
手把手教你使用XPath爬取免費代理IP
點擊上方“Python爬蟲與數(shù)據(jù)挖掘”,進(jìn)行關(guān)注
回復(fù)“書籍”即可獲贈Python從入門到進(jìn)階共10本電子書
大家好,我是霖hero。
前言
可能有人說,初學(xué)者Python爬蟲爬數(shù)據(jù)太難啦,構(gòu)造正則表達(dá)式的時候,太煩瑣了,眼睛都看花了,而且前一秒還可以愉快地爬取,下一秒IP就被封了,這還爬個屁啊,不爬了。哎,不要著急,這篇文章我們教你如何使用XPath來爬取快代理中的免費代理IP,告別眼花,告別IP被封的煩惱。
XPath
首先我們來簡單了解一下XPath,想要了解更多XPath,我們可以打開W3school官方文檔進(jìn)行了解。
什么是 XPath?
XPath是XML路徑語言(XML Path Language); XPath 使用路徑表達(dá)式在 XML 文檔中進(jìn)行導(dǎo)航; XPath 包含一個標(biāo)準(zhǔn)函數(shù)庫; XPath 是 XSLT 中的主要元素; XPath 是一個 W3C 標(biāo)準(zhǔn);
XPath作用是什么?
XPath用來確定XML文檔中某部分位置的語言 XPath在XML文檔中查找信息的語言 XPath用于在XML文檔中通過元素和屬性進(jìn)行導(dǎo)航。
XPath 含有超過 100 個內(nèi)建的函數(shù)。這些函數(shù)用于字符串值、數(shù)值、日期和時間比較、節(jié)點和 QName 處理、序列處理、邏輯值等等。在Python爬蟲中,我們完成可以使用XPath來做相應(yīng)的信息抽取。
XPath——常用規(guī)則
簡單了解一下XPath后,我們來看看它的常用規(guī)則,如下表:
| 表達(dá)式 | 描述 |
|---|---|
| nodename | 選取此節(jié)點的所有子節(jié)點 |
| / | 從根節(jié)點選取 |
| // | 從匹配選擇的當(dāng)前節(jié)點選擇文檔中的節(jié)點,而不考慮它們的位置 |
| . | 選取當(dāng)前節(jié)點 |
| .. | 選取當(dāng)前節(jié)點的父節(jié)點 |
| @ | 選取屬性 |
我們來簡單說一個示例:
//title[@*]
這就是一個XPath規(guī)則,它代表選擇選取所有帶有屬性的 title 元素。
好了,大概了解了XPath的常用規(guī)則和用法了,我們來添加一個Chrome瀏覽器的小插件——XPath Helper,這個小插件可以大大提高了我們使用XPath的效率。
XPath Helper的添加與使用
XPath Helper的添加
首先打開Chrome商店搜索XPath Helper,如下圖所示:
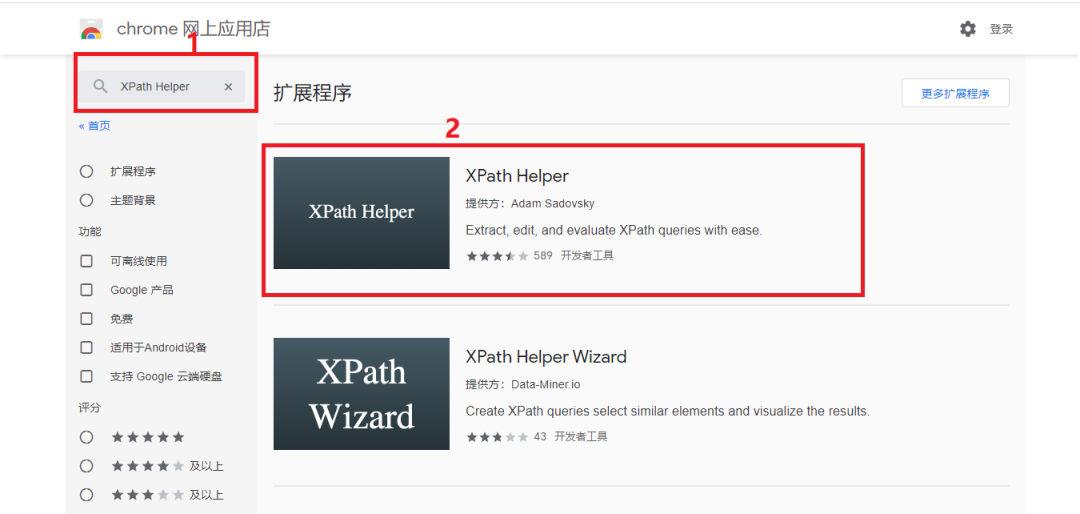
點擊方框2,將插件添加至Chrome中,如下圖所示:
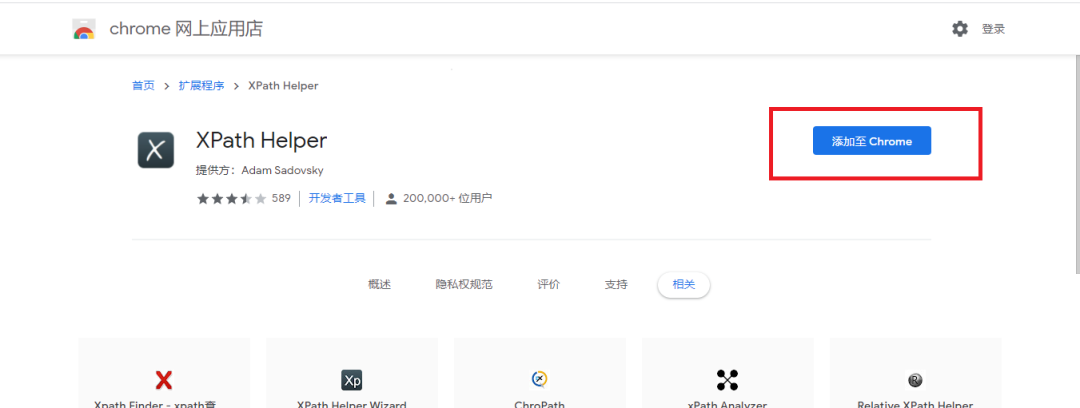
這里我們推薦點擊下圖的小圖釘,更方便我們使用XPath Helper插件
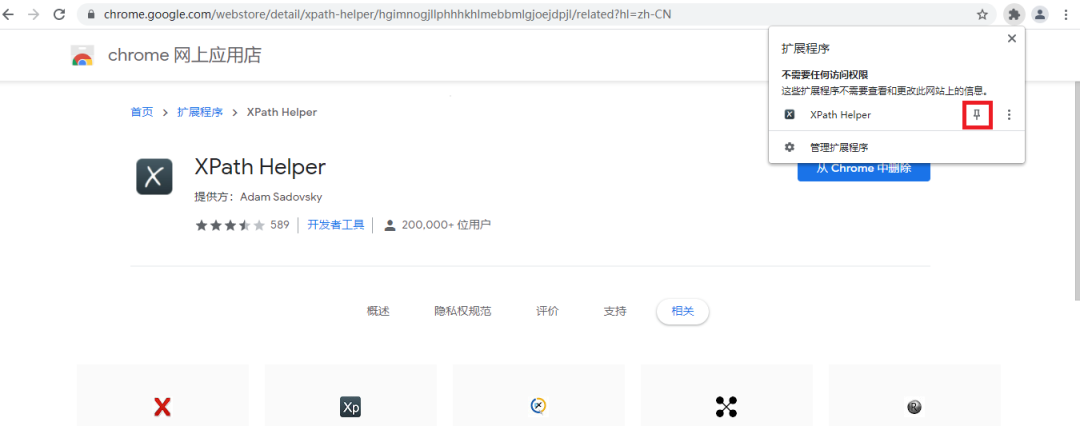
這樣XPath Helper插件就添加完畢了,接下來我們簡單演示一下如何使用該插件。
XPath Helper的使用
首先我們打開今天要爬取的快代理網(wǎng)站并打開開發(fā)者工具,找到我們要爬取內(nèi)容的節(jié)點,如下圖所示:
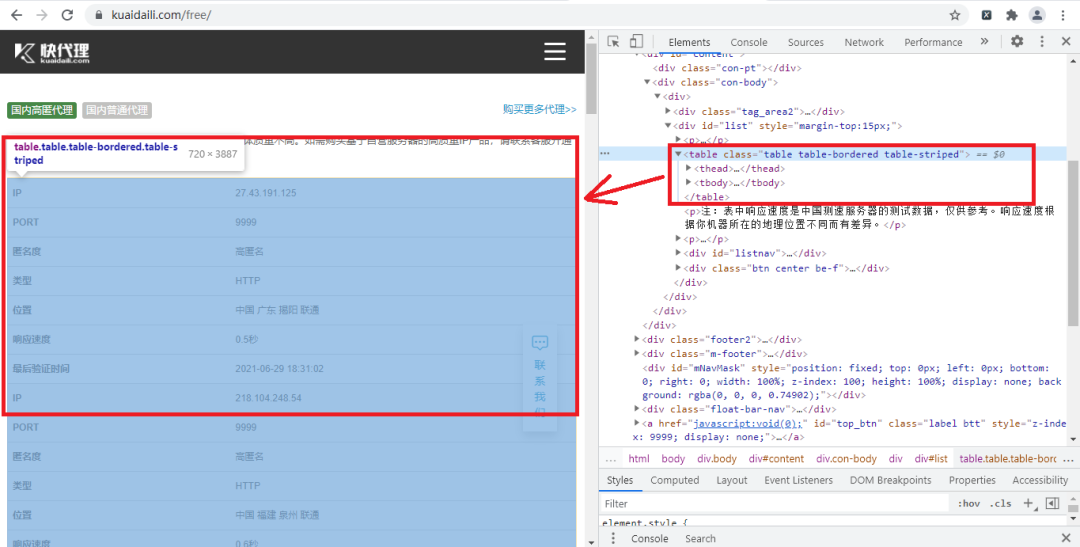
