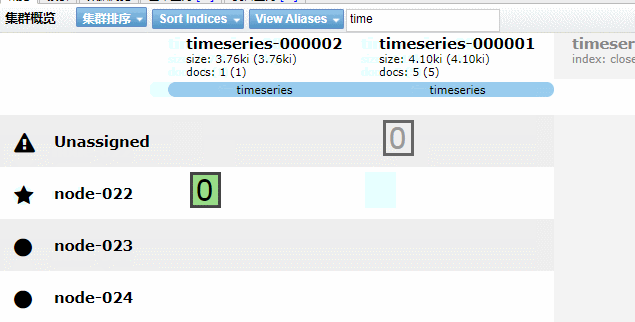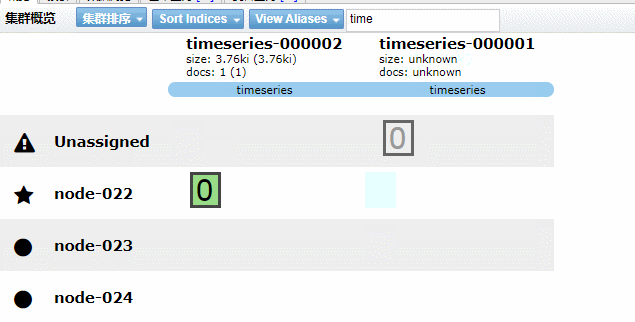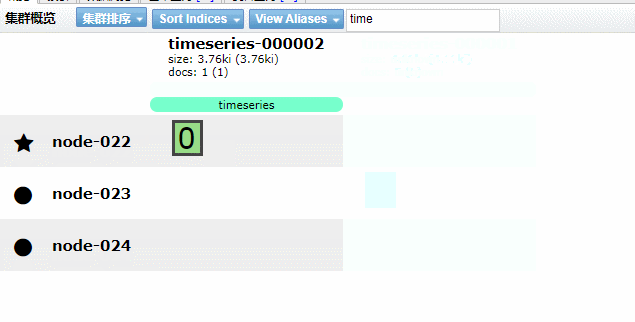
5.4、Kibana 圖形化界面實現(xiàn)索引生命周期管理
步驟 1:配置 policy。
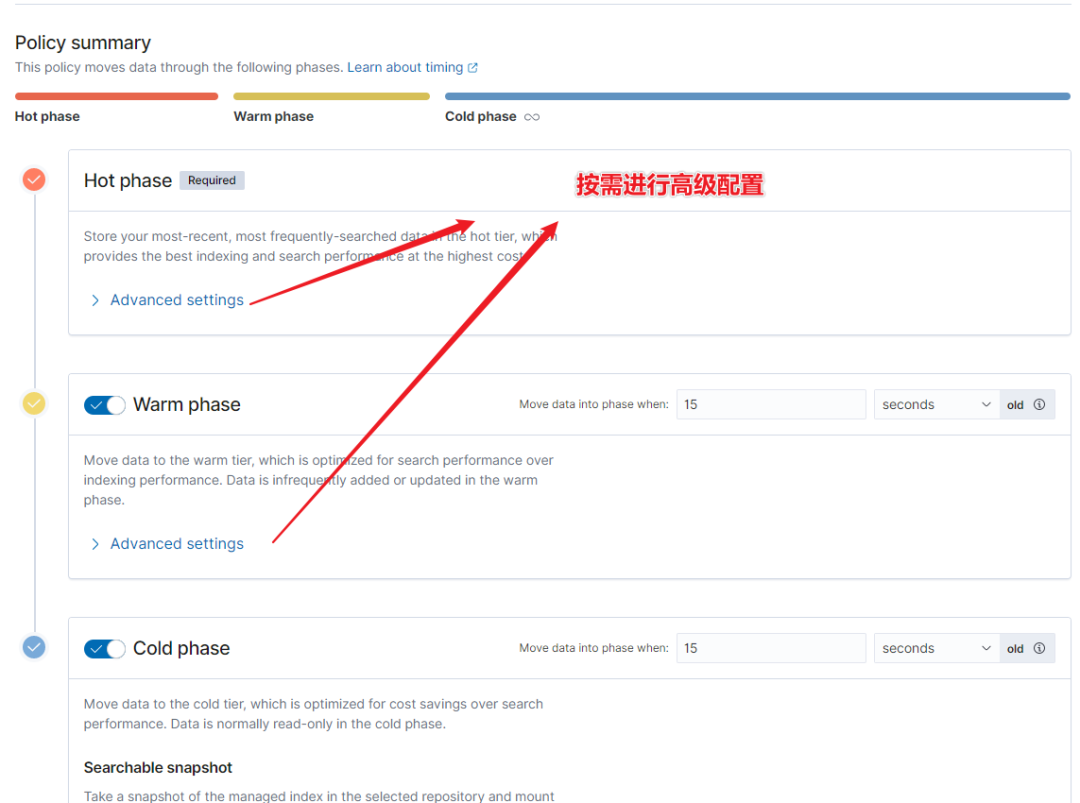
步驟 2:關(guān)聯(lián)模板。
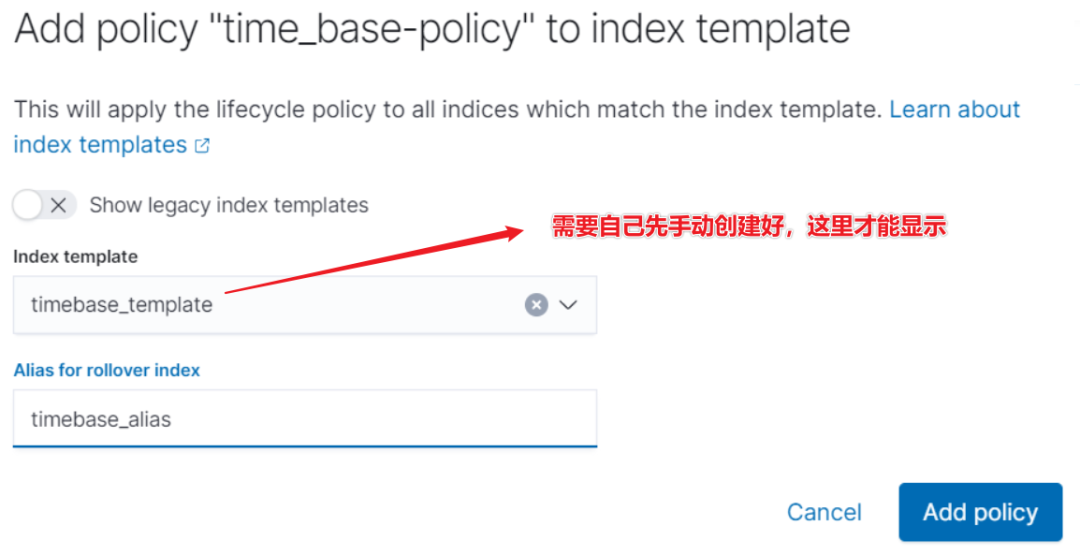
前提條件:
模板要自己 DSL 創(chuàng)建,以便關(guān)聯(lián)。 PUT _index_template/timebase_template
{ "index_patterns": ["time_base-*"] }創(chuàng)建起始索引,指定別名和寫入。 PUT time_base-000001 { "aliases": { "timebase_alias": { "is_write_index": true } } }
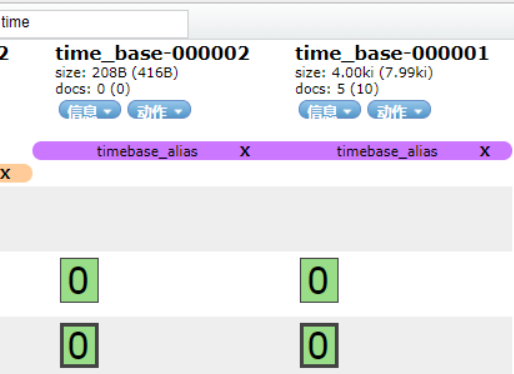
6、小結(jié)
索引生命周期管理需要加強對三個概念的認知:
橫向——Phrase 階段:Hot、Warm、Cold、Delete 等對應(yīng)索引的生、老、病、死。 縱向——Actions 階段:各個階段的動作。 橫向縱向整合的Policy:實際是階段和動作的綜合體。
配置完畢Policy,關(guān)聯(lián)好模板 template,整個核心工作就完成了80%。
剩下就是各個階段 Actions 的調(diào)整和優(yōu)化了。
實戰(zhàn)表明:用 DSL 實現(xiàn)ILM 比圖形化界面更可控、更便于問題排查。
ILM 你實際生產(chǎn)環(huán)境使用了嗎?效果如何?歡迎留言討論。
參考
https://www.elastic.co/guide/en/elasticsearch/reference/current/example-using-index-lifecycle-policy.html
https://ptran32.github.io/2020-08-08-hot-warm-cold-elasticsearch/
https://www.elastic.co/cn/blog/implementing-hot-warm-cold-in-elasticsearch-with-index-lifecycle-management
魏彬老師ET開源課堂
推薦:
全網(wǎng)首發(fā)!《 Elasticsearch 最少必要知識教程 V1.0 》低調(diào)發(fā)布
干貨 | Elasticsearch索引管理利器——Curator深入詳解
中國最大的 Elastic 非官方公眾號
點擊查看“閱讀原文”,和全球近 1100 位+ Elastic 愛好者(中國 50%+ Elastic 認證工程師來自死磕Elasticsearch 知識星球)每日精進 ELK 技能!