
原因的原因不是原因,結(jié)果的結(jié)果不是結(jié)果

導讀:人生難料,世事無常,大多是“原因”和“結(jié)果”之間的糾纏。

01
故事A
某地空氣極好,但是當?shù)厮烙诤粑到y(tǒng)疾病的患者數(shù)量,卻名列全國前幾位。
故事B
我有個親戚,開服裝廠,行業(yè)每況愈下,總說要關門。去年底好容易接了幾個大單,年初因為疫情,訂單被砍掉了一大半!
A面:我們應該看得更長遠; B面:我們應該立足當下,做好眼前的事情。

假設有人嚇走了一只鴿子。 鴿子飛走的時候,驚到了一位正在穿越街道的路人。 路人駐足觀望,結(jié)果導致一輛正在朝他騎過來的自行車不得不在最后一秒急轉(zhuǎn)車頭。 自行車避讓行人后,正好騎到了一輛出租車行駛的車道上。 出租車為了避讓自行車,結(jié)果撞上了一個消防栓。 消防栓出水導致附近一棟大樓的地下室被淹,破壞了地下室的供電設施。
雖然嚇走鴿子是啟動整個原因鏈的原因,我們也可以認為是嚇走鴿子這件事導致了后面的一系列事件,但很少有人會認為嚇走鴿子的那個人應該對之后出現(xiàn)的一系列事件負責——即使很多人都同意是那個人引起了這一系列的事件。
一只蝴蝶在巴西輕拍翅膀,可以導致一個月后德克薩斯州的一場龍卷風。

若一個經(jīng)濟學的特性被用作經(jīng)濟指標,那這項指標最終一定會失去其功能,因為人們會開始玩弄這項指標。

人類對因果的“幻覺”; 誤將“相關性”當作“因果性”; 因果之間距離過大; 混淆了原因和結(jié)果; 對條件概率的混亂; 人類的無知和科學的局限; 過于依賴確定性; “自上而下”的習慣思維。
雖然我們能觀察到一件事物隨著另一件事物而來,我們卻并不能觀察到這兩件事物之間的關聯(lián)。
我們無從得知因果之間的關系,只能得知某些事物總是會連結(jié)在一起,而這些事物在過去的經(jīng)驗里又是從不曾分開過的。 我們并不能看透連結(jié)這些事物背后的理性為何,我們只能觀察到這些事物的本身,并且發(fā)現(xiàn)這些事物總是透過一種經(jīng)常的連結(jié)而被我們在想像中歸類。

已知:美國400萬被虐待的妻子中只有1432名被其丈夫殺死。? 所以:辛普森殺死妻子的概率只有1432/400萬,即1/2500。 因此:辛普森殺死妻子的概率是非常低的事件,即辛普森幾乎不可能殺死他的妻子。
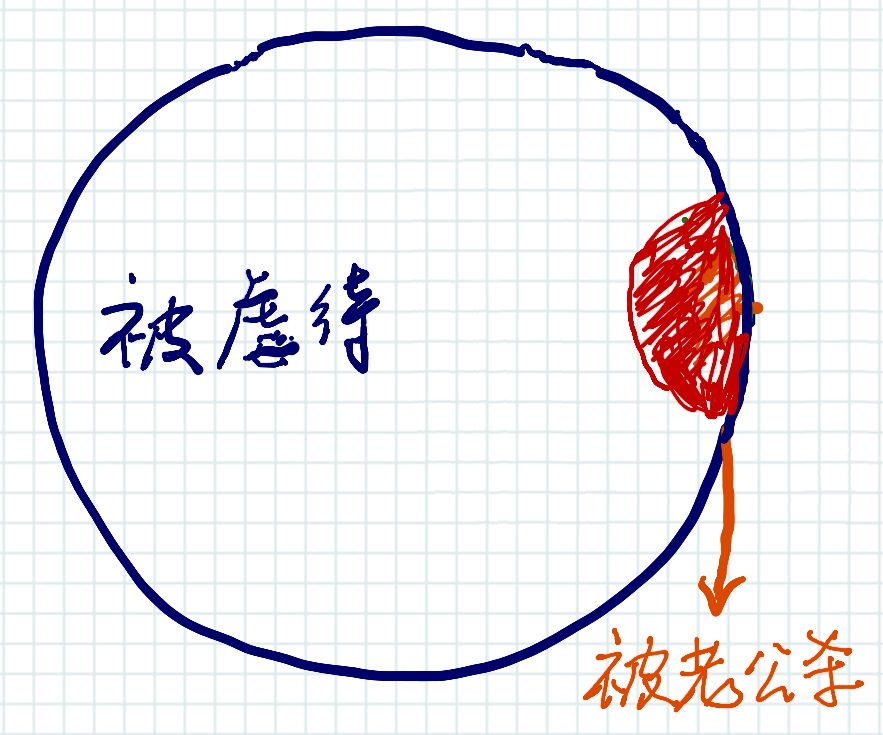
因為我們討論的是被謀殺的被虐待妻子,所以綠色圓圈被包含在藍色圓圈內(nèi); 因為并不是所有被謀殺的妻子都是被丈夫殺害的,所以紅色圓圈被包含在綠色圓圈內(nèi),“問號”部分表示那些被別人謀殺的被丈夫虐待的妻子。

