
時(shí)序數(shù)據(jù)庫(kù) CeresDB 1.0 正式發(fā)布
經(jīng)過近一年的開源研發(fā)工作,我們很高興地和大家同步:時(shí)序數(shù)據(jù)庫(kù) CeresDB 1.0 正式發(fā)布,達(dá)到生產(chǎn)可用標(biāo)準(zhǔn)。
代碼主倉(cāng)庫(kù)的GitHub 地址為:https://github.com/CeresDB/ceresdb
CeresDB 1.0 官方文檔:https://docs.ceresdb.io
1.
設(shè)計(jì)目標(biāo)
CeresDB 團(tuán)隊(duì)已經(jīng)在時(shí)序數(shù)據(jù)領(lǐng)域進(jìn)行了5年的深耕。但是隨著在領(lǐng)域內(nèi)研究的深入以及用戶場(chǎng)景的逐漸復(fù)雜化,我們發(fā)現(xiàn)了若干傳統(tǒng)時(shí)序數(shù)據(jù)庫(kù)尚未很好解決的一些技術(shù)問題,比如:
高效處理高基數(shù) Tag 組合(時(shí)間線膨脹問題)與分析型工作負(fù)載
現(xiàn)代且完備的分布式技術(shù)方案
云原生與計(jì)算存儲(chǔ)分離
因此,CeresDB 開源項(xiàng)目發(fā)起之初,我們就將其定義為下一代的云原生時(shí)序數(shù)據(jù)庫(kù)。希望它能同時(shí)較好支持傳統(tǒng)時(shí)間序列工作負(fù)載(timeseries workload)與分析型工作負(fù)載(analytic workload),并且能擁有一個(gè)現(xiàn)代的云原生分布式技術(shù)架構(gòu),支持從簡(jiǎn)單的單節(jié)點(diǎn)到龐大分布式集群等各種部署場(chǎng)景。
這樣的設(shè)計(jì)目標(biāo),也直接決定了我們過去一年在研發(fā) CeresDB 1.0 過程中主要的精力投入方向。目前,隨著 CeresDB 1.0 的正式發(fā)布,我們認(rèn)為以上問題均得到了基本的解決。
2.
CeresDB 1.0 核心特性介紹
存儲(chǔ)引擎
支持列式混合存儲(chǔ)
高效 XOR 過濾器
云原生分布式
實(shí)現(xiàn)了計(jì)算存儲(chǔ)分離(支持 OSS 作為數(shù)據(jù)存儲(chǔ),WAL 實(shí)現(xiàn)支持 OBKV、Kafka)
支持 HASH 分區(qū)表
部署與運(yùn)維
支持單機(jī)部署
支持分布式集群部署
支持 Prometheus + Grafana 搭建自監(jiān)控
讀寫協(xié)議
支持 SQL 查詢與寫入
實(shí)現(xiàn)了 CeresDB 內(nèi)置高性能讀寫協(xié)議,提供多語(yǔ)言 SDK
支持 Prometheus,可以作為 Prometheus 的 remote storage 進(jìn)行使用
多語(yǔ)言讀寫 SDK
實(shí)現(xiàn)了四種語(yǔ)言的客戶端SDK:Java、Python、Go、Rust
3.
