
一文看懂阿里、京東、滴滴大數(shù)據(jù)架構(gòu)變遷
↓推薦關(guān)注↓
大數(shù)據(jù)的概念從上世紀(jì)90年代被提出,03-06年Google的3篇經(jīng)典論文(GFS、MapReduce、Bigtable)作為奠基,Hadoop等優(yōu)秀系統(tǒng)的出現(xiàn)使之繁榮,經(jīng)歷了十余年的時(shí)間。
從Gartner Hype Cycle這一行業(yè)技術(shù)發(fā)展的趨勢(shì)圖看,大數(shù)據(jù)從2011年進(jìn)入該圖譜,2014年被標(biāo)記為進(jìn)入衰退期,2015年開(kāi)始不再標(biāo)注,確實(shí)反映了這一概念經(jīng)歷了從不切實(shí)際的幻想期,到泡沫期,到衰退和成熟期的整個(gè)過(guò)程。目前來(lái)看,這一領(lǐng)域的技術(shù)已經(jīng)相對(duì)穩(wěn)定和成熟,各類應(yīng)用已確實(shí)產(chǎn)生價(jià)值,使其成為了一種普惠性質(zhì)的技術(shù)。
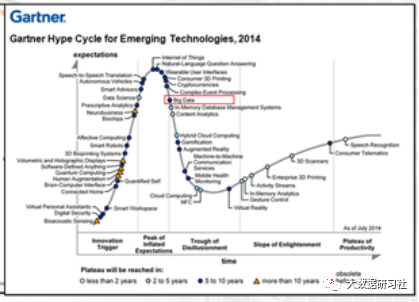
從主要互聯(lián)網(wǎng)企業(yè)大數(shù)據(jù)技術(shù)棧的變遷,我們可以得到如下結(jié)論:
1、數(shù)據(jù)規(guī)模會(huì)繼續(xù)擴(kuò)大,數(shù)據(jù)價(jià)值會(huì)進(jìn)一步挖掘
隨著IOT技術(shù)的發(fā)展和成熟,5G的逐步推廣,上游產(chǎn)生的數(shù)據(jù)量仍會(huì)快速增長(zhǎng),海量數(shù)據(jù)的采集、存儲(chǔ)、處理技術(shù)仍有提升空間。
對(duì)于下游產(chǎn)業(yè)應(yīng)用,則會(huì)進(jìn)一步挖掘數(shù)據(jù)的價(jià)值,目前還有很多金礦沒(méi)有開(kāi)采。
2、數(shù)據(jù)實(shí)時(shí)性需求將進(jìn)一步增加
大數(shù)據(jù)誕生之初的目的是做海量數(shù)據(jù)的離線處理,包括離線的數(shù)據(jù)倉(cāng)庫(kù)、報(bào)表等應(yīng)用。隨著近幾年軟硬件檔次的提升,大規(guī)模數(shù)據(jù)的離線處理已經(jīng)難度不大,新的挑戰(zhàn)在于各種實(shí)時(shí)應(yīng)用,這其中又包括了實(shí)時(shí)采集、實(shí)時(shí)計(jì)算、實(shí)時(shí)可視化、在線機(jī)器學(xué)習(xí)等多個(gè)領(lǐng)域。
3、底層技術(shù)集中化,上層應(yīng)用全面開(kāi)花
從前面的大數(shù)據(jù)技術(shù)棧圖可以看到,大數(shù)據(jù)領(lǐng)域各種組件和技術(shù)繁多,更新也非常快。但近幾年包括頭部互聯(lián)網(wǎng)企業(yè)也都將底層技術(shù)進(jìn)行集中,如批處理領(lǐng)域的Spark,消息隊(duì)列領(lǐng)域的Kafka幾乎成為事實(shí)的標(biāo)準(zhǔn),我們預(yù)計(jì)每一個(gè)細(xì)分領(lǐng)域的組件都會(huì)集中到1-2個(gè)上來(lái)。
與此相反,上層應(yīng)用層面則百花齊放,大互聯(lián)網(wǎng)公司幾乎所有產(chǎn)品都包含大數(shù)據(jù)元素,某些垂直領(lǐng)域也出現(xiàn)了專業(yè)性公司,如專門做BI的、專門做AI產(chǎn)品的。可以預(yù)見(jiàn)今后的創(chuàng)新主要都將集中在應(yīng)用層面。
4、公有云和私有云并存
在國(guó)外,公有云上的大數(shù)據(jù)服務(wù)已經(jīng)基本普及。但在國(guó)內(nèi),由于各企業(yè)所在領(lǐng)域不同,對(duì)數(shù)據(jù)安全性標(biāo)準(zhǔn)不同,并且互聯(lián)網(wǎng)行業(yè)存在惡性競(jìng)爭(zhēng)情況,短期內(nèi)大多數(shù)企業(yè)仍傾向于以本地機(jī)房方式來(lái)部署大數(shù)據(jù)的基礎(chǔ)設(shè)施。無(wú)論采用哪種方式,未來(lái)的大數(shù)據(jù)技術(shù)棧都會(huì)朝著容器化、存儲(chǔ)計(jì)算分離、跨機(jī)房跨地域部署的方向發(fā)展。?