然后打開我們添加的插件,并輸入XPath規(guī)則,如下圖所示:
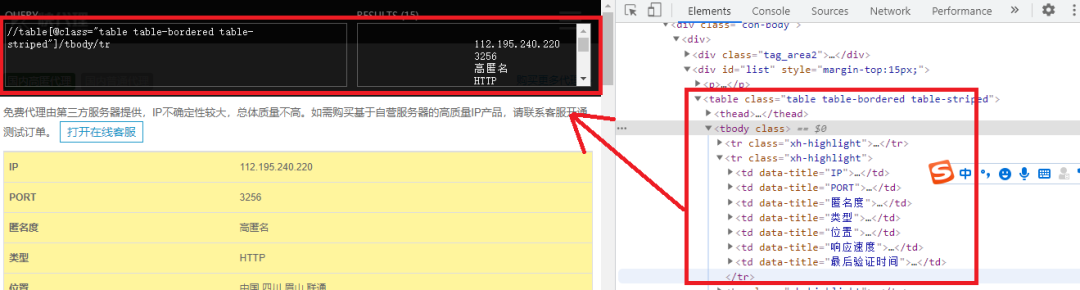
我們根據(jù)了table節(jié)點信息,來構(gòu)造了XPath規(guī)則,輸入XPath規(guī)矩可以直接看到返回的是什么,這樣我們就不需要每構(gòu)成一次就在程序里運行看看能不能返回我們想要的值,這樣大大提高我們的效率。
實戰(zhàn)演練
爬取首頁
我們首先打開快代理免費代理網(wǎng)站并打開開發(fā)者工具,如下圖所示:
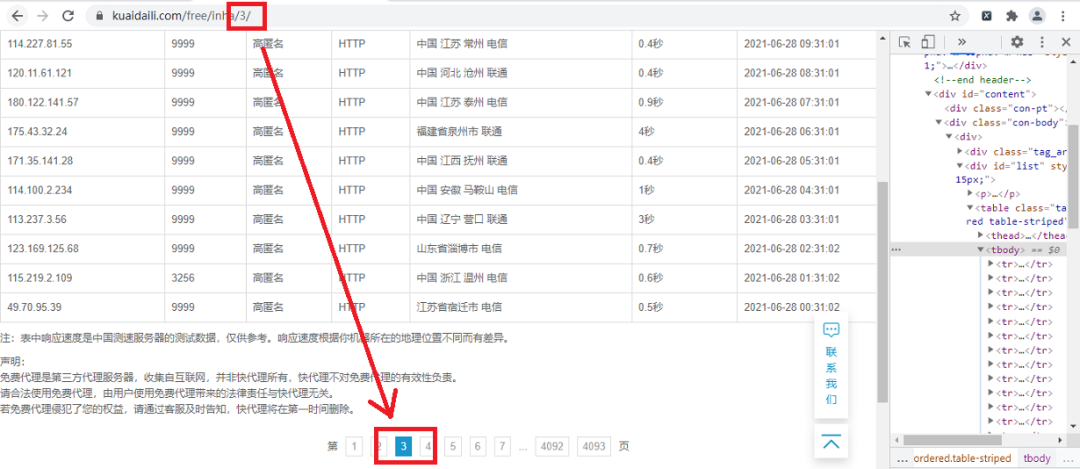
通過觀察可以發(fā)現(xiàn),頁面的URL最后的那個數(shù)字就是頁碼,也就是我們進(jìn)行翻頁的重要參數(shù),這里我們使用了page變量為我們翻頁的參數(shù),具體代碼如下:
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.106 Safari/537.36'
}
def get_page(page):
url='https://www.kuaidaili.com/free/inha/'+str(page)
response=requests.get(url,headers=headers)
#數(shù)據(jù)類型轉(zhuǎn)換
html = parsel.Selector(response.text)
parse_page(html)
首先我們構(gòu)造了一個請求頭,然后定義了一個get_page()方法,這里要注意的是,當(dāng)我們獲取了請求頁面的文本數(shù)據(jù)時,要進(jìn)行數(shù)據(jù)類型的轉(zhuǎn)換,轉(zhuǎn)換為XPath可以查找信息的HTML文本,也就是創(chuàng)建了一個parsel.Selector對象,轉(zhuǎn)換后,我們就調(diào)用parse_page()方法,并傳入html參數(shù)。