核心技術(shù)方案
這里簡(jiǎn)單介紹一下 CeresDB 在過去一年投入的幾個(gè)重點(diǎn)方向的技術(shù)方案。由于篇幅限制,這里僅作簡(jiǎn)要說明。本文的最后包含 CeresDB 發(fā)布會(huì)技術(shù)分享視頻,里面有更加詳細(xì)的介紹。
存儲(chǔ)引擎探索
經(jīng)典時(shí)序模型會(huì)使用倒排索引的方式對(duì)數(shù)據(jù)進(jìn)行組織。然而在某些場(chǎng)景如短生命周期 pod 監(jiān)控、業(yè)務(wù)數(shù)據(jù)監(jiān)控等,會(huì)產(chǎn)生高基數(shù)時(shí)間線,進(jìn)而導(dǎo)致倒排索引膨脹問題,寫入查詢性能會(huì)急劇變差。
寫入時(shí)由于索引的復(fù)雜性高,寫入耗時(shí)變高
查詢時(shí)由于索引的有效性低,查詢耗時(shí)變高
下圖為經(jīng)典時(shí)序模型的示意圖:
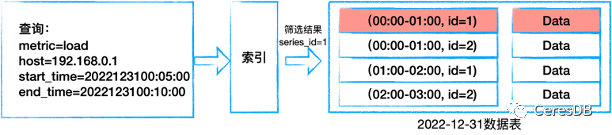
為了解決高基數(shù)的問題,CeresDB 受 InfluxDB IOx 以及各類分析型數(shù)據(jù)庫(kù)的啟發(fā),采用以下方式對(duì)時(shí)序數(shù)據(jù)進(jìn)行組織來實(shí)現(xiàn)存儲(chǔ)和查詢:
列式存儲(chǔ) + 混合存儲(chǔ)
分區(qū)掃描 + 剪枝 + 高效 fitler
下圖展示了 CeresDB 內(nèi)部的數(shù)據(jù)組織形式:

分布式方案
CeresDB 采用存儲(chǔ)計(jì)算分離架構(gòu),如下圖所示。CeresDB 實(shí)例本身可以不存儲(chǔ)任何數(shù)據(jù),在此基礎(chǔ)上可以較好實(shí)現(xiàn)關(guān)鍵的幾項(xiàng)分布式特性,比如:計(jì)算存儲(chǔ)彈性擴(kuò)縮容、服務(wù)高可用和負(fù)載均衡等等。
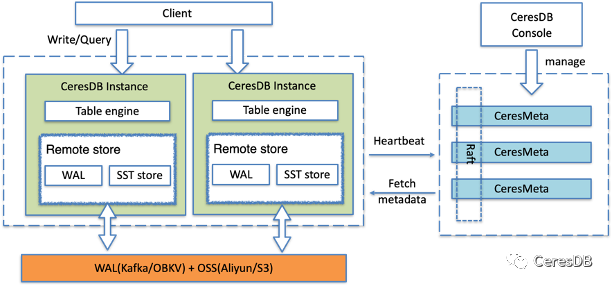
CeresDB 分布式集群主要由以下部分組成:
CeresMeta Cluster:集群的元數(shù)據(jù)中心,負(fù)責(zé)集群的整體調(diào)度;
CeresDB:一個(gè) CeresDB 實(shí)例, 負(fù)責(zé)時(shí)序數(shù)據(jù)組織與存儲(chǔ);
WAL Service(外部):WAL 服務(wù),在集群方案中,用于存儲(chǔ)實(shí)時(shí)寫入的數(shù)據(jù);
Object Storage(外部):對(duì)象存儲(chǔ)服務(wù),用于存儲(chǔ)從 memtable 生成的 SST 文件。
詳細(xì)的集群方案可以參看官方文檔(https://docs.ceresdb.io/cn/design/clustering.html)
4.