飛天大數(shù)據(jù)平臺(tái)始于2009年阿里巴巴的“登月”計(jì)劃,目前已經(jīng)在阿里云內(nèi)部實(shí)際運(yùn)行和服務(wù)了十年之久(大家過(guò)去更為熟悉的 MaxCompute 是飛天系統(tǒng)的三大件之一,也是如今飛天大數(shù)據(jù)平臺(tái)的核心)。如今飛天大數(shù)據(jù)平臺(tái)在阿里巴巴經(jīng)濟(jì)體中支撐99%的數(shù)據(jù)存儲(chǔ)和99%的計(jì)算力,單日數(shù)據(jù)處理量超過(guò)600PB,也是阿里AI技術(shù)最重要的基礎(chǔ)設(shè)施之一。
歷史
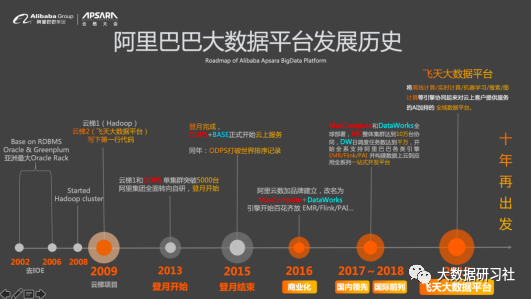
2009 年,阿里啟動(dòng)“云梯”計(jì)劃,當(dāng)時(shí)有兩條技術(shù)路線同步進(jìn)行,分別是開(kāi)源的Hadoop和自研的ODPS(也就是今天的MaxCompute)。當(dāng)時(shí)阿里已經(jīng)下定決心要開(kāi)始去IOE并構(gòu)建自己的大數(shù)據(jù)平臺(tái),但還沒(méi)有決定好是走開(kāi)源路線還是自研路線,因此就有了云梯1(Hadoop)和云梯2(ODPS)的并行。2013年,兩個(gè)平臺(tái)先后突破單集群5000臺(tái)服務(wù)器。最終從深度技術(shù)把控力和極致性能優(yōu)化的角度,決定采用云梯2。同年,“登月”項(xiàng)目正式啟動(dòng)。
在“登月”項(xiàng)目進(jìn)行過(guò)程中,自研數(shù)據(jù)綜合治理平臺(tái)DataWorks(原來(lái)叫作BASE)也同步開(kāi)始構(gòu)建。到了2015年,“登月”項(xiàng)目完成,ODPS+BASE開(kāi)始在阿里云上對(duì)外提供服務(wù),這也標(biāo)志著阿里第一套數(shù)據(jù)中臺(tái)體系構(gòu)建完成。同年,ODPS打破了SortBenchmark的4項(xiàng)世界紀(jì)錄,100TB數(shù)據(jù)排序僅耗時(shí)不到7分鐘。
2016年,阿里集團(tuán)內(nèi)部開(kāi)始涌現(xiàn)出一批新的計(jì)算引擎,包括支持開(kāi)源大數(shù)據(jù)的EMR(E-MapReduce)、實(shí)時(shí)計(jì)算Stream Compute、機(jī)器學(xué)習(xí)PAI等。隨著企業(yè)數(shù)據(jù)場(chǎng)景變得越來(lái)越復(fù)雜,數(shù)據(jù)類型和存儲(chǔ)類型越來(lái)越多樣化,單一引擎或單一存儲(chǔ)已經(jīng)很難滿足客戶需求。這也給大數(shù)據(jù)平臺(tái)帶來(lái)了新的挑戰(zhàn),對(duì)于不同的數(shù)據(jù)類型、存儲(chǔ)類型、計(jì)算引擎,如何方便地進(jìn)行數(shù)據(jù)統(tǒng)一管理和開(kāi)發(fā)?阿里巴巴認(rèn)為當(dāng)前最佳實(shí)現(xiàn)方式是跨引擎統(tǒng)一編程平臺(tái)+跨數(shù)據(jù)源綜合治理,而這推動(dòng)了阿里大數(shù)據(jù)平臺(tái)向飛天大數(shù)據(jù)平臺(tái)的演進(jìn)。