由于不正確的假設、錯誤的因果聯(lián)系、輸入的噪聲多于數(shù)據(jù),以及未被預測到的人為因素,經(jīng)濟模型經(jīng)常遭遇反復失敗。預測被證明是不準確的。模型總是會低估風險,從而導致金融危機的爆發(fā)。
一種是理解不確定性的; 一種是不理解不確定性的。
首先《人生算法》是一本關于不確定性的書; 其次為什么有人愿意相信花幾十塊錢買本書可以“確保”人生富足?(別信圖書封面......)
人們對于需要追求確定性的事情,例如投資,以及一些關乎幸福的關鍵決策,往往不假思索。 反倒對那些無法預料、需要伸手去觸碰的事情思前想后。

演變就發(fā)生在我們身邊。它是理解人類世界和自然世界如何變化的最佳途徑。 人類制度、人工制品和習慣的改變,都是漸進的、必然的、不可抵擋的。
它遵循從一個階段進入下一個階段的敘述方式; 它慢慢推進而非大步跳躍; 它有自己自發(fā)的勢頭,不為外部所推動; 它心里沒有什么目標,也沒有具體的終點; 它基本上是靠試錯產(chǎn)生的,而試錯是自然選擇的一種形式。
促使眼睛總對光做出反應的“視蛋白”分子,可以追溯到所有動物的共同祖先身上(海綿類動物除外)。 大約7億年前,視蛋白基因復制了兩次,產(chǎn)生了我們今天擁有的3種感光分子。 故此,眼睛演變的每一個階段,從感光分子的發(fā)展、透鏡和色覺的自然形成,都可以從基因的語言里直接讀取。

極其復雜,棋局變化的可能性約等于2.08x10^170種,比整個宇宙里的原子數(shù)量還要多很多。 棋子都是一樣的,反而更難評估優(yōu)劣。 象棋越下棋子越少,圍棋越下棋子越多。 圍棋既有局部精確的計算,又有宏觀局面模糊的判斷。
圍棋中沒有等級概念,所有棋子都一樣,圍棋是筑防游戲,因此需要盤算未來。你在下棋的過程中,是棋盤在心中,必須要預測未來。小小一個棋子可撼動全局,牽一發(fā)動全身。



