
深度學習中目標檢測
點擊上方“小白學視覺”,選擇加"星標"或“置頂”
重磅干貨,第一時間送達

本文轉(zhuǎn)自|AI算法與圖像處理
該部分內(nèi)容出自書《21個項目玩轉(zhuǎn)深度學習:基于TensorFlow的實踐詳解》,有需要的同志可以關(guān)注我的公眾號,加入下發(fā)的群,在群公告中有附網(wǎng)盤,可以自取(僅供學習使用)。如果失效可以聯(lián)系或者在公眾號留言!!!
深度學習中目標檢測的原理
R-CNN 的全稱是 Region-CNN,它可以說是第一個成功地將深度學習應用到目標檢測上的算法 。 后面將要學習的 Fast R-CNN、 Faster R-CNN 全部都是建立在 R-CNN 基礎(chǔ)上的 。
傳統(tǒng)的目標檢測方法大多以圖像識別為基礎(chǔ)。 一般可以在圖片上使用窮
舉法選出所高物體可能出現(xiàn)的區(qū)域框,對這些區(qū)域框提取特征并使用圄像識
別萬法分類, 得到所高分類成功的區(qū)域后 , 通過非極大值抑制( Non-maximum suppression )輸出結(jié)果 。
R-CNN遵循傳統(tǒng)目標檢測的思路 , 同樣采用提取框 、 對每個框提取特征 、 圖像分類、 非極大值抑制四個步驟進行目標檢測。 只不過在提取特征這一步,將傳統(tǒng)的特征(如 SIFT 、 HOG 特征等)換成了深度卷積網(wǎng)絡(luò)提取的特征 。 R-CNN 的整體框架如圖 5-2 所示 。
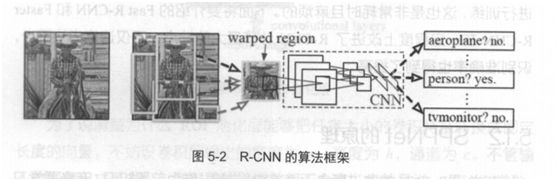
對比:
對于原始圖像 , 首先使用 SelectiveSearch 搜尋可能存在物體的區(qū)域 。
Selective Search 可以從圖像中啟發(fā)式地搜索出可能包含物體的區(qū)域。 相比窮舉而言, Selective Search 可以減少一部分計算量 。 下一步,將取出的可能含
高物體的區(qū)域送入 CNN 中提取特征 。 CNN 通常是接受一個固定大小的圖像,而取出的區(qū)域大小卻各高不同 。對此, R-CNN的做法是將區(qū)域縮放到統(tǒng)一大小 , 再使用 CNN提取特征 。 提取出特征后使用 SVM 進行分類,最后通過非極大值抑制輸出結(jié)果 。
R-CNN的訓練、可以分成下面四步:
1)在數(shù)據(jù)集上訓練 CNN 。 R-CNN 論文中使用的 CNN 網(wǎng)絡(luò)是 AlexNet,數(shù)據(jù)集為 ImageNet 。
2)在目標檢測的數(shù)據(jù)集上,對訓練好的 CNN司做微調(diào) 。
3)用 Selective Search 搜索候選區(qū)域,統(tǒng)一使用微調(diào)后的 CNN對這些區(qū)域提取特征,并將提取到的特征存儲起來。
4)使用存儲起來的特征 ,訓練 SVM 分類器 。
盡管 R-CNN 的識別框架與傳統(tǒng)方法區(qū)別不是很大,但是得益于 CNN 優(yōu)異的特征提取能力, R-CNN 的效果還是比傳統(tǒng)方法好很多。 如在 VOC 2007數(shù)據(jù)集上,傳統(tǒng)方法最高的平均精確度 mAP ( mean Average Precision )為40%左右,而 R-CNN 的 mAP 達到了 58.5%!
R-CNN 的缺點是計算量太大 。 在一張圖片中,通過 Selective Search 得
到的有效區(qū)域往往在 1000 個以上,這意昧著要重復計算 1000 多次神經(jīng)網(wǎng)絡(luò) ,非常耗時 。另外,在訓練、階段,還需要把所有特征保存起來 ,再通過 SVM進行訓練,這也是非常耗時且麻煩的。Fast R-CNN 和 FasterR-CNN 在一定程度上改進了 R-CNN 計算量大的缺點,不僅速度變快不少,識別準確率也得到了提高 。

具體的實現(xiàn)書中有詳細說明
下面放上一些檢測的代碼


Faster –RCNN的檢測效果


交流群
歡迎加入公眾號讀者群一起和同行交流,目前有SLAM、三維視覺、傳感器、自動駕駛、計算攝影、檢測、分割、識別、醫(yī)學影像、GAN、算法競賽等微信群(以后會逐漸細分),請掃描下面微信號加群,備注:”昵稱+學校/公司+研究方向“,例如:”張三 + 上海交大 + 視覺SLAM“。請按照格式備注,否則不予通過。添加成功后會根據(jù)研究方向邀請進入相關(guān)微信群。請勿在群內(nèi)發(fā)送廣告,否則會請出群,謝謝理解~