目前的飛天大數(shù)據(jù)平臺(tái),是一個(gè)能夠?qū)㈦x線計(jì)算、實(shí)時(shí)計(jì)算、機(jī)器學(xué)習(xí)、搜索、圖計(jì)算等引擎協(xié)同起來(lái)對(duì)云上客戶提供服務(wù)、且有AI加持的全域數(shù)據(jù)平臺(tái)。下圖是其完整架構(gòu)。
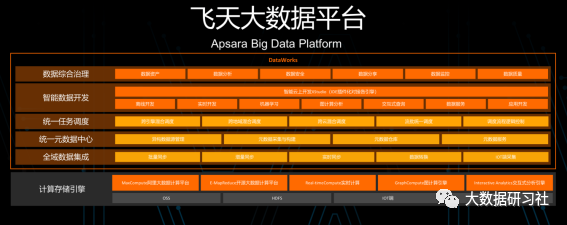
與傳統(tǒng)大數(shù)據(jù)平臺(tái)相比,該平臺(tái)具備以下特色:
1.計(jì)算力與成本的極致優(yōu)化
2.企業(yè)數(shù)據(jù)綜合治理能力
3.大數(shù)據(jù)與AI雙生
下圖是其核心能力。

2010年,京東集團(tuán)啟動(dòng)了在大數(shù)據(jù)領(lǐng)域的研發(fā)和應(yīng)用探索工作,正式組建京東大數(shù)據(jù)部,并確立了數(shù)據(jù)集中式的數(shù)據(jù)服務(wù)模式,成為企業(yè)大數(shù)據(jù)最早的實(shí)踐者之一。
大數(shù)據(jù)平臺(tái)的發(fā)展是隨著京東業(yè)務(wù)同步發(fā)展的,由原來(lái)的傳統(tǒng)數(shù)據(jù)倉(cāng)庫(kù)模式逐步演變?yōu)榛贖adoop的分布式計(jì)算架構(gòu),技術(shù)領(lǐng)域覆蓋Hadoop、Kubernetes、Spark、Hive、Alluxio、Presto、Hbase、Storm、Flink、Kafka等大數(shù)據(jù)全生態(tài)體系。
目前已擁有集群規(guī)模40000+服務(wù)器,單集群規(guī)模達(dá)到7000+臺(tái),數(shù)據(jù)規(guī)模 800PB+,日增數(shù)據(jù)1P+,日運(yùn)行JOB數(shù)100萬(wàn)+,業(yè)務(wù)表900萬(wàn)+張。每日的離線數(shù)據(jù)日處理30PB+,實(shí)時(shí)計(jì)算每天消費(fèi)的行數(shù)近萬(wàn)億條。
下圖為京東大數(shù)據(jù)平臺(tái)整體架構(gòu)圖。
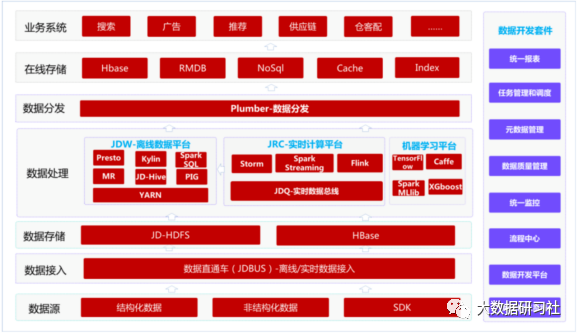
京東的大數(shù)據(jù)體系可以看作是基于Hadoop的大數(shù)據(jù)體系的優(yōu)化和應(yīng)用,因此對(duì)除阿里以外的企業(yè)來(lái)說(shuō)更有借鑒意義。以下是其各主要模塊所使用的技術(shù)棧。
1、數(shù)據(jù)采集和預(yù)處理
搭建了標(biāo)準(zhǔn)化的數(shù)據(jù)采集系統(tǒng):數(shù)據(jù)直通車(框架自研,組件有使用開(kāi)源技術(shù)),具備離線和實(shí)時(shí)兩種數(shù)據(jù)采集方式。
離線采集主要類型:MySQL、SQLServer、Oracle、MongoDB、HBase、ElasticSearch、離線文件。
實(shí)時(shí)采集主要類型:MySQL、日志、HTTP API、JMQ等。
2、流量數(shù)據(jù)采集