圍棋棋子除了顏色以外,完全一樣,不像象棋那樣分帥車兵馬。 另外,圍棋的棋子,落下之后就不能移動。 圍棋棋子的效率和價值,是由棋子之間的空間關系而決定的。 就像搭宜家家具或者樂高玩具,即使空間位置對了,但如果順序錯了,也不行。
拋硬幣的結(jié)果并不取決于以前拋硬幣的結(jié)果,所以這不是馬爾可夫理想的模型。 但是,如果增加一點依賴關系,使下一個事件取決于剛剛發(fā)生了什么,而不是整個系統(tǒng)如何影響了當前事件,又會怎么樣呢? 每個事件的概率僅取決于先前事件的一系列事件被稱為馬爾可夫鏈。 預測天氣就是一個例子:明天的天氣肯定取決于今天的天氣,但并不特別依賴于上周的天氣。
馬爾可夫模型構建的意義,是為了探尋未來的最優(yōu)策略,以及馬爾可夫性與歷史總是不相關的,僅與當前狀態(tài)有關。所以一切模型構建均是圍繞未來進行展開的。 (本段來自網(wǎng)絡)
起始狀態(tài)是一個空的棋盤,棋手根據(jù)棋面(狀態(tài))選擇落子點(動作)后,轉(zhuǎn)換到下一個狀態(tài)(轉(zhuǎn)換概率為:其中一個狀態(tài)的概率為 1,其他狀態(tài)的概率為 0),局勢的優(yōu)劣是每個狀態(tài)的回報。棋手需要根據(jù)棋面選擇合適落子點,建立優(yōu)勢并最終贏下游戲。 (本段來自劉思鄉(xiāng))
環(huán)境可以是真實世界,電腦游戲,模擬,甚至棋盤游戲,比如圍棋或象棋。就像人類一樣,人工智能代理人從其行為的結(jié)果中學習,而不是從明確的教導中學習。 在深度強化學習中,智能體是由神經(jīng)網(wǎng)絡表示的。神經(jīng)網(wǎng)絡直接與環(huán)境相互作用。它觀察環(huán)境的當前狀態(tài),并根據(jù)當前狀態(tài)和過去的經(jīng)驗決定采取何種行動(例如向左、向右移動等)。根據(jù)采取的行動,AI智能體收到一個獎勵(Reward)。獎勵的數(shù)量決定了在解決給定問題時采取的行動的質(zhì)量(例如學習如何走路)。智能體的目標是學習在任何特定的情況下采取行動,使累積的獎勵隨時間最大化。
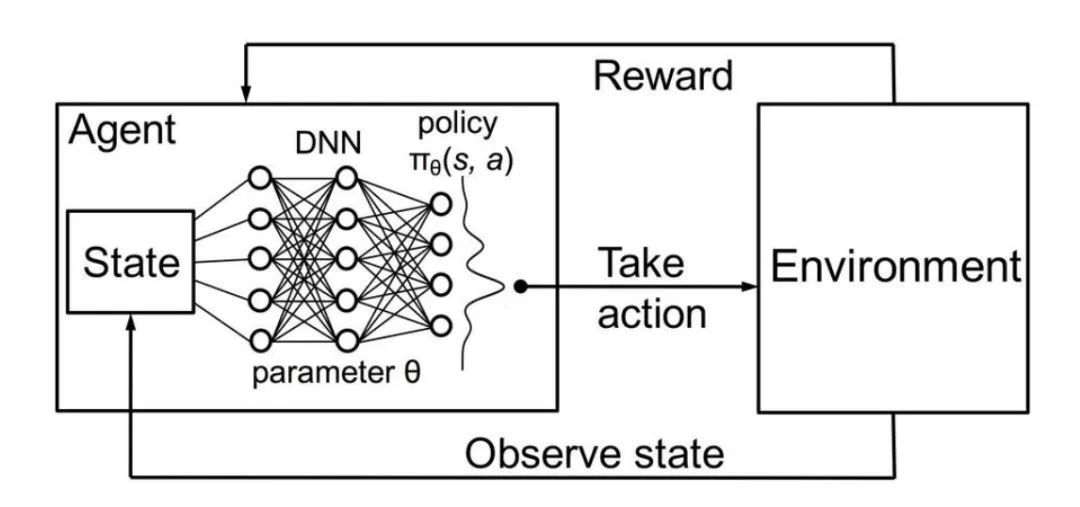
阿爾法狗每下的一盤棋,都是一次自我進化的學習過程,工作即學習,學習即工作; 阿爾法狗的唯一目標是終局勝負,因此而有強烈的使命感,鋼鐵般的意志,和石佛般的平常心(盡管它不需要這些形容詞); 把每一手棋,都當作一個獨立決策點,將當前的整個局面視為一個初始狀態(tài),根據(jù)當前局面,發(fā)現(xiàn)(模仿人的直覺)獲勝概率較高的幾手棋,并估算每一手棋的終局勝率; 從中選擇最優(yōu)決策; 等對方落子后,再次進入“初始狀態(tài)”,根據(jù)更新的信息,重復以上動作,直至終局。
圍棋應該自由舒展,妙趣橫生地下。因此,我覺得應該把整個棋盤當做自己的舞臺。

很長一段時間, 我的生活看似馬上就要開始了, 真正的生活, 但是總有一些障礙阻擋著, 有些事得先解決, 有些工作還有待完成, 時間貌似夠用, 還有一筆債務要去付清, 然后生活就會開始, 最后我終于明白, 這些障礙, 正是我的生活。
有死之人的思想必須讓自身沒入深深泉源的黑暗中,以便在白天能看到星星。
黑暗有黑暗的清澈,不過我們沒有洞悉黑暗的眼睛。于是我們點亮了燭光,企圖照亮整個宇宙。 然而,我們越來越固執(zhí)于光明,在此光明中營造自己的家園,反而遺忘了那深不可測無邊無際的黑暗,遺忘了我們本源的家。

延伸閱讀《天才與算法》
推薦語:美、英兩國雙料院士馬庫斯·杜·索托伊先生作品。我們即將進入一個由算法主導世界,AI將在繪畫、音樂、寫作等向人類發(fā)起挑戰(zhàn),作者用數(shù)學幫我們理解算法及創(chuàng)造力的本質(zhì)。
干貨直達??
評論
圖片
表情