
使用Redis來做緩存,你該知道的!
一、緩存一些知識
1.1、緩存擊穿、緩存穿透、緩存雪崩是什么?
緩存擊穿
用戶請求的某個key在DB或者緩存中存在,但是可能正好在當這個key在緩存中到達了失效時間而過期,而此時大量訪問該數(shù)據請求過來,相當于在緩存中鑿開一個缺口,一下子全部打在DB上,造成DB壓力壓垮DB。

緩存穿透
用戶通過請求一些緩存和DB中壓根都不存在的數(shù)據,致使每次請求都會繞過緩存,請求DB,給DB帶來壓力
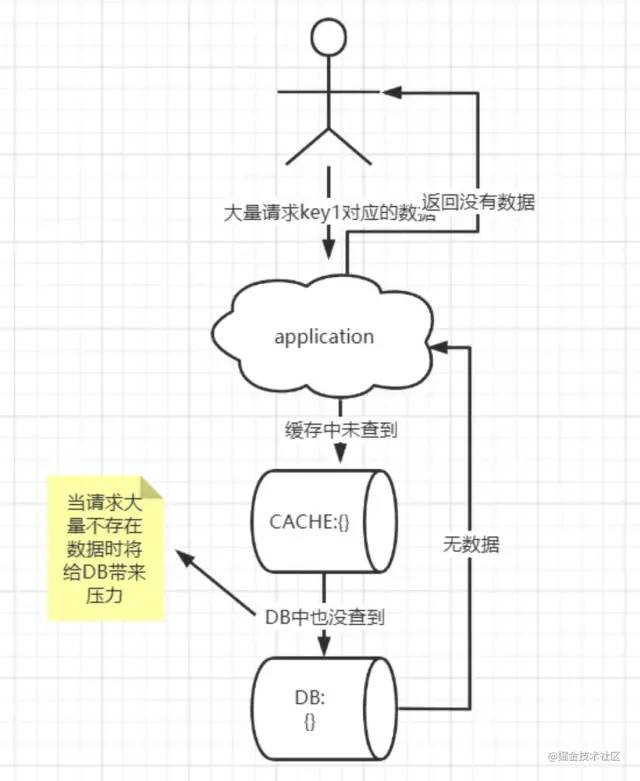
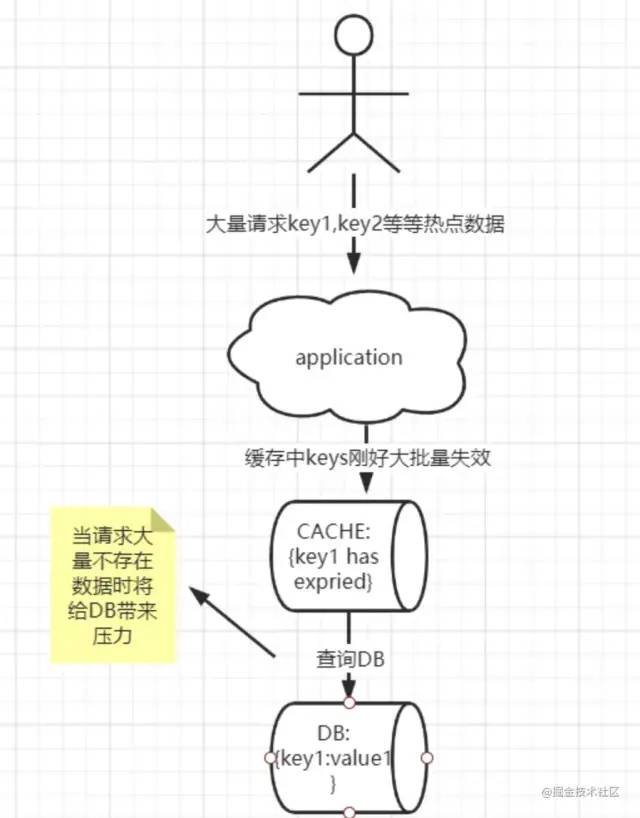
緩存雪崩
當緩存服務器重啟或者大量緩存的keys過期失效,導致客戶端過來的請求全部直接請求到DB中,造成DB壓力大而崩潰(注意這里和緩存擊穿不同的是緩存擊穿是單個key失效引起,而雪崩是大量key失效)
1.2 應對緩存擊穿
1)互斥鎖訪問數(shù)據
針對某一熱點數(shù)據,在獲取時可通過加互斥鎖使得只有一個請求進行處理訪問DB,并將數(shù)據放置到緩存中,后續(xù)阻塞的請求將直接命中緩存。
2)設置熱點數(shù)據永不過期
1.3 應對緩存穿透
加強接口入參校驗。將不合法入參抹殺在搖籃中
如果未查出數(shù)據,可賦予緩存中對應key一個null值,并設置一個過期時間,防止單位時間內大量請求訪問DB。因為設置了過期時間,所以可以保證后續(xù)該key有值了,可以獲取到。
1.4 應對緩存雪崩
1)設置緩存過期時間時,加上隨機時間戳
這樣做的好處就是盡量使得緩存key們的過期時間均勻分散,不至于在同一個時間點大面積緩存過期失效引起雪崩
2)不設置緩存過期時間
3)分布式緩存服務器部署的情況下,可以將熱點數(shù)據分散在不同的緩存服務器中
二、redisLRU緩存機制
2.1 Redis內存淘汰機制
LRU是Least Recently Used的縮寫,即最近最少使用,是一種常用的頁面置換算法,選擇最近最久未使用的頁面予以淘汰。該算法賦予每個頁面一個訪問字段,用來記錄一個頁面自上次被訪問以來所經歷的時間 t,當須淘汰一個頁面時,選擇現(xiàn)有頁面中其 t 值最大的,即最近最少使用的頁面予以淘汰。----- 摘自百度百科
LRU緩存那就是將最近最少訪問的緩存剔除。redis針對LRU機制提供了實現(xiàn)支持。redis在redis.conf中提供了配置選項maxmemory 來配置執(zhí)行大小的內存數(shù)據集。或者在服務器運行時,可在客戶端通過CONFIG SET進行設置。
maxmemory 100mb
復制代碼如果設置為0,那么則表示內存不受限制。當往redis中存放值時,達到我們指定的maxmemory值時,redis提供了多種不同的剔除值策略。可以通過在redis.conf中配置策略
noeviction xxx
復制代碼noeviction(default)
即當達到maxmemory內存限制時,不做數(shù)據剔除,直接返回錯誤
allkeys-lru
即當達到maxmemory內存限制時,刪除最近最少使用的key以保證新的值可以添加進來
volatile-lru
即當達到maxmemory內存限制時,刪除最近最少使用并且通過expire設置了過期時間的key,以保證新的值可以添加進來
allkeys-random
即當達到maxmemory內存限制時,隨機刪除一些key以保證新的值可以添加進來
volatile-random
即當達到maxmemory內存限制時,隨機刪除一些設置了過期時間的key以保證新的值可以添加進來
volatile-ttl
即當達到maxmemory內存限制時,刪除一些設置了過期時間并且TTK所剩時間最短的keys以保證新的值可以添加進來
其中volatile-lru、volatile-random、volatile-ttl如果沒有滿足條件的key可以進行刪除,那么它們的行為就和noeviction策略一樣。剔除策略也可以在運行時進行設置。