主要采集PC端、移動(dòng)端應(yīng)用、移動(dòng)端H5頁(yè)面、微信手Q內(nèi)嵌入口、小程序等流量入口的埋點(diǎn)數(shù)據(jù)。這部分難點(diǎn)在于,各流量入口實(shí)現(xiàn)原理不同,數(shù)據(jù)采集的訴求也不同,甚至有可能不同來(lái)源的數(shù)據(jù)需要做連接,因此需要較多的數(shù)據(jù)標(biāo)識(shí)工作。
3、數(shù)據(jù)存儲(chǔ)
包括JDHDFS存儲(chǔ)(開(kāi)源HDFS的改進(jìn)版)、JDHBase(開(kāi)源HBase的改進(jìn)版)、冷熱數(shù)據(jù)管理等。對(duì)開(kāi)源組件的改進(jìn)點(diǎn)主要在容災(zāi)、元數(shù)據(jù)、多租戶等方面,對(duì)核心代碼邏輯沒(méi)有做大的改動(dòng)。
4、離線計(jì)算
包括JDHive計(jì)算引擎(開(kāi)源Hive的改進(jìn)版)、JDSpark計(jì)算引擎(開(kāi)源Spark的改進(jìn)版)、Adhoc查詢服務(wù)(封裝了Presto和Kylin)等,底層仍使用YARN作為資源調(diào)度器。另外還支持使用Alluxio作為緩存層,加速線上業(yè)務(wù)的數(shù)據(jù)查詢速度。
5、實(shí)時(shí)計(jì)算
搭建了京東大數(shù)據(jù)實(shí)時(shí)計(jì)算平臺(tái),包括實(shí)時(shí)數(shù)據(jù)總線JDQ(開(kāi)源Kafka的改進(jìn)版)、準(zhǔn)實(shí)時(shí)數(shù)據(jù)倉(cāng)庫(kù)(數(shù)據(jù)以準(zhǔn)實(shí)時(shí)的延遲灌入Hive)、實(shí)時(shí)計(jì)算平臺(tái)JRC(Storm、SparkStreaming、Flink)。仍然是各類Hadoop體系開(kāi)源組件的小范圍優(yōu)化。
6、機(jī)器學(xué)習(xí)
京東機(jī)器學(xué)習(xí)平臺(tái)由基礎(chǔ)架構(gòu)層、工具層、任務(wù)調(diào)度層、算法層以及API層組成。京東沒(méi)有公開(kāi)其具體實(shí)現(xiàn)技術(shù),但可以推測(cè),其完全依賴大數(shù)據(jù)平臺(tái)的數(shù)據(jù)采集、計(jì)算、存儲(chǔ)能力,在工具層、算法層、API層做定制開(kāi)發(fā)。
7、任務(wù)管理和調(diào)度
自研了京東分布式調(diào)度平臺(tái),包括管理節(jié)點(diǎn)、工作節(jié)點(diǎn)、Web管理端和日志收集器幾個(gè)組件。其中管理節(jié)點(diǎn)支持高可用。
8、資源監(jiān)控和運(yùn)維
京東大數(shù)據(jù)平臺(tái)監(jiān)控實(shí)現(xiàn)了對(duì)調(diào)度系統(tǒng)、集群任務(wù)管理、集群存儲(chǔ)資源、機(jī)房網(wǎng)絡(luò)專線、全集群服務(wù)器資源的統(tǒng)一監(jiān)控體系,在開(kāi)源的Premetheus上進(jìn)行二次開(kāi)發(fā)。另外還有CMDB、自動(dòng)部署系統(tǒng)等其他系統(tǒng)的支持。
滴滴大數(shù)據(jù)到目前為止經(jīng)歷了三個(gè)階段,第一階段是業(yè)務(wù)方自建小集群;第二階段是集中式大集群、平臺(tái)化;第三階段是SQL化。
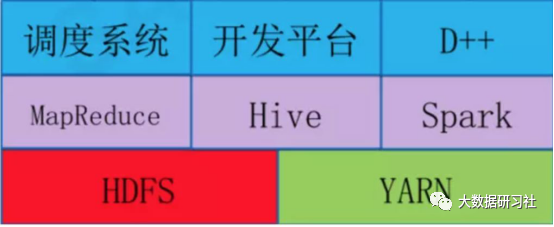
滴滴的離線大數(shù)據(jù)平臺(tái)是基于Hadoop2(HDFS、Yarn、MapReduce)和Spark以及Hive構(gòu)建,在此基礎(chǔ)上開(kāi)發(fā)了自己的調(diào)度系統(tǒng)和開(kāi)發(fā)系統(tǒng)。調(diào)度系統(tǒng)負(fù)責(zé)調(diào)度大數(shù)據(jù)作業(yè)的優(yōu)先級(jí)和執(zhí)行順序。開(kāi)發(fā)平臺(tái)是一個(gè)可視化的SQL編輯器,可以方便地查詢表結(jié)構(gòu)、開(kāi)發(fā)SQL,并發(fā)布到大數(shù)據(jù)集群上。
離線計(jì)算平臺(tái)架構(gòu)如下:
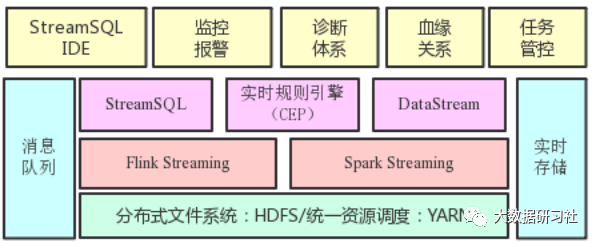
另外,由于滴滴的業(yè)務(wù)特性,非常依賴于實(shí)時(shí)計(jì)算。從2017年開(kāi)始構(gòu)建統(tǒng)一的實(shí)時(shí)計(jì)算集群及平臺(tái)。技術(shù)選型上,基于滴滴現(xiàn)狀選擇了內(nèi)部用以大規(guī)模數(shù)據(jù)清洗的Spark Streaming引擎,以on YARN模式運(yùn)行。利用YARN的多租戶體系構(gòu)建了認(rèn)證、鑒權(quán)、資源隔離、計(jì)費(fèi)等機(jī)制。在流計(jì)算引擎基礎(chǔ)上提供了 StreamSQL IDE、監(jiān)控報(bào)警、診斷體系、血緣關(guān)系、任務(wù)管控等能力。
此外,滴滴還對(duì)HBase重度使用,并對(duì)相關(guān)產(chǎn)品(HBase、Phoenix)做了一些自定義的開(kāi)發(fā),維護(hù)著一個(gè)較大的HBase平臺(tái)。
來(lái)自于實(shí)時(shí)計(jì)算平臺(tái)和離線計(jì)算平臺(tái)的計(jì)算結(jié)果被保存到HBase中,然后應(yīng)用程序通過(guò)Phoenix訪問(wèn)HBase。而Phoenix是一個(gè)構(gòu)建在HBase上的SQL引擎,可以通過(guò)SQL方式訪問(wèn)HBase上的數(shù)據(jù)。
5.1?中等規(guī)模企業(yè)
指研發(fā)團(tuán)隊(duì)規(guī)模在千人左右,專職大數(shù)據(jù)團(tuán)隊(duì)規(guī)模在百人左右的企業(yè)。類似京東、滴滴。
這樣的企業(yè)可以首先以開(kāi)源Hadoop為基準(zhǔn)搭建大數(shù)據(jù)平臺(tái)。當(dāng)在技術(shù)上有一定沉淀以后,可以在開(kāi)源Hadoop社區(qū)各組件的版本上疊加自己的一些特性,使得能夠更好地適配自身的業(yè)務(wù)形態(tài),或減少運(yùn)維的壓力。在發(fā)展模式上,建議從一開(kāi)始就建立統(tǒng)一的大數(shù)據(jù)平臺(tái),向公司內(nèi)各部門統(tǒng)一輸出能力,而不要各部門分散建設(shè),避免后續(xù)的整合、遷移成本。在大數(shù)據(jù)平臺(tái)形成完備的體系后,進(jìn)一步建設(shè)公司層面的大數(shù)據(jù)中臺(tái)。?
1、數(shù)據(jù)采集
開(kāi)源的數(shù)據(jù)采集組件如Flume、StreamSets等都經(jīng)過(guò)了較長(zhǎng)時(shí)間的生產(chǎn)檢驗(yàn),優(yōu)勢(shì)劣勢(shì)都很明確,可以優(yōu)先采用。如果定制型的采集需求很多,或者需要對(duì)數(shù)據(jù)做較多的on fly處理,也可以自研采集組件,但通常來(lái)說(shuō)效率都沒(méi)有開(kāi)源的好。
還有一些比較新的開(kāi)源采集工具,例如Apache Nifi,可以適當(dāng)關(guān)注,不建議在生產(chǎn)中大規(guī)模使用。
2、數(shù)據(jù)存儲(chǔ)
HDFS和HBase幾乎是大數(shù)據(jù)存儲(chǔ)領(lǐng)域?qū)崟r(shí)上的標(biāo)準(zhǔn)。所有需求都應(yīng)該優(yōu)先往這兩種存儲(chǔ)上靠,其中HDFS對(duì)應(yīng)離線數(shù)據(jù)的存儲(chǔ),HBase對(duì)應(yīng)實(shí)時(shí)數(shù)據(jù)的存儲(chǔ)。
Kudu是一種比較新的存儲(chǔ)引擎,在某些互聯(lián)網(wǎng)企業(yè)中被用來(lái)構(gòu)建實(shí)時(shí)數(shù)倉(cāng),其實(shí)時(shí)性介于HDFS和HBase之間。目前也比較穩(wěn)定,有實(shí)時(shí)數(shù)倉(cāng)需求時(shí)可以引入。
另外,傳統(tǒng)的RDBMS也是一種可靠的存儲(chǔ),在大數(shù)據(jù)領(lǐng)域可以用于報(bào)表、BI類服務(wù),但使用時(shí)需要注意其數(shù)據(jù)量。
其余還有一些可用于緩存層的存儲(chǔ),如Redis,Alluxio等,嚴(yán)格來(lái)說(shuō)不屬于Hadoop生態(tài)體系,可以按需使用。
3、離線計(jì)算
MapReduce程序不應(yīng)該再使用,這包括Hive on MapReduce的方案。如果一定需要Hive,可以跑在Spark上。
Spark一定需要,可以將Spark SQL作為構(gòu)建離線數(shù)倉(cāng)的主力工具。
如果有較多的BI類應(yīng)用,可以考慮引入Impala或Kylin,這取決于是要事實(shí)計(jì)算數(shù)據(jù)立方,還是離線把數(shù)據(jù)立方準(zhǔn)備好。
離線計(jì)算的資源管理可以繼續(xù)使用YARN。
4、實(shí)時(shí)計(jì)算
Spark Streaming和Flink幾乎是事實(shí)上的標(biāo)準(zhǔn)。有一些比較年輕的企業(yè)僅使用Flink,但絕大多數(shù)的頭部互聯(lián)網(wǎng)公司都使用了Spark Streaming和Flink兩者,因?yàn)樵诙鄶?shù)批流結(jié)合的場(chǎng)景下,Spark仍然是優(yōu)秀的。
Storm則不應(yīng)該再使用了。
消息隊(duì)列領(lǐng)域,Kafka是必選方案。如果沒(méi)有特別的理由,不要選用阿里開(kāi)源出來(lái)的RocketMQ。