XPath規(guī)則提取內(nèi)容
我們已經(jīng)成功提取了網(wǎng)頁的HTML文本,接下來我們開始利用XPath規(guī)則來提取想要的內(nèi)容,首先我們要確定XPath規(guī)則提取內(nèi)容的范圍,如下圖所示:
從圖中我們可以看到table節(jié)點里包含我們要提取內(nèi)容,然后我們使用XPath Helper插件來方便我們確定是否能準(zhǔn)確提取目標(biāo)內(nèi)容,如下圖所示:
圖中的方框就是我們要提取內(nèi)容的范圍,確定范圍后,我們確定提取內(nèi)容對應(yīng)的XPath規(guī)則,如下圖所示:
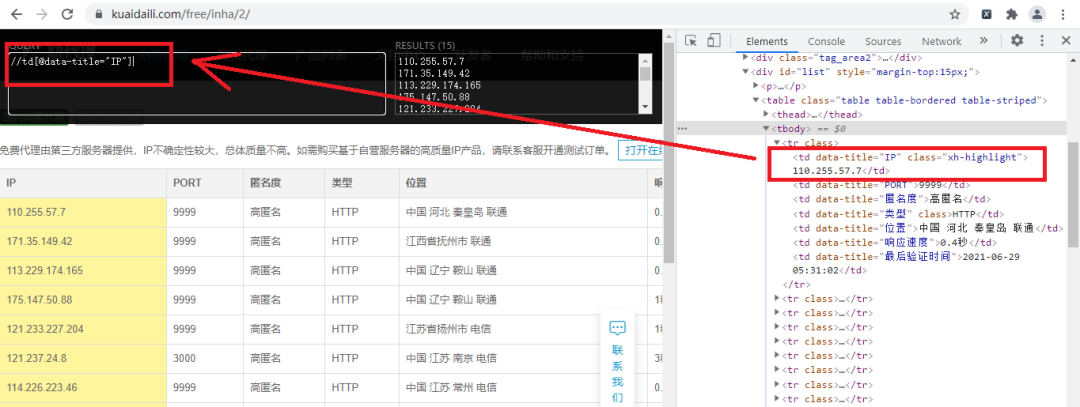
好了,我們成功提取到了IP地址,經(jīng)過觀察,我們只要把圖中左上角的方框中IP改為PORT,這樣就可以提取到了端口號了,具體實現(xiàn)代碼如下:
def parse_page(html):
#XPath的匹配范圍
parse_list = html.xpath('//table[@class="table table-bordered table-striped"]/tbody/tr')
for tr in parse_list:
parse_lists = {}
http=tr.xpath('./td[@data-title="類型"]//text()').extract_first()
num=tr.xpath('./td[@data-title="IP"]//text()').extract_first()