2.2 Redis LRU淘汰機制精確度
在redis3.0之后,redis針對之前近似LRU算法進行了性能上的改進提升,以及使得LRU算法更加接近準確。通過配置參數(shù)maxmemory-samples可以調整樣本的數(shù)量來為LRU算法獲取精度。注意redis的LRU算法并不是LRU真正具體的實現(xiàn),因為那很耗費內存。但是其實redis計算出的近似值于真實算法值是很相近的。
maxmemory-samples 5
復制代碼
從上述Redis官方給的測試數(shù)據可以看出,同樣樣本數(shù)未5,redis3.0要比之前好一點,當提高樣本數(shù)之后,更加的好一點,但是與真實LRU算法實現(xiàn)還是差點火候。
我們可以以額外的CPU使用為代價將樣本大小增加到10,以接近真實的LRU,并檢查這是否會對緩存漏報率產生影響。
在生產環(huán)境中,很容易通過CONFIG SET maxmemory-samples 命令來設置不同的樣本值進行實驗。
三、Redis結合Spring Cache Abstraction實現(xiàn)緩存
spring cache abstraction的更多使用spring知識之Spring Cache Abstraction的使用
實現(xiàn)緩存的思想其實并不復雜,簡單點說,就是查詢先從緩存服務器中查詢,如果查詢到則立即返回,否則再去DB中查詢返回然后再放至到緩存當中;;在對數(shù)據進行更新操作時,操作DB成功以后,在決定緩存的更新策略(更新緩存or刪除緩存)。
3.1 配置RedisCacheManager
spring-data-redis提供了spring抽象緩存的實現(xiàn),為了借助于spring cache實現(xiàn)緩存,我們需要加載一個RedisCacheManager。
@Bean
public RedisCacheManager cacheManager(RedisConnectionFactory connectionFactory) {
return RedisCacheManager.create(connectionFactory);
}
復制代碼通過RedisCacheManager.create創(chuàng)建出的是默認配置的RedisCacheManager,如果我們想設置一些事務或者預定義緩存則可通過builder進行構建。
3.1.1 自定義緩存配置RedisCacheConfiguration
RedisCacheConfiguration配置類,可以用來配置比如設置緩存key的過期時間、是否緩存null值、是否啟用key前綴、以及key和value緩存過程中二進制數(shù)據 的序列化策略。
基本配置
// 默認緩存配置
RedisCacheConfiguration redisCacheConfiguration = RedisCacheConfiguration.defaultCacheConfig();
// 設置緩存key失效時間為2分鐘
redisCacheConfiguration.entryTtl(Duration.ofMinutes(2));
// 禁用緩存null值(默認為啟用)
redisCacheConfiguration.disableCachingNullValues();
// 禁用設置key前綴(默認為啟用)
redisCacheConfiguration.disableKeyPrefix();
// 設置key前綴
redisCacheConfiguration.prefixCacheNameWith("miaomiao:");
復制代碼key,value序列化策略
RedisCacheConfiguration默認key的序列化器是StringRedisSerializer,value的序列化器是JdkSerializationRedisSerializer
3.2 代碼實操Srping Cache Abstranction
大致貼下各層demo。
entity(注意需要序列化)
@Entity
@Table(name = "user")
public class UserInfo implements Serializable {
@Id
@Column(name = "user_id")
private int userId;
@Column(name = "user_name")
private String userName;
get set 省略。。。
}
復制代碼Dao
@Repository
public interface UserInfoRepository extends JpaRepository<UserInfo,Integer> {
}
復制代碼Service
public interface UserInfoService {
Optional<UserInfo> getUserInfo(int userId);
}
復制代碼@Service
public class UserInfoServiceImpl implements UserInfoService {
@Autowired
private UserInfoRepository userInfoRepository;
@Override
@Cacheable("user")
public Optional<UserInfo> getUserInfo(int userId) {
System.out.println("發(fā)生了真實調用!!!");
return userInfoRepository.findById(userId);
}
}
復制代碼config(注意@EnableCaching啟用緩存)
@Configuration
@EnableCaching
public class RedisCacheConfig {
@Bean
public RedisCacheManager cacheManager(RedisConnectionFactory redisConnectionFactory) {
// 默認緩存配置
RedisCacheConfiguration redisCacheConfiguration = RedisCacheConfiguration.defaultCacheConfig();
// 設置緩存key失效時間為2分鐘
redisCacheConfiguration.entryTtl(Duration.ofMinutes(2));
// 禁用緩存null值(默認為啟用)
redisCacheConfiguration.disableCachingNullValues();
return RedisCacheManager.builder(redisConnectionFactory).cacheDefaults(redisCacheConfiguration).build();
}
}
復制代碼Test 以及輸入
@SpringBootTest
public class UserInfoServiceImplTest {
@Autowired
private UserInfoService userInfoService;
@Test
public void getUserInfo() {
System.out.println("=========start1===========");
System.out.println(userInfoService.getUserInfo(1));
System.out.println("==========end1==========");
System.out.println("=========start2===========");
System.out.println(userInfoService.getUserInfo(1));
System.out.println("==========end2==========");
}
}
復制代碼=========start1===========
發(fā)生了真實調用!!!