5、機(jī)器學(xué)習(xí)
Spark的MLlib可以解決一部分的機(jī)器學(xué)習(xí)需求。對(duì)于另一些比較復(fù)雜、偏門的算法,如果有明確需求需要使用,可以自己實(shí)現(xiàn)。
另一個(gè)問(wèn)題是機(jī)器學(xué)習(xí)任務(wù)的開(kāi)發(fā)環(huán)境。開(kāi)源產(chǎn)品中只有Cloudera的CDSW比較好用,但它強(qiáng)依賴于CDH。中等規(guī)模互聯(lián)網(wǎng)公司一般都自己開(kāi)發(fā)這樣的環(huán)境。
6、任務(wù)管理和調(diào)度
Hadoop生態(tài)下的開(kāi)源調(diào)度系統(tǒng)有Oozie、Azkaban等,但功能都太簡(jiǎn)單,一般不會(huì)被這個(gè)規(guī)模的企業(yè)所采用。國(guó)內(nèi)廠商貢獻(xiàn)給社區(qū)的DolphinScheduler可以嘗試。也可以自研。
7、其他
還有一些比較成熟的開(kāi)源項(xiàng)目,如果有需求,完全可以在生產(chǎn)中使用。例如用于文檔存儲(chǔ)和搜索的ElasticSearch。這些可以根據(jù)企業(yè)所在的領(lǐng)域和自身技術(shù)積累來(lái)決策。?
5.2 小規(guī)模企業(yè)
指研發(fā)團(tuán)隊(duì)規(guī)模在百人左右,專職大數(shù)據(jù)團(tuán)隊(duì)規(guī)模在幾人到小幾十人的企業(yè)。
這樣的企業(yè)在構(gòu)建大數(shù)據(jù)平臺(tái)時(shí),應(yīng)該以現(xiàn)成的穩(wěn)定產(chǎn)品為主,不要自研或者少量自研,因?yàn)槔习蹇隙ú辉敢獍延邢薜难邪l(fā)資源投入到組件的研究上。
首先要考慮的是使用公有云上的大數(shù)據(jù)服務(wù),還是自建大數(shù)據(jù)集群。兩者各有優(yōu)劣,公有云出成果較快,自建集群掌控力較強(qiáng),但成本投入相差不大。
一旦確定要自建集群,推薦使用成熟的Hadoop發(fā)行版,例如CDH、FusionInsight等。開(kāi)源社區(qū)版本由于缺乏很多運(yùn)維管理上的集成,不推薦小企業(yè)使用。所使用的技術(shù)棧仍可按照我們前面介紹的Hadoop core + Hive + HBase + Spark/Flink + Kafka的組合來(lái)選擇。?
來(lái)源:大數(shù)據(jù)研習(xí)社
- EOF -
PS:如果覺(jué)得我的分享不錯(cuò),歡迎大家隨手點(diǎn)贊、在看。
(完) 加我"微信"?獲取一份 最新Java面試題資料 請(qǐng)備注:666,不然不通過(guò)~
最近好文
1、Kafka 3.0重磅發(fā)布,棄用 Java 8 的支持!
最近面試BAT,整理一份面試資料《Java面試BAT通關(guān)手冊(cè)》,覆蓋了Java核心技術(shù)、JVM、Java并發(fā)、SSM、微服務(wù)、數(shù)據(jù)庫(kù)、數(shù)據(jù)結(jié)構(gòu)等等。 獲取方式:關(guān)注公眾號(hào)并回復(fù)?java?領(lǐng)取,更多內(nèi)容陸續(xù)奉上。 明天見(jiàn)(??ω??)??