port=tr.xpath('./td[@data-title="PORT"]//text()').extract_first()
parse_lists[http]=num+':'+port
time.sleep(0.1)
print(parse_lists)
要注意的是:
我們在構(gòu)造XPath規(guī)則時,如://td[@data-title="IP"],我們要將最前面的/改為.,否則只匹配頁面的第一個內(nèi)容; 在XPath規(guī)則中,通過使用text()方法獲取節(jié)點內(nèi)部的文本,如在規(guī)則后面加//text(); 調(diào)用extract_first()返回的是一個string字符串,是list數(shù)組里面的第一個字符串。
最后我們通過構(gòu)造一個parse_lists字典,來使我們的數(shù)據(jù)更好看。
循環(huán)遍歷
我們使用一個for循環(huán),來遍歷翻頁,具體代碼為:
if __name__ == '__main__':
for page in range(1,3):
get_page(page)
好了,這樣我們就成功爬取了快代理的免費代理IP的前兩頁,我們可以根據(jù)需要來進(jìn)行保存免費代理IP。
結(jié)果展示
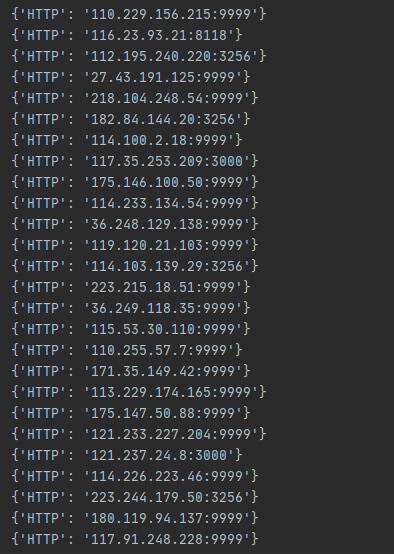
代碼獲取
------------------- End -------------------
往期精彩文章推薦:

歡迎大家點贊,留言,轉(zhuǎn)發(fā),轉(zhuǎn)載,感謝大家的相伴與支持
想加入Python學(xué)習(xí)群請在后臺回復(fù)【入群】
萬水千山總是情,點個【在看】行不行
/今日留言主題/
隨便說一兩個吧~