性能優(yōu)化與實(shí)驗(yàn)結(jié)果
CeresDB 組合使用了列式混合存儲(chǔ)、數(shù)據(jù)分區(qū)、剪枝、高效掃描等技術(shù),解決海量時(shí)間線(high cardinality)下寫入查詢性能變差的問題。
寫入優(yōu)化
CeresDB 采用類 LSM(Log-structured merge-tree)寫入模型,無需在寫入時(shí)處理復(fù)雜的倒排索引,因此寫入性能上較好。
查詢優(yōu)化
主要采用以下技術(shù)手段提高查詢性能:
剪枝:
min/max 剪枝:構(gòu)建代價(jià)比較低,在特定場(chǎng)景,性能較好
XOR 過濾器:提高對(duì) parquet 文件中的 row group 的篩選精度
高效掃描:
多個(gè) SST 間并發(fā):同時(shí)掃描多個(gè) SST 文件
單個(gè) SST 內(nèi)部并發(fā):支持 Parquet 層并行拉取多個(gè) row group
合并小 IO:針對(duì) OSS 上的文件,合并小 IO 請(qǐng)求,提高拉取效率
本地 cache:緩存 OSS 拉取文件,支持內(nèi)存和磁盤緩存
性能測(cè)試結(jié)果
采用 TSBS 進(jìn)行性能測(cè)試。壓測(cè)參數(shù)如下:
10個(gè) Tag
10 個(gè) Field
時(shí)間線(Tags 組合數(shù))100w 量級(jí)
壓測(cè)機(jī)器配置:24c90g
InfluxDB 版本:1.8.5
CeresDB 版本:1.0.0
寫入性能對(duì)比
InfluxDB 寫入性能隨著時(shí)間下降較多。CeresDB 在寫入穩(wěn)定后,寫入速率趨于平穩(wěn),并且總體寫入性能表現(xiàn)為 InfluxDB 的 1.5 倍以上(一段時(shí)間后可達(dá) 2 倍以上差距)
下圖中,單行 row 包含 10 個(gè) Field。
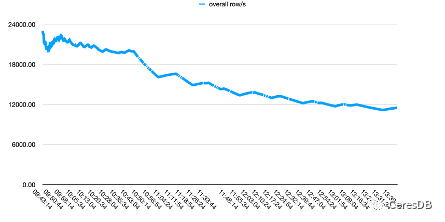
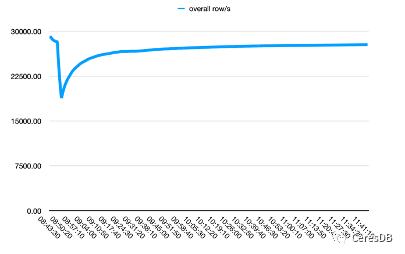
左圖為Influxdb,右圖為CeresDB
查詢性能對(duì)比
低篩選度條件(條件:os=Ubuntu15.10),CeresDB 比 InfluxDB 快 26 倍,具體數(shù)據(jù)如下:
CeresDB 查詢耗時(shí):15s
InfluxDB 查詢耗時(shí):6m43s
高篩選度條件(命中的數(shù)據(jù)較少,條件:hostname=[8個(gè)],此時(shí)理論上傳統(tǒng)倒排索引會(huì)更有效),這是 InfluxDB 更有優(yōu)勢(shì)的場(chǎng)景,此時(shí)在預(yù)熱完成條件下,CeresDB 比 InfluxDB 慢 5 倍。
CeresDB:85ms
InfluxDB:15ms
5.
2023 年 roadmap
2023 年,在 CeresDB 1.0 發(fā)布之后,我們的大部分工作將聚焦在性能、分布式與周邊生態(tài)方面的工作。尤其周邊生態(tài)的對(duì)接支持工作,希望能讓各種不同的用戶更加簡(jiǎn)單的用上 CeresDB:
周邊生態(tài)
生態(tài)兼容,包括 PromQL、InfluxdbQL、OpenTSDB 等常用時(shí)序數(shù)據(jù)庫(kù)協(xié)議兼容
運(yùn)維工具支持,包括 k8s 支持、CeresDB 運(yùn)維系統(tǒng)、自監(jiān)控等
開發(fā)者工具,包括數(shù)據(jù)導(dǎo)入導(dǎo)出等
性能
探索新的存儲(chǔ)格式
增強(qiáng)不同類型索引,強(qiáng)化 CeresDB 在不同工作負(fù)載下的表現(xiàn)
分布式
自動(dòng)負(fù)載均衡
提高可用性、可靠性
6.
加入我們
CeresDB 團(tuán)隊(duì)致力于將開源社區(qū)打造成一個(gè)開放和有創(chuàng)造力的社區(qū)。歡迎任何形式的參與,包括且不限于提問、代碼貢獻(xiàn)、技術(shù)討論等。期待收到社區(qū)想法和反饋,以推動(dòng)項(xiàng)目往前進(jìn)一步發(fā)展。
微信群:
釘釘群: