
面試 | 22道機器學習常見面試題目
點擊上方“小白學視覺”,選擇加"星標"或“置頂”
重磅干貨,第一時間送達
本文轉(zhuǎn)自|視覺算法 分享22道常考的機器學習面試題,給正在準備面試的朋友們。 (1) 無監(jiān)督和有監(jiān)督算法的區(qū)別?
有監(jiān)督學習:對具有概念標記(分類)的訓練樣本進行學習,以盡可能對訓練樣本集外的數(shù)據(jù)進行標記(分類)預(yù)測。這里,所有的標記(分類)是已知的。因此,訓練樣本的岐義性低。
無監(jiān)督學習:對沒有概念標記(分類)的訓練樣本進行學習,以發(fā)現(xiàn)訓練樣本集中的結(jié)構(gòu)性知識。這里,所有的標記(分類)是未知的。因此,訓練樣本的岐義性高。聚類就是典型的無監(jiān)督學習。
(2) SVM 的推導,特性?多分類怎么處理?
SVM是最大間隔分類器,幾何間隔和樣本的誤分次數(shù)之間存在關(guān)系,
,其中
從線性可分情況下,原問題,特征轉(zhuǎn)換后的dual問題,引入kernel(線性kernel,多項式,高斯),最后是soft margin。
線性:簡單,速度快,但是需要線性可分。
多項式:比線性核擬合程度更強,知道具體的維度,但是高次容易出現(xiàn)數(shù)值不穩(wěn)定,參數(shù)選擇比較多。
高斯:擬合能力最強,但是要注意過擬合問題。不過只有一個參數(shù)需要調(diào)整。
多分類問題,一般將二分類推廣到多分類的方式有三種,一對一,一對多,多對多。
一對一:將N個類別兩兩配對,產(chǎn)生N(N-1)/2個二分類任務(wù),測試階段新樣本同時交給所有的分類器,最終結(jié)果通過投票產(chǎn)生。
一對多:每一次將一個例作為正例,其他的作為反例,訓練N個分類器,測試時如果只有一個分類器預(yù)測為正類,則對應(yīng)類別為最終結(jié)果,如果有多個,則一般選擇置信度最大的。從分類器角度一對一更多,但是每一次都只用了2個類別,因此當類別數(shù)很多的時候一對一開銷通常更小(只要訓練復雜度高于O(N)即可得到此結(jié)果)。
多對多:若干各類作為正類,若干個類作為反類。注意正反類必須特殊的設(shè)計。
(3) LR 的推導,特性?
LR的優(yōu)點在于實現(xiàn)簡單,并且計算量非常小,速度很快,存儲資源低,缺點就是因為模型簡單,對于復雜的情況下會出現(xiàn)欠擬合,并且只能處理2分類問題(可以通過一般的二元轉(zhuǎn)換為多元或者用softmax回歸)。
(4) 決策樹的特性?
決策樹基于樹結(jié)構(gòu)進行決策,與人類在面臨問題的時候處理機制十分類似。其特點在于需要選擇一個屬性進行分支,在分支的過程中選擇信息增益最大的屬性,定義如下
在劃分中我們希望決策樹的分支節(jié)點所包含的樣本屬于同一類別,即節(jié)點的純度越來越高。決策樹計算量簡單,可解釋性強,比較適合處理有缺失屬性值的樣本,能夠處理不相關(guān)的特征,但是容易過擬合,需要使用剪枝或者隨機森林。信息增益是熵減去條件熵,代表信息不確定性較少的程度,信息增益越大,說明不確定性降低的越大,因此說明該特征對分類來說很重要。由于信息增益準則會對數(shù)目較多的屬性有所偏好,因此一般用信息增益率(c4.5)
其中分母可以看作為屬性自身的熵。取值可能性越多,屬性的熵越大。
Cart決策樹使用基尼指數(shù)來選擇劃分屬性,直觀的來說,Gini(D)反映了從數(shù)據(jù)集D中隨機抽取兩個樣本,其類別標記不一致的概率,因此基尼指數(shù)越小數(shù)據(jù)集D的純度越高,一般為了防止過擬合要進行剪枝,有預(yù)剪枝和后剪枝,一般用cross validation集進行剪枝。
連續(xù)值和缺失值的處理,對于連續(xù)屬性a,將a在D上出現(xiàn)的不同的取值進行排序,基于劃分點t將D分為兩個子集。一般對每一個連續(xù)的兩個取值的中點作為劃分點,然后根據(jù)信息增益選擇最大的。與離散屬性不同,若當前節(jié)點劃分屬性為連續(xù)屬性,該屬性還可以作為其后代的劃分屬性。
(5) SVM、LR、決策樹的對比?
SVM既可以用于分類問題,也可以用于回歸問題,并且可以通過核函數(shù)快速的計算,LR實現(xiàn)簡單,訓練速度非常快,但是模型較為簡單,決策樹容易過擬合,需要進行剪枝等。從優(yōu)化函數(shù)上看,soft margin的SVM用的是hinge loss,而帶L2正則化的LR對應(yīng)的是cross entropy loss,另外adaboost對應(yīng)的是exponential loss。所以LR對遠點敏感,但是SVM對outlier不太敏感,因為只關(guān)心support vector,SVM可以將特征映射到無窮維空間,但是LR不可以,一般小數(shù)據(jù)中SVM比LR更優(yōu)一點,但是LR可以預(yù)測概率,而SVM不可以,SVM依賴于數(shù)據(jù)測度,需要先做歸一化,LR一般不需要,對于大量的數(shù)據(jù)LR使用更加廣泛,LR向多分類的擴展更加直接,對于類別不平衡SVM一般用權(quán)重解決,即目標函數(shù)中對正負樣本代價函數(shù)不同,LR可以用一般的方法,也可以直接對最后結(jié)果調(diào)整(通過閾值),一般小數(shù)據(jù)下樣本維度比較高的時候SVM效果要更優(yōu)一些。
(6) GBDT 和隨機森林的區(qū)別?
隨機森林采用的是bagging的思想,bagging又稱為bootstrap aggreagation,通過在訓練樣本集中進行有放回的采樣得到多個采樣集,基于每個采樣集訓練出一個基學習器,再將基學習器結(jié)合。隨機森林在對決策樹進行bagging的基礎(chǔ)上,在決策樹的訓練過程中引入了隨機屬性選擇。傳統(tǒng)決策樹在選擇劃分屬性的時候是在當前節(jié)點屬性集合中選擇最優(yōu)屬性,而隨機森林則是對結(jié)點先隨機選擇包含k個屬性的子集,再選擇最有屬性,k作為一個參數(shù)控制了隨機性的引入程度。
另外,GBDT訓練是基于Boosting思想,每一迭代中根據(jù)錯誤更新樣本權(quán)重,因此是串行生成的序列化方法,而隨機森林是bagging的思想,因此是并行化方法。
(7) 如何判斷函數(shù)凸或非凸?什么是凸優(yōu)化?
首先定義凸集,如果x,y屬于某個集合C,并且所有的
也屬于c,那么c為一個凸集,進一步,如果一個函數(shù)其定義域是凸集,并且
則該函數(shù)為凸函數(shù)。上述條件還能推出更一般的結(jié)果,
如果函數(shù)有二階導數(shù),那么如果函數(shù)二階導數(shù)為正,或者對于多元函數(shù),Hessian矩陣半正定則為凸函數(shù)。
(也可能引到SVM,或者凸函數(shù)局部最優(yōu)也是全局最優(yōu)的證明,或者上述公式期望情況下的Jessen不等式)
(8) 如何解決類別不平衡問題?
有些情況下訓練集中的樣本分布很不平衡,例如在腫瘤檢測等問題中,正樣本的個數(shù)往往非常的少。從線性分類器的角度,在用
對新樣本進行分類的時候,事實上在用預(yù)測出的y值和一個y值進行比較,例如常常在y>0.5的時候判為正例,否則判為反例。幾率
反映了正例可能性和反例可能性的比值,閾值0.5恰好表明分類器認為正反的可能性相同。在樣本不均衡的情況下,應(yīng)該是分類器的預(yù)測幾率高于觀測幾率就判斷為正例,因此應(yīng)該是
時預(yù)測為正例,這種策略稱為rebalancing。但是訓練集并不一定是真實樣本總體的無偏采樣,通常有三種做法,一種是對訓練集的負樣本進行欠采樣,第二種是對正例進行升采樣,第三種是直接基于原始訓練集進行學習,在預(yù)測的時候再改變閾值,稱為閾值移動。注意過采樣一般通過對訓練集的正例進行插值產(chǎn)生額外的正例,而欠采樣將反例劃分為不同的集合供不同的學習器使用。
(9) 解釋對偶的概念。
一個優(yōu)化問題可以從兩個角度進行考察,一個是primal 問題,一個是dual 問題,就是對偶問題,一般情況下對偶問題給出主問題最優(yōu)值的下界,在強對偶性成立的情況下由對偶問題可以得到主問題的最優(yōu)下界,對偶問題是凸優(yōu)化問題,可以進行較好的求解,SVM中就是將primal問題轉(zhuǎn)換為dual問題進行求解,從而進一步引入核函數(shù)的思想。
(10) 如何進行特征選擇?
特征選擇是一個重要的數(shù)據(jù)預(yù)處理過程,主要有兩個原因,首先在現(xiàn)實任務(wù)中我們會遇到維數(shù)災(zāi)難的問題(樣本密度非常稀疏),若能從中選擇一部分特征,那么這個問題能大大緩解,另外就是去除不相關(guān)特征會降低學習任務(wù)的難度,增加模型的泛化能力。冗余特征指該特征包含的信息可以從其他特征中推演出來,但是這并不代表該冗余特征一定沒有作用,例如在欠擬合的情況下也可以用過加入冗余特征,增加簡單模型的復雜度。
在理論上如果沒有任何領(lǐng)域知識作為先驗假設(shè)那么只能遍歷所有可能的子集。但是這顯然是不可能的,因為需要遍歷的數(shù)量是組合爆炸的。一般我們分為子集搜索和子集評價兩個過程,子集搜索一般采用貪心算法,每一輪從候選特征中添加或者刪除,分別成為前向和后先搜索。或者兩者結(jié)合的雙向搜索。子集評價一般采用信息增益,對于連續(xù)數(shù)據(jù)往往排序之后選擇中點作為分割點。
常見的特征選擇方式有過濾式,包裹式和嵌入式,filter,wrapper和embedding。Filter類型先對數(shù)據(jù)集進行特征選擇,再訓練學習器。Wrapper直接把最終學習器的性能作為特征子集的評價準則,一般通過不斷候選子集,然后利用cross-validation過程更新候選特征,通常計算量比較大。嵌入式特征選擇將特征選擇過程和訓練過程融為了一體,在訓練過程中自動進行了特征選擇,例如L1正則化更易于獲得稀疏解,而L2正則化更不容易過擬合。L1正則化可以通過PGD,近端梯度下降進行求解。
(11) 為什么會產(chǎn)生過擬合,有哪些方法可以預(yù)防或克服過擬合?
一般在機器學習中,將學習器在訓練集上的誤差稱為訓練誤差或者經(jīng)驗誤差,在新樣本上的誤差稱為泛化誤差。顯然我們希望得到泛化誤差小的學習器,但是我們事先并不知道新樣本,因此實際上往往努力使經(jīng)驗誤差最小化。然而,當學習器將訓練樣本學的太好的時候,往往可能把訓練樣本自身的特點當做了潛在樣本具有的一般性質(zhì)。這樣就會導致泛化性能下降,稱之為過擬合,相反,欠擬合一般指對訓練樣本的一般性質(zhì)尚未學習好,在訓練集上仍然有較大的誤差。
欠擬合:一般來說欠擬合更容易解決一些,例如增加模型的復雜度,增加決策樹中的分支,增加神經(jīng)網(wǎng)絡(luò)中的訓練次數(shù)等等。
過擬合:一般認為過擬合是無法徹底避免的,因為機器學習面臨的問題一般是np-hard,但是一個有效的解一定要在多項式內(nèi)可以工作,所以會犧牲一些泛化能力。過擬合的解決方案一般有增加樣本數(shù)量,對樣本進行降維,降低模型復雜度,利用先驗知識(L1,L2正則化),利用cross-validation,early stopping等等。
(12) 什么是偏差與方差?
泛化誤差可以分解成偏差的平方加上方差加上噪聲。偏差度量了學習算法的期望預(yù)測和真實結(jié)果的偏離程度,刻畫了學習算法本身的擬合能力,方差度量了同樣大小的訓練集的變動所導致的學習性能的變化,刻畫了數(shù)據(jù)擾動所造成的影響,噪聲表達了當前任務(wù)上任何學習算法所能達到的期望泛化誤差下界,刻畫了問題本身的難度。偏差和方差一般稱為bias和variance,一般訓練程度越強,偏差越小,方差越大,泛化誤差一般在中間有一個最小值,如果偏差較大,方差較小,此時一般稱為欠擬合,而偏差較小,方差較大稱為過擬合。
偏差:
方差:
(13) 神經(jīng)網(wǎng)絡(luò)的原理,如何進行訓練?
神經(jīng)網(wǎng)絡(luò)自發(fā)展以來已經(jīng)是一個非常龐大的學科,一般而言認為神經(jīng)網(wǎng)絡(luò)是由單個的神經(jīng)元和不同神經(jīng)元之間的連接構(gòu)成,不夠的結(jié)構(gòu)構(gòu)成不同的神經(jīng)網(wǎng)絡(luò)。最常見的神經(jīng)網(wǎng)絡(luò)一般稱為多層前饋神經(jīng)網(wǎng)絡(luò),除了輸入和輸出層,中間隱藏層的個數(shù)被稱為神經(jīng)網(wǎng)絡(luò)的層數(shù)。BP算法是訓練神經(jīng)網(wǎng)絡(luò)中最著名的算法,其本質(zhì)是梯度下降和鏈式法則。
(14) 介紹卷積神經(jīng)網(wǎng)絡(luò),和 DBN 有什么區(qū)別?
卷積神經(jīng)網(wǎng)絡(luò)的特點是卷積核,CNN中使用了權(quán)共享,通過不斷的上采用和卷積得到不同的特征表示,采樣層又稱為pooling層,基于局部相關(guān)性原理進行亞采樣,在減少數(shù)據(jù)量的同時保持有用的信息。DBN是深度信念網(wǎng)絡(luò),每一層是一個RBM,整個網(wǎng)絡(luò)可以視為RBM堆疊得到,通常使用無監(jiān)督逐層訓練,從第一層開始,每一層利用上一層的輸入進行訓練,等各層訓練結(jié)束之后再利用BP算法對整個網(wǎng)絡(luò)進行訓練。
(15) 采用 EM 算法求解的模型有哪些,為什么不用牛頓法或梯度下降法?
用EM算法求解的模型一般有GMM或者協(xié)同過濾,k-means其實也屬于EM。EM算法一定會收斂,但是可能收斂到局部最優(yōu)。由于求和的項數(shù)將隨著隱變量的數(shù)目指數(shù)上升,會給梯度計算帶來麻煩。
(16) 用 EM 算法推導解釋 Kmeans。
k-means算法是高斯混合聚類在混合成分方差相等,且每個樣本僅指派一個混合成分時候的特例。注意k-means在運行之前需要進行歸一化處理,不然可能會因為樣本在某些維度上過大導致距離計算失效。k-means中每個樣本所屬的類就可以看成是一個隱變量,在E步中,我們固定每個類的中心,通過對每一個樣本選擇最近的類優(yōu)化目標函數(shù),在M步,重新更新每個類的中心點,該步驟可以通過對目標函數(shù)求導實現(xiàn),最終可得新的類中心就是類中樣本的均值。
(17) 用過哪些聚類算法,解釋密度聚類算法。
k-means算法,聚類性能的度量一般分為兩類,一類是聚類結(jié)果與某個參考模型比較(外部指標),另外是直接考察聚類結(jié)果(內(nèi)部指標)。后者通常有DB指數(shù)和DI,DB指數(shù)是對每個類,找出類內(nèi)平均距離/類間中心距離最大的類,然后計算上述值,并對所有的類求和,越小越好。類似k-means的算法僅在類中數(shù)據(jù)構(gòu)成簇的情況下表現(xiàn)較好,密度聚類算法從樣本密度的角度考察樣本之間的可連接性,并基于可連接樣本不斷擴展聚類蔟得到最終結(jié)果。DBSCAN(density-based spatial clustering of applications with noise)是一種著名的密度聚類算法,基于一組鄰域參數(shù)
進行刻畫,包括鄰域,核心對象(鄰域內(nèi)至少包含
個對象),密度直達(j由i密度直達,表示j在i的鄰域內(nèi),且i是一個核心對象),密度可達(j由i密度可達,存在樣本序列使得每一對都密度直達),密度相連(xi,xj存在k,i,j均有k可達),先找出樣本中所有的核心對象,然后以任一核心對象作為出發(fā)點,找出由其密度可達的樣本生成聚類蔟,直到所有核心對象被訪問過為止。
(18) 聚類算法中的距離度量有哪些?
聚類算法中的距離度量一般用閩科夫斯基距離,在p取不同的值下對應(yīng)不同的距離,例如p=1的時候?qū)?yīng)曼哈頓距離,p=2的情況下對應(yīng)歐式距離,p=inf的情況下變?yōu)榍斜妊┓蚓嚯x,還有jaccard距離,冪距離(閩科夫斯基的更一般形式),余弦相似度,加權(quán)的距離,馬氏距離(類似加權(quán))作為距離度量需要滿足非負性,同一性,對稱性和直遞性,閩科夫斯基在p>=1的時候滿足讀來那個性質(zhì),對于一些離散屬性例如{飛機,火車,輪船}則不能直接在屬性值上計算距離,這些稱為無序?qū)傩裕梢杂肰DM(Value Diffrence Metrix),屬性u上兩個離散值a,b之間的VDM距離定義為
其中
表示在第i個簇中屬性u上a的樣本數(shù),樣本空間中不同屬性的重要性不同的時候可以采用加權(quán)距離,一般如果認為所有屬性重要性相同則要對特征進行歸一化。一般來說距離需要的是相似性度量,距離越大,相似度越小,用于相似性度量的距離未必一定要滿足距離度量的所有性質(zhì),例如直遞性。比如人馬和人,人馬和馬的距離較近,然后人和馬的距離可能就很遠。
(19) 解釋貝葉斯公式和樸素貝葉斯分類。
貝葉斯公式:
最小化分類錯誤的貝葉斯最優(yōu)分類器等價于最大化后驗概率。
基于貝葉斯公式來估計后驗概率的主要困難在于,條件概率
是所有屬性上的聯(lián)合概率,難以從有限的訓練樣本直接估計得到。樸素貝葉斯分類器采用了屬性條件獨立性假設(shè),對于已知的類別,假設(shè)所有屬性相互獨立。這樣,樸素貝葉斯分類則定義為
如果有足夠多的獨立同分布樣本,那么
可以根據(jù)每個類中的樣本數(shù)量直接估計出來。在離散情況下先驗概率可以利用樣本數(shù)量估計或者離散情況下根據(jù)假設(shè)的概率密度函數(shù)進行最大似然估計。樸素貝葉斯可以用于同時包含連續(xù)變量和離散變量的情況。如果直接基于出現(xiàn)的次數(shù)進行估計,會出現(xiàn)一項為0而乘積為0的情況,所以一般會用一些平滑的方法,例如拉普拉斯修正,
這樣既可以保證概率的歸一化,同時還能避免上述出現(xiàn)的現(xiàn)象。
(20) 解釋L1和L2正則化的作用。
L1正則化是在代價函數(shù)后面加上
,L2正則化是在代價函數(shù)后面增加了
,兩者都起到一定的過擬合作用,兩者都對應(yīng)一定的先驗知識,L1對應(yīng)拉普拉斯分布,L2對應(yīng)高斯分布,L1偏向于參數(shù)稀疏性,L2偏向于參數(shù)分布較為稠
(21) TF-IDF是什么?
TF指Term frequecy,代表詞頻,IDF代表inverse document frequency,叫做逆文檔頻率,這個算法可以用來提取文檔的關(guān)鍵詞,首先一般認為在文章中出現(xiàn)次數(shù)較多的詞是關(guān)鍵詞,詞頻就代表了這一項,然而有些詞是停用詞,例如的,是,有這種大量出現(xiàn)的詞,首先需要進行過濾,比如過濾之后再統(tǒng)計詞頻出現(xiàn)了中國,蜜蜂,養(yǎng)殖且三個詞的詞頻幾乎一致,但是中國這個詞出現(xiàn)在其他文章的概率比其他兩個詞要高不少,因此我們應(yīng)該認為后兩個詞更能表現(xiàn)文章的主題,IDF就代表了這樣的信息,計算該值需要一個語料庫,如果一個詞在語料庫中出現(xiàn)的概率越小,那么該詞的IDF應(yīng)該越大,一般來說TF計算公式為(某個詞在文章中出現(xiàn)次數(shù)/文章的總詞數(shù)),這樣消除長文章中詞出現(xiàn)次數(shù)多的影響,IDF計算公式為log(語料庫文章總數(shù)/(包含該詞的文章數(shù))+1)。將兩者乘乘起來就得到了詞的TF-IDF。傳統(tǒng)的TF-IDF對詞出現(xiàn)的位置沒有進行考慮,可以針對不同位置賦予不同的權(quán)重進行修正,注意這些修正之所以是有效的,正是因為人觀測過了大量的信息,因此建議了一個先驗估計,人將這個先驗估計融合到了算法里面,所以使算法更加的有效
(22) 文本中的余弦距離是什么,有哪些作用?
余弦距離是兩個向量的距離的一種度量方式,其值在-1~1之間,如果為1表示兩個向量同相,0表示兩個向量正交,-1表示兩個向量反向。使用TF-IDF和余弦距離可以尋找內(nèi)容相似的文章,例如首先用TF-IDF找出兩篇文章的關(guān)鍵詞,然后每個文章分別取出k個關(guān)鍵詞(10-20個),統(tǒng)計這些關(guān)鍵詞的詞頻,生成兩篇文章的詞頻向量,然后用余弦距離計算其相似度。

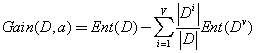
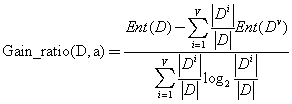
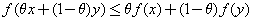
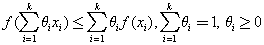
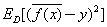
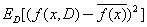
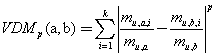
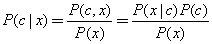
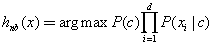
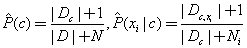
交流群
歡迎加入公眾號讀者群一起和同行交流,目前有SLAM、三維視覺、傳感器、自動駕駛、計算攝影、檢測、分割、識別、醫(yī)學影像、GAN、算法競賽等微信群(以后會逐漸細分),請掃描下面微信號加群,備注:”昵稱+學校/公司+研究方向“,例如:”張三 + 上海交大 + 視覺SLAM“。請按照格式備注,否則不予通過。添加成功后會根據(jù)研究方向邀請進入相關(guān)微信群。請勿在群內(nèi)發(fā)送廣告,否則會請出群,謝謝理解~