Hibernate: select userinfo0_.user_id as user_id1_0_0_, userinfo0_.user_name as user_nam2_0_0_ from user userinfo0_ where userinfo0_.user_id=?
Optional[UserInfo{userId=1, userName='cf'}]
==========end1==========
=========start2===========
Optional[UserInfo{userId=1, userName='cf'}]
==========end2==========
復制代碼3.3 小結
從上述測試輸出我們可以看出,在第一次進行調用(緩存中未存放相關值時,發(fā)生了真實調用,查庫,然后返回結果),而第二次因為在第一次調用的基礎上,緩存中已經有了值,所以直接將緩存結果返回,完全未觸發(fā)真實的方法邏輯,所以這里也是很需要注意的地方,如果不太了解,只是跟著網上demo去使用,則可能發(fā)生將其他業(yè)務邏輯包雜在上述方法中,造成有緩存清空未調用導致bug等。
四、如何保障緩存DB一致性以及分布式數(shù)據一致性?
4.1 緩存和DB數(shù)據不一致場景(或者說誘因)
1)緩存和DB的操作不在一個事務中進行,很可能緩存的操作和DB的操作其中一個成功一個失敗,導致數(shù)據不一致。2)多線程對緩存進行更新操作時,可能導致舊數(shù)據被更新至緩存中。
4.2 Cache Aside Pattern
當緩存失效時
即讀緩存,未命中,則從數(shù)據庫中取,成功之后將數(shù)據放到緩存中
當緩存命中時
即讀緩存,若命中,則成功返回
當數(shù)據更新時
先更新數(shù)據庫,然后刪除緩存
著重與最后一條,當數(shù)據發(fā)生變化時,針對緩存如何進行處理?可能有以下幾種情況:
先更新緩存,再更新數(shù)據庫
此方案如果說更新數(shù)據庫的時候,數(shù)據庫宕機導致DB更新失敗,造成了數(shù)據不一致
先更新數(shù)據庫,再更新緩存
此方案主要存在兩個問題:1).假如線程A先更新了數(shù)據,然后準備做更新數(shù)據庫,更新緩存的操作,此時線程B也更新了相同的數(shù)據,更新數(shù)據庫更新緩存。按道理線程B的數(shù)據應該是最新的,但是因為多線程的時序問題,很可能最終緩存被更新成了舊值。2).并不是所有緩存是熱點數(shù)據,有可能此緩存不會被經常讀取,而如果每次更新數(shù)據的時候,都要去更新一下緩存,就造成了不必要的性能和內存消耗。
先刪除緩存,再更新數(shù)據庫
developer.aliyun.com/article/712… 強推!!!!
參考文檔
[1].docs.spring.io/spring-data…
[2].docs.spring.io/spring/docs…
[3].juejin.cn/post/684490…
作者:我有一只喵喵
鏈接:https://juejin.cn/post/6996820141405274142
來源:掘金
著作權歸作者所有。商業(yè)轉載請聯(lián)系作者獲得授權,非商業(yè)轉載請注